20182303 哈夫曼编码实践
哈夫曼编码实践
实践要求
设有字符集:S={a,b,c,d,e,f,g,h,i,j,k,l,m,n.o.p.q,r,s,t,u,v,w,x,y,z}。
给定一个包含26个英文字母的文件,统计每个字符出现的概率,根据计算的概率构造一颗哈夫曼树,并完成对英文文件的编码和解码。
要求:
(1)准备一个包含26个英文字母的英文文件(可以不包含标点符号等),统计各个字符的概率;
(2)构造哈夫曼树;
(3)对英文文件进行编码,输出一个编码后的文件;
(4)对编码文件进行解码,输出一个解码后的文件;
(5)撰写博客记录实验的设计和实现过程,并将源代码传到码云;
(6)把实验结果截图上传到云班课。
实现过程
- 准备一个包含26个英文字母的英文文件,
HuffmanNode类
每个结点都包含六项内容:权值、结点代表字母、字母的编码、左孩子、右孩子和父结点。
private double weight; //权值
private T word; // 字母
private HuffmanNode left;
private HuffmanNode right;
private HuffmanNode parent;
String code; // 存储最后的编码
HuffmanTree类
- createTree方法用于构造树;
public static HuffmanNode createTree(List<HuffmanNode<String>> nodes) {
while (nodes.size() > 1){
Collections.sort(nodes);
HuffmanNode left = nodes.get(nodes.size() - 2);
left.setCode(0 + "");
HuffmanNode right = nodes.get(nodes.size() - 1);
right.setCode(1 + "");
HuffmanNode parent = new HuffmanNode(left.getWeight() + right.getWeight(), null);
// 使新结点成为父结点
parent.setLeft(left);
parent.setRight(right);
