Oracle Database-基础及查询部分
Oracle Database-基础及查询部分

Oracle Database,又名Oracle RDBMS,或简称Oracle。是甲骨文公司的一款关系数据库管理系统。它是在数据库领域一直处于领先地位的产品。可以说Oracle数据库系统是目前世界上流行的关系数据库管理系统,系统可移植性好、使用方便、功能强,适用于各类大、中、小、微机环境。它是一种高效率、可靠性好的 适应高吞吐量的数据库解决方案。
基本概念
一个Oracle服务器
- 是一个数据管理系统(RDBMS),提供开放的,全面的,近乎完整的信息管理
- 由一个Oracle数据库和多个Oracle实例组成
- 数据库对应物理上的文件存在,将数据库文件读取到内存中就成为了实例
- 操作Oracle数据库即通过操作实例来完成
- 数据库与实例可以为一对一或一对多,若为一对多,即称集群(cluster)
- 集群的优点:负载均衡,失败迁移

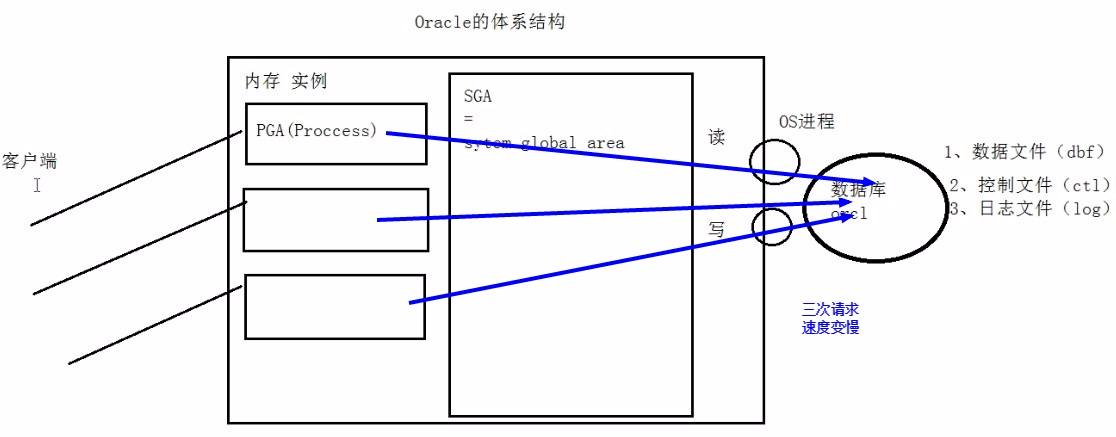
Oracle的体系结构

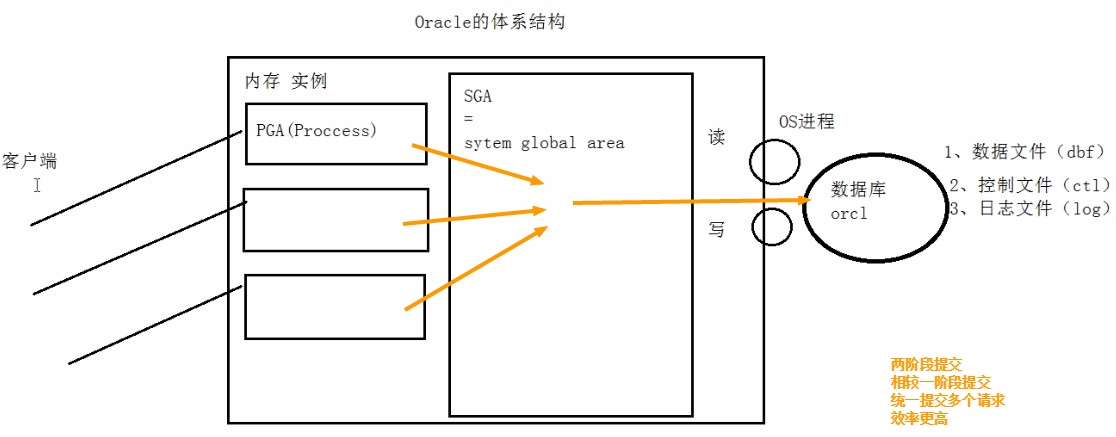
若为一阶段提交:

Database 数据库
- Oracle数据库是数据的物理存储,包括数据文件ORA或DBF、控制文件(CTL)、联机日志和参数文件
- Oracle数据库的概念与MySQL有所不同,一个操作系统只能由一个库
Instance 实例
- 一个Oracle实例(Oracle Instance)又一系列的后台进程和内存结构组成,一个数据库可以有多个实例
数据文件(dbf)
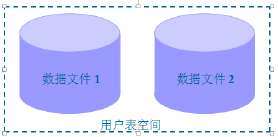
- 数据文件是数据库的物理存储单位,数据库的数据是表面上存储在表空间中的,实际上是在某一个或多个数据文件中存放
- 一个表空间可以由一个或多个数据文件组成
- 一个数据文件只能属于一个表空间
- 一旦数据文件被加入到某个表空间后,就不可以删除这个文件,如果要上出这个文件必须先删除其所属表空间
表空间
- 表空间是Oracle对物理数据库上的相关数据文件(ORA或DBF文件)的逻辑映射,一个数据库在逻辑上被划分为一到若干个表空间,每个表空间包含了在逻辑上相关联的一组结构
- 每个数据库至少有一个表空间
- 每个表空间由同一磁盘上的一个或多个文件组成,这些文件称数据文件(datafile)
- 一个数据文件只能属于一个表空间
![]()
- 表空间为逻辑概念,数据文件为物理概念
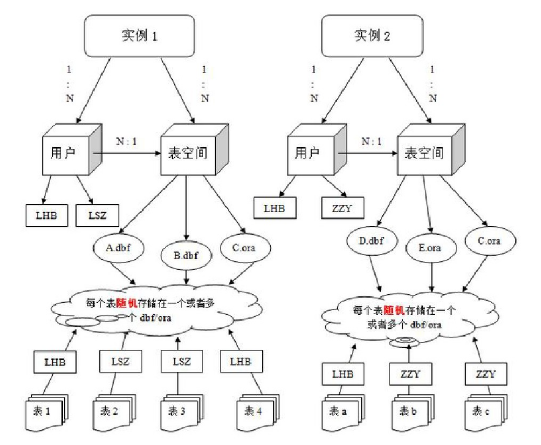
用户
- 用户实在实例下建立的,不同的实例中可以创建相同名称的用户
- 表中的数据是由用户放入某一个表空间的,而这个表空间会随机把这些表数据放到一个或者多个数据文件中
- Oracle数据库不是普通的概念,Oracle是由用户和表空间对数据进行管理和存放的,但表不是由表空间去查询二十由用户来查询的,故不同用户可以在同一个表空间建立同一个名字的表,这个表就是由建表用户来区分了
![]()
SCOTT用户和HR用户
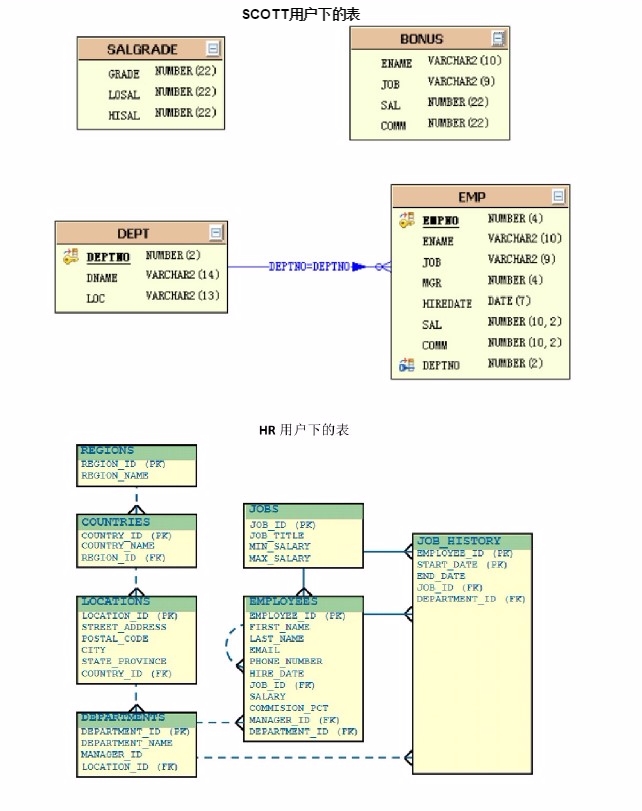
基本查询
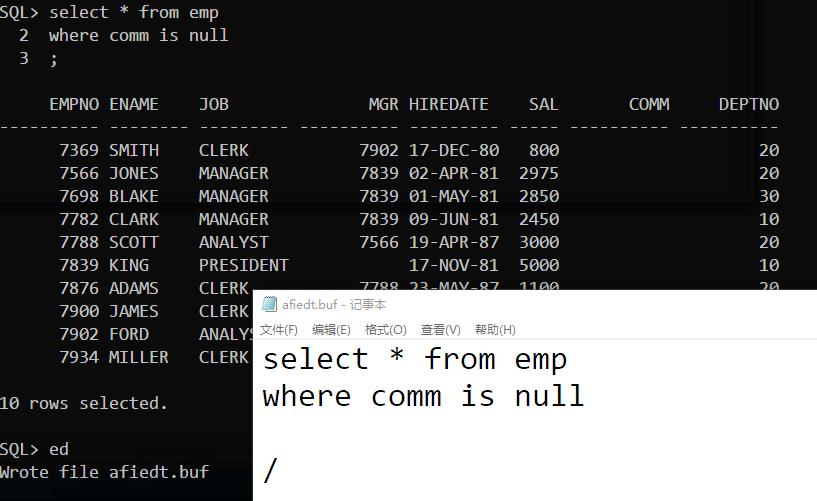
更改某行SQL语句
- 使用【c】命令

