

08-03_阅读flask上下文前夕补充、flask请求上下文、数据库连接池
阅读flask上下文前夕补充
预读源码必要了解的知识点
在阅读源码之前,源码中会涉及到很多python类的特殊的用法以及类写好的功能组件,所以这里我们做一个补充,以便于接下来源码的阅读
01 偏函数
当函数的参数个数太多,需要简化时,使用functools.partial可以创建一个新的函数,这个新函数可以固定住原函数的部分参数,从而在调用时更简单。
from functools import partial
def func(a1,a2,a3):
print(a1,a2,a3)
new_func1 = partial(func,a1=1,a2=2)
new_func1(a3=3)
new_func2 = partial(func,1,2)
new_func2(3)
new_func3 = partial(func,a1=1)
new_func3(a2=2,a3=3)
注意:partial括号内第一个参数是原函数,其余参数是需要固定的参数
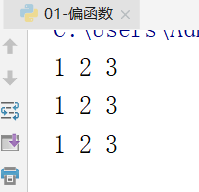
效果图:
02 __add__的使用
如果一个类里面定义了 __add__方法,如果这个类的对象 +另一个对象,会触发这个类的__add__方法,换个说法如果 对象1+对象2 则会触发对象1的 __add__方法,python在类中有很多类似的方法,对象会在不同情况下出发对应的方法。
class Foo:
def __init__(self):
self.num = 1
def __add__(self, other):
if isinstance(other,Foo):
result = self.num + other.num
else:
result = self.num + other
return result
fo1 = Foo()
fo2 = Foo()
v1 = fo1 + fo2
v2 = fo1 + 4
print(v1,v2)
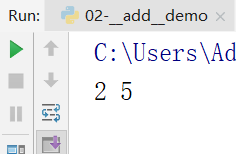
效果图:
03 chain函数
chain函数来自于itertools库,itertools库提供了非常有用的基于迭代对象的函数,而chain函数则是可以串联多个迭代对象来形成一个更大的迭代对象 。
实例1:
from itertools import chain
l1 = [1,2,3]
l2 = [4,5]
new_iter = chain(l1,l2) # 参数必须为可迭代对象
print(new_iter)
for i in new_iter:
print(i)
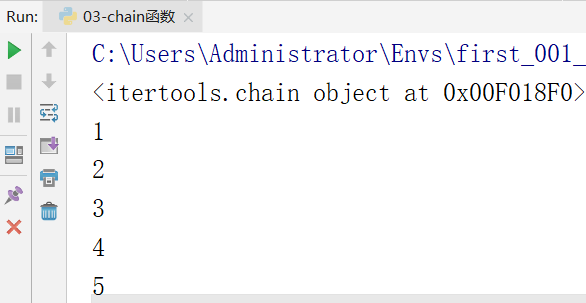
效果图:
实例2:
from itertools import chain
def f1(x):
return x+1
def f2(x):
return x+2
def f3(x):
return x+3
list_4 = [f1, f2]
new_iter2 = chain([f3], list_4)
for i in new_iter2:
print(i)
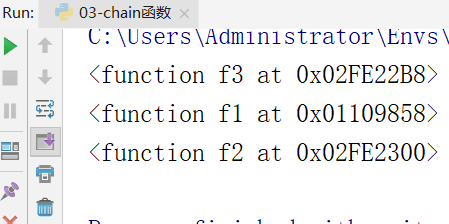
效果图:
2 flask请求上下文
在分析上下问之前,要做好一个心理准备,因为设计到的代码会很多,需要不懂的要跟着文档自己去翻阅源码。
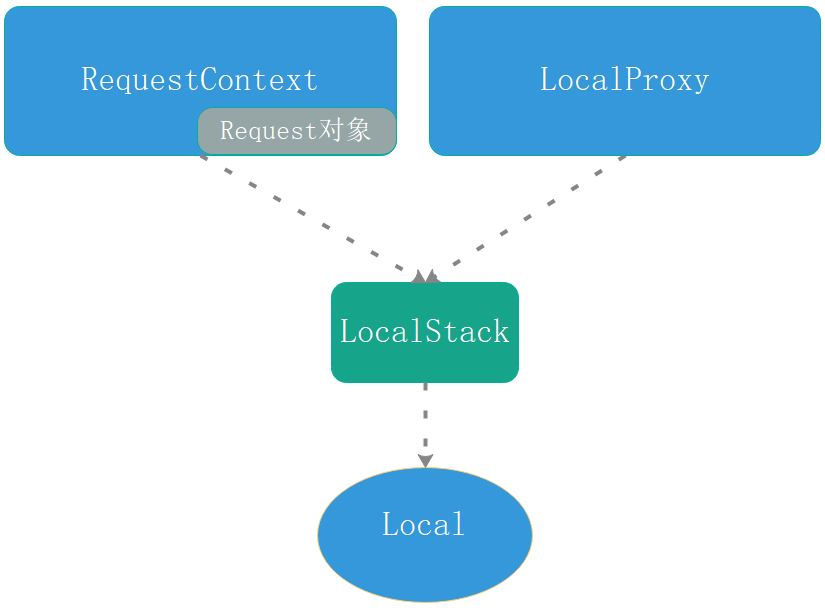
首先把涉及到的主要的类或者设计到的py页面展示如下图。下面我会以对应类或者页面去讲解flask源码

