第3部分:关系数据库管理系统原理part1
题型:选择题、填空题、算法题、分析题分值:约35%
第7章:数据库存储
要求准确掌握基本概念和基本原理
存储介质:存储介质的分类
-
(主存储器、⼆级存储器、三级存储器、易失存储器、⾮易失存储器)

主存储器:
-
字节寻址,高速缓存,内存寄存器,CPU直接访问

二级存储器
-
磁盘、硬盘 按块寻址、cpu不能直接访问、联机使用

三级存储器
-
磁盘光盘 可以脱机使用、按块寻址、通过二级存储器才能访问

数据传输速度和大小对比

易失性存储器与非易失性存储器

非易失性内存

磁盘的块与组成部分
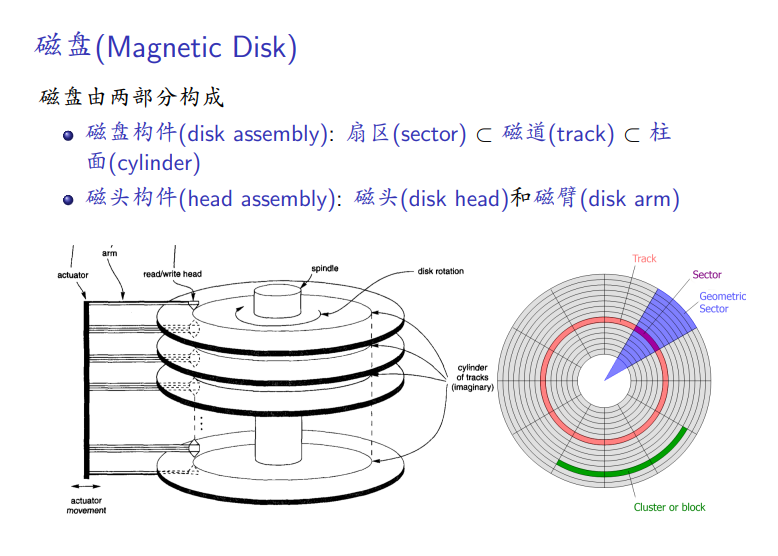

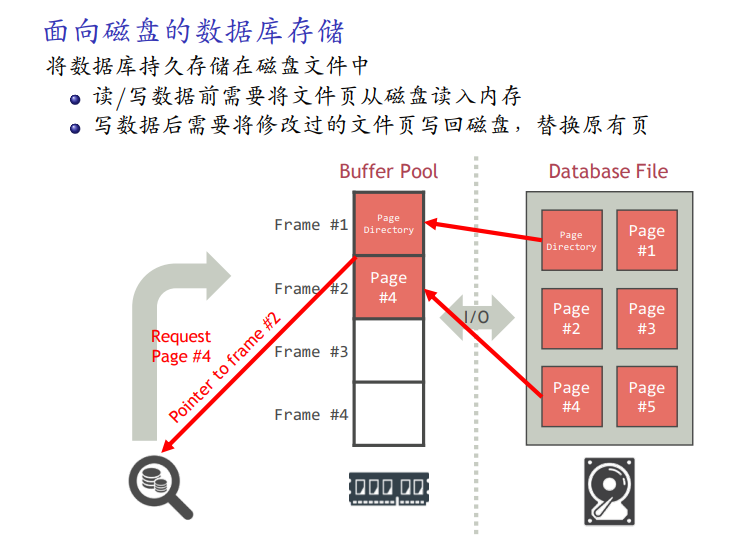
基于磁盘的数据库存储结构:
-
内容:属性值的表示、元组的表示、⻚的布局、⽂件的组织
-
磁盘能永久存储,所以用磁盘存数据库;文件以文件页构成;需要将磁盘中把页读到内存中。
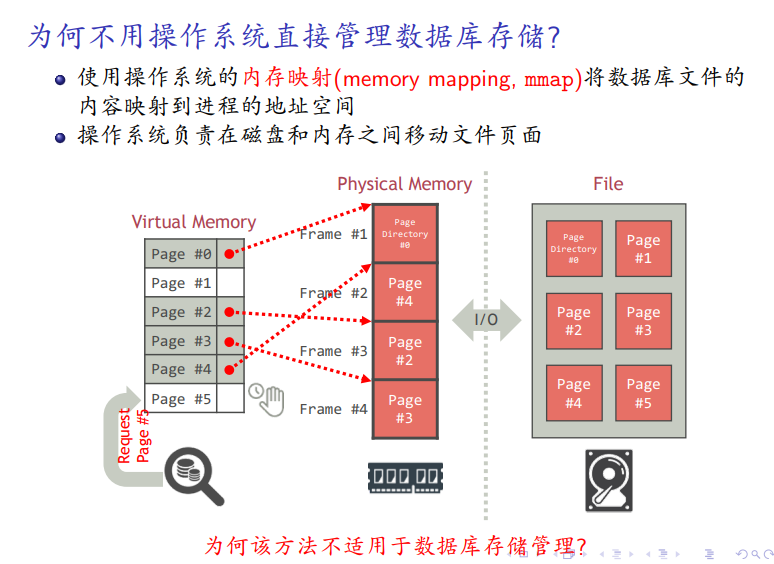
-
将内存映射到虚拟内存中,无法控制操作系统如何调度,所以不能用操作系统管理
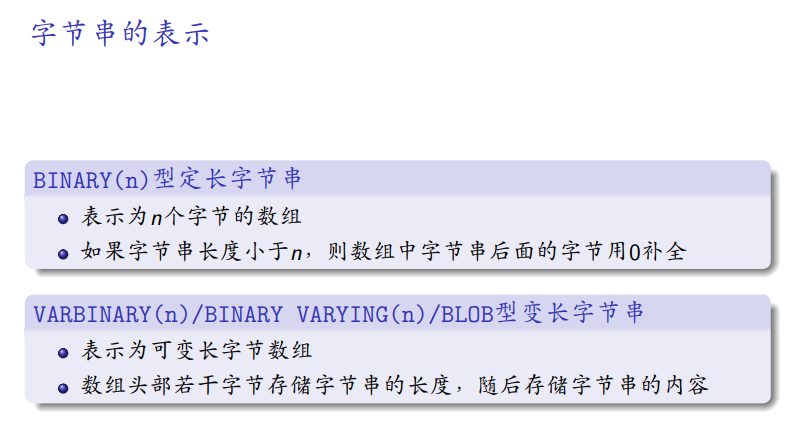
属性值的表示
数的表示

字符串的表示:按字符限定

字符串的表示:按字节限定
-
四种字符串的区别:https://www.bbsmax.com/A/A2dmQ9Lgde/
元组的表示

元组头
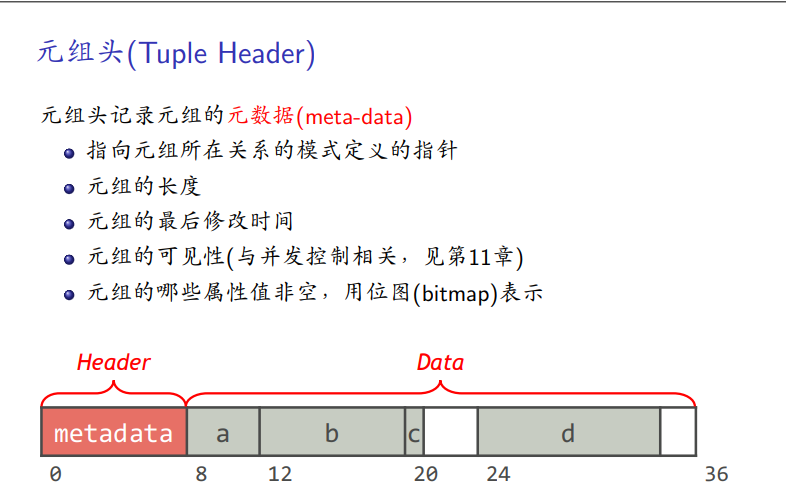
元组数据:4字节对齐
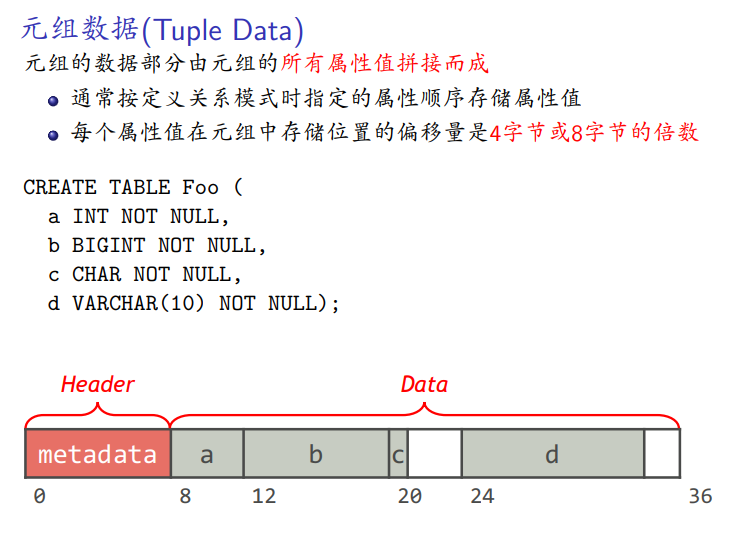
变长元组的布局:放两端
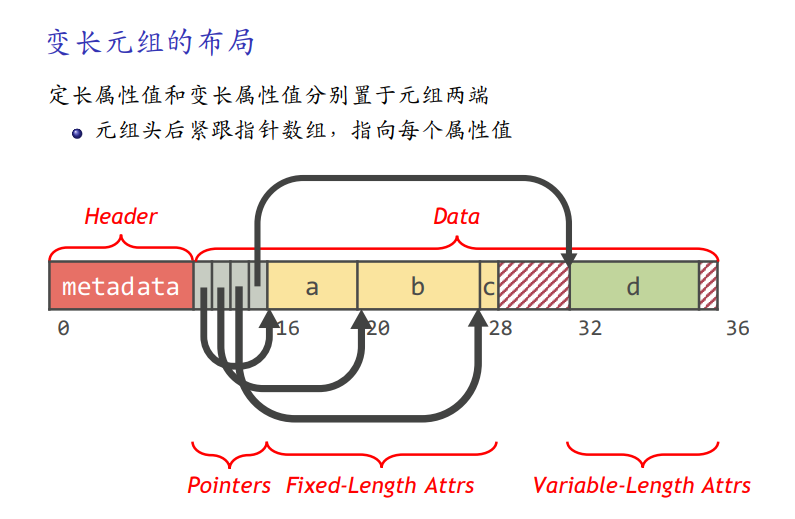
页的布局
页头
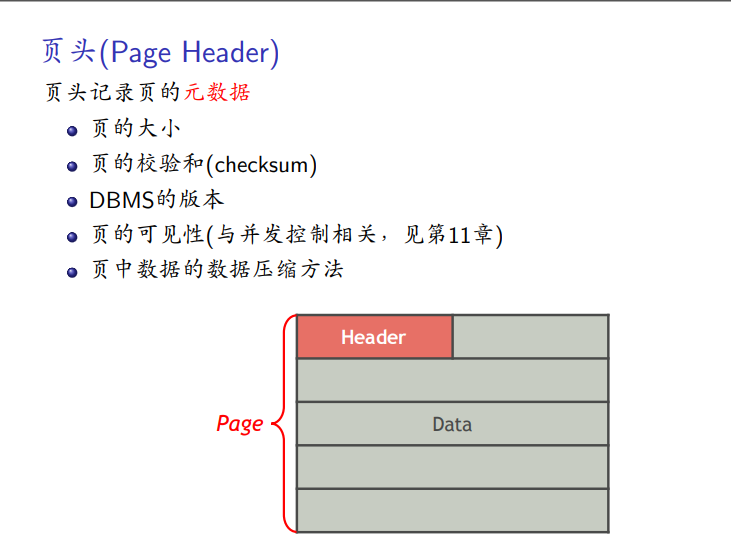
页数据:面向元组和面向日志
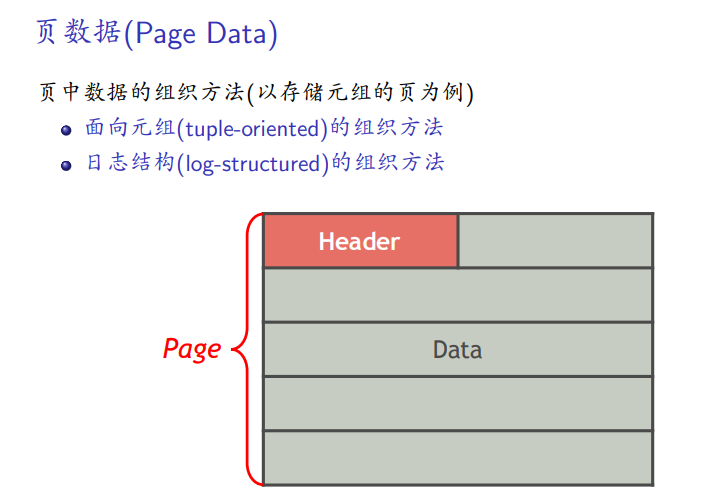
面向元组数据组织
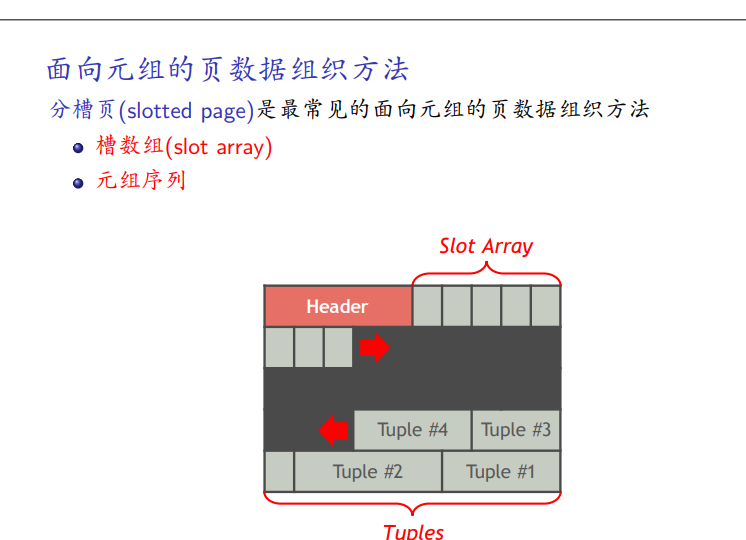
分槽页
-
尾部放元组(一个槽,字节对齐)
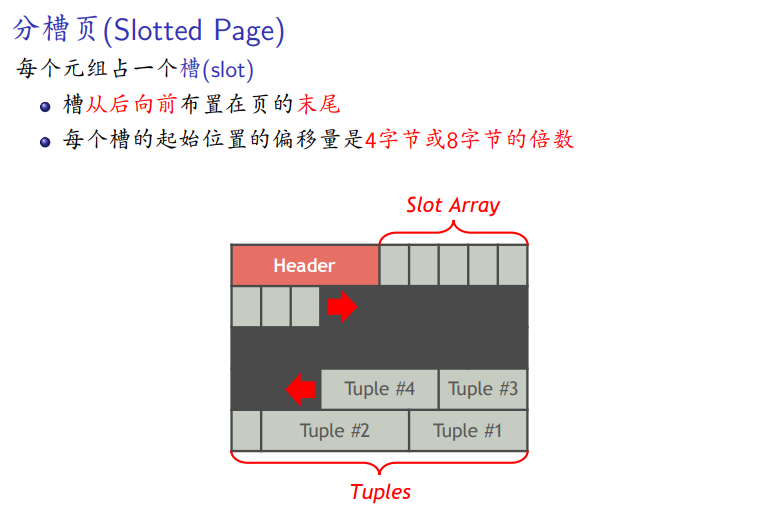
-
页头后放起始位置的偏移
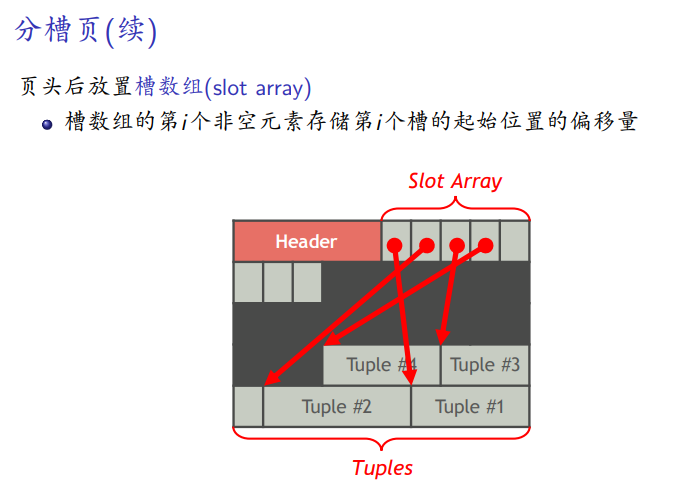
页头中的元数据
-
最后一个槽的起始位置的偏移量因为是倒叙,就是新元组插入的位置。
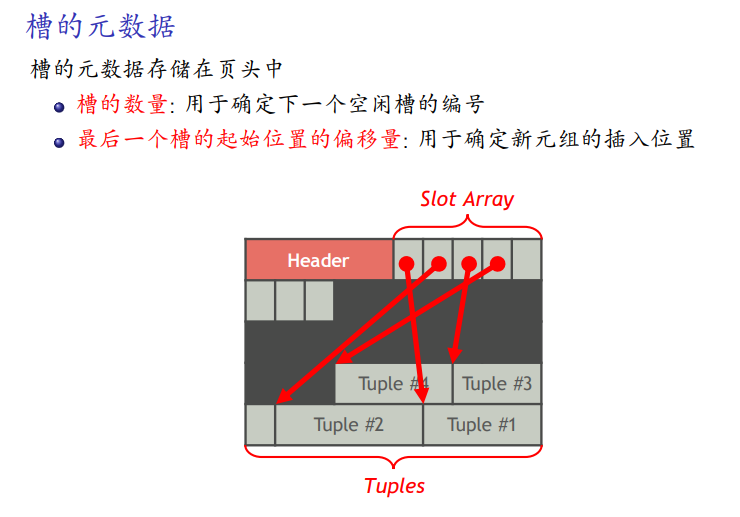
记录号

