反向传播算法
简单的神经网络:
一个神经网络,其中包含一个输入节点、一个输出节点,以及两个隐藏层(分别有两个节点)。相邻的层中的节点通过权重 𝑤𝑖𝑗wij 相关联,这些权重是网络参数
每个节点都有一个总输入 𝑥、一个激活函数 𝑓(𝑥)以及一个输出 𝑦=𝑓(𝑥)。 𝑓(𝑥)必须是非线性函数,否则神经网络就只能学习线性模型。
正向传播:是根据输入数据,以及每一层的权重系数,激活函数,不断向前计算,最终得出模型输出值y-output的过程。
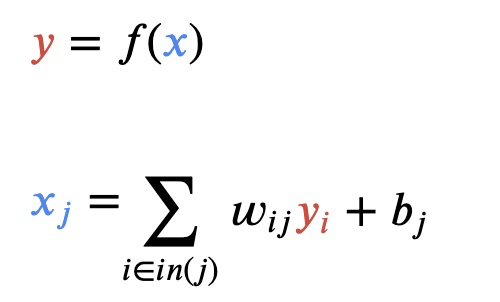
得到结果的误差:
![]()
梯度算法:
可以得出 e是w的函数

- 误差E有了,怎么调整权重让误差不断减小?
- E是权重w的函数,何如找到使得函数值最小的w。
解决上面问题的方法是梯度下降算法,我的理解是 所谓梯度,就是求出了在线上或平面上某一点处,e在w的斜率,如果这个斜率是大于0的说明随着w的增大,e也会增大,那么就应该减小权重w。如果斜率是小于0的,说明随着w的增大,e会减小,那么就应该增大权重w。
反向传播算法:本质上来说是 误差e对w求梯度,根据倒数链式法则,最终梯度值可以由x,y表示并计算出来。这也是当然的,因为其实e对w的方程里,x和y都相当于常量值,只不过对于每个输入数据,常量值都是不一样的罢了。
对特定样本的预测输出和理想输出进行比较,然后确定网络的每个权重的更新幅度。 为此,我们需要计算误差相对于每个权重的变化情况。

介绍到这里,后面的就是链式法则的推导了,主要逻辑是 将e对w求导转换为e对y的求导(由e的定义可以求出),y对w的求导(y可以表示为f(wx+b)).
参考链接:
https://blog.csdn.net/ft_sunshine/article/details/90221691
https://developers-dot-devsite-v2-prod.appspot.com/machine-learning/crash-course/backprop-scroll/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号