之前我们已经论述过了,每次请求过来都会触发app(),所以会触发FLask类的__call__方法,__call__方法会触发Flask类的wsgi_app()方法。然后所有的请求的整个生命周期都在整个wsgi_app()里面了。
根据上图类和序号来完成我们的分析流程。
1 首先分析请求上下文对象(ctx)创立
- 1.0 FLask 类中的
wsgi_app()中的 ctx = self.request_context(environ) - 1.1 RequestContext类中的
__init__
实例化出请求上下文对象ctx
并且关注:
if request is None:
request = app.request_class(environ)
self.request = request
- 1.2 Request类中的
__init__
该类的 __init__方法实例化出reqeust对象
这三部完成了初始化一个用户请求相关的数据,也就是请求上下文对象。
1.0中的ctx就是RequestContext对象,请求上下文对象ctx中初始化所有请求所有内容,并且其内部封装着Request对象,Request对象把请求过来的信息格式化并且储存起来。
2 把请求对象(ctx)添加到local中(入栈)
- 2.0 FLask 类中的
wsgi_app()中的 ctx.push() - 2.1 RequestContext 类中的 push() 下
只关注_request_ctx_stack.push(self)
- 2.2 LocalStack类中的 push()方法
只关注 self._local.stack = rv = [] ,触发2.3执行。
在实现了2.3的基础上,关注本方法中的 rv.append(obj) , rv就是2.3中stack的value值,此obj就是ctx对象 ,相当于为Local类中的storage里面的当前线程或携程唯一标识里的stack对应的value值,添加了球队上下文对象ctx,这个对象里面包含了所有请求过来的信息。
{
线程或携程唯一标识:{
stack:[请求上下文对象ctx]。
},
}
- 2.3 Local类中的
__setattr__方法实现了创建了
storage = {
线程或携程唯一标识:{
stack: [ ]
},
}
3 找到视图函数并且使用导入request对象
- 3.0 FLask 类中的
wsgi_app()中response = self.full_dispatch_request()的找到视图函数并执行 - 3.1 找到了视图函数并且执行
request.method方法。
@app.route(‘/’)
def index():
v = request.method
return v - 3.2 须知:
request = LocalProxy(partial(_lookup_req_object, 'request'))用于在视图函数里导入的request对象
偏函数:partial(_lookup_req_object, ‘request’) 不懂可以翻阅之前的文章
- 3.3 触发了
LocalProxy类 中的__getattr__
关注:return getattr(self._get_current_object(), name) # name是‘method’,去Request类中查询‘method’属性,
- 3.4 触发了
LocalProxy类 中的_get_current_object()
关注 return self.__local() #返回了Request对象
在LocalProxy类实例化的时候使得self.__local的值就是实例化时传入偏函数。所以会返回偏函数运行结果。
- 3.5 触发了