溢出页

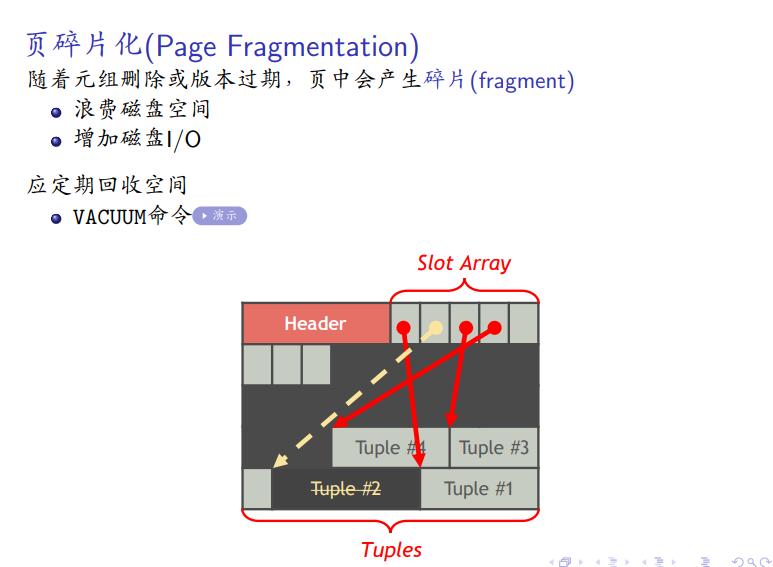
碎片化
日志结构页的布局

日志记录

读元组:
-
从后往前找记录,然后重建即可

日志索引
-
帮助更快的读

日志记录的合并

文件组织
分类

堆文件组织
-
任意顺序存储,链表和页目录两种组织方法

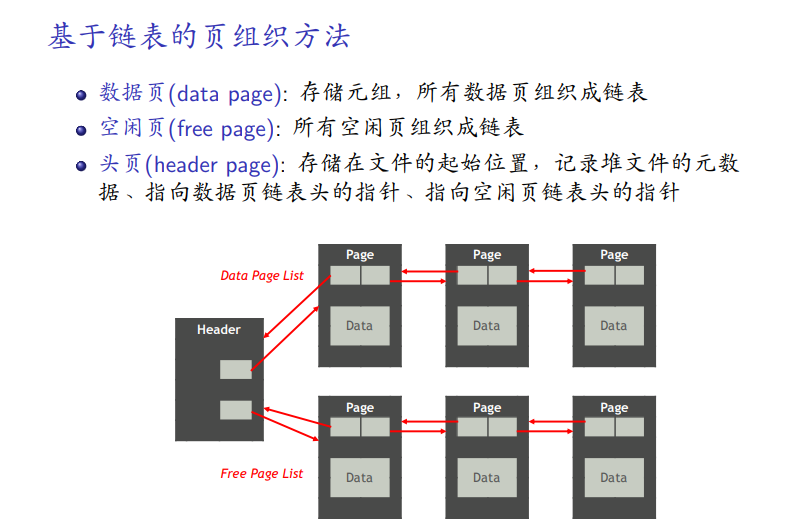
基于链表的组织
-
头页两个指针,分别指向空闲的和有数据的
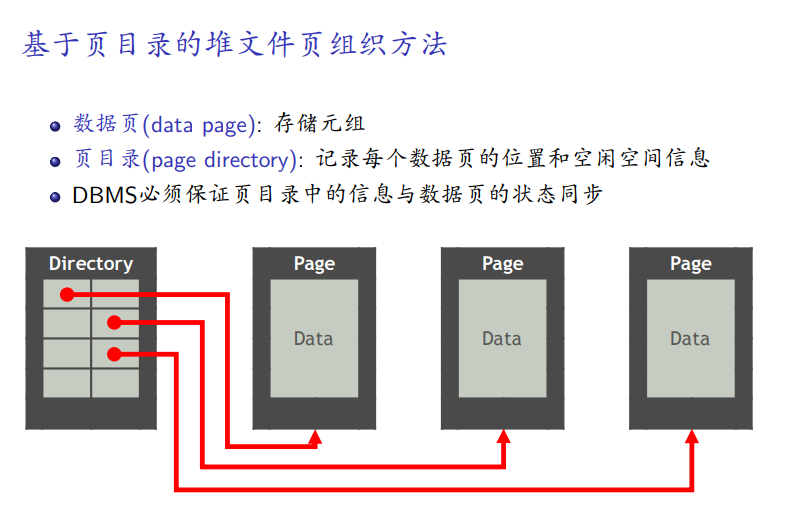
基于页目录的组织
-
记录 页的位置和是否空闲
顺序文件组织
-
插入如果不符合顺序,需要将后面所有的元组往后挪位置,很慢,适用于排序键是主键的存储
哈希文件组织
-
利用哈希函数