- 使用【edit/ed】命令,将自动用编辑器打开上一条执行的sql语句
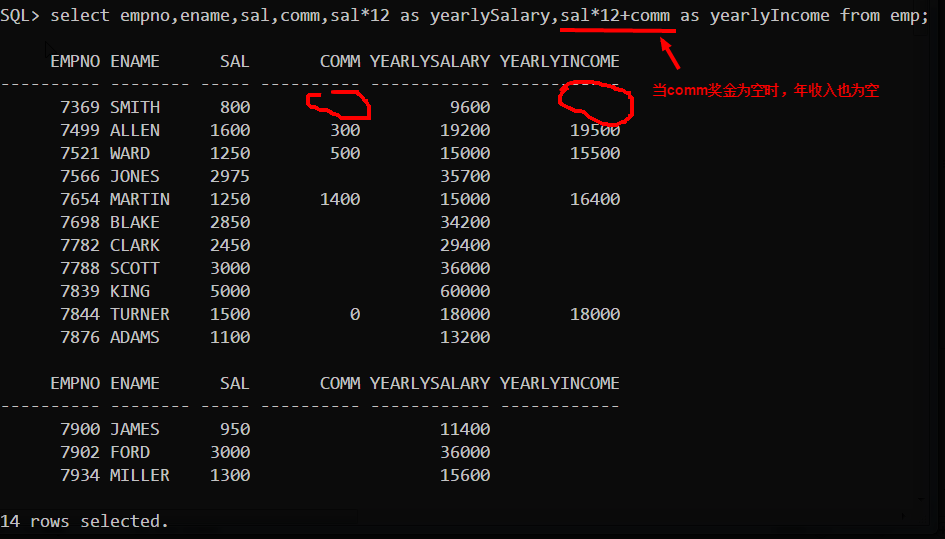
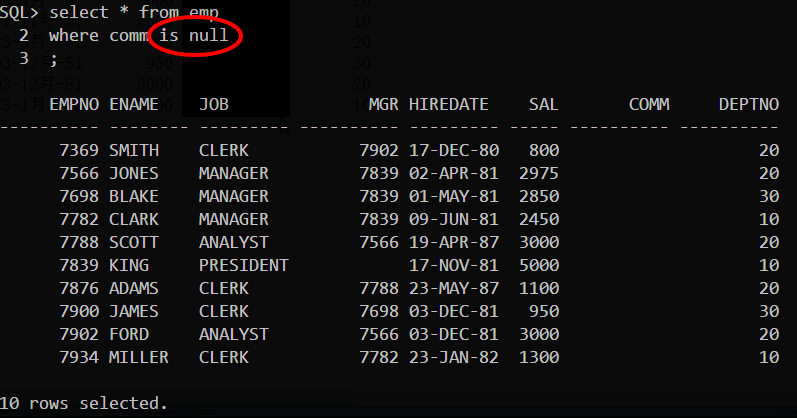
SQL中的空值(null)问题
- 包含null的表达式都为null
![]()
- null永远不等于null,所以判断一个值是否等于null应该使用is null语句而非x = null 这样的语句
![]()
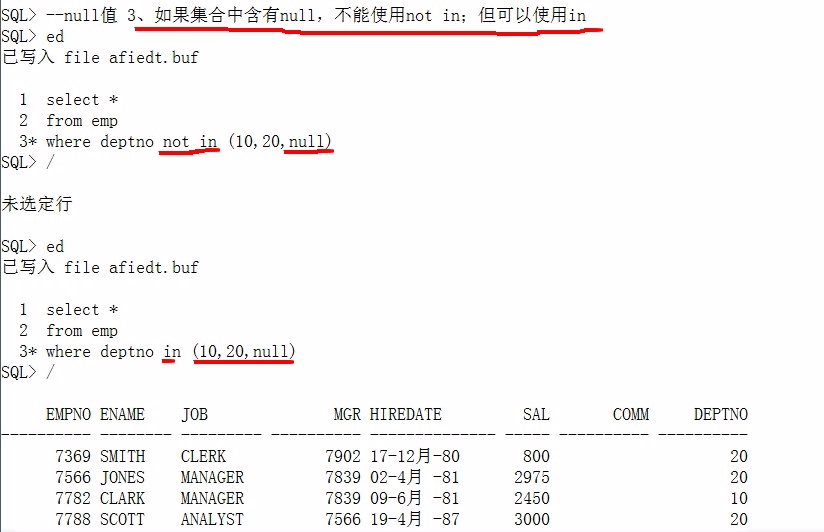
- 如果集合中含有空值,不能使用not in关键字,但可以使用in,具体见下文提及in关键字的部分
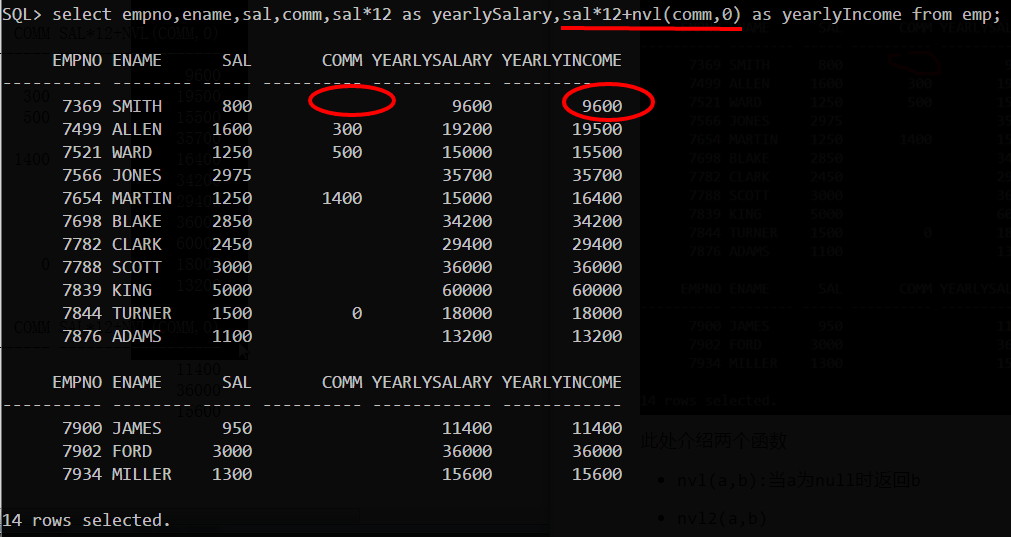
此处介绍两个函数
- nvl(a,b):当a为null时返回b
![]()
- nvl2(a,b)
查询结果显示格式