globals.py里的_lookup_req_object()运行。
关注 top = _request_ctx_stack.top # 触发3.6执行
return getattr(top, name) # name = ‘request’,所以返回了Request对象
- 3.6 触发了
LocalStack类中的top()方法:
关注 return self._local.stack[-1] # 返回了请求上下文ctx对象。
- 3.7 触发了Local类中的
__getattr__()方法
关注return self.__storage__[self.__ident_func__()][name] #返回了当前线程或携程的stack对应的value值,可以理解为返回了 [ctx对象]
4 请求结束时从Local中移除上下文对象(出栈)
经过了添加请求上下文到Local的storage中,以及视图函数的运行返回相应对象,我们现在进行把请求上下文对象从storage中移除。
- 4.0 FLask 类中的
wsgi_app()中 ctx.auto_pop() - 4.1 触发了 RequestContext类中的 auto_pop()
关注 self.pop()
- 4.2 触发了 RequestContext类中的 pop() 方法
rv = _request_ctx_stack.pop()
- 4.3 触发了 LocalStack类中的pop()的pop方法
elif len(stack) == 1: # 证明push过一次 添加过了一次对象
release_local(self._local) # 在这里pop掉该线程。release_local pop掉的是一个字典
return stack[-1] - 4.4 触发了 Local类中的
__release_local__()方法
self.storage.pop(self.ident_func(), None) #在Local对象中删除掉了当前线程或者携程的请求上下文对象,
总结:
- 其实操作flask的请求上下文就是操作Local中的字典
__storage__
通过REquestContext类首先实例化ctx请求上下文对象,其内部包含请求对象
入栈,通过请求上下文对象的类的push()方法触发了LocalStack类的push() 方法,从而添加到Local类中的字典里。
观察导入的request源码 ,通过观察LocalProxy的源码,最后触发了LocalStack的top()方得到上下文对象,再的到请求对象,从而实现reuqest的功能。
出站,和入栈原理相同通过请求上下文对象的类的方法,触发了LocalStack的的pop()方法从而从字典中删除掉当前线程或当前携程的请求信息。
数据库连接池
01 如何在python中操作数据库?
在后端开发中免不掉与数据库打交道,无非是使用orm或者原生sql来操作数据库。
在python中通过原生sql操作数据库,主流就两种。
- 使用pymysql模块:
pymysql支持python2.x和python3.x的版本 - 使用mysqldb模块:
mysqldb仅支持python2.x的版本
orm的使用以flask和django为例。
- flask使用的orm是基于
SQLAlchemy(SQLAlchemy本就是orm),flask团队并在SQLAlchemy基础之上又封装了一个Flask-SQLchemy并予以应用 。 - django使用的orm是django自带的orm。
orm的操作数据库的方式我们已经熟知了,这里我们聊一聊如何在web中使用原生sql操作数据库,以及会出现的问题。
02 在web中使用原生sql(pymysql)操作数据库?