缓冲区管理:
-
内容:缓冲池的结构、⻚请求、⻚释放、⻚替换策略
-
cpu借助缓冲区与磁盘中数据交互
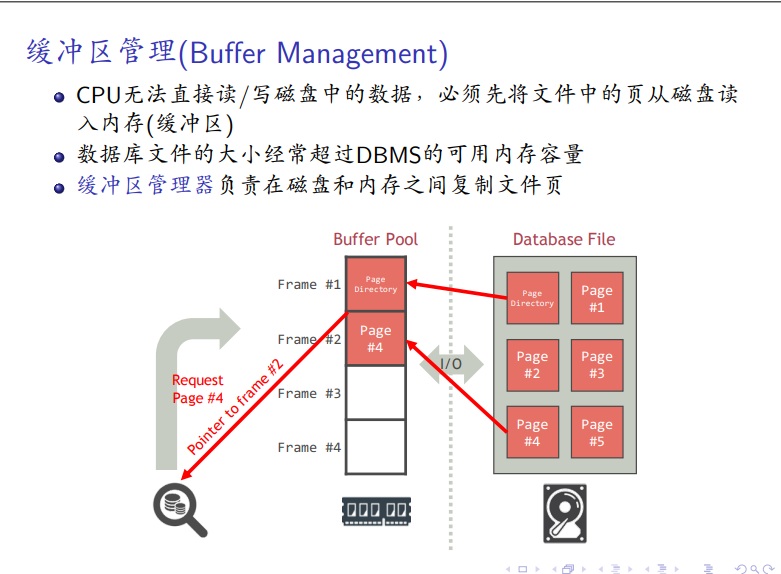
缓冲池的结构
-
内存区域分页
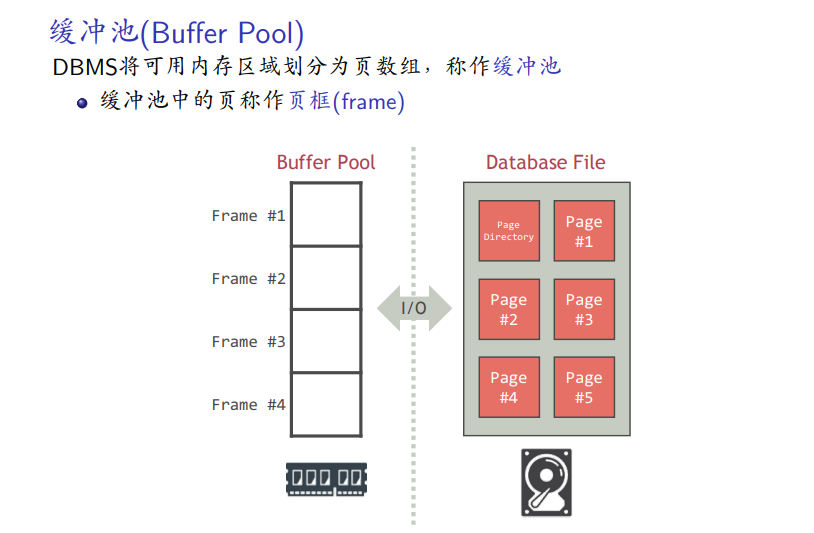
页表
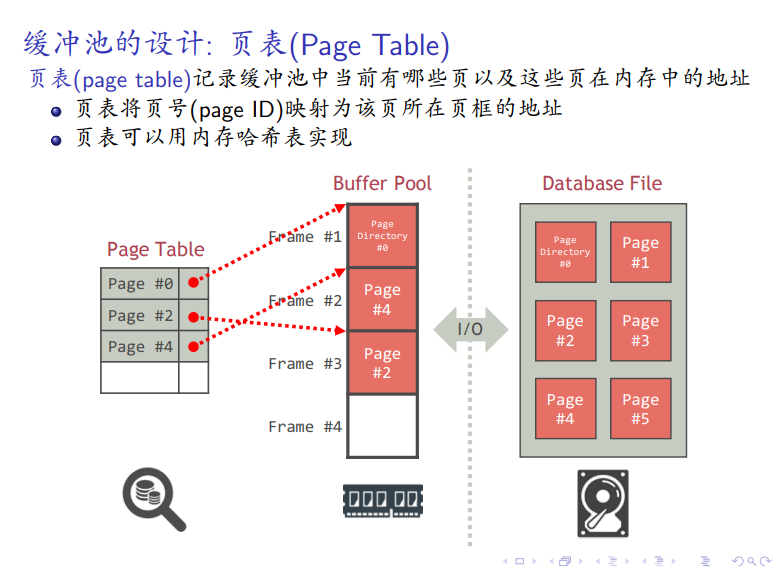
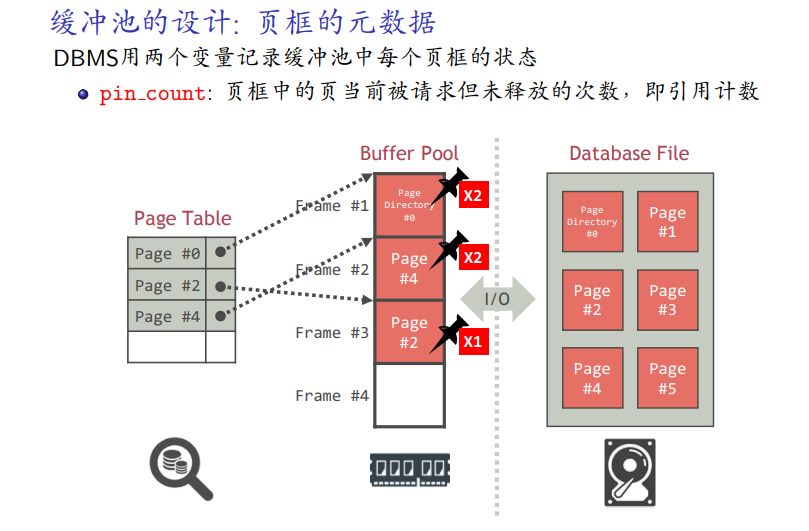
页框中的元数据(基本数据)
-
pincount 表示当前引用的计数
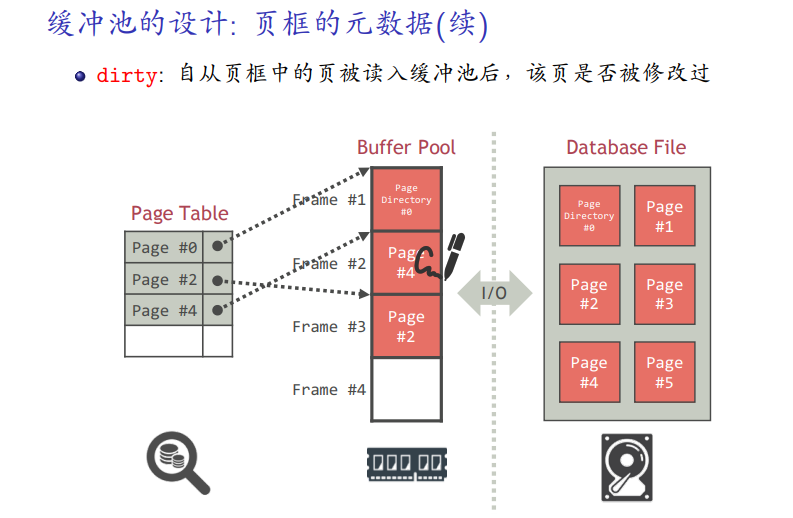
-
表示是否被修改过
页的功能:请求修改和释放

页请求
-
有则pincount+1
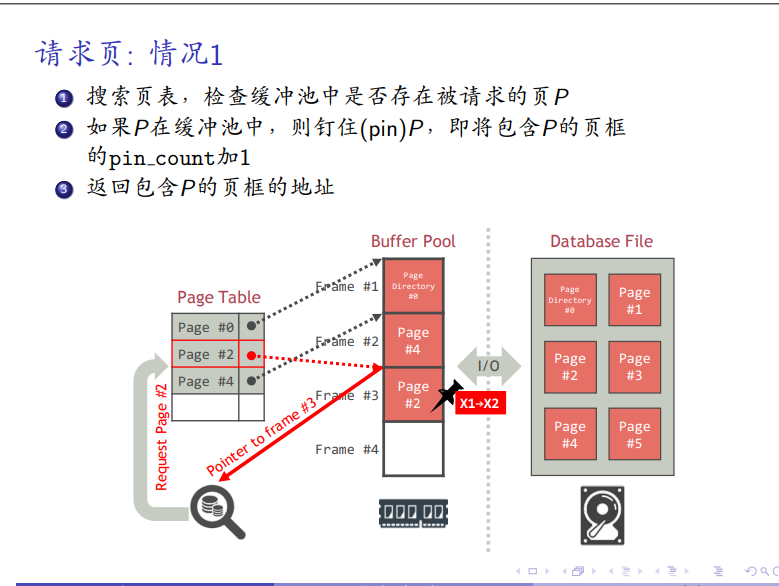
-
没有则选择一个pin_count=0的页框,脏页写回,否则直接读入需要的页,并将pin_count=1

-
没有pin_count=0,则需要等待,或者直接abort,防止死锁
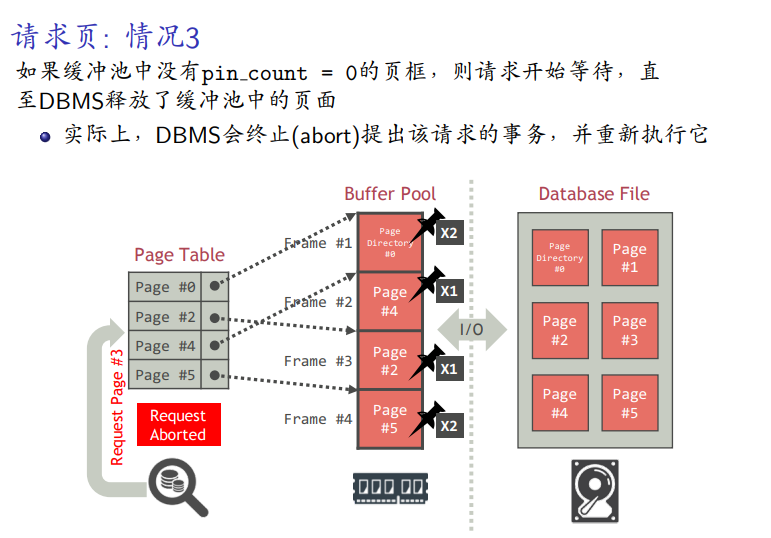
页的释放
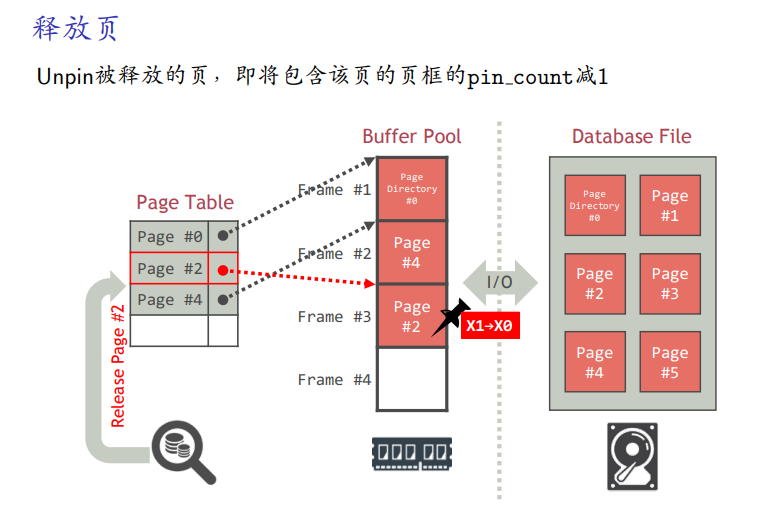
页的修改
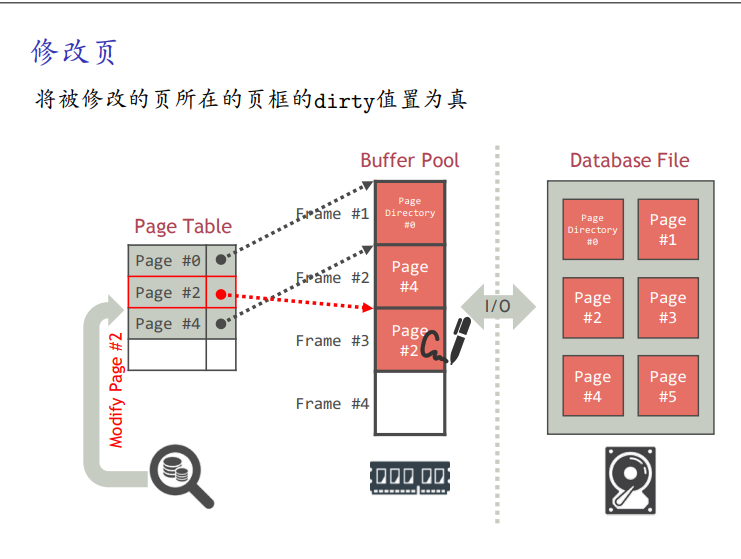
页替换策略
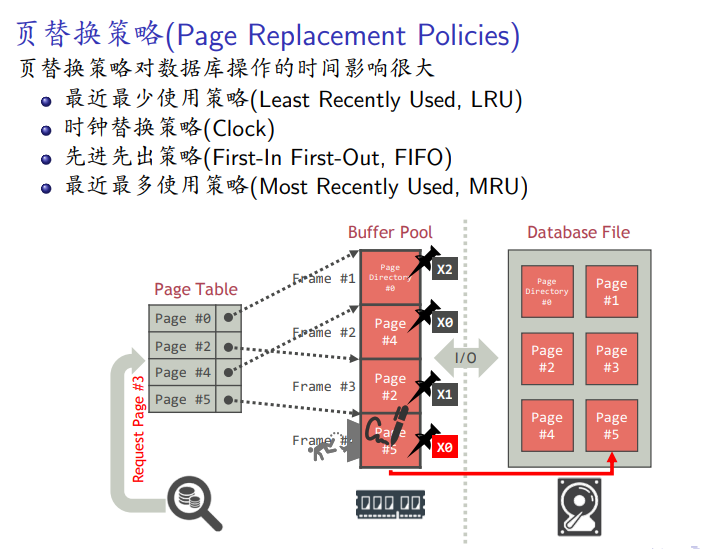
最近最少使用策略
-
效率不高
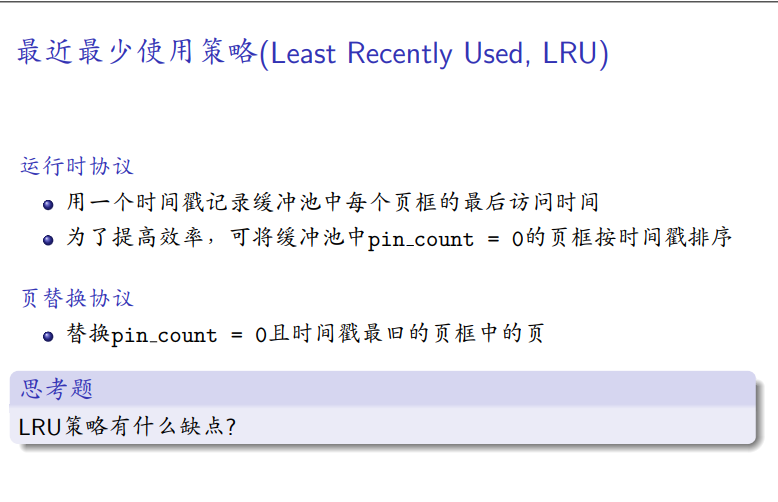
时钟替换策略
-
LRU的近似,这样做选择了一个较长时间没有访问的表
-
reference bit读入或者访问时赋值为1
-
扫过为1赋值为0,否则进行替换