关于别名

三种方式均可以(【列名 as "xx"】或【列名 "xx"】或【列名 xx】)
加as和不加as完全没有区别,只是省略了as关键字
而加双引号和不加双引号有区别:具体在于不加双引号只能填写连续的别名,若中间有空格,则认为别名已经结束,从而会把空格后的别名当作SQL语句的关键字来执行(一般会报关键字错误),中间有逗号等等同理,用数字来作别名的话也要加双引号
注意:单引号表示字符串
DISTINCT关键字
用于去重
若distinct关键字的位置如:![]()

则去重作用于后面的所有列,只要这些列组合起来是不相同的,则认为不是重复的![]()
![]()
![]()
![]()
SQL和SQL*Plus
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
逻辑运算

伪表和伪列
Oracle中提供dual表等作为伪表,用于适应SQL99标准的select语句中必须有from关键字,而伪表则仅仅是为满足需要from关键字的要求,本身无意义

伪列同理
连接符||和concat函数
相当于Java中的'+'用于连接字符串
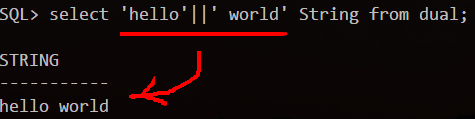

数据库中的字符串
- 字符串可以是SELECT列表中的一个字符,数字,日期
- 日期和字符只能在单引号中出现,双引号表示列的别名
- 每当返回一行时,字符串被输出一次
spool语句
Oracle提供的录屏功能,能把本次命令行的所有输入输出转存成一个文本文件
SQL和SQL*Plus
SQL
- 一种语言
- ANSI 标准
- 关键字不能缩写
- 使用语句控制数据库中的表的定义信息和表中的数据
SQL*Plus
- 一种环境
- Oracle 的特性之一
- 关键字可以缩写
- 命令不能改变数据库中的数据的值
- 集中运行
区分SQL与SQLPlus命令的方法就是看这个命令是否可以缩写
iSQL*Plus
使用iSQL*Plus可以:
iSQL*Plus相当于网页版的SQL*Plus
- 描述表结构。
- 编辑SQL语句。
- 执行SQL语句。
- 将SQL保存在文件中并将SQL语句执行结果保存在文件中。
- 在保存的文件中执行语句。
- 将文本文件装入SQL*Plus编辑窗口。
- Oracle在本机:http://localhost:5560/isqlplus/
- 若Oracle在虚拟机,本机为例http://169.254.35.157:5560/isqlplus/

条件查询和排序
条件查询(过滤)

字符和日期
- 字符和日期要包含在单引号中
- 字符大小写敏感(而MySQL不区分大小写),日期格式敏感
- 默认的日期格式时DD-MON-RR

可以修改日期的格式:
先查询当前日期格式:select * from v$nls_parameters;

然后可以通过alter修改参数的值
若仅对当前会话生效:alter session set NLS_DATE_FORMAT='yyyy-mm-dd';
若对全局生效:alter system set NLS_DATE_FORMAT='yyyy-mm-dd';
比较运算
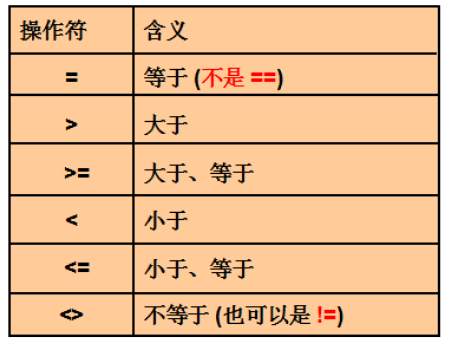
赋值使用'='
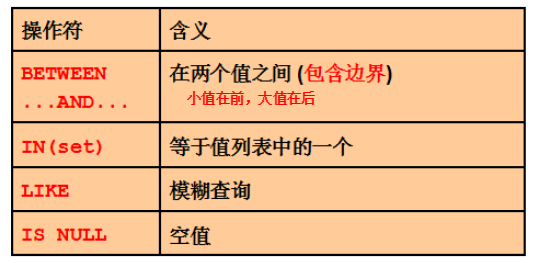
BETWEEN AND

IN

LIKE
在模糊查询中,可以使用ESCAPE标识符选择‘%’和‘_’符号
若查询条件中有下划线作,则使用转义字符'\'将下划线转义成字符串而不是标识符
转义字符需要用escape关键字声名:

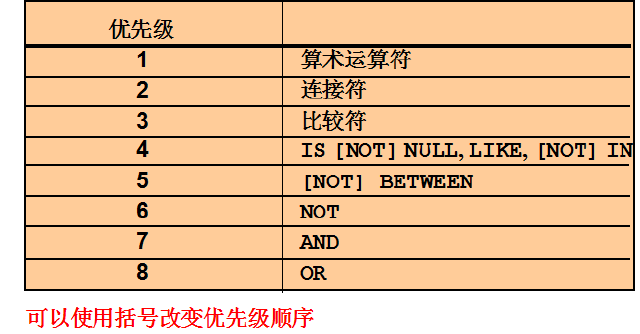
逻辑运算

运算符的优先级
ORDER BY子句


序号从1开始
单个列排序
使用ORDER BY来排序
- ASC(ascend):升序
- DESC(descend):降序
ORDER BY 子句在SELECT语句的结尾

降序如下

多个列排序

若需要降序排序,则在需要降序的列名后加desc关键字,若需要全部列都按降序排序,则需要在全部列名后加desc

排序的规则
- 可以按照select语句中的列名排序
- 可以按照别名列名排序
- 可以按照select语句中的列名的顺序值排序
- 如果要按照多列进行排序,则规则是先按照第一列排序,如果相同,则按照第二列排序;以此类推
考虑空值null的排序
默认升序时空值排最后,而降序时空值排最前,可以加nulls last关键字来使空值在降序时仍然排在最后
函数
SQL函数的概念

两种SQL函数
单行函数
这部分只列出了常用的函数,其他函数见Oracle官方文档
- 操作数据对象
- 接受参数返回一个结果
- 只对一行进行变换
- 每行返回一个结果
- 可以转换数据类型
- 可以嵌套
- 参数可以是一列或一个值
- 使用函数时函数名对大小写不敏感

单行函数分为五大类型(另外可以说条件表达式是第六种单行函数)

字符函数
大小写控制函数
用于改变字符的大小写
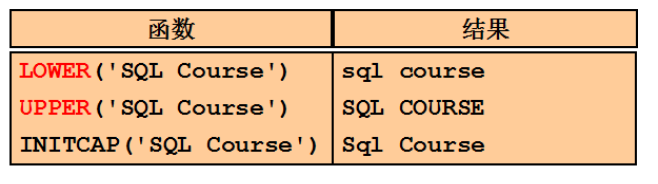
示例:

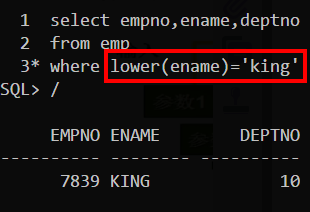
字符控制函数
注意下表由1开始(而不是0)

数值函数





日期函数
- Oracle中的日期型数据类型(date类型)实际含有两个值(而MySql有date-日期和datetime-日期时间两种表示日期的数据类型): 日期和时间
- date=日期+时间
- 使用select sysdate from dual来查看当前时间
![]()
- 默认的日期格式是DD-MON-RR
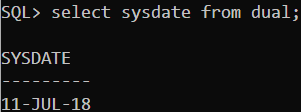
日期的运算
- 在日期上加上或减去一个数字结果仍为日期,直接加减单位是天
![]()
- 两个日期相减返回日期之间相差的天数,两个日期之间不可以相加
![]()
- 可以用数字除24来向日期中加上或减去小时