2.1 在web中通过原生sql操作数据库会出现的问题。
示例1:
把所有的数据库操作全部都放在了视图函数里面。
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
import pymysql
CONN = pymysql.connect(host='127.0.0.1',
port=3306,
user='root',
password='123',
database='pooldb',
charset='utf8')
cursor = CONN.cursor()
cursor.execute('select * from tb1')
result = cursor.fetchall()
cursor.close()
print(result)
return "Hello World"
if __name__ == '__main__':
app.run()
会出现的问题
- 很多个用户并发的来请求,一个用户可以理解为一个线程,每个线程都会跟数据库建立连接,数据库承受不了这种量级的连接数。
示例2
为了避免之前每个用户都建立连接,我们把数据库连接放到了全局变量里面,只会建立一次连接,但是依然会出现问题。
from flask import Flask
app = Flask(__name__)
import pymysql
CONN = pymysql.connect(host='127.0.0.1',
port=3306,
user='root',
password='123',
database='pooldb',
charset='utf8')
@app.route("/")
def hello():
cursor = CONN.cursor()
cursor.execute('select * from tb1')
result = cursor.fetchall()
cursor.close()
print(result)
return "Hello World"
if __name__ == '__main__':
app.run()
会出现的问题:
- 会出现线程安全问题,比如如果第一个用户拿到了连接给关闭了,而第二个用户正在进行查询,第二个用户查询的时候第一个用户把连接断了,会导致第二个用户出现问题。
- 假设第一用户查询了一下表1,正准备获取查询的内容,这时第二个人查询了一下表2,由于cursor对象都是同一个,第一个人获取到的查询内容就是表2的内容了,所以也会出现线程安全问题
示例3
为了避免之前的线程不安全,在示例2的基础上加上一把线程锁
from flask import Flask
import threading
app = Flask(__name__)
import pymysql
CONN = pymysql.connect(host='127.0.0.1',
port=3306,
user='root',
password='123',
database='pooldb',
charset='utf8')
@app.route("/")
def hello():
with threading.Lock():
cursor = CONN.cursor()
cursor.execute('select * from tb1')
result = cursor.fetchall()
cursor.close()
print(result)
return "Hello World"
if __name__ == '__main__':
app.run()
会出现的问题:
- 根据代码可以发现,只是在示例2的基础上加了一把线程锁,确实是保证了线程安全,但是所有关于数据库操作的请求变成了串行,无法实现并发了。
小结:
- 如果直接连接坐在视图函数中,会导致每个用户都要创建连接,数据库承受不了这种量级的连接数。
- 如果连接数据库的内容做成全局变量的话,无法保证线程安全。
- 如果定义全局变量用于连接数据库,并且在线程中操作数据库内容加线程锁头,就会变成串行,无法保证并发
所以我们既要控制数据库的连接数,又要保证线程安全,又要保证web的并发,这个时候最终的解决方案是数据库连接池。
2.1 什么是数据库连接池呢?
数据库连接池概念:数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个,这项技术能明显提高对数据库操作的性能。
图解:
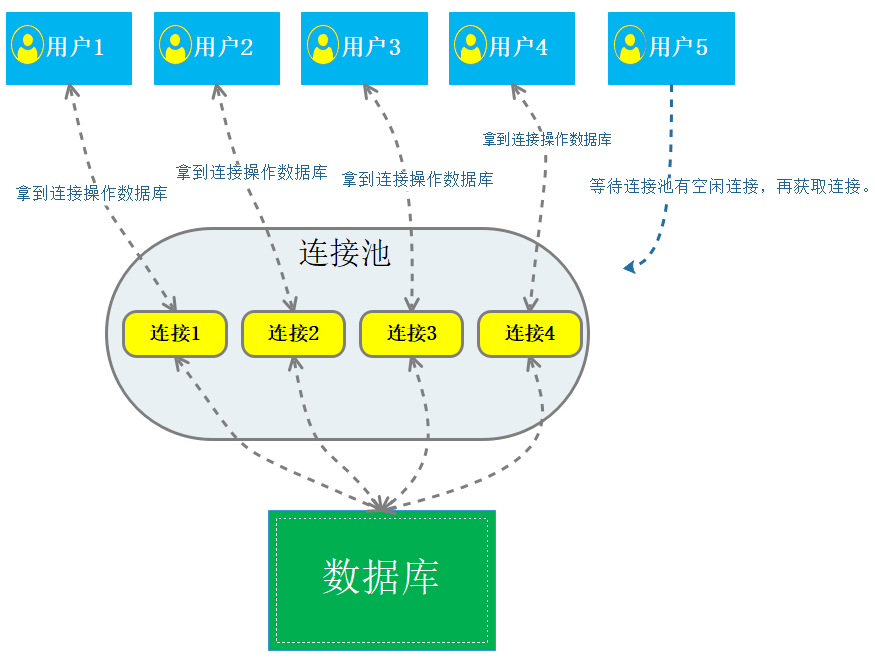
通俗的讲就是,假设数据库连接池中有5个连接对象,每个用户简单理解为一个线程,比如现在有6个用户同时来访问,6个线程去数据库连接池里面申请数据库的连接对象。前5个线程每个都申请到了连接对象去操作数据库,每个线程使用完了数据库连接对象会归还给数据库连接池,那么第6个线程会等待前5个线程归还连接对象给连接池,再具体一点是:假设第一个线程使用完了连接对象,那么此时6个线程才会结束等待,从而申请到连接对象,以此类推。

2.2 Python数据库连接池DBUtiles
DBUtils 是Python的一个用于实现数据库连接池的模块。
首先安装一下DBUtils模块。
pip install DBUtils
DBUtils连接池的两种连接模式:
**模式一:**为每个线程创建一个连接,线程即使调用了close方法,也不会关闭,只是把连接重新放到连接池,仅供自己的线程再次使用,当线程终止时,连接会自动关闭。(不推荐使用,因为这样需要自己控制线程数量)
import pymysql
from DBUtils.PersistentDB import PersistentDB
from threading import local
POOL = PersistentDB(
creator=pymysql, # 使用链接数据库的模块
maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制
setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
ping=0, # ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always
closeable=False,
