
b树和b+树
b树和b+树都是应用于数据库索引的,b树与二叉树的区别是,b树是m叉的多路平衡查找树。
理论上来说二叉树的查找速度和比较次数是最少的,但数据库用b树不用二叉树的原因是b树的高度比二叉树小,数据库索引是建立在磁盘上的,所以我们应该减少IO次数,对于树来说,IO次数就是树的高度。
b树的每个节点最多包含m个孩子,m成为树的阶,m的大小取决于磁盘的大小。
b树的特点:
- 任意非叶子结点最多只有m个儿子,m > 2
- 根节点的儿子数为[2,m]
- 除根节点以外的非叶子结点的儿子数为[m/2,m]
- 非叶子结点的关键字个数=儿子数 - 1
- 所有叶子结点位于同一层
- 对于一个非叶子结点,k个关键字把结点拆成k+1段,分别指向k+1个结点
关于b树的一些特征:
- 关键字集合分布在节点中
- 任何一个关键字出现且只出现在一个结点中
- 搜索可能在非叶子结点中结束
- 搜索性能等价于在全集内做一次二分查找
b+树是b树的一种变体,查询性能更好。
b+树的特征:
- 有k棵子树的非叶子结点中包含k个关键字(b树为k- 1个),这些关键字不保存数据,只用来索引,所有数据都保存在叶子结点中(b树为所有结点中都保存数据)
- 叶子结点的数据为自小而大顺序链接,所有非叶子结点包含了子节点的最大或最小关键字
- 同一个关键字出现在不同节点中,在根节点中的最大元素就是整个树中的最大元素
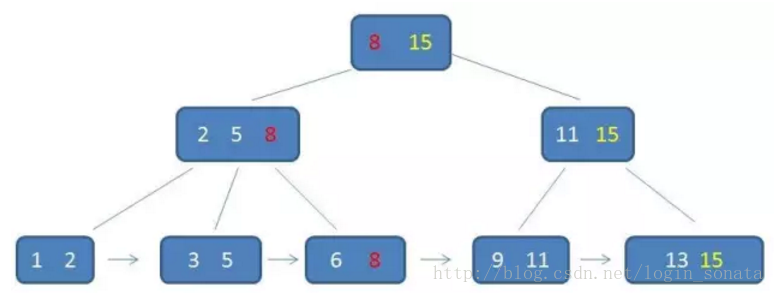
b+树相比b树的查询优势:
- 中间结点不保存数据,只保存了这些数据的关键信息以便索引,所以b+树更加矮胖,IO次数更少
- b+树查询必须查到叶子结点,b树有可能查询到中间结点就找到 了匹配元素,b+树更稳定,但速度并不慢
- 对于范围查找,因为b+树的数据是自小而大在叶子结点中排序的,所以只需要遍历叶子结点链表即可,而b树需要重复中序查找

 浙公网安备 33010602011771号
浙公网安备 33010602011771号