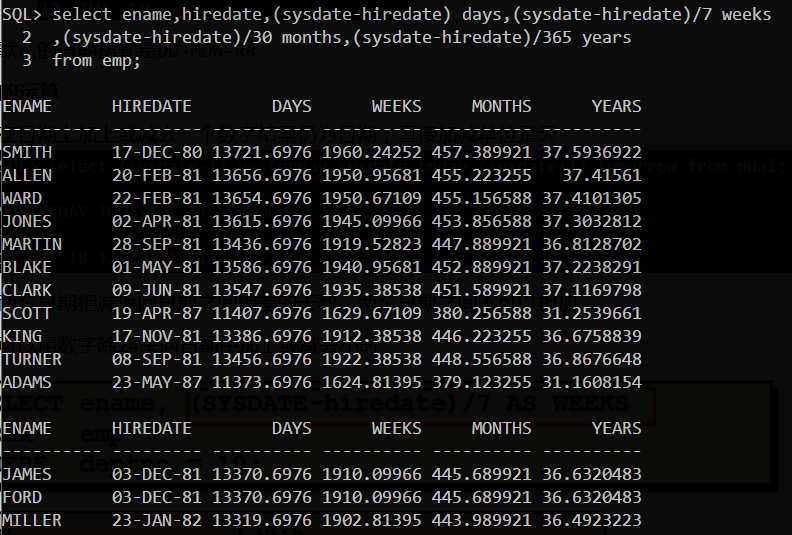

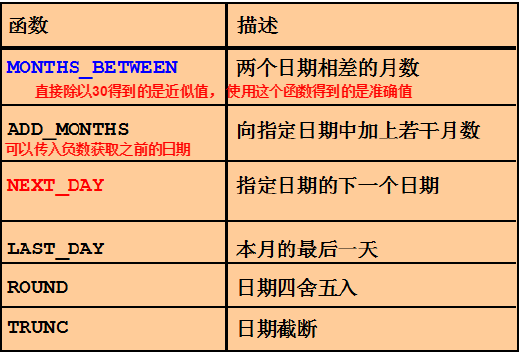
MONTHS_BETWEEN函数

NEXT_DAY函数

ROUND函数和TRUNC函数应用到日期

转换函数(数据类型转换)

隐式转换
Oracle自动完成以下转换

显式转换
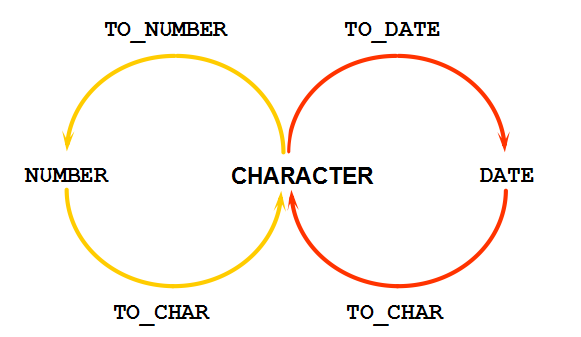
TO_CHAR 函数对日期的转换

格式
- 必须包含在单引号中而且大小写敏感。
- 可以包含任意的有效的日期格式。
- 日期之间用逗号隔开。

若精确到分秒,使用hh24或12:mi:ss

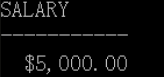
TO_CHAR 函数对数字的转换

常用格式

示例:


TO_NUMBER 和TO_DATE 函数

通用函数
这些函数适用于任何数据类型,同时也适用于空值
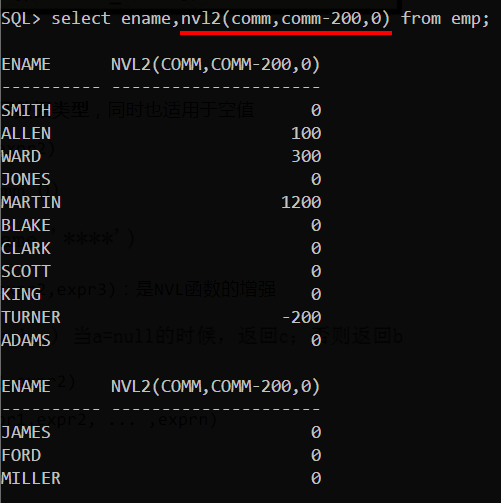
- NVL(expr1, expr2)
![]()
- NVL2(expr1,expr2,expr3):是NVL函数的增强
![]()
![]()
- NULLIF(expr1,expr2)
![]()
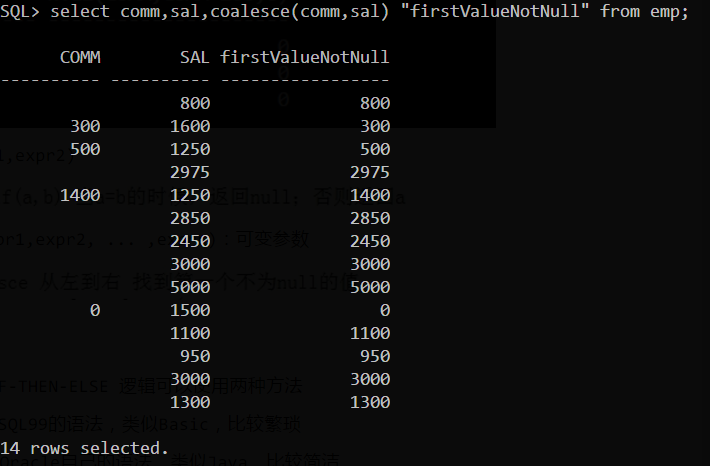
- COALESCE(expr1,expr2, ... ,exprn):可变参数
![]()
![]()



条件表达式
在SQL语句中使用IF-THEN-ELSE 逻辑可以使用两种方法
- CASE表达式:SQL99的语法,类似Basic,比较繁琐
- DECODE函数:Oracle自己的语法,类似Java,比较简洁
CASE表达式

示例:
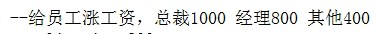
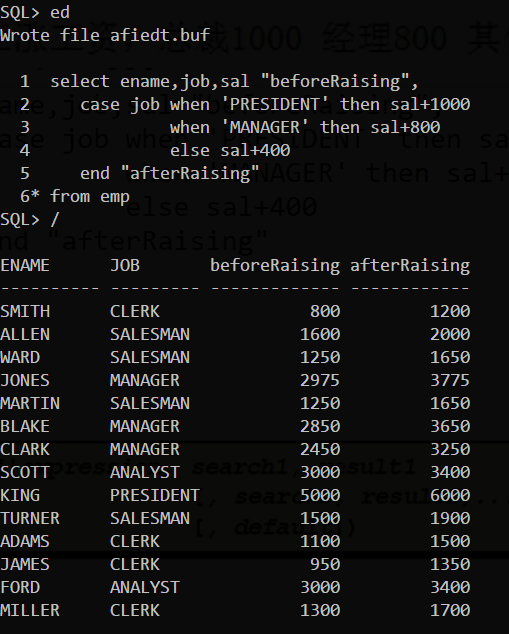
注意:这个表达式不会修改原来的值
DECODE函数

示例:![]()
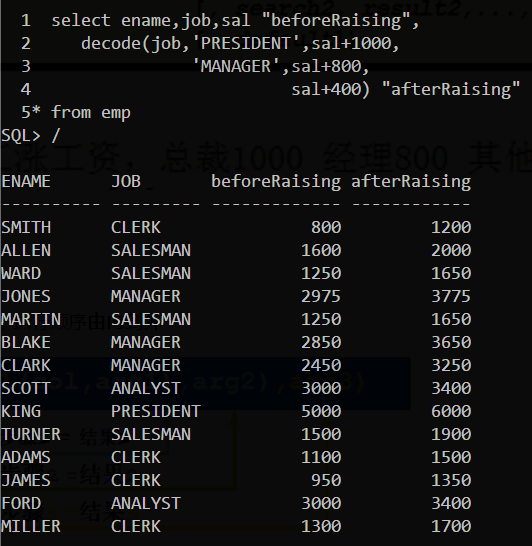
另外,条件表达式也适用于范围条件
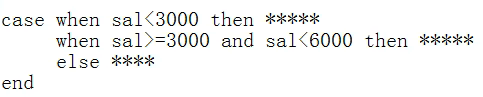
函数可以嵌套使用
单行函数可以嵌套,执行顺序由内到外
多行函数(或称组函数、分组函数)
多行函数作用于多行数据,并对多行数据返回一个值

