
使用DQN实现AI自动玩FlappyBird
DQN是强化学习的系列方法之一。
这里简单介绍一下强化学习,强化学习是以一种不断“试错”的方式,通过与环境的交互获得的奖赏指导行为,从而使模型获得最大化奖赏,由于外部环境提供的强化信号仅仅是对模型动作的一种评价,强化学习必须靠自身的经历进行学习,通过这种方式,模型得以从行动-评价的环境中学到知识,从而改善自身。DQN是传统的强化学习方法Q-Learning和Deep-Learning的结合体。
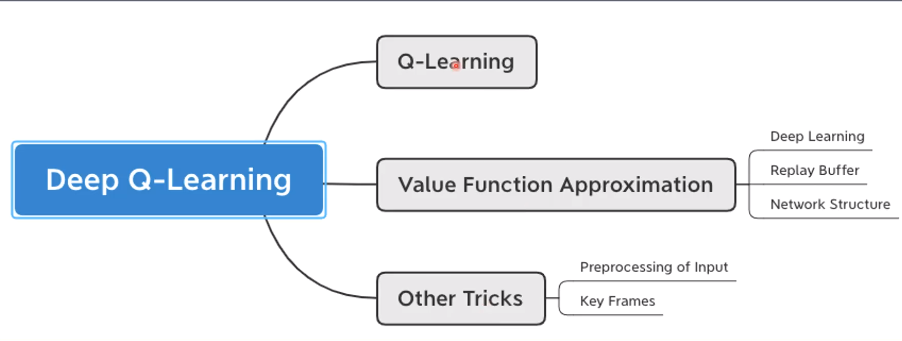
读者可按照上知识树对DQN进行学习。
网络结构代码如下:
1 def Net(): 2 state_shape, action_dim = [80, 80, 4], 2 3 actions = Input([action_dim]) 4 state = Input(state_shape) 5 6 x = Conv2D(32, kernel_size=8, strides=4, padding="same")(state) 7 x = Activation("relu")(x) 8 x = MaxPool2D(pool_size=2)(x) 9 10 x = Conv2D(64, kernel_size=4, strides=2, padding="same")(x) 11 x = Activation('relu')(x) 12 13 x = Conv2D(64, kernel_size=3, strides=1, padding="same")(x) 14 x = Activation('relu')(x) 15 16 x = Flatten()(x) 17 x = Dense(512)(x) 18 x = Activation('relu')(x) 19 20 out1 = Dense(action_dim)(x) 21 22 out2 = Dot(-1)([actions, out1]) 23 model = keras.Model([state, actions], out2) 24 optimizer = keras.optimizers.Adam(1e-6) 25 # optimizer = keras.optimizers.SGD(lr=1e-5, decay=1e-6, momentum=0.9, nesterov=True) 26 loss = keras.losses.mse 27 model.compile(optimizer=optimizer, loss=loss) 28 model.summary() 29 return model
最终训练280epoch之后(每个epoch训练10000帧图像),结果如图:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号