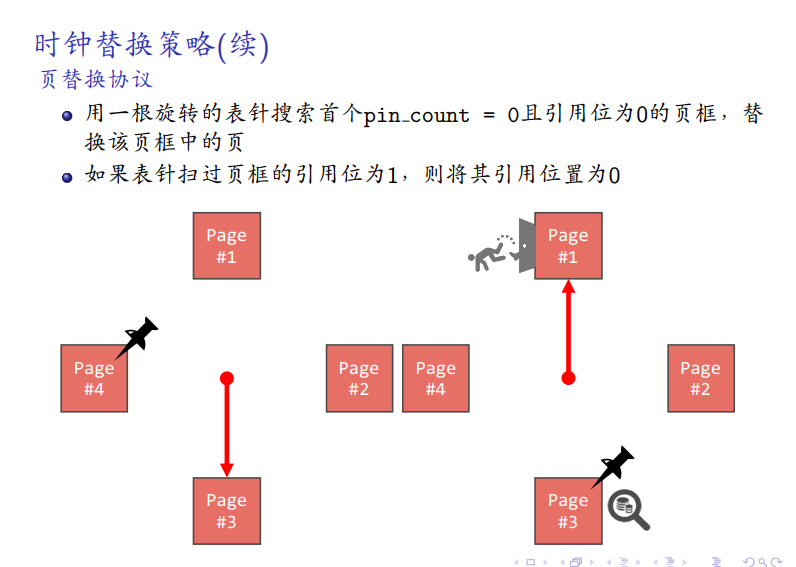
预取
-
提前取
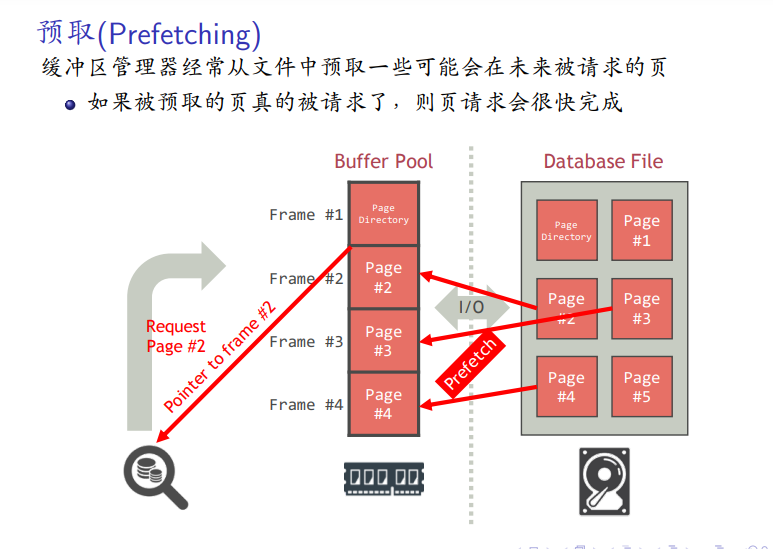
缓冲池和虚拟内存的比较
-
dbms预测更准确

