linux VFS基础学习
一、概念
VFS(Virtual Filesystem Switch)称为虚拟文件系统或虚拟文件系统转换,是一个内核软件层,在具体的文件系统之上抽象的一层,用来处理与Posix文件系统相关的所有调用,表现为能够给各种文件系统提供一个通用的接口,使上层的应用程序能够使用通用的接口访问不同文件系统,同时也为不同文件系统的通信提供了媒介。
二、架构
VFS在整个Linux系统中的架构视图如下:
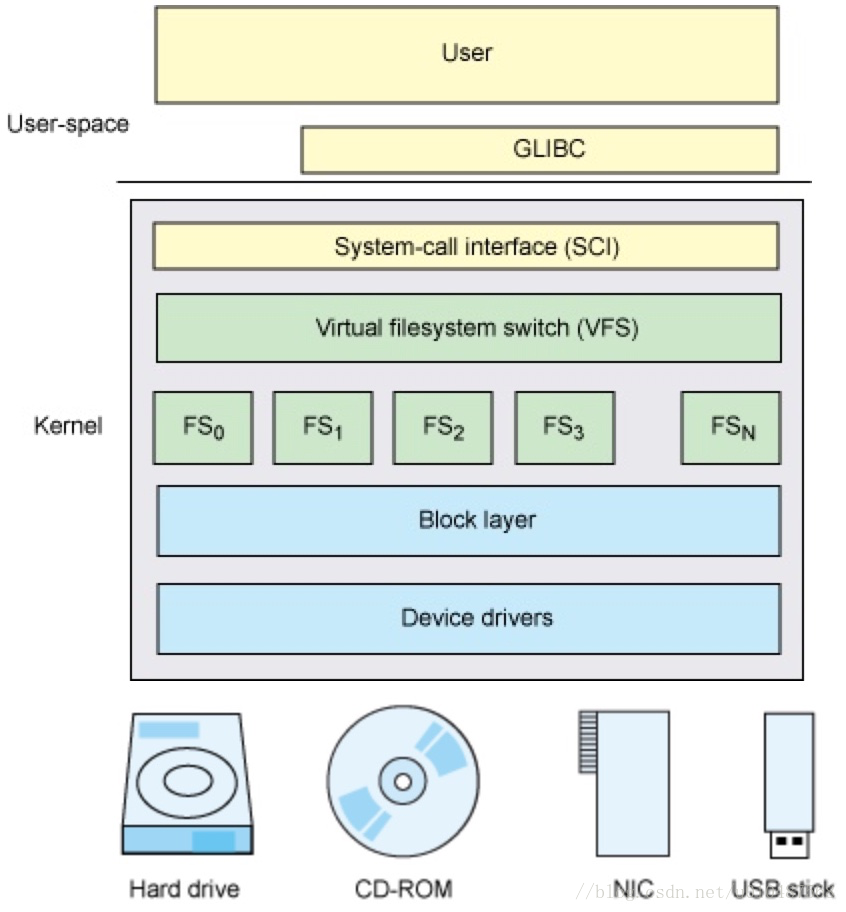
Linux系统的User使用GLIBC(POSIX标准、GUN C运行时库)作为应用程序的运行时库,然后通过操作系统,将其转换为系统调用SCI(system-call interface),SCI是操作系统内核定义的系统调用接口,这层抽象允许用户程序的 I/O 操作转换为内核的接口调用。VFS提供了一个抽象层,将POSIX API接口与不同存储设备的具体接口实现进行了分离,使得底层的文件系统类型、设备类型对上层应用程序透明。
三、接口转换示例:
用户写入一个文件,使用 POSIX 标准的 write 接口,会被操作系统接管,转调 sys_write 这个系统调用(属于SCI层)。然后 VFS 层接受到这个调用,通过自身抽象的模型,转换为对给定文件系统、给定设备的操作,这一关键性的步骤是VFS的核心,需要有统一的模型,使得对任意支持的文件系统都能实现系统的功能。这就是VFS提供的统一的文件模型(common file model),底层具体的文件系统负责具体实现这种文件模型,负责完成POSIX API的功能,并最终实现对物理存储设备的操作。
四、跨设备/文件系统示例:
VFS为不同设备或文件系统间的访问提供了媒介,下面的示意图和代码中,用户通过cp命令进行文件的拷贝,对用户来说是不用关心底层是否跨越文件系统和设备的,具体都通过VFS抽象层实现对不同文件系统的读写操作。

五、VFS的抽象接口
上述示例中提到VFS也有自己的文件模型,用来支持操作系统的系统调用。下面是VFS抽象模型支持的所有Linux系统调用:
文件系统相关:mount, umount, umount2, sysfs, statfs, fstatfs, fstatfs64, ustat
目录相关:chroot,pivot_root,chdir,fchdir,getcwd,mkdir,rmdir,getdents,getdents64,readdir,link,unlink,rename,lookup_dcookie
链接相关:readlink,symlink
文件相关:chown, fchown,lchown,chown16,fchown16,lchown16,hmod,fchmod,utime,stat,fstat,lstat,acess,oldstat,oldfstat,oldlstat,stat64,lstat64,lstat64,open,close,creat,umask,dup,dup2,fcntl, fcntl64,select,poll,truncate,ftruncate,truncate64,ftruncate64,lseek,llseek,read,write,readv,writev,sendfile,sendfile64,readahead
六、Linux系统VFS模块支持的文件系统
Disk-based 文件系统:Ext2, ext3, ReiserFS,Sysv, UFS, MINIX, VxFS,VFAT, NTFS,ISO9660 CD-ROM, UDF DVD,HPFS, HFS, AFFS, ADFS,
Network 文件系统:NFS, Coda, AFS, CIFS, NCP
特殊文件系统:/proc,/tmpfs等
七、统一文件模型(common file model)
