

hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析
hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析
Spark是一种快速、通用的计算集群系统,Spark提出的最主要抽象概念是弹性分布式数据集(RDD),它是一个元素集合,划分到集群的各个节点上,可以被并行操作。而Flink是可扩展的批处理和流式数据处理的数据处理平台。
Apache Flink,apache顶级项目,是一个高效、分布式、基于Java实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java,Python和Scala的API,跟Apache Spark非常类似,官网链接:https://flink.apache.org
Spark和Flink都支持实时计算,且都可基于内存计算(spark是伪实时的分片技术,只能按每秒分片技术,不能每条数据都实时技术,flink和storm可以)。Spark后面最重要的核心组件仍然是Spark SQL,而在未来几次发布中,除了性能上更加优化外(包括代码生成和快速Join操作),还要提供对SQL语句的扩展和更好地集成。至于Flink,其对于流式计算和迭代计算支持力度将会更加增强。无论是Spark、还是Flink的发展重点,将是数据科学和平台API化,除了传统的统计算法外,还包括学习算法,同时使其生态系统越来越完善。
Spark是一种快速、通用的计算集群系统,Spark提出的最主要抽象概念是弹性分布式数据集(RDD),它是一个元素集合,划分到集群的各个节点上,可以被并行操作。用户也可以让Spark保留一个RDD在内存中,使其能在并行操作中被有效的重复使用。Flink是可扩展的批处理和流式数据处理的数据处理平台,设计思想主要来源于Hadoop、MPP数据库、流式计算系统等,支持增量迭代计算。
1. 原理
Spark 1.4特点如下所示。
Spark为应用提供了REST API来获取各种信息,包括jobs、stages、tasks、storage info等。
Spark Streaming增加了UI,可以方便用户查看各种状态,另外与Kafka的融合也更加深度,加强了对Kinesis的支持。
Spark SQL(DataFrame)添加ORCFile类型支持,另外还支持所有的Hive metastore。
Spark ML/MLlib的ML pipelines愈加成熟,提供了更多的算法和工具。
Tungsten项目的持续优化,特别是内存管理、代码生成、垃圾回收等方面都有很多改进。
SparkR发布,更友好的R语法支持。

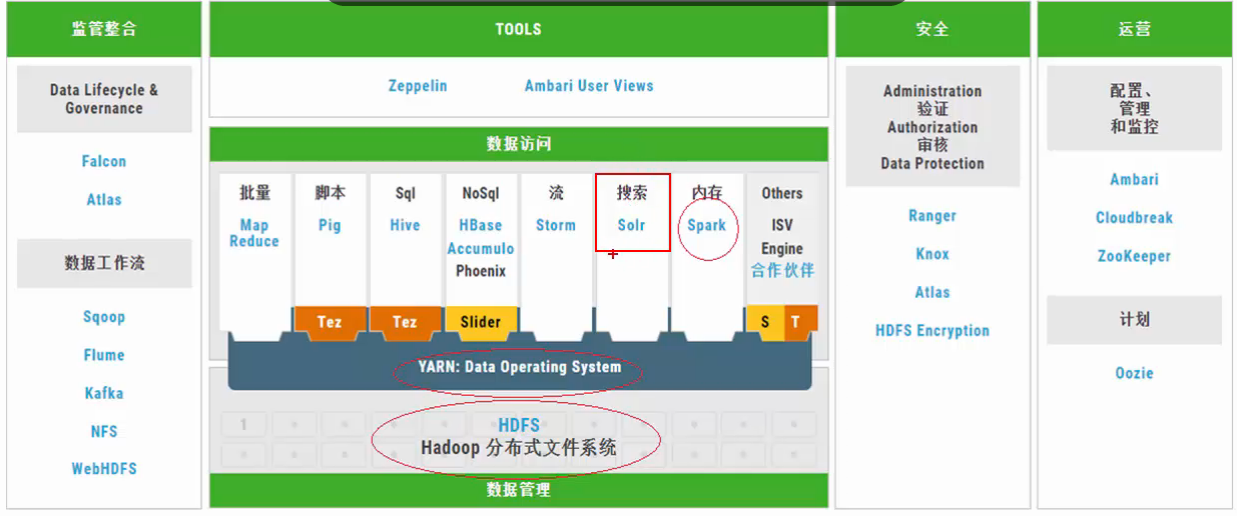
Spark架构图
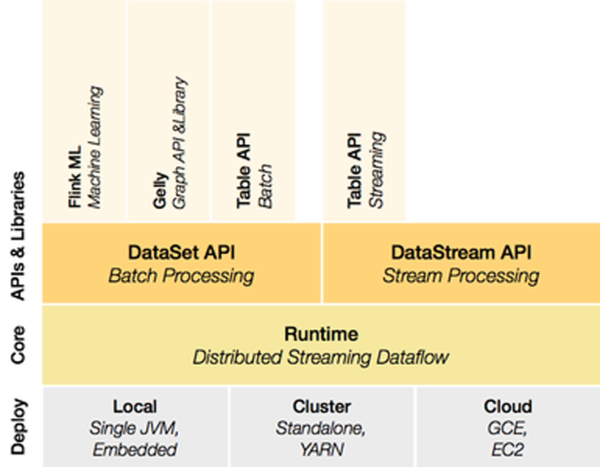
Flink架构图
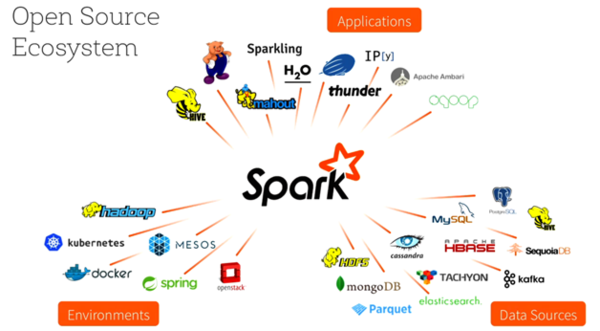
Spark生态系统图
Flink 0.9特点如下所示。
DataSet API 支持Java、Scala和Python。
DataStream API支持Java and Scala。
Table API支持类SQL。
有机器学习和图处理(Gelly)的各种库。
有自动优化迭代的功能,如有增量迭代。
支持高效序列化和反序列化,非常便利。
与Hadoop兼容性很好。
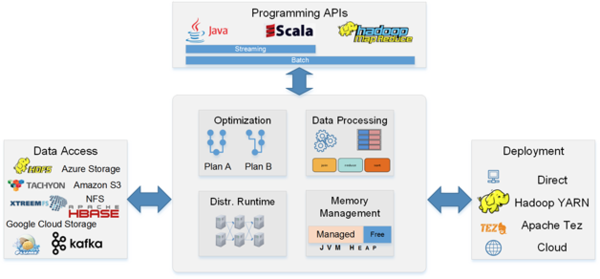
Flink生态系统图
2. 分析对比
2.1 性能对比
首先它们都可以基于内存计算框架进行实时计算,所以都拥有非常好的计算性能。经过测试,Flink计算性能上略好。
测试环境:
CPU:7000个;
内存:单机128GB;
版本:Hadoop 2.3.0,Spark 1.4,Flink 0.9
数据:800MB,8GB,8TB;
算法:K-means:以空间中K个点为中心进行聚类,对最靠近它们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
迭代:K=10,3组数据