多行函数语法

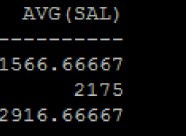
常用的多行函数
- AVG:平均值
- COUNT:计数
- MAX:最大值
- MIN:最小值
- SUM:求和
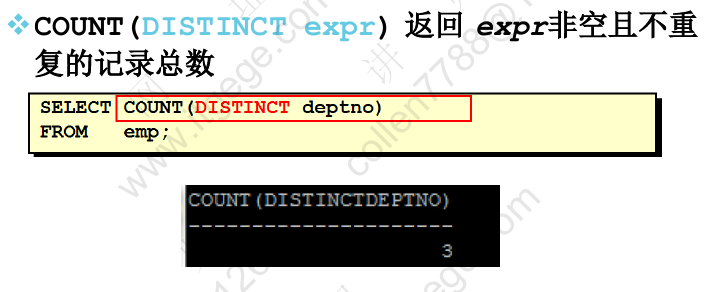
COUNT(计数)函数

也可以使用distinct关键字返回非空且不重复的记录数
多行函数与空值
多行函数将忽略空值
可以使用嵌套nvl函数来使多行函数对空值有效,如下

分组数据(GROUP BY)
语法

可以使用GROUP BY子句将表中的数据分成若干组
使用GRUOP BY子句的基本要求
在SELECT列表中所有未包含在多行函数中的列都应该包含在GROUP BY子句中


包含在GROUP BY子句中的列不必包含在SELECT列表中

非法使用示例

多个列分组
在GRUOP BY子句中包含多个列就可以按照多个列分组
先按照第一个列分组,再按照第二个列分组,以此类推

过滤分组数据
HAVING子句
- 行已经被分组。
- 使用了组函数。
- 满足HAVING 子句中条件的分组将被显示

使用注意
- 不能在WHERE子句中使用多行函数
![]()
- 可以在HAVING子句中使用多行函数
![]()

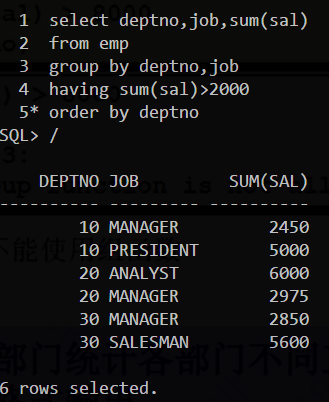
GROUP BY语句的增强

结果分别是下列三条select语句的查询结果组合

相当于下面这条语句
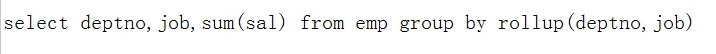
是为GROUP BY语句的增强
rollup函数的作用:
ROLLUP(A,B)

图中结果有调整过格式,使用break on deptno skip 2就可以调整格式了,若要取消,则使用break on null既可以还原原来的格式了
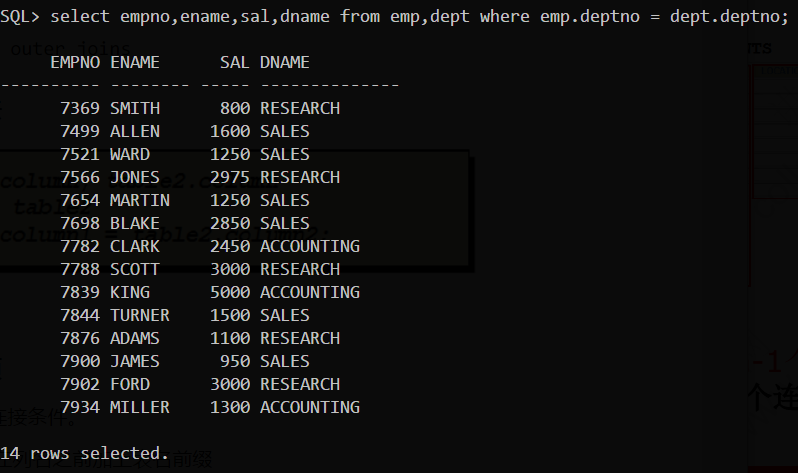
多表查询
笛卡尔积

笛卡尔积是两(多)张表的简单相乘,而多表查询的目的的就是从笛卡尔积中查询出正确的、对应的数据结果
而查询出正确的数据结果的根据是连接条件,如上表的连接条件是deptno部门号
所以多表查询即是在笛卡尔全积中根据连接条件查询出正确的数据结果
连接条件至少有N-1个,N是表的个数
Oracle中连接条件的类型
Oracle中,根据连接条件的不同,分为以下几个类型
- 等值连接
- 不等值连接
- 外连接
- 自连接
SQL99标准中的连接类型
- Cross joins
- Natural joins
- Using clause
- Full or two sided outer joins
不同类型的连接条件多表查询的基本语法和作用
等值连接

不等值连接

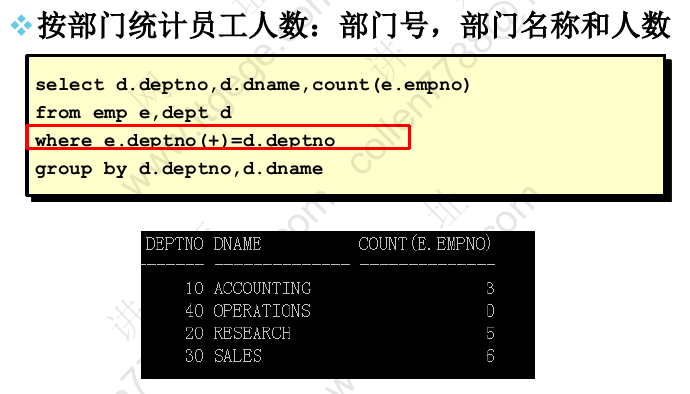
外连接
- 使用外连接可以查询不满足连接条件的数据。
- 外连接的符号是"(+)"
右外连接语法
当等值条件不成立时,等号右边的列数据仍然被包含在查询结果中

左外连接语法
当等值条件不成立时,等号左边的列数据仍然被包含在查询结果中

示例:
若按照简单等值查询,则会丢失没有员工的OPERATIONS部门的记录,应该使用外连接查询
此处为右外连接,相对地,左外连接应该在
自连接
即单个表作为两个表来连接
示例:


自连接查询多表的缺陷
自连接查询多表的笛卡尔积记录数是这个表记录数的平方,查询记录数庞大的表时,就会得到庞大的笛卡尔积,造成性能浪费
所以自连接不适合操作大表,要避免庞大的笛卡尔积或者说避免笛卡尔积的出现,可以使用层次查询
*层次查询
层次查询实际上是单表查询,避免了笛卡尔积的出现
示例:
员工与经理的层次关系如下
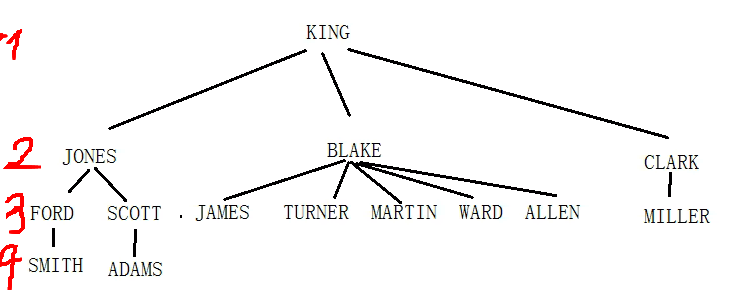
层次查询的语法