-
强制写回

第8章:索引结构
要求准确掌握基本概念熟练运⽤可扩展哈希表、线性哈希表、B+树的操作算法
外存哈希表的分类
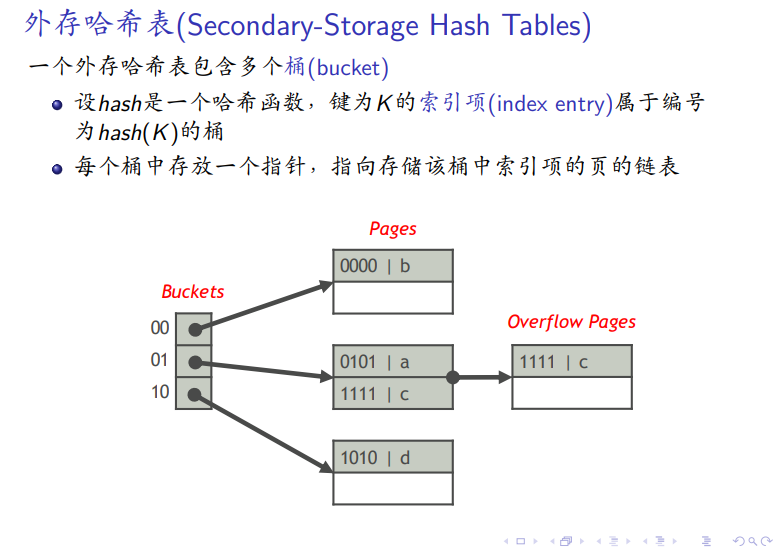
可扩展哈希表:
-
数据结构、查找索引项的算法、插⼊索引项的算法
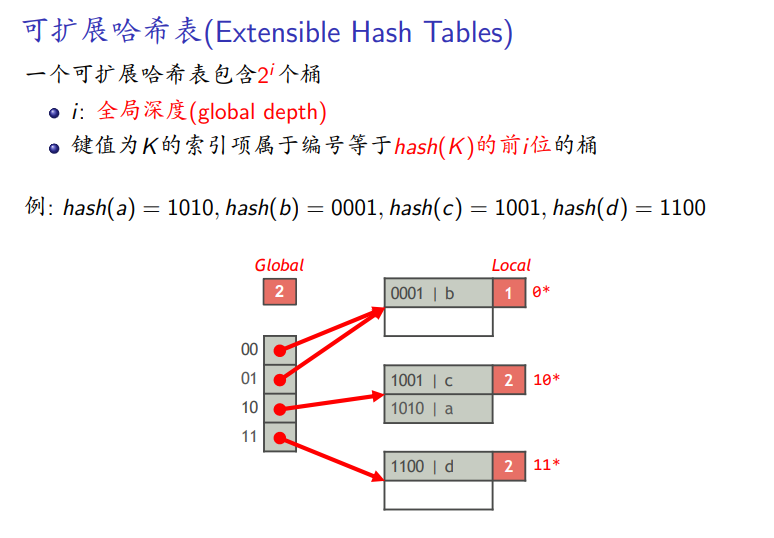
数据结构
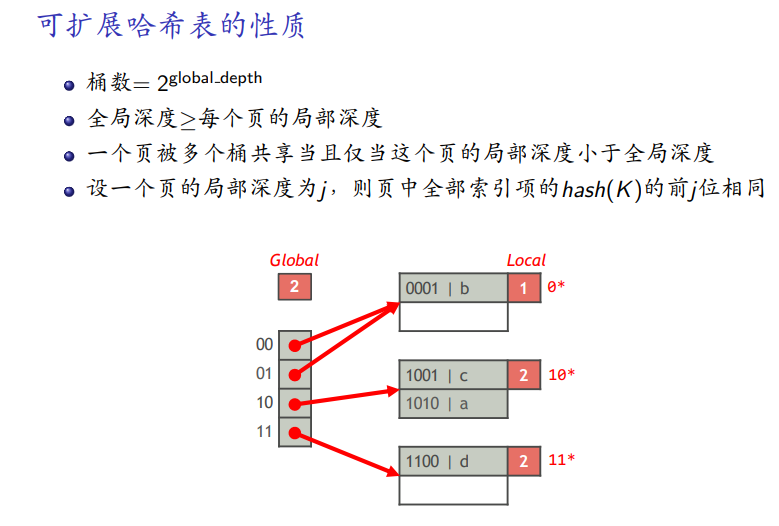
-
桶的个数是2的指数
-
指数幂i是全局深度
-
前i位相同的键值在一个桶中
-
没有溢出页
-
局部深度前j位在一个桶中
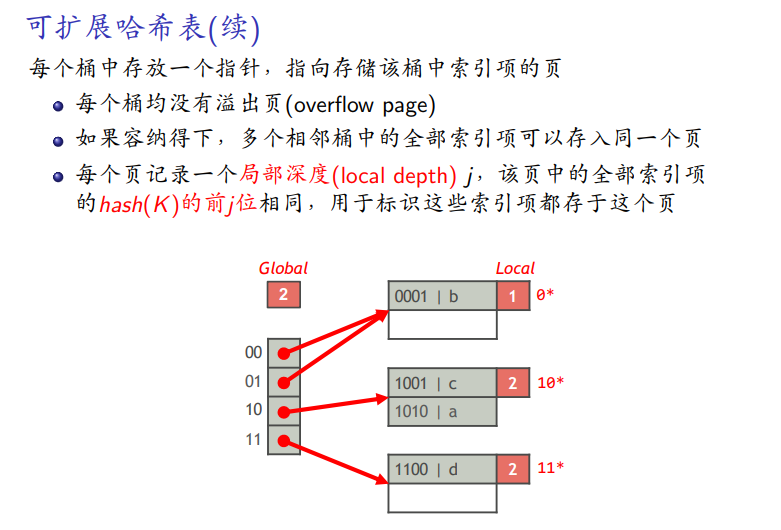
性质
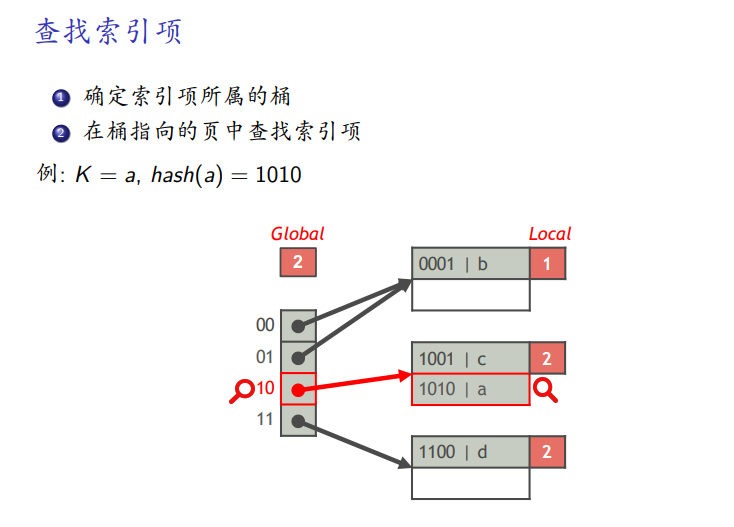
查找
-
通过全局深度确定在那个桶中
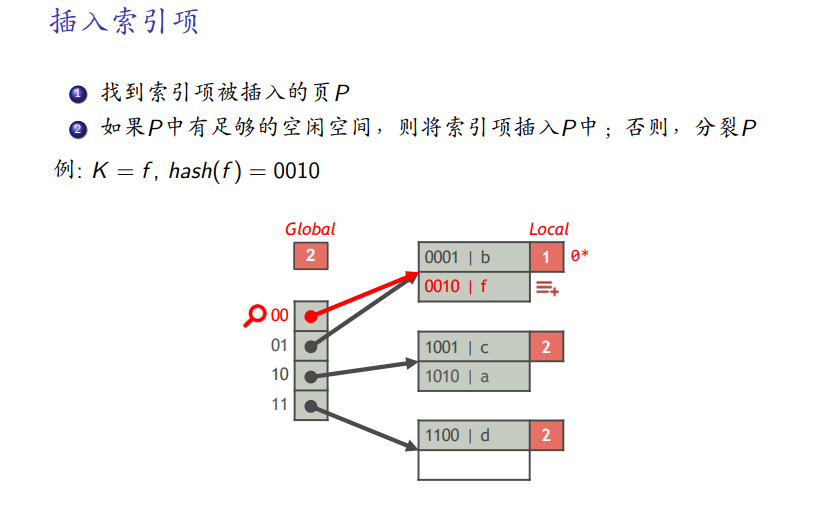
插入
-
页中有足够空间
-
没有足够空间且局部深度小于全局,局部表分裂
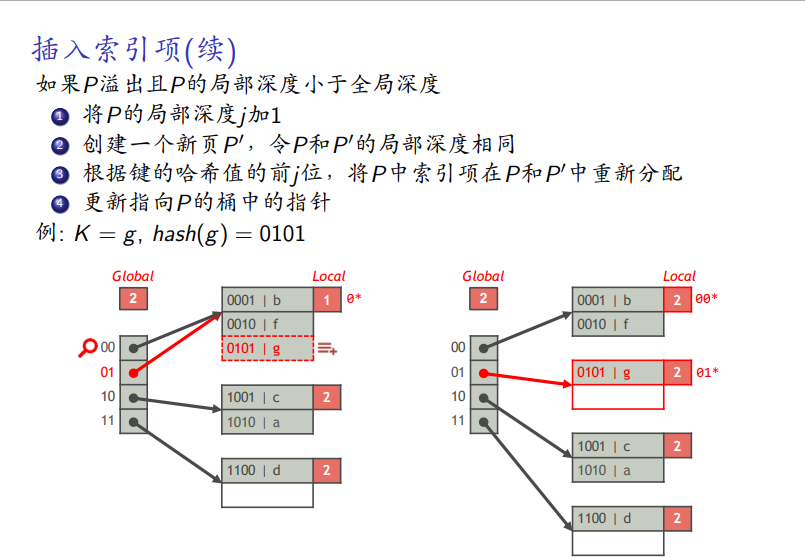
-
如果全局深度等于局部深度,全局表分裂
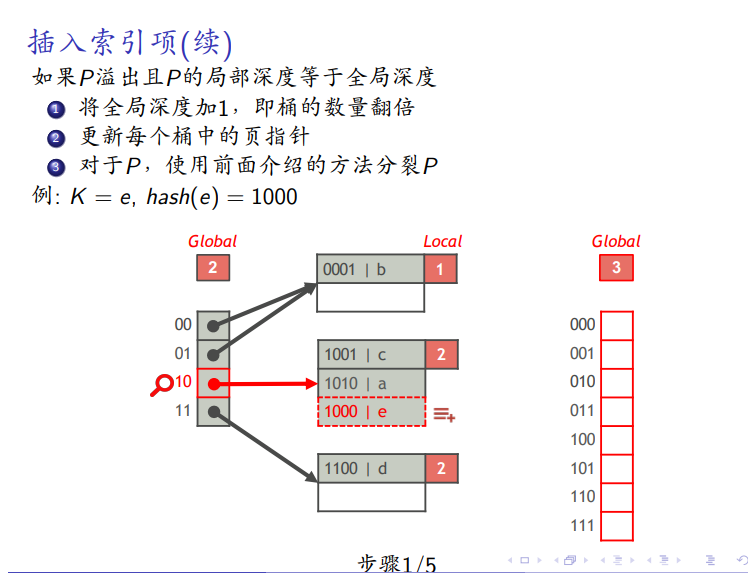
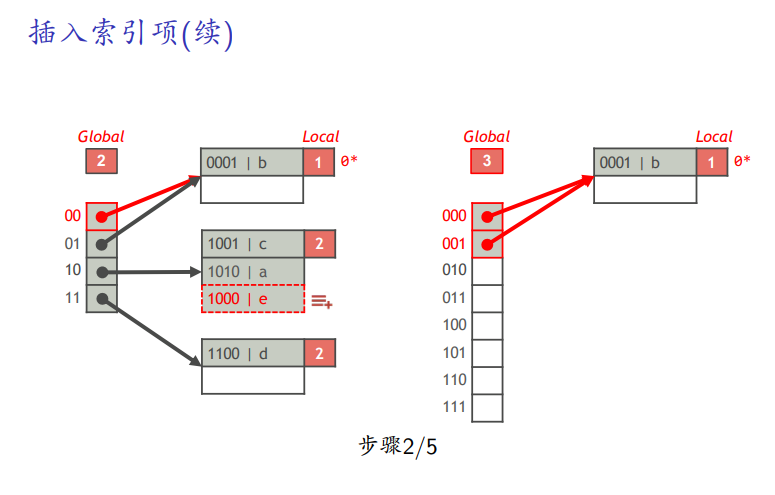
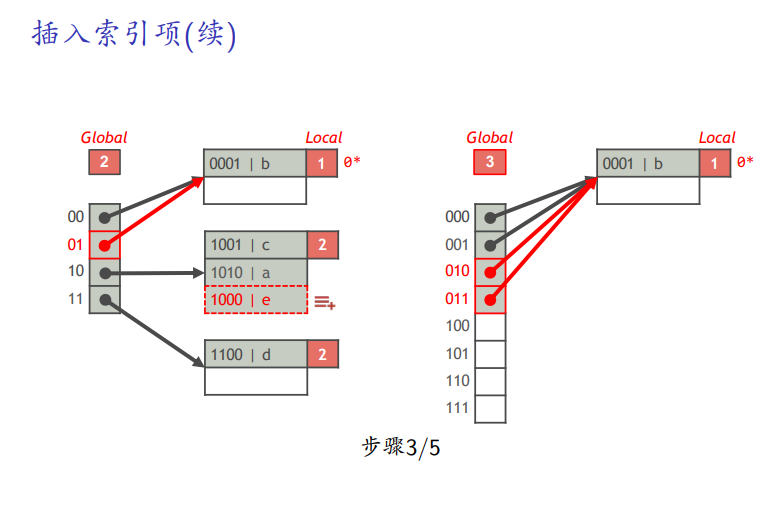
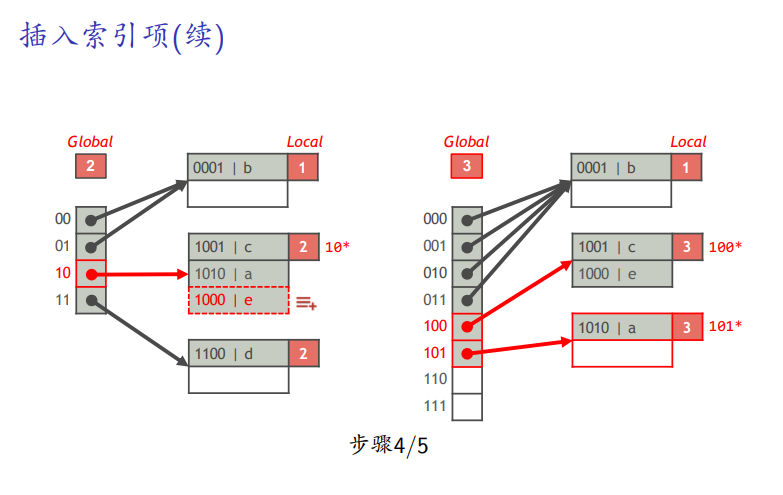
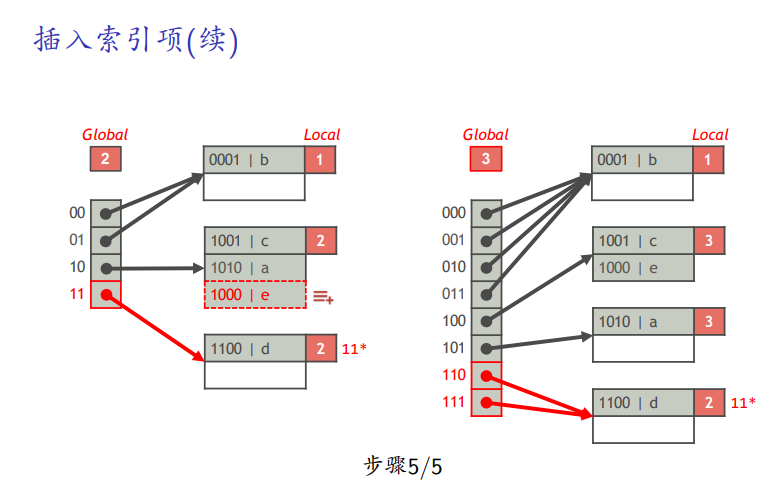
删除
-
直接找到后删除,不用合并,未来一般数据会以一个增加的趋势,合并有额外开销
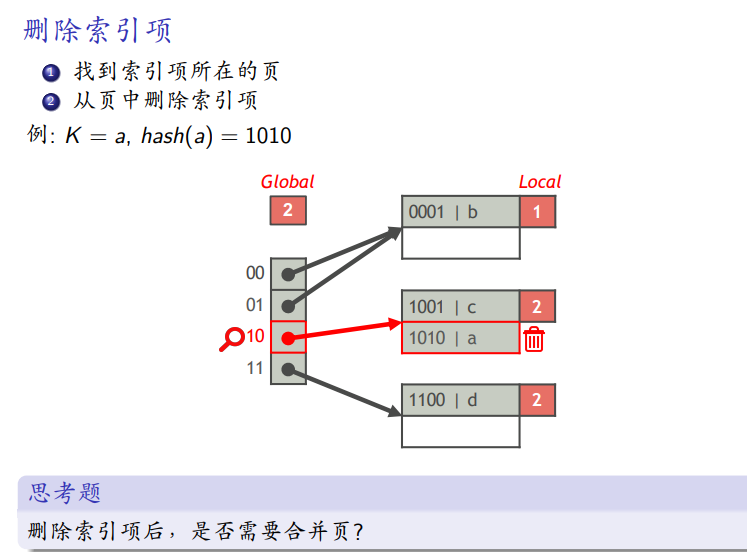
线性哈希表:
-
数据结构、查找索引项的算法、插⼊索引项的算法
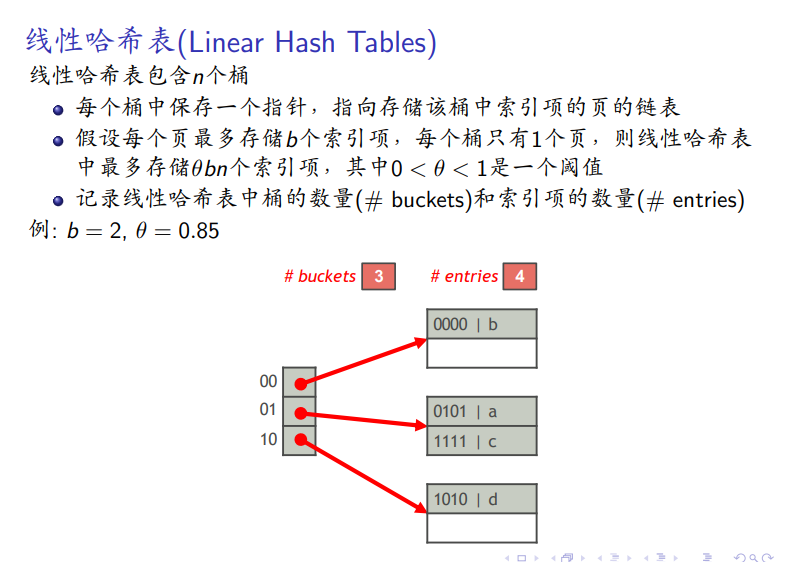
数据结构
-
b人为规定,n是桶的个数