# 如果为False时, conn.close() 实际上被忽略,供下次使用,再线程关闭时,才会自动关闭链接。如果为True时, conn.close()则关闭链接,那么再次调用pool.connection时就会报错,因为已经真的关闭了连接(pool.steady_connection()可以获取一个新的链接)
threadlocal=None, # 如果为none,用默认的threading.Loacl对象,否则可以自己封装一个local对象进行替换
host='127.0.0.1',
port=3306,
user='root',
password='123',
database='pooldb',
charset='utf8'
)
def func():
conn = POOL.connection(shareable=False)
cursor = conn.cursor()
cursor.execute('select * from tb1')
result = cursor.fetchall()
cursor.close()
conn.close()
func()
模式二: 创建一批连接到连接池,供所有线程共享使用。
import time
import pymysql
import threading
from DBUtils.PooledDB import PooledDB, SharedDBConnection
POOL = PooledDB(
creator=pymysql, # 使用链接数据库的模块
maxconnections=6, # 连接池允许的最大连接数,0和None表示不限制连接数
mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxcached=5, # 链接池中最多闲置的链接,0和None不限制
maxshared=3, # 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。
blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错
maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制
setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
ping=0,
# ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always
host='127.0.0.1',
port=3306,
user='root',
password='123',
database='pooldb',
charset='utf8'
)
def func():
conn = POOL.connection()
cursor = conn.cursor()
cursor.execute('select * from tb1')
result = cursor.fetchall()
conn.close()
func()
2.3 实际开发小应用案例:
案例目录:
- app.py
- db_helper.py
app.py
from flask import Flask
from db_helper import SQLHelper
app = Flask(__name__)
@app.route("/")
def hello():
result = SQLHelper.fetch_one('select * from t1',[])
print(result)
return "Hello World"
if __name__ == '__main__':
app.run()
db_helper.py
import pymysql
from DBUtils.PooledDB import PooledDB
POOL = PooledDB(
creator=pymysql, # 使用链接数据库的模块
maxconnections=6, # 连接池允许的最大连接数,0和None表示不限制连接数
mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxcached=5, # 链接池中最多闲置的链接,0和None不限制
maxshared=3, # 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。
blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错
maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制
setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
ping=0,
# ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always
host='127.0.0.1',
port=3306,
user='root',
password='123',
database='pooldb',
charset='utf8'
)
class SQLHelper(object):
@staticmethod
def fetch_one(sql,args):
conn = POOL.connection()
cursor = conn.cursor()
cursor.execute(sql, args)
result = cursor.fetchone()
conn.close()
return result
@staticmethod
def fetch_all(self,sql,args):
conn = POOL.connection()
cursor = conn.cursor()
cursor.execute(sql, args)
result = cursor.fetchall()
conn.close()
return result
以后在开发的过程中我们可以基于数据库连接池,基于pymysql,来实现自己个性化操作数据库的需求。
本文来自博客园,作者:喝茶看狗叫,转载请注明原文链接:https://www.cnblogs.com/zdwzdwzdw/p/17487866.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通