遍历这棵层次树需要有起始节点,如下
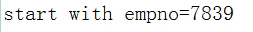
若起始节点为根节点,可以这样书写

具体如下

Oracle还提供了伪列之一 level来表示层级
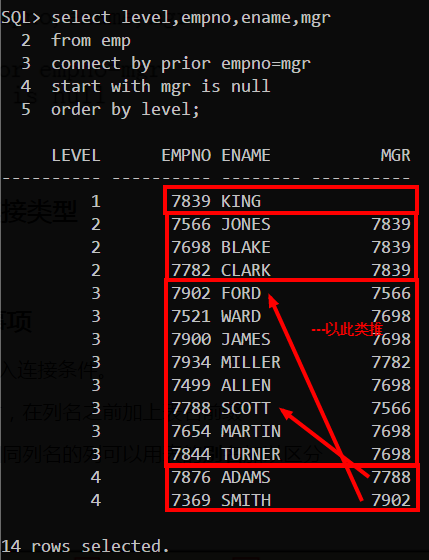
故查询语句如下

查询结果如下
SQL99标准中的连接类型
自查,附件pdf
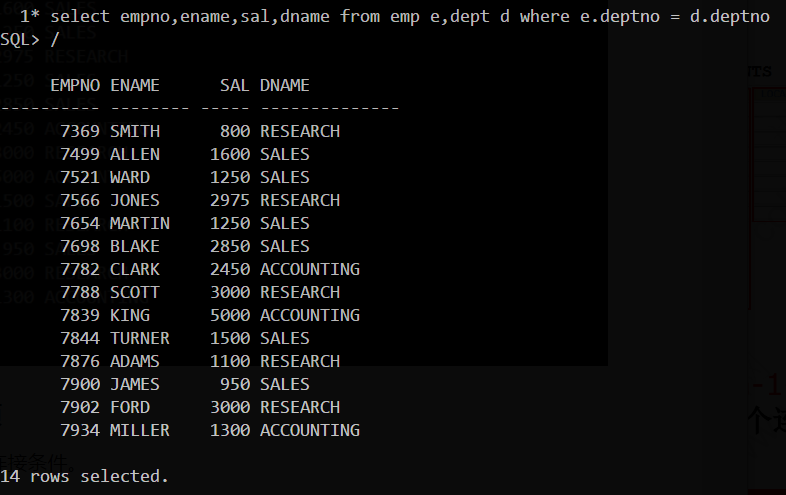
多表查询的注意事项
- 在WHERE字句中写入连接条件。
- 在表中有相同列时,在列名之前加上表名前缀
- 在不同表中具有相同列名的列可以用表的别名加以区分
使用表的别名

注意:如果使用了表的别名,则不能再使用表的真名
子查询
子查询又叫内查询,相对的,主查询也成为外查询
- 子查询(内查询) 在主查询之前一次执行完成
- 有例外,见下文注意事项
- 子查询的结果被主查询使用(外查询)
- 更多详细示例见附件pdf(day02)
子查询语法

示例:
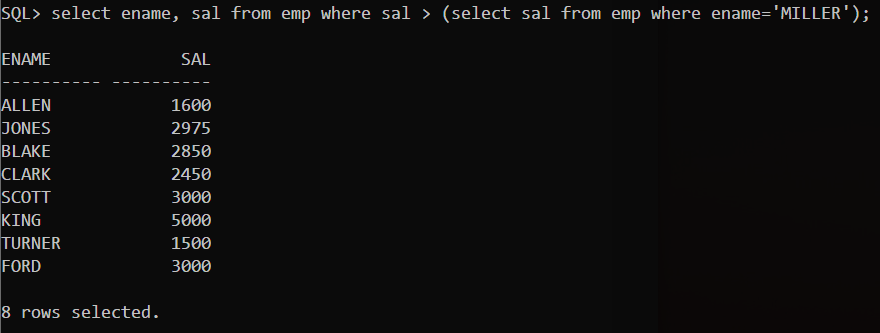
子查询使用细节
注意事项
- 子查询要包含在括号内
- 将子查询放在比较条件的右侧
- 单行操作符对应单行子查询,多行操作符对应多行子查询
- 有一定的SQL语句格式便于阅读
- 不可以在GROUP BY子句后使用子查询
- 主查询和子查询可以是分别查询两(多)张不同的表
- 需要满足子查询返回的结果主查询可以使用即可
![]()
- 一般不在子查询中排序
- 在top-n分析问题中必须在子查询中排序,关于top-n问题,见下文拓展内容
- 通常先执行子查询,在执行主查询
- 特殊情况:在相关子查询中有可能先执行主查询再执行子查询
- 子查询的空值问题
- 当子查询和多表查询可以得到相同的结果时,尽量使用多表查询
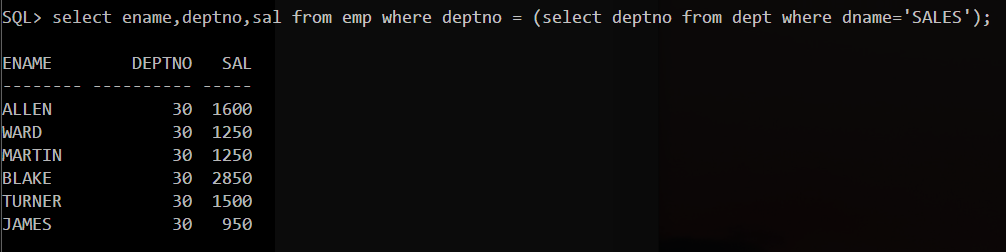
子查询可以用于
- where关键字后
- select关键字后
- 需要子查询返回一行数据,即子查询应该是一个单行子查询,若返回多行数据则报错
![]()
- having关键字后
- from关键字后(特殊)
![]()

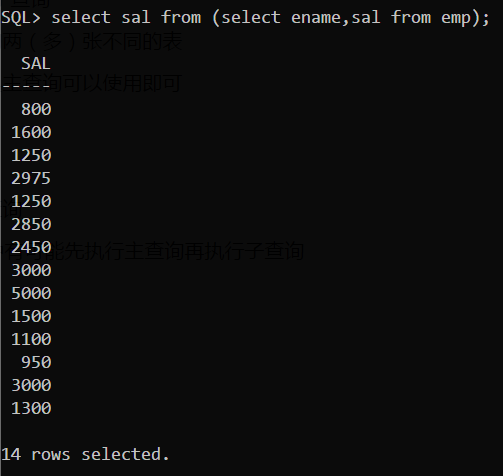
▲在FROM关键字后使用子查询
子查询返回的结果相当于一个新的表,把它看作一张独立的表作查询即可
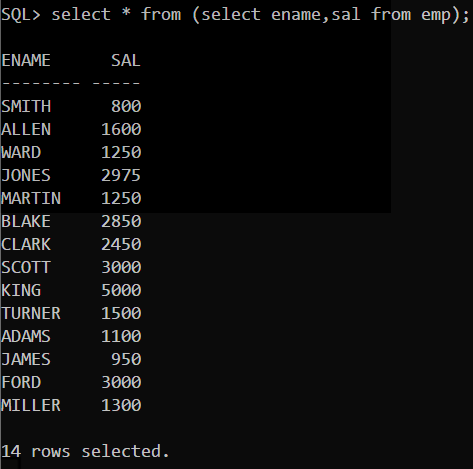
利用在FROM关键字后加上子查询可以在现有查询条件的基础上增加更多的查询条件
子查询类型

单行子查询
- 只返回一行记录
- 使用单行比较操作符
![]()
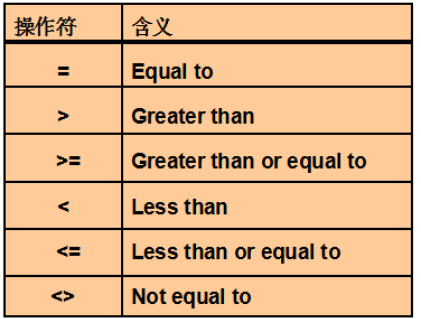
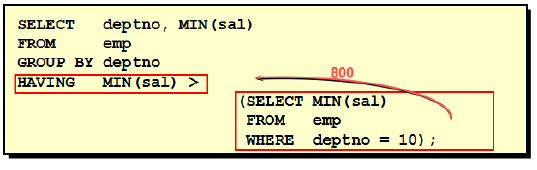
在子查询中使用组函数


