mnist识别优化——使用新的fashion mnist进行模型训练
今天通过论坛偶然知道,在mnist之后,还出现了一个旨在代替经典mnist数据集的Fashion MNIST,同mnist一样,它也是被用作深度学习程序的“hello world”,而且也是由70k张28*28的图片组成的,它们也被分为10类,有60k被用作训练,10k被用作测试。唯一的区别就是,fashion mnist的十种类别由手写数字换成了服装。这十种类别如下:
'T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat','Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot'
设计流程如下:
· 首先获取数据集,tensorflow获取fashion mnist的方法和mnist类似,使用keras.datasets.fashion_mnist.load_data()即可
· 将数据集划分为训练集和测试集
· 由于图片像素值范围是0-255,将数据集进行预处理,把像素值缩放到0到1的范围(即除以255)
· 搭建网络模型 (784→128(relu)→10(softmax)),全连接
· 编译模型,设计损失函数(对数损失)、优化器(adam)以及训练指标(accuracy)
· 训练模型
· 评估准确性(测试数据使用matplotlib进行可视化)
关于Adam优化器的来源和特点请参考:https://www.jianshu.com/p/aebcaf8af76e
关于matplotlib数据可视化请参考:https://blog.csdn.net/xHibiki/article/details/84866887
训练集部分数据可视化如下:

一共做了50轮训练,训练开始时的损失和精度如下:
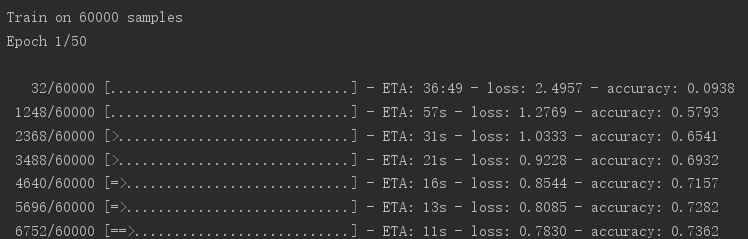
训练完成时的损失和精度如下:

模型在测试集上的表现如下:

选择测试集某张图片的预测可视化结果如下:
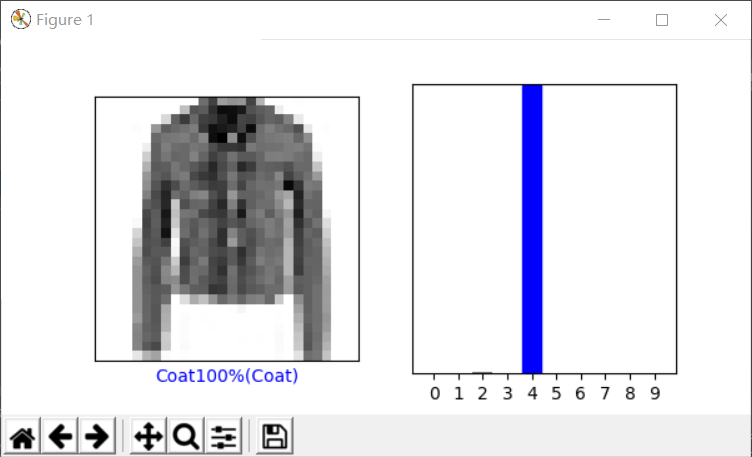
程序代码如下:
1 import tensorflow as tf 2 from tensorflow import keras 3 import numpy as np 4 import matplotlib.pyplot as plt 5 6 # 导入fashion mnist数据集 7 fashion_mnist = keras.datasets.fashion_mnist 8 (train_images,train_labels),(test_images,test_labels) = fashion_mnist.load_data() 9 10 # 衣服类别 11 class_names = ['T-shirt/top','Trouser','Pullover','Dress','Coat','Sandal', 12 'Shirt','Sneaker','Bag','Ankle boot'] 13 print(train_images.shape,len(train_labels)) 14 print(test_images.shape,len(test_labels)) 15 16 # 查看图片 17 plt.figure() 18 plt.imshow(train_images[0]) 19 plt.colorbar() 20 plt.grid(False) 21 plt.show() 22 23 # 预处理数据,将像素值除以255,使其缩放到0到1的范围 24 train_images = train_images / 255.0 25 test_images = test_images / 255.0 26 27 # 验证数据格式的正确性,显示训练集前25张图像并注明类别 28 plt.figure(figsize=(10,10)) 29 for i in range(25): 30 plt.subplot(5,5,i+1) 31 plt.xticks([]) 32 plt.yticks([]) 33 plt.grid(False) 34 plt.imshow(train_images[i],cmap=plt.cm.binary) 35 plt.xlabel(class_names[train_labels[i]]) 36 plt.show() 37 38 # 搭建网络结构 39 model = keras.Sequential([ 40 keras.layers.Flatten(input_shape=(28,28)), 41 keras.layers.Dense(128,activation='relu'), 42 keras.layers.Dense(10,activation='softmax') 43 ]) 44 45 # 设置损失函数、优化器及训练指标 46 model.compile( 47 optimizer='adam', 48 loss='sparse_categorical_crossentropy', 49 metrics=['accuracy'] 50 ) 51 52 # 训练模型 53 model.fit(train_images,train_labels,epochs=50) 54 55 # 模型评估 56 test_loss,test_acc=model.evaluate(test_images,test_labels,verbose=2) 57 print('/nTest accuracy:',test_acc) 58 59 # 选择测试集中的图像进行预测 60 predictions=model.predict(test_images) 61 62 # 查看第一个预测 63 print("预测结果:",np.argmax(predictions[0])) 64 # 将正确标签打印出来和预测结果对比 65 print("真实结果:",test_labels[0]) 66 67 # 以图形方式查看完整的十个类的预测 68 def plot_image(i,predictions_array,true_label,img): 69 predictions_array,true_label,img=predictions_array,true_label[i],img[i] 70 plt.grid(False) 71 plt.xticks([]) 72 plt.yticks([]) 73 74 plt.imshow(img,cmap=plt.cm.binary) 75 76 predicted_label=np.argmax(predictions_array) 77 if predicted_label==true_label: 78 color='blue' 79 else: 80 color='red' 81 82 plt.xlabel("{}{:2.0f}%({})".format(class_names[predicted_label], 83 100*np.max(predictions_array), 84 class_names[true_label]), 85 color=color) 86 87 def plot_value_array(i,predictions_array,true_label): 88 predictions_array,true_label=predictions_array,true_label[i] 89 plt.grid(False) 90 plt.xticks(range(10)) 91 plt.yticks([]) 92 thisplot=plt.bar(range(10),predictions_array,color="#777777") 93 plt.ylim([0,1]) 94 predicted_label=np.argmax(predictions_array) 95 96 thisplot[predicted_label].set_color('red') 97 thisplot[true_label].set_color('blue') 98 99 i=10 100 plt.figure(figsize=(6,3)) 101 plt.subplot(1,2,1) 102 plot_image(i,predictions[i],test_labels,test_images) 103 plt.subplot(1,2,2) 104 plot_value_array(i,predictions[i],test_labels) 105 plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号