
zookeeper原理与安装
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。
1. Zookerper工作机制

2. Zookeeper工作特点
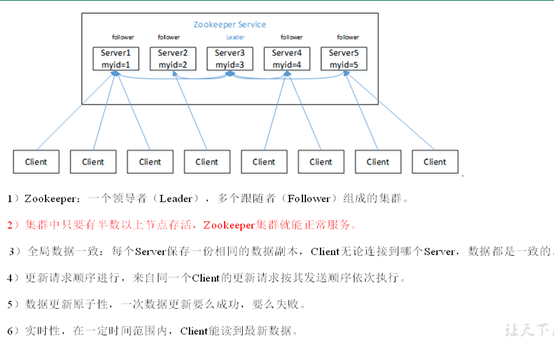
3. Zookeeper文件系统:znode不区分文件与文件夹
4. Zookeeper配置文件参数:
tickTime =2000:通信心跳数,Zookeeper服务器与客户端心跳时间,单位毫秒
Zookeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒。
它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间。(session的最小超时时间是2*tickTime)
initLimit =10:LF初始通信时限
集群中的Follower跟随者服务器与Leader领导者服务器之间初始连接时能容忍的最多心跳数(tickTime的数量),用它来限定集群中的Zookeeper服务器连接到Leader的时限。
syncLimit =5:LF同步通信时限
集群中Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
dataDir:数据文件目录+数据持久化路径
主要用于保存Zookeeper中的数据。
clientPort =2181:客户端连接端口
监听客户端连接的端口。
5. Zookeeper分布式安装
1. 集群规划
2. 解压安装
解压Zookeeper安装包到/opt/module/目录下
同步/opt/module/zookeeper-3.4.10目录内容
3.配置服务器编号
(1)在/opt/module/zookeeper-3.4.10/这个目录下创建zkData
(2)在/opt/module/zookeeper-3.4.10/zkData目录下创建一个myid的文件
(3)编辑myid文件,在文件中添加与server对应的编号
(4)拷贝配置好的zookeeper到其他机器上,并修改myid
4.配置zoo.cfg文件
(1)重命名/opt/module/zookeeper-3.4.10/conf这个目录下的zoo_sample.cfg为zoo.cfg
(2)打开zoo.cfg文件
修改数据存储路径配置
dataDir=/opt/module/zookeeper-3.4.10/zkData
增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
(3)配置参数解读
server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
B是这个服务器的地址;
C是这个服务器Follower与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
6. 客户端操作
Bin目录 ./zkCli.sh 登录客户端
|
命令基本语法 |
功能描述 |
|
help |
显示所有操作命令 |
|
ls path [watch] |
使用 ls 命令来查看当前znode中所包含的内容 |
|
ls2 path [watch] |
查看当前节点数据并能看到更新次数等数据 |
|
create |
普通创建 -s 含有序列 -e 临时(重启或者超时消失) |
|
get path [watch] |
获得节点的值 |
|
set |
设置节点的具体值 |
|
stat |
查看节点状态 |
|
delete |
删除节点 |
|
rmr |
递归删除节点 |
7.
- Stat结构体
1)czxid-创建节点的事务zxid
每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID。
事务ID是ZooKeeper中所有修改总的次序。每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生。
2)ctime - znode被创建的毫秒数(从1970年开始)
3)mzxid - znode最后更新的事务zxid
4)mtime - znode最后修改的毫秒数(从1970年开始)
5)pZxid-znode最后更新的子节点zxid
6)cversion - znode子节点变化号,znode子节点修改次数
7)dataversion - znode数据变化号
8)aclVersion - znode访问控制列表的变化号
9)ephemeralOwner- 如果是临时节点,这个是znode拥有者的session id。如果不是临时节点则是0。
10)dataLength- znode的数据长度
11)numChildren - znode子节点数量
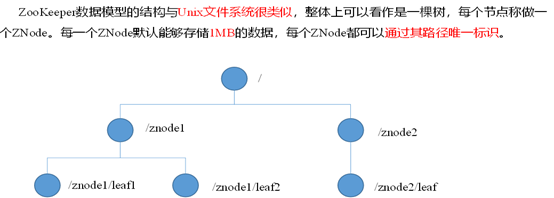
8. 四种节点类型
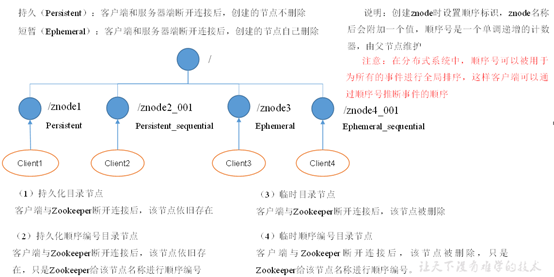
9. 监听器原理
 。
。
10. Paxos算法
11. 选举机制
1)半数机制:集群中半数以上机器存活,集群可用。所以Zookeeper适合安装奇数台服务器
2)Zookeeper虽然在配置文件中并没有指定Master和Slave。但是,Zookeeper工作时,是有一个节点为Leader,其他则为Follower,Leader是通过内部的选举机制临时产生的。
3)以一个简单的例子来说明整个选举的过程。
假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动

(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的ID比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
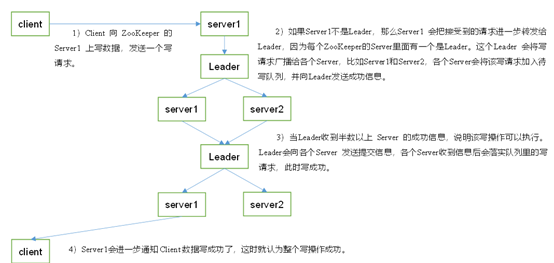
12. Zookeeper写数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号