在HAVING子句后使用子查询中
- 首先执行子查询。
- 向主查询中的HAVING子句返回结果
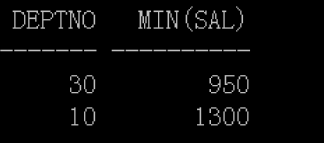
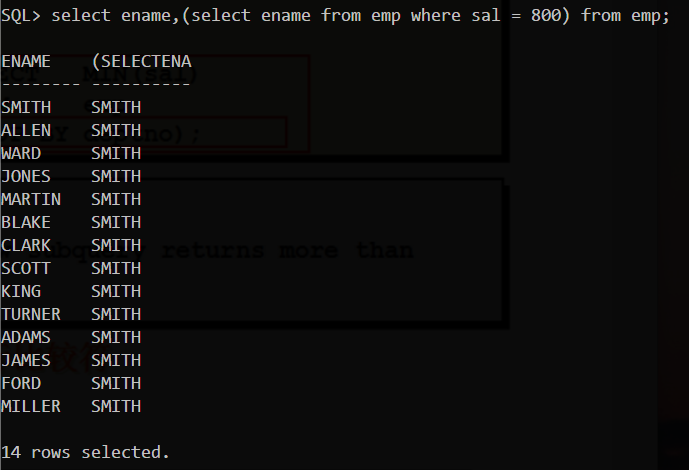
在SELECT关键字后使用单行子查询
非法使用单行子查询
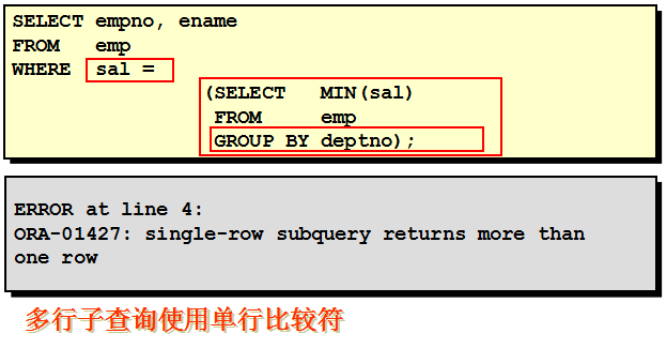
单行子查询中的空值问题

多行子查询
- 返回多行记录
- 使用多行比较操作符
![]()
- 若使用NOT IN操作符,则表中不能有空值,若有空值,则查询将返回空值
- 若一定要使用NOT IN操作符,需要手动使用is not null来过滤掉空值记录
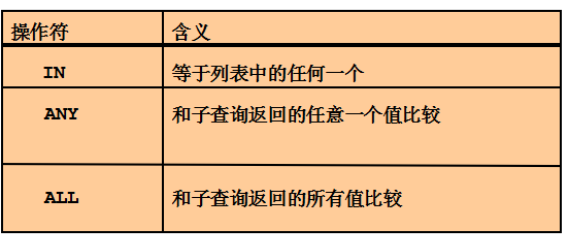
在多行子查询中使用ANY操作符

查询SALES部门和ACCOUNTING部门的员工信息
两种方式:
1.使用ANY关键字
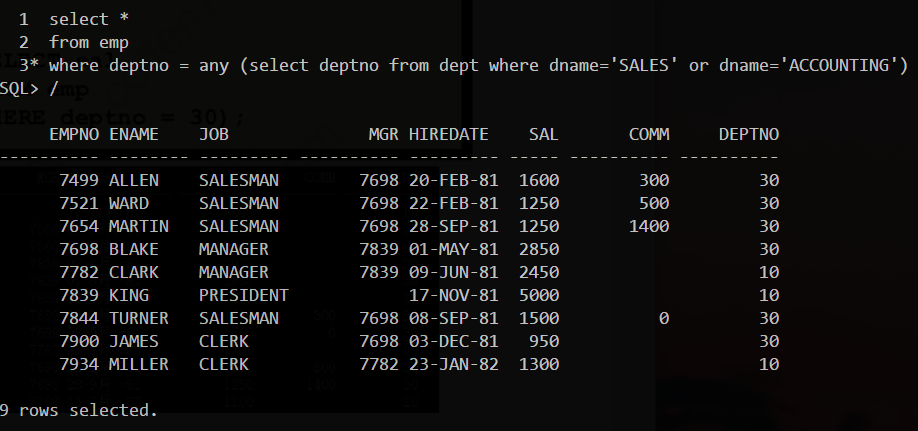
2.使用IN关键字,可知"IN"相当于"= ANY"
在多行子查询中使用ALL操作符

多行子查询中的空值问题

正确解决方法如下
集合运算
语法示例:
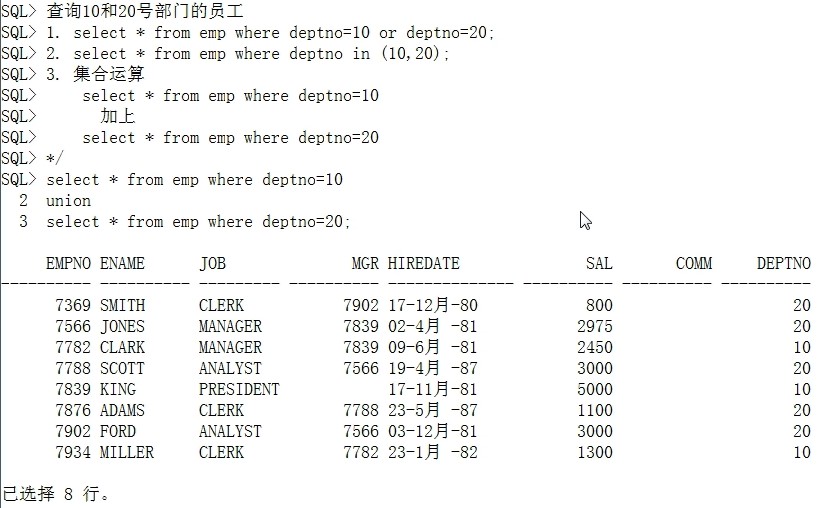
集合运算符
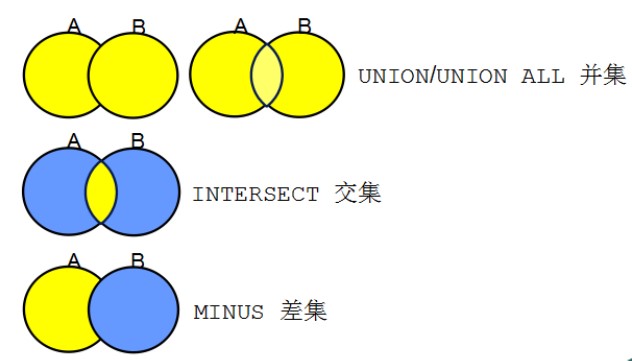
并集
UNION

UINON ALL
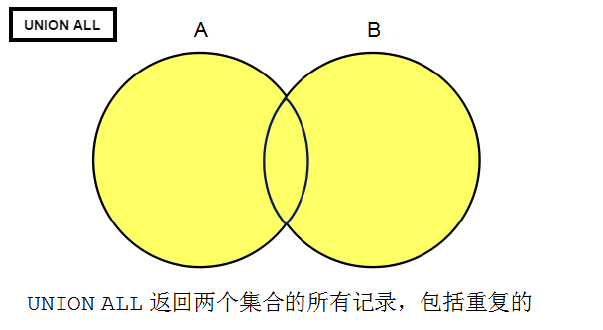
交集
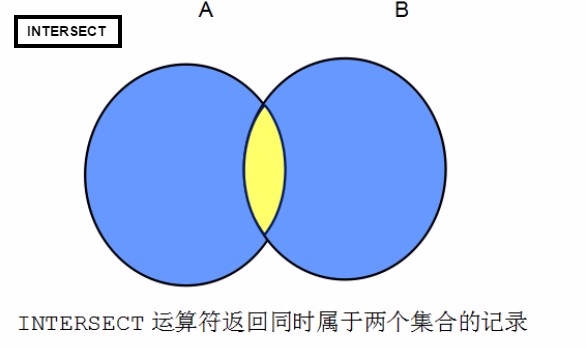
差集
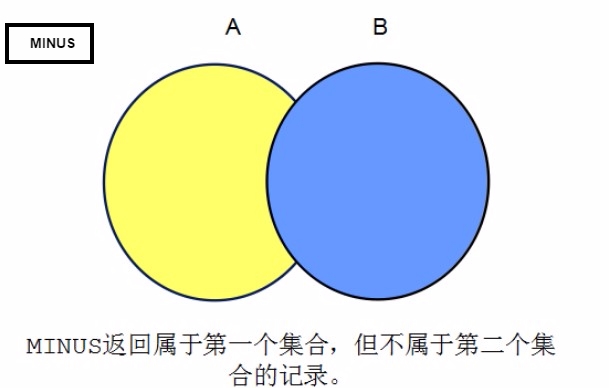
集合运算中的注意事项
- select语句中参数类型和个数(即列的个数)要一致
- 若不一致,一般可以按需要补上类型一样的空值来符合这个语法
- 可以使用括号改变集合执行的顺序
- 如果有order by子句,必须放到最后一句查询语句后
- 集合运算采用第一个语句的表头作为表头
- 若要给列定义别名,在第一个表的查询语句中定义
Oracle查询拓展内容
SQL语句的优化要点
- 尽量使用列名来查询(用select 列名1,列名2,... 来代替select *)
- where 条件1 and 条件2,应该把经常返回假的条件放在右边
- 因为where解析顺序是从右到左,若有一个为假则全为假(相当与Java的&&)
- 同理,where 条件1 or 条件2,应该把经常返回真的条件放在右边
- 当使用where子句或having子句都可以得到结果时,尽量使用where子句来完成查询
- 因为where是先筛选后分组,having是先分组后筛选(对不必要的数据进行了分组)
- 当子查询和多表查询可以得到相同的结果时,尽量使用多表查询
- 因为子查询会访问两(多)次数据库
- 实际上Oracle中使用子查询语句很多时候会被Oracle自动转换成多表查询
- 尽量不要使用集合运算,参与集合的查询越多,耗费性能越严重
若需要查看SQL执行的时间,可以使用"set timing on"命令来打开显示执行时间的配置,"set timing off"关闭