// 删除权值最小的两个结点
nodes.remove(left);
nodes.remove(right);
nodes.add(parent);
}
return nodes.get(0);
}
- BFS方法是使用广度优先遍历来给每一个叶子结点进行编码。
public static List<HuffmanNode> BFS(HuffmanNode root){
Queue<HuffmanNode> queue = new ArrayDeque<HuffmanNode>();
List<HuffmanNode> list = new ArrayList<HuffmanNode>();
if (root != null){
// 将根元素加入队列
queue.offer(root);
root.getLeft().setCode(root.getCode() + "0");
root.getRight().setCode(root.getCode() + "1");
}
while (!queue.isEmpty()){
// 将队列的队尾元素加入列表中
list.add(queue.peek());
HuffmanNode node = queue.poll();
// 如果左子树不为空,将它加入队列并编码
if (node.getLeft() != null){
queue.offer(node.getLeft());
node.getLeft().setCode(node.getCode() + "0");
}
// 如果右子树不为空,将它加入队列并编码
if (node.getRight() != null){
queue.offer(node.getRight());
node.getRight().setCode(node.getCode() + "1");
}
}
return list;
}
HuffmanMakeCode类
用于将文件中的内容提取,放入数组并进行计数。HuffmanTest类
- 实现文件的读取,构造哈夫曼树,编码,解码,文件的写入五个步骤,前三个步骤使用之前三个类中的方法即可实现。