文件是存储在硬盘上的,硬盘的最小存储单位叫做扇区sector,每个扇区存储512字节。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个块block。这种由多个扇区组成的块,是文件存取的最小单位。块的大小,最常见的是4KB,即连续八个sector组成一个block。
文件数据存储在块中,那么还必须找到一个地方存储文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种存储文件元信息的区域就叫做inode,中文译名为索引节点,也叫i节点。因此,一个文件必须占用一个inode,但至少占用一个block。
元信息 → inode
数据 → block
VFS为了提供对不同底层文件系统的统一接口,需要有一个高度的抽象和建模,这就是VFS的核心设计——统一文件模型。目前的Linux系统的VFS都是源于Unix家族,因此这里所说的VFS对所有Unix家族的系统都适用。Unix家族的VFS的文件模型定义了四种对象,这四种对象构建起了统一文件模型。
- superblock:存储文件系统基本的元数据。如文件系统类型、大小、状态,以及其他元数据相关的信息(元元数据)一个超级块对应一个文件系统(已经安装的文件系统类型如ext2,此处是实际的文件系统哦,不是VFS)。之前我们已经说了文件系统用于管理这些文件的数据格式和操作之类的,系统文件有系统文件自己的文件系统,同时对于不同的磁盘分区也有可以是不同的文件系统。
- index node(inode):保存一个文件相关的元数据。包括文件的所有者(用户、组)、访问时间、文件类型等,但不包括这个文件的名称。文件和目录均有具体的inode对应
- directory entry(dentry):保存了文件(目录)名称和具体的inode的对应关系,用来粘合二者,同时可以实现目录与其包含的文件之间的映射关系。另外也作为缓存的对象,缓存最近最常访问的文件或目录,提示系统性能
- file:一组逻辑上相关联的数据,被一个进程打开并关联使用统一文件模型是一个标准,各种具体文件系统的实现必须以此模型定义的各种概念来实现。
统一文件模型是一个标准,各种具体文件系统的实现必须以此模型定义的各种概念来实现。
7.1 superblock
静态:superblock保存了一个文件系统的最基础的元信息,一般都保存在底层存储设备的开头;
动态:挂载之后会读取文件系统的superblock并常驻内存,部分字段是动态创建时设置的。superblock的具体定义见linux/include/fs/fs.h,下图展示了内存中维护的superblock:
7.2 index node
静态:创建文件系统时生成inode,保存在具体存储设备上,记录了文件系统的元信息;
动态:VFS在内存中使用inode数据结构,来管理文件系统的文件对象,记录了文件对象的详细信息,部分字段与关联的文件对象有关,会动态创建;
索引节点inode:保存的其实是实际的数据的一些信息,这些信息称为“元数据”(也就是对文件属性的描述)。例如:文件大小,设备标识符,用户标识符,用户组标识符,文件模式,扩展属性,文件读取或修改的时间戳,链接数量,指向存储该内容的磁盘区块的指针,文件分类等等。
( 注意数据分成:元数据+数据本身 )
注意:inode有两种,一种是VFS的 inode,一种是具体文件系统的inode。前者在内存中,后者在磁盘中。所以每次其实是将磁盘中的inode调进填充内存中的inode,这样才是算使用了磁盘文件inode。
inode怎样生成的:每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定(如ext4)(到了xfs可以动态变化),一般每2KB就设置一个inode。一般文件系统中很少有文件小于2KB的,所以预定按照2KB分,一般inode是用不完的。所以inode在文件系统安装的时候会有一个默认数量,后期会根据实际的需要发生变化。
inode号:inode号是唯一的,表示不同的文件。其实在Linux内部的时候,访问文件都是通过inode号来进行的,所谓文件名仅仅是给用户容易使用的。当我们打开一个文件的时候,首先,系统找到这个文件名对应的inode号;然后,通过inode号,得到inode信息,最后,由inode找到文件数据所在的block,现在可以处理文件数据了。