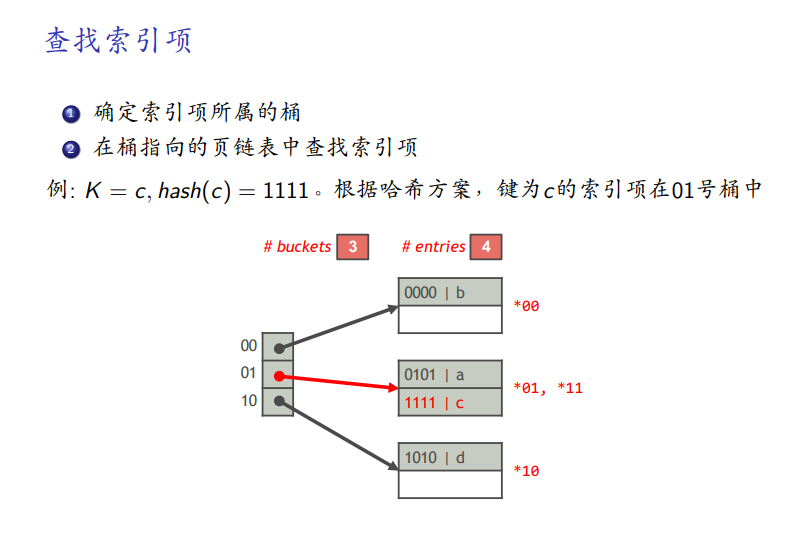
查找
插入
-
不超过负载因子,直接插入
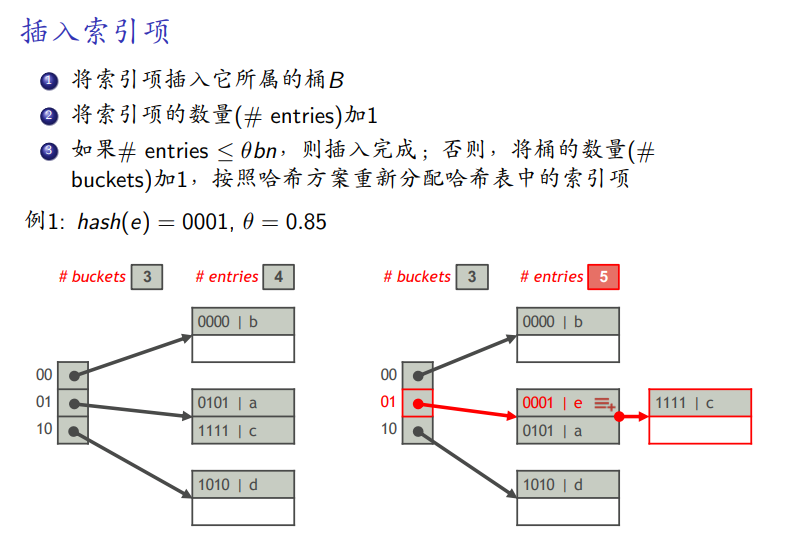
-
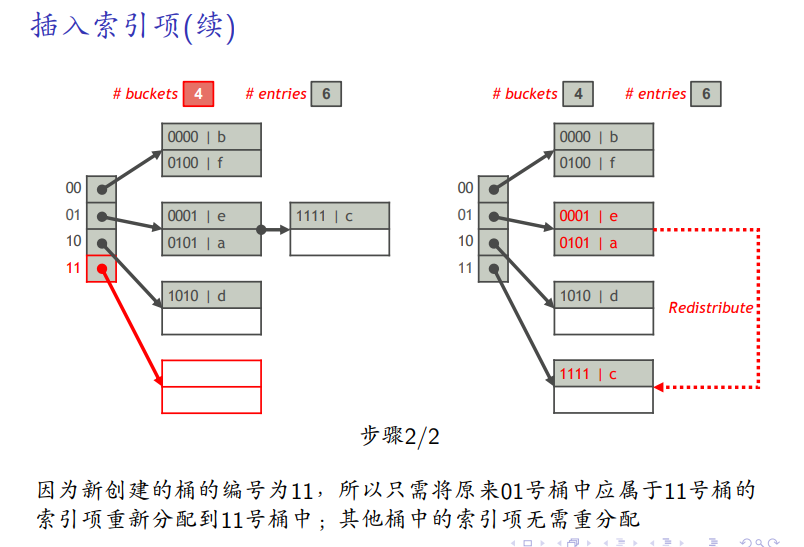
超过负载因子
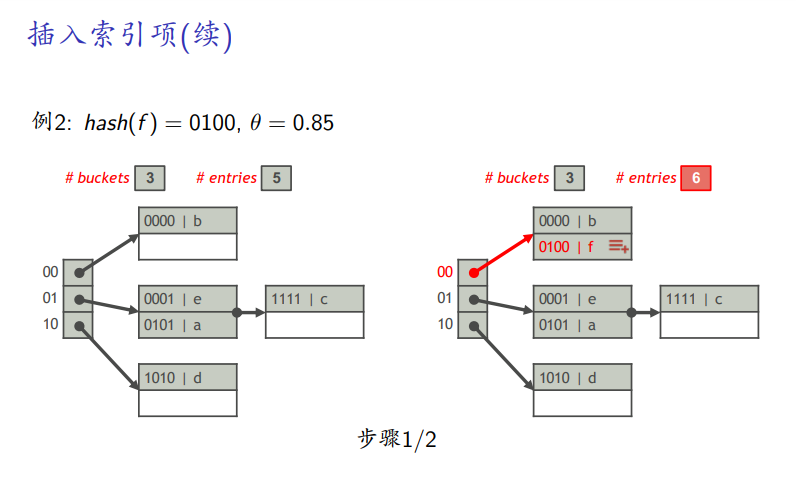
-
桶的数目正好是2的幂,相当于每个桶都是两个3位的局部深度,负载均衡了,随着桶的增加,新来的桶,会分担其它桶的局部深度,使之升为3,以此类推
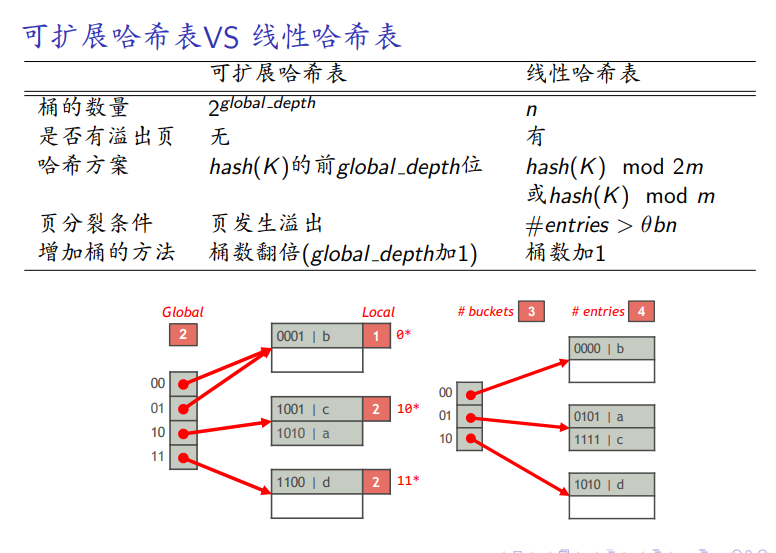
两种哈希表的对比
B+树:
-
数据结构、点查询算法、区间查询算法、插⼊索引项的算法、删除索引项的算法
数据结构
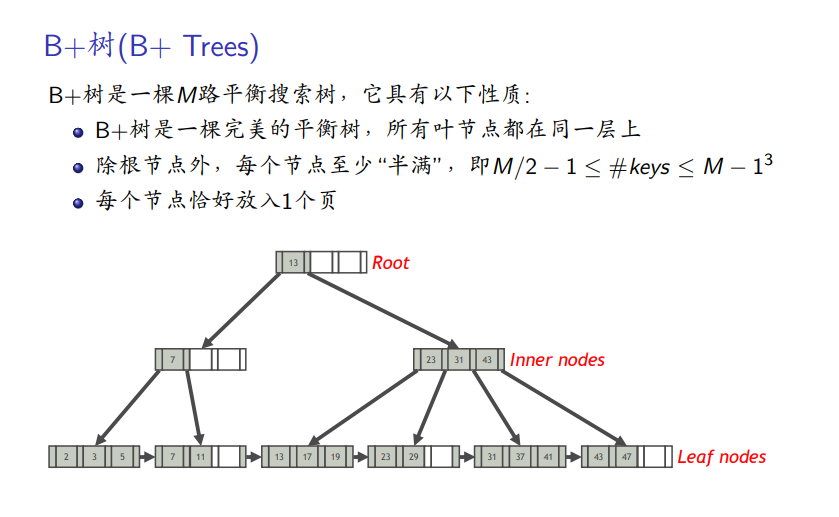
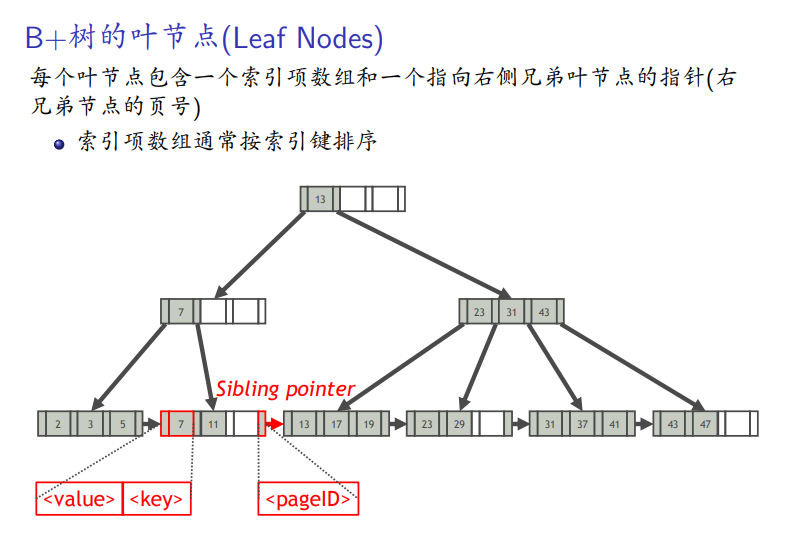
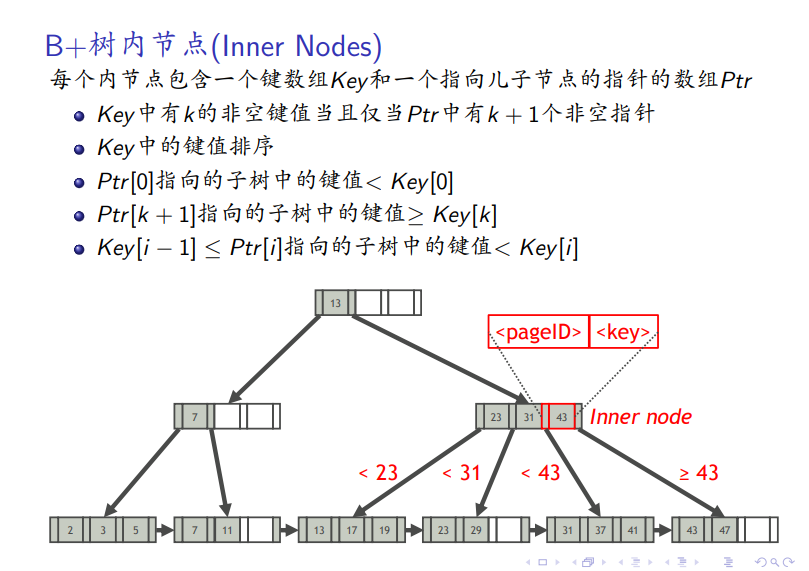
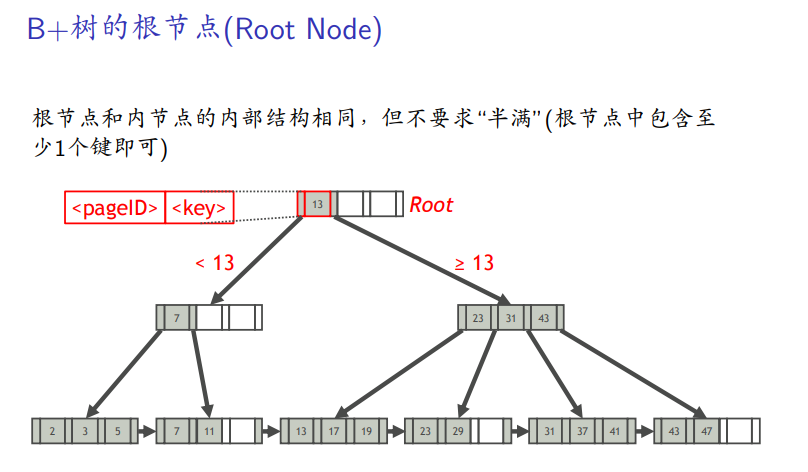
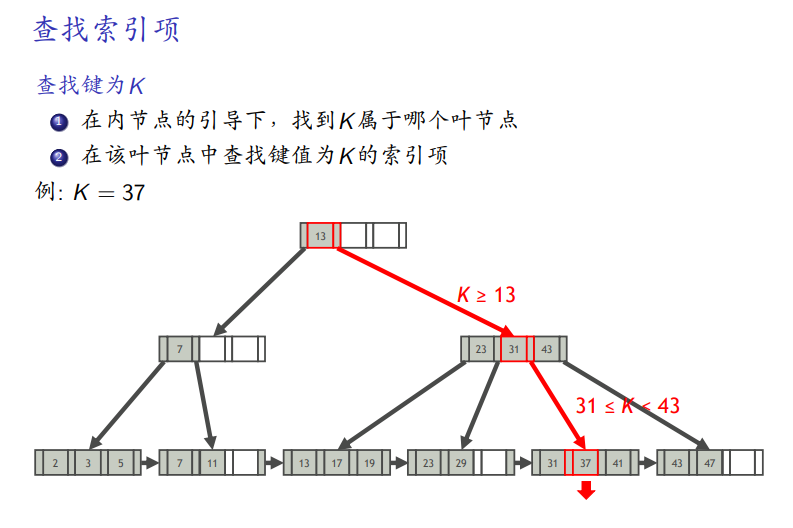
点对点查找
-
直接多分查找
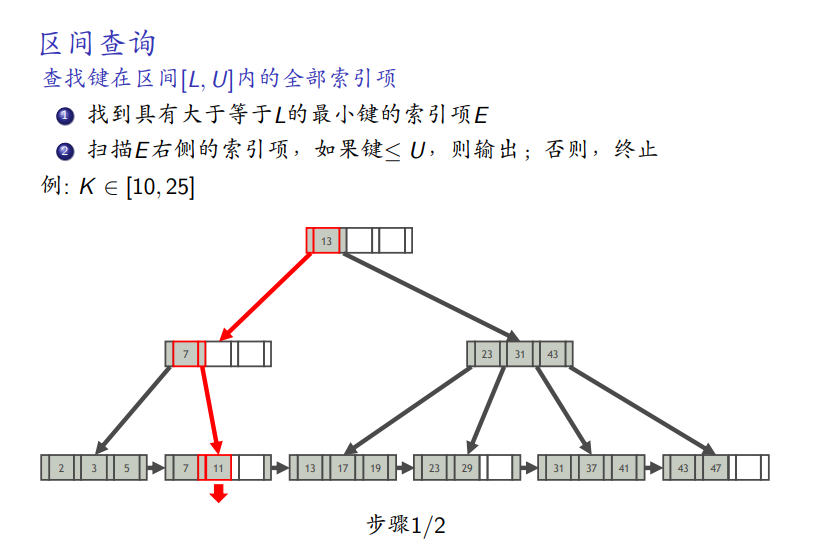
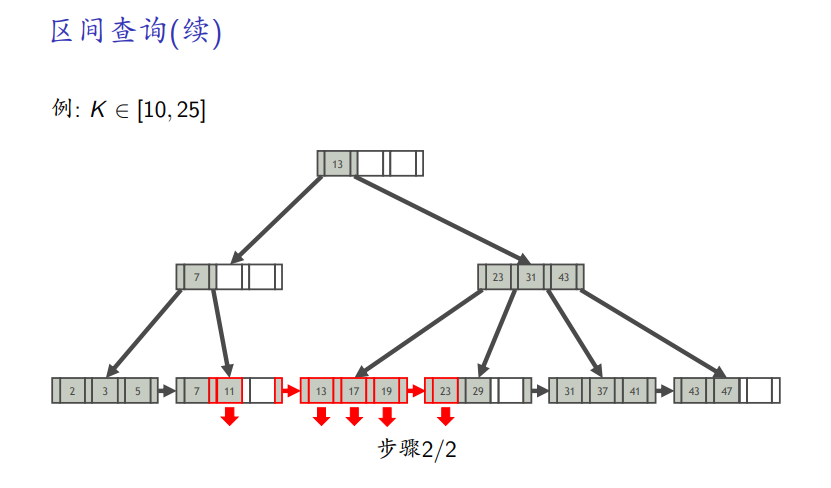
区间查询
-
找大于等于最小区间的第一个
-
一直向右搜索,直到找到小于最大区间的最大数为止
插入