迭代次数(纵坐标是秒,横坐标是次数)
总结:Spark和Flink全部都运行在Hadoop YARN上,性能为Flink > Spark > Hadoop(MR),迭代次数越多越明显,性能上,Flink优于Spark和Hadoop最主要的原因是Flink支持增量迭代,具有对迭代自动优化的功能。
2.2 流式计算比较
它们都支持流式计算,Flink是一行一行处理,而Spark是基于数据片集合(RDD)进行小批量处理,所以Spark在流式处理方面,不可避免增加一些延时。Flink的流式计算跟Storm性能差不多,支持毫秒级计算,而Spark则只能支持秒级计算。
2.3 与Hadoop兼容
计算的资源调度都支持YARN的方式
数据存取都支持HDFS、HBase等数据源。
Flink对Hadoop有着更好的兼容,如可以支持原生HBase的TableMapper和TableReducer,唯一不足是现在只支持老版本的MapReduce方法,新版本的MapReduce方法无法得到支持,Spark则不支持TableMapper和TableReducer这些方法。
2.4 SQL支持
都支持,Spark对SQL的支持比Flink支持的范围要大一些,另外Spark支持对SQL的优化,而Flink支持主要是对API级的优化。
2.5 计算迭代
delta-iterations,这是Flink特有的,在迭代中可以显著减少计算,Hadoop(MR)、Spark和Flink的迭代流程:
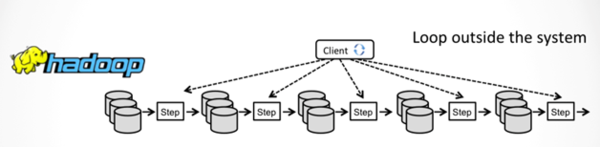
Hadoop(MR)迭代流程
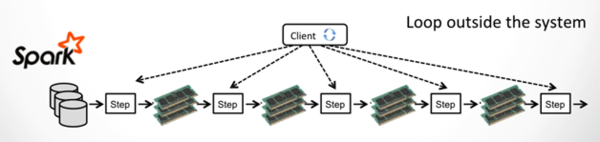
Spark迭代流程

Flink迭代流程
Flink自动优化迭代程序具体流程如图所示。
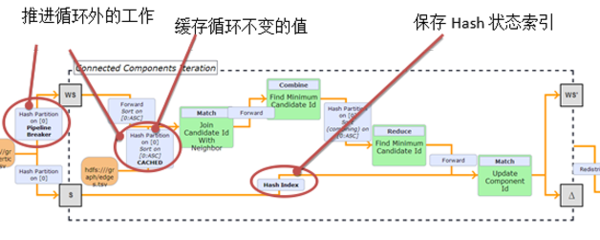
Flink自动优化迭代程序具体流程
2.6 社区支持
Spark社区活跃度比Flink高很多。
golang技术交流群:316397059,vuejs技术交流群:458915921 囤币一族:621258209,有兴趣的可以加入
微信公众号: 心禅道(xinchandao)投资论道


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?
2012-10-17 谈谈几个月以来开发android蓝牙4.0 BLE低功耗应用的感受