inode和文件的关系:当创建一个文件的时候,就给文件分配了一个inode。一个inode只对应一个实际文件,一个文件也会只有一个inode。inodes最大数量就是文件的最大数量。
inode在内存中创建后会有inode cache进行缓存,并执行延迟的write back策略保存到底层存储设备。
7.3 directory entry
目录项:目录项是描述文件的逻辑属性,只存在于内存中,并没有实际对应的磁盘上的描述,更确切的说是存在于内存的目录项缓存,为了提高查找性能而设计。注意不管是文件夹还是最终的文件,都是属于目录项,所有的目录项在一起构成一颗庞大的目录树。
dentry是用来记录具体的文件名与对应的inode间的对应关系的,同时可以用来实现硬链接、缓存、多级目录等树状文件系统的特性。VFS的dentry设计上就是为了实现整个文件系统树状层次结构的,每个文件系统拥有一个没有父dentry的根目录(root dentry),这个dentry会被superblock引用,用来作为进行树形结构的查找入口。其余的所有dentry都是有唯一的父dentry,并可以由若干个孩子dentry。示例:对于一个文件"/home/user/a”,会存在“/”“home”“user”“a”四个dentry,依次构成父子关系,每个dentry也都有一个inode与之关联,存储了具体的数据。
dentry没有在磁盘等底层持久化存储设备上存储,是一个动态创建的内存数据结构,主要是为了构建出树状组织结构而设计,用来进行文件、目录的查找。dentry创建之后会被操作系统进行缓存,目的是为了提升对文件系统进行操作的性能。

dentry在需要使用时动态创建,并会被缓存。每个dentry有三种状态:
- used:与一个inode关联,正处于被VFS使用的状态,不能被损坏和丢弃
- unused:与inode关联,但处于被缓存状态,没有被VFS使用
- negative:没有与具体的inode关联(相当于是一个无效的路径)
dentry由于会被动态创建,为了提升系统性能,设计了一个dentry cache进行缓存,包括三个部分:
- used dentries 链表:记录每个正在使用的dentry,将其关联的inode的i_dentry字段指向的dentry链表连接起来形成一个dentry链表的链表
- LRU双向环链表:用于维护unused和negative状态的dentry对象,从头部插入,离头部越近就是最近访问过的。当需要删除dentry时,从队列尾部删除最旧的dentry
- hash table和hash function:用来快速查询一个给定的路径到dentry对象
7.4 file
文件对象描述的是进程已经打开的文件。因为一个文件可以被多个进程打开,所以一个文件可以存在多个文件对象。但是由于文件是唯一的,那么inode就是唯一的,目录项也是定的!
进程其实是通过文件描述符来操作文件的,注意每个文件都有一个32位的数字来表示下一个读写的字节位置,这个数字叫做文件位置。一般情况下打开文件后,打开位置都是从0开始,除非一些特殊情况。Linux用file结构体来保存打开的文件的位置,所以file称为打开的文件描述。这个需要好好理解一下!file结构形成一个双链表,称为系统打开文件表。
八、VFS抽象组件间的联系
从用户角度来看VFS的时候,可以通过下图很容易的理解各个抽象组件间的协作关系:
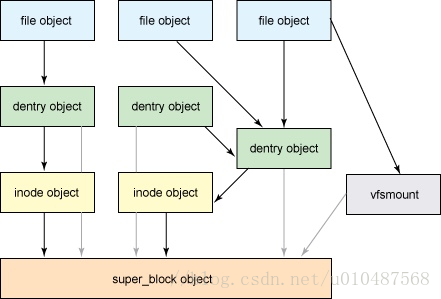
每个打开的文件对用户来说有一个文件描述符,也就是VFS抽象的file object。file object指向一个dentry,dentry指向新的dentry或一个inode,inode最终代表了一个具体存储设备上的数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号