叶节点分裂
-
先插入,若满了,则平分L,前一半放中,后一半放L2,L2的最小值作为中间键上如父亲节点

-
会有个多余的中间键向上传递

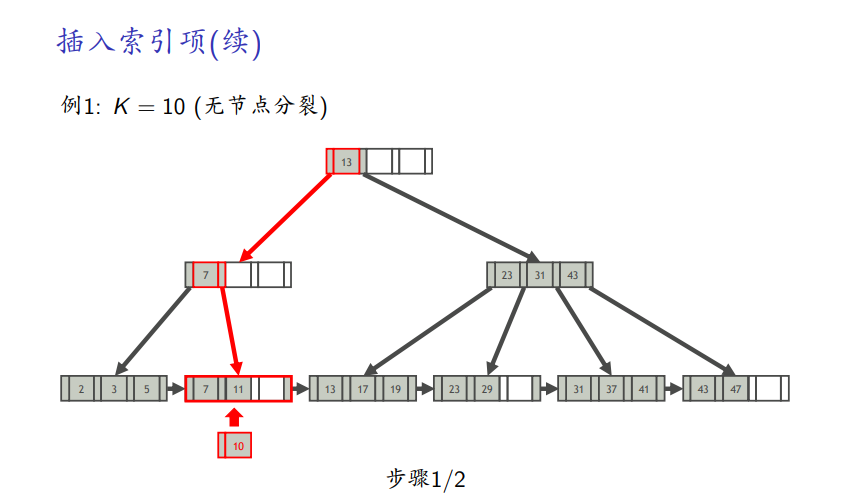
插入例子
-
无分裂情况
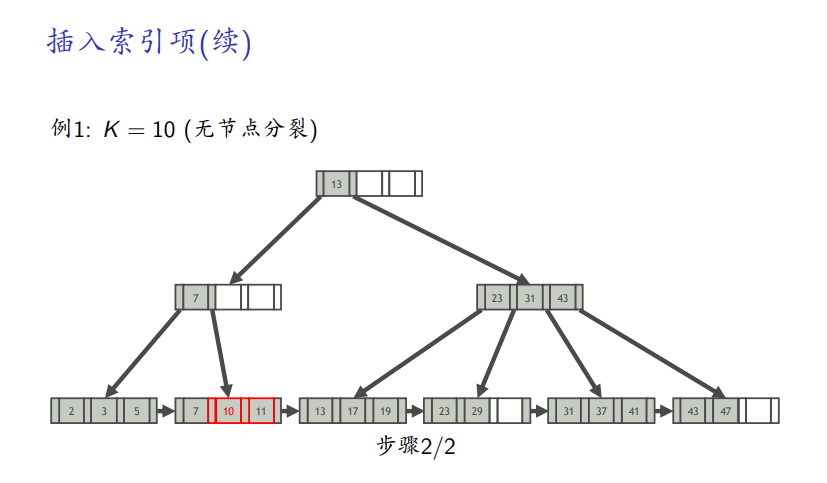
-
有分裂
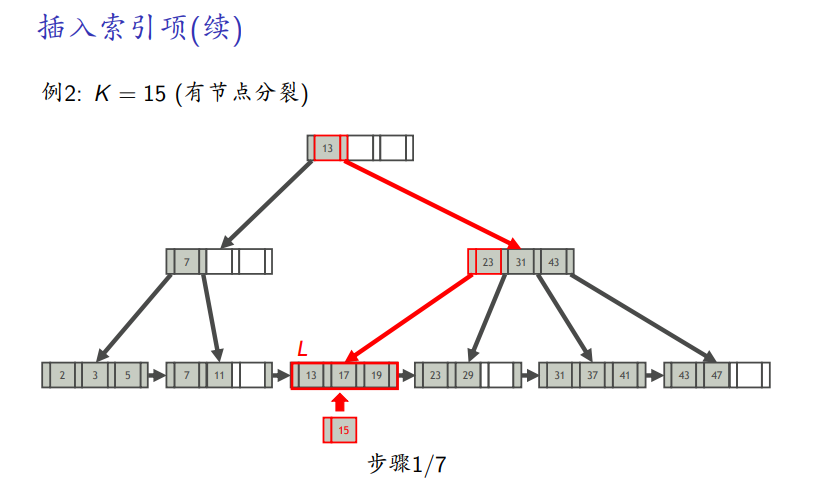
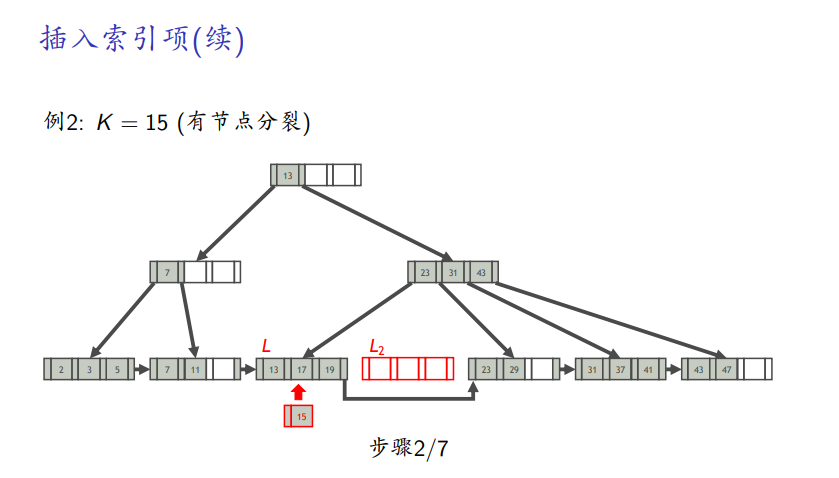
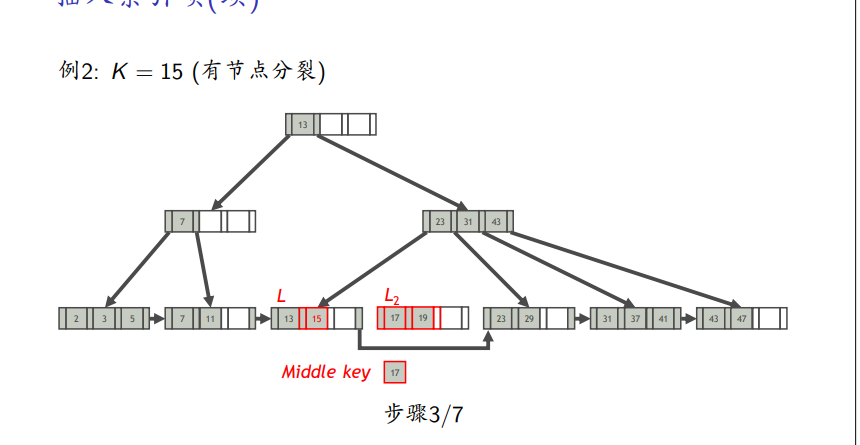
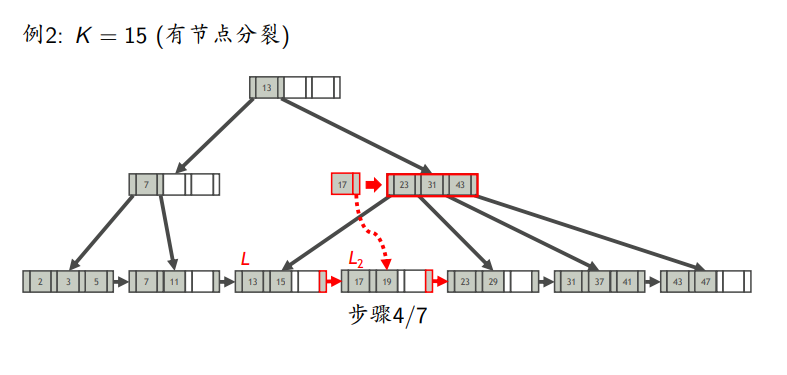
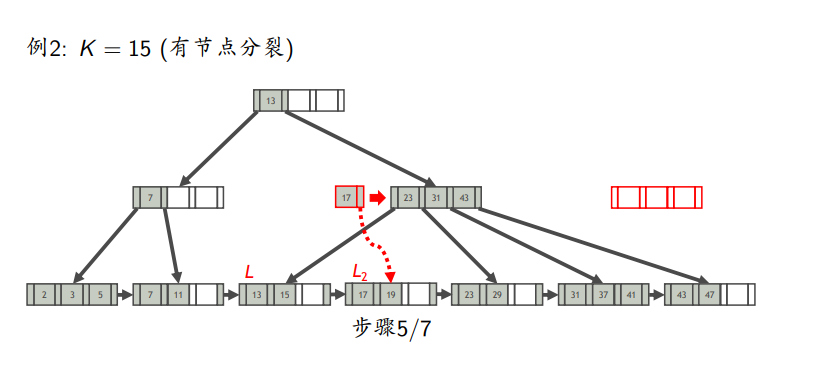
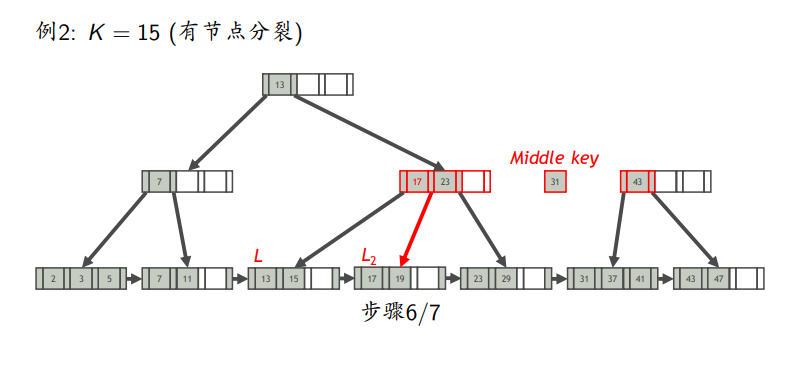
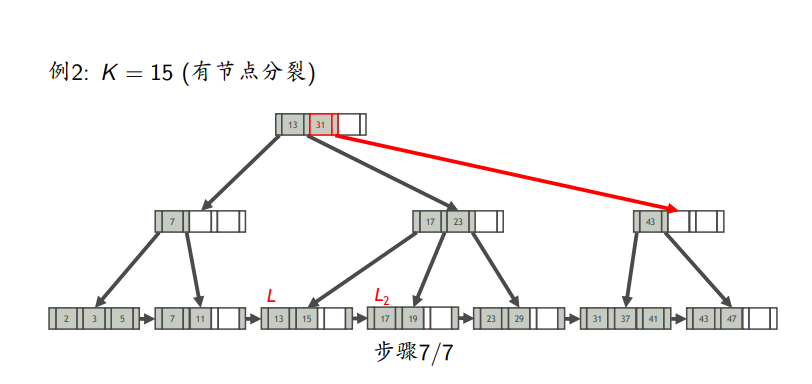
删除
-
不半满就合并