- 解码:解码部分使用一个列表list4将编码结果的字符串转化到列表中去,然后定义了两个变量,第一个变量用于每次依次获取的编码值,然后与list3(存储编码的列表)进行比较找到对应索引,然后将list2(存储字母的列表)中对应索引值位置的字母加入第二个变量中,每次循环后删除列表list4的第一个元素,循环直至list4为空时结束,第二个变量temp1中存储的即为解码结果。
List<String> list4 = new ArrayList<>();
for (int i = 0;i < result.length();i++){
list4.add(result.charAt(i) + "");
}
String temp = "";
String temp1 = "";
while (list4.size() > 0){
temp += "" + list4.get(0);
list4.remove(0);
for (int i = 0;i < list3.size();i++){
if (temp.equals(list3.get(i))){
temp1 += "" + list2.get(i);
temp = "";
}
}
}
System.out.println("文件解码结果为: " + temp1);
- 文件写入:文件写入就是很简单的方法使用,这里使用的是字符操作流(使用FileWriter类和FileReader类)的方法。
File file = new File("D:\\IDEA\\2303\\src\\Chapter17\\Huffman\\outHuffman.txt");
Writer out = new FileWriter(file);
out.write(result);
out.close();
实践结果
-
在
inHuffman中输入i write it because it makes me warm all over inside to write it to you
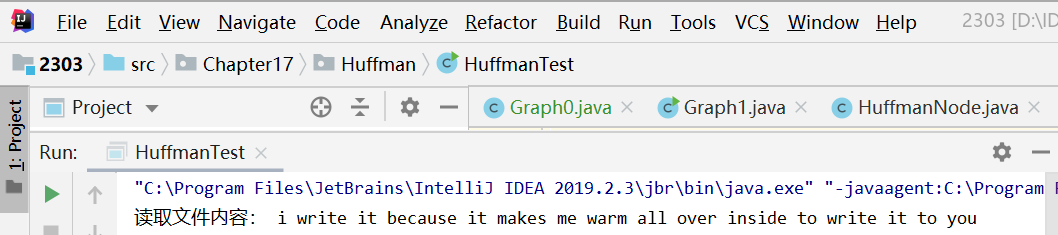
-
读入文件
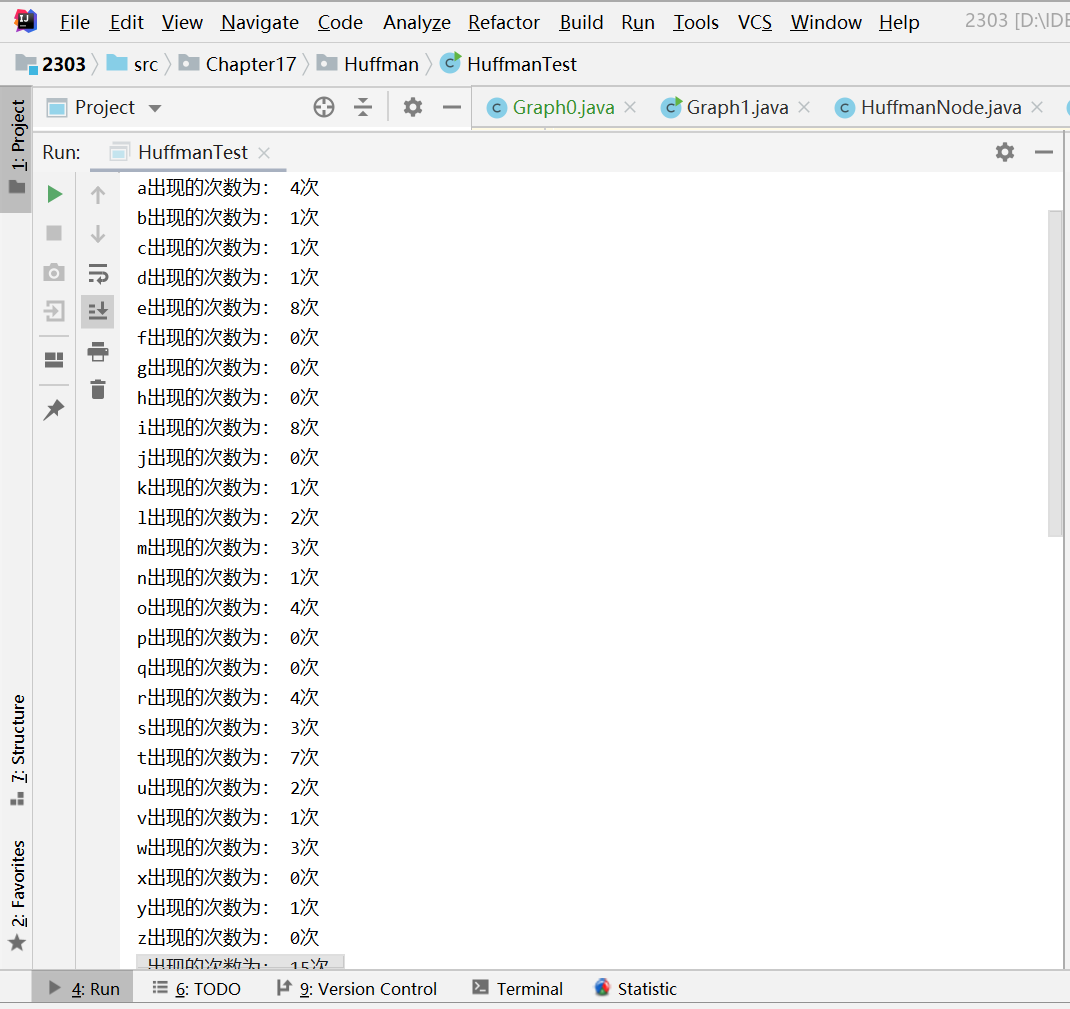
-
次数统计
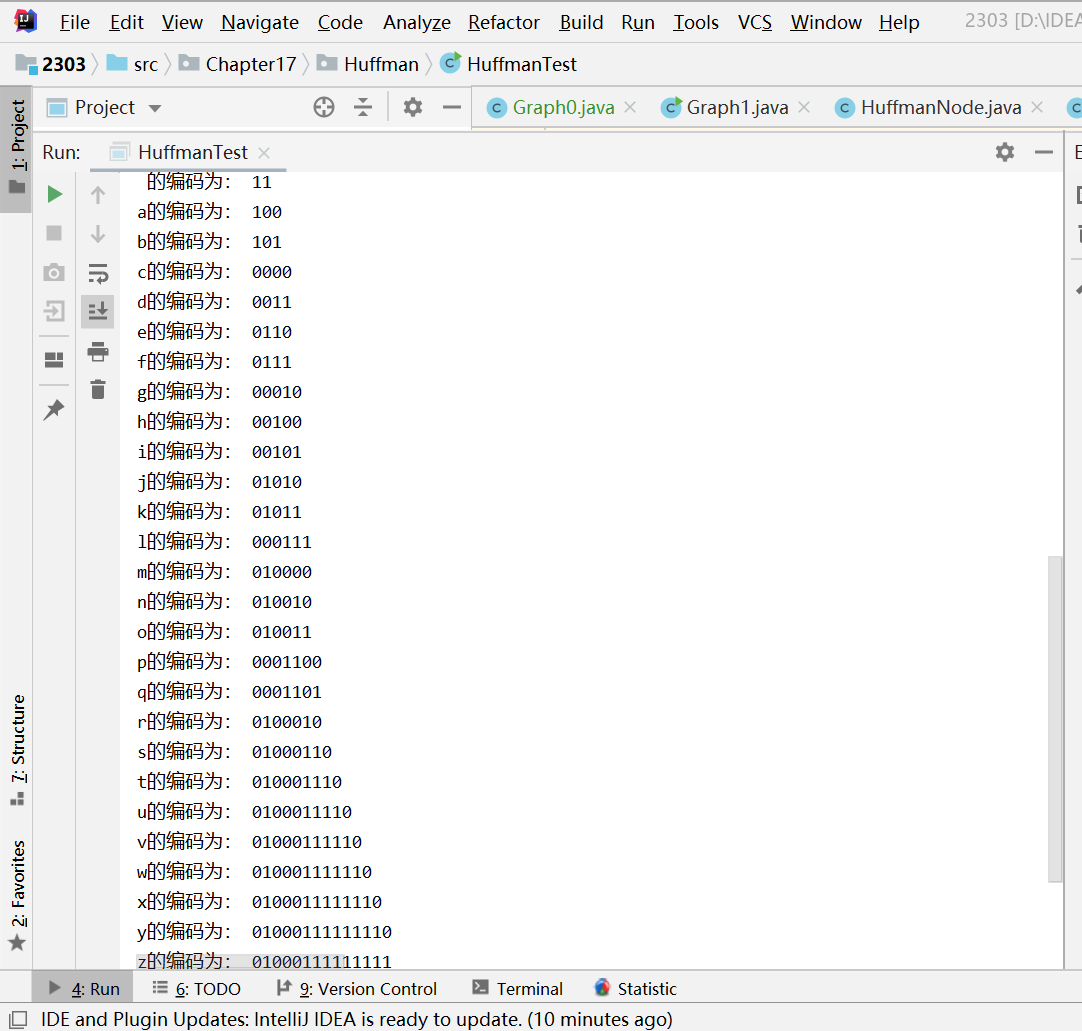
-
编码
-
文件编码
-
解码

-
将解码后的字符串写入
outHuffman中