关于空值
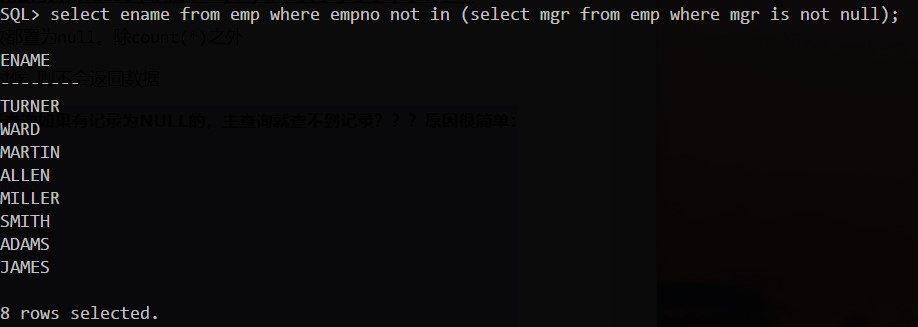
判断一个值是否为空值(null)不能直接使用逻辑运算符,而应该使用is not null/is null关键字,详细内容自查网络博客
- 如果null参与算术运算,则该算术表达式的值为null(例如:+,-,*,/ 加减乘除)
- 如果null参与比较运算,则结果无论如何将为false(例如:>=,<=,<> 大于,小于,不等于)
- 如果null参与聚集运算,则聚集函数都置为null。除count(*)之外
- 如果在not in子查询中有null值的时候,则不会返回数据
![]()

SQL执行计划
例题
TOP-N问题
如:
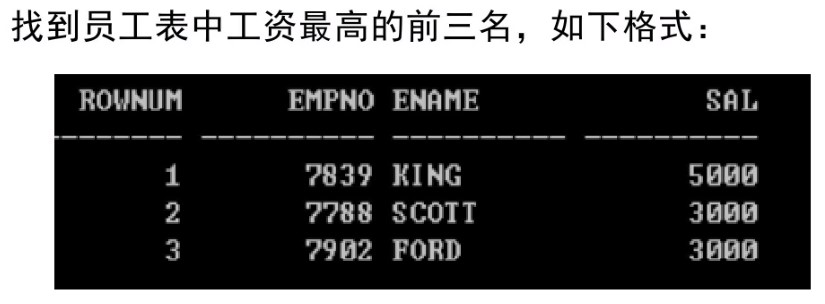
解:
按照工资排序,使用ROWNUM(行号)伪列来只查询前三个
因为子查询的结果相当于一张表,再对已经这张排序的表进行查询就可以按照sal来排序行号了
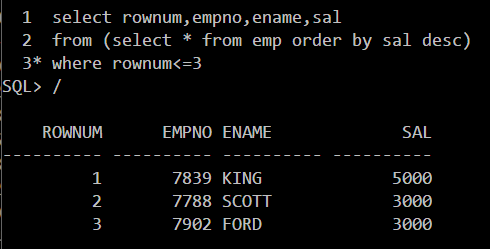
关于ROWNUM行号的要点
- 行号永远按照默认的顺序生成
- 关于行号的默认排序
- Oracle中有三种表:标准表、索引表和临时表
- 临时表可以被手动创建,也可以被Oracle自动创建
- 当查询语句中有排序操作时,会创建临时表作为排序后的表来显示,故(子)查询其实相当于创建了一张新的表
- 当事务或会话结束的时候,表和表中的数据自动删除
- 关于行号的过滤条件只能使用"<"、"<=",不可以使用">"、">="
- 那么分页就需要在外面嵌套一个外查询并在其中中定义分页条件了
- 如:需要查询行号为5到8的数据
![]()
- 此时r不再是行号伪列,而是子查询中的”真列“,故不需要在意不可以使用大于条件这条规则了、

相关子查询
- 将主查询的值作为参数传递给子查询
如:
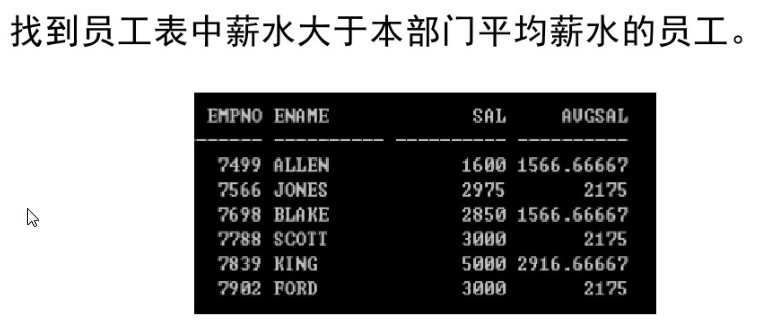
解1:这种方法没有使用相关子查询
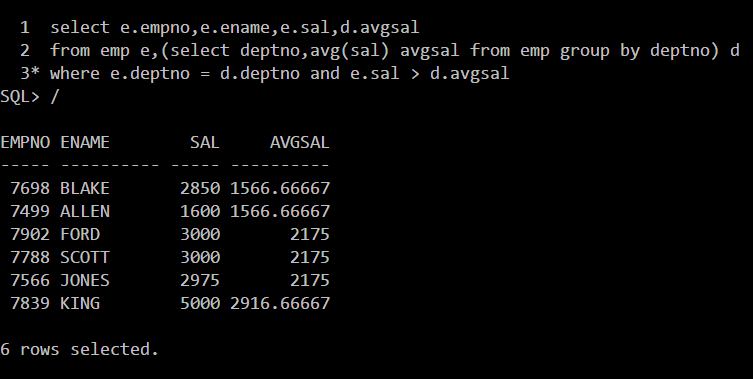
关键在于将子查询看作是一张表,为其定义别名并添加部门号相等的条件
解2:使用相关子查询,且注意用子查询结果作为列
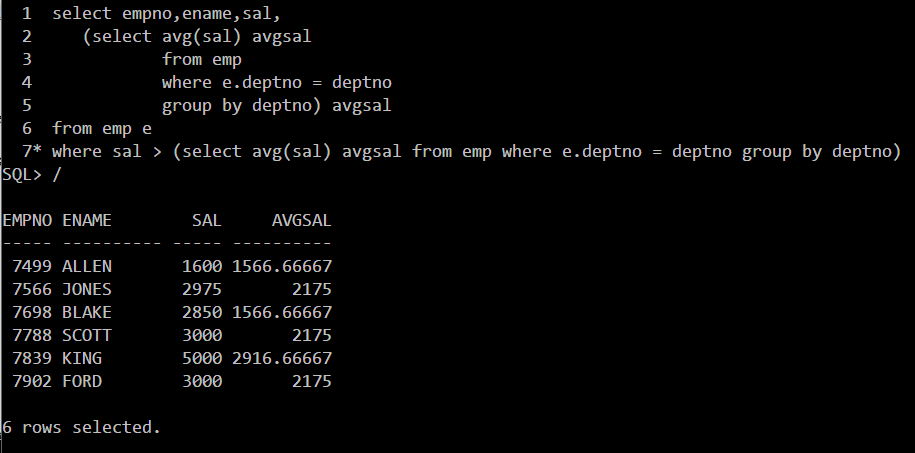
行转列
多行函数wm_concat(varchar2)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号