删除例子
-
直接删
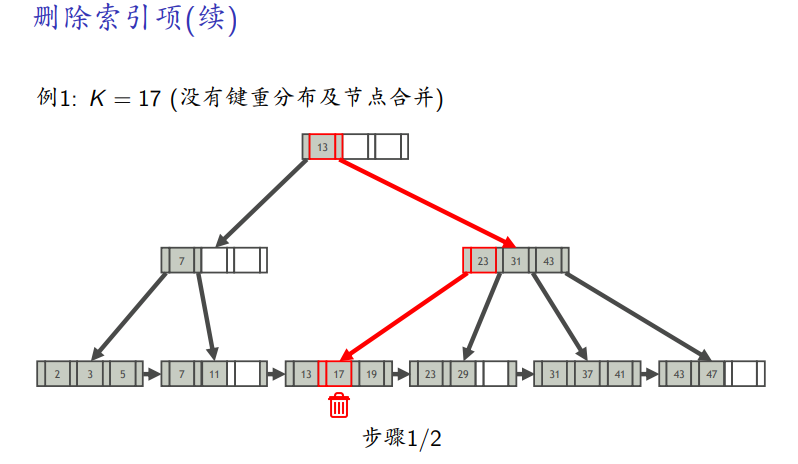
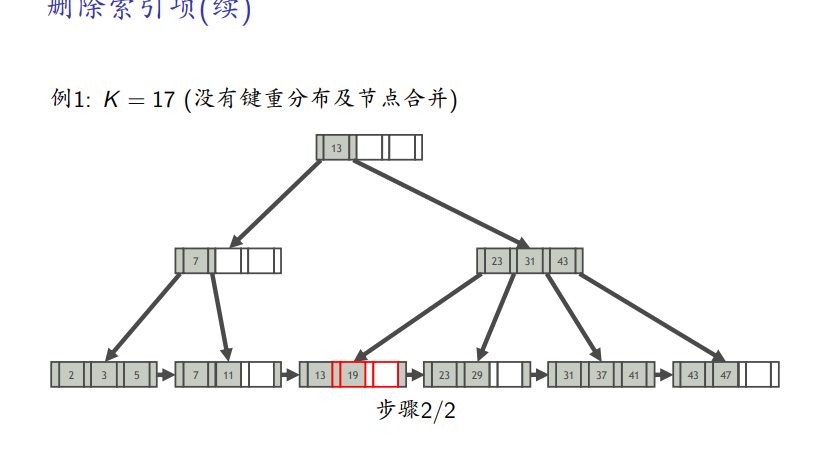
-
需要重新分布
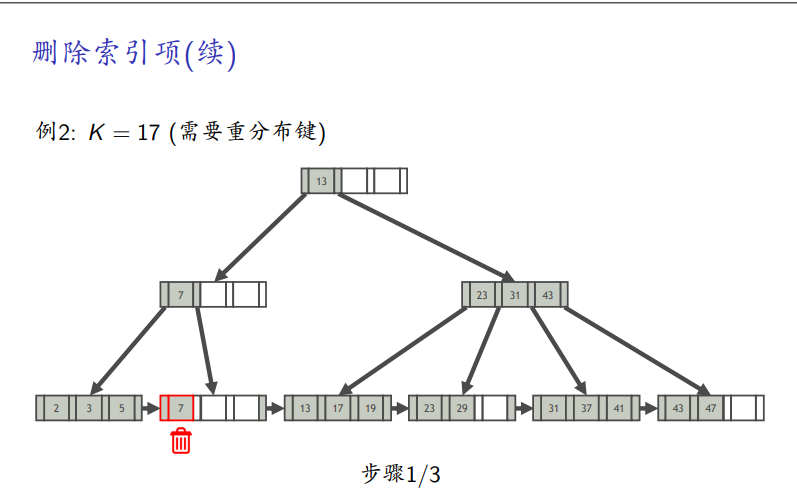
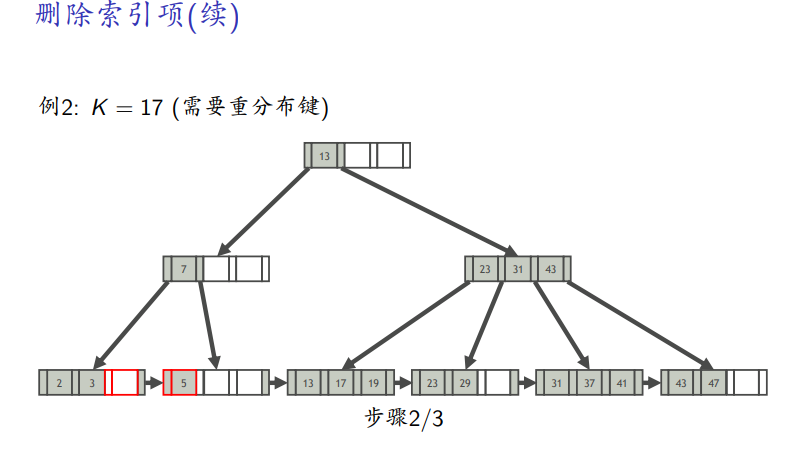
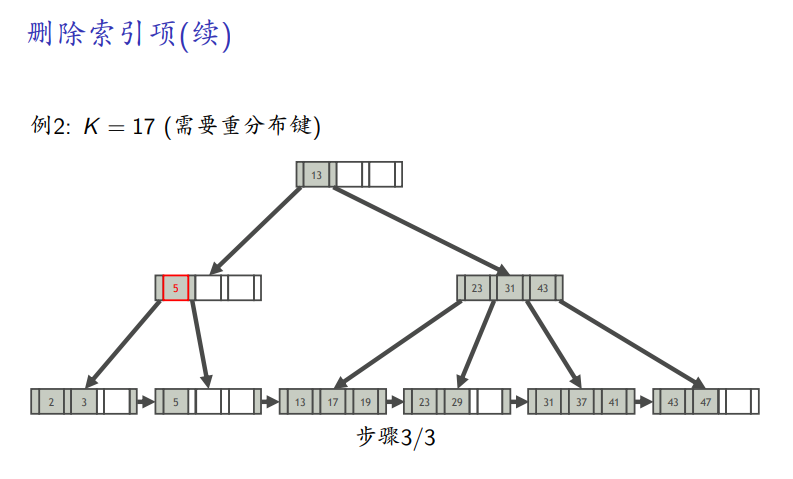
-
需要合并
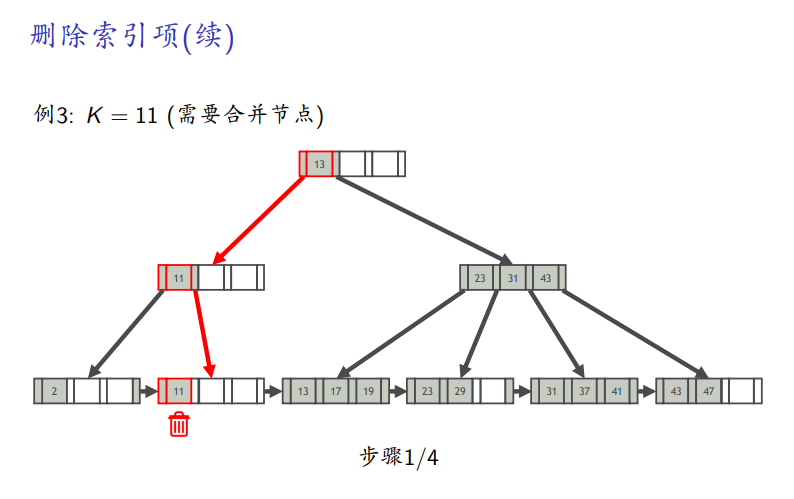
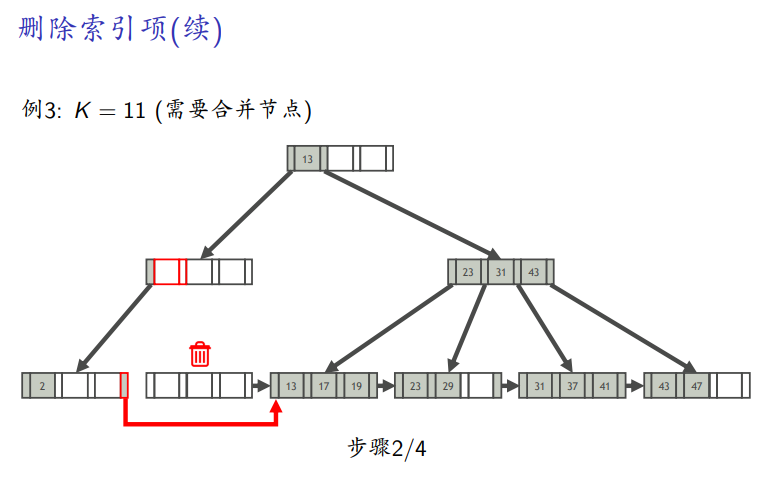
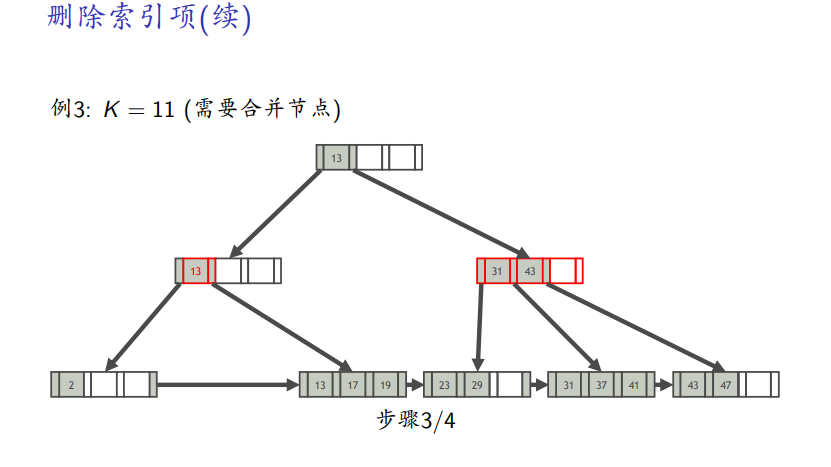
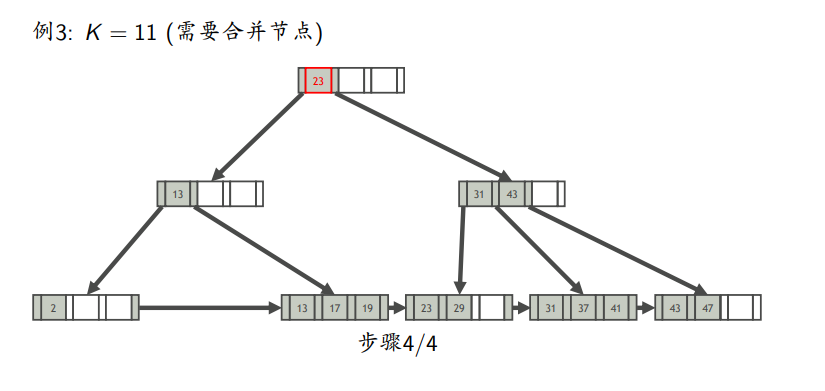
B+树操作在线演示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号