垃圾回收算法介绍
垃圾回收算法介绍
在早期的C/C++时代,垃圾回收基本上是手工进行的。开发人员可以使用new关键字进行内存申请,并使用delete关键字进行内存释放。比如下面代码:
MibBiridge *pBridge = new cmBaseGroupBridge();
if (pBridge->Register(kDestroy)!=NO_ERROR)
delete pBridge;
上述代码通过new关键字申请一块对象空间,然后对对象进行注册,如果注册失败的话,就将这块空间释放掉;
为了使程序员可以从繁重的内存管理中释放出来,因此设计了垃圾回收机制,有了垃圾回收机制,上述代码块可能变成这样:
MibBiridge *pBridge = new cmBaseGroupBridge();
pBridge->Register(kDestroy);
开发人员只需要关注内存的申请,内存的释放就交给虚拟机自动执行;
下面介绍垃圾回收用到的算法
引用计数法
原理:为每个对象配备一个整形的计数器,假如有一个对象A,当有一个对象引用了A,则A的计数器加一,当 有一个引用失效时计数器就减一。计数器值为0的对象都是可回收对象。
缺点:
-
无法处理循环引用的情况。例如:对象A引用对象B,对象B引用对象A,这两个对象计数器值都为1,所以无法回收,但是这两个对象和主要程序是没有引用关系的,应该是要回收的。因为这个原因所以java虚拟机中没有采用这种算法。
-
每次引用和消除需要伴随一个加法操作和减法操作,对系统性能的影响较大
标记清除法
原理:首先通过根节点,标记所有可达对象(指通过根对象进行引用搜索,最终可以达到的对象)。因此,未被标记的对象就是未被引用的垃圾对象。然后,对没有被标记的对象进行清除。
缺点:
- 会产生很多空间碎片
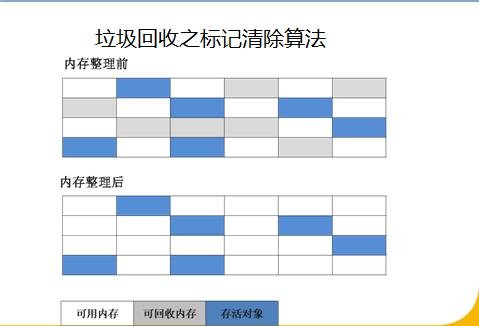
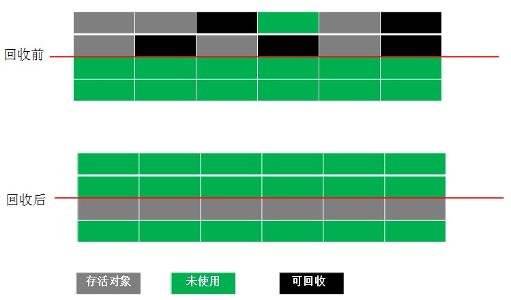
复制算法
原理:将原来的内存空间分为两块,每次只用其中一块,将在垃圾回收时,将正在使用的内存中的存活对象(看资料没有明白到底是使用什么方法判断存活对象的,我的理解是根据GC Root(根对象)向下搜索对象,搜索走过的对象称为引用链,将引用链的对象都复制到未使用的内存块中,不需要遍历所有对象)复制到未使用的内存块中。然后原来的内存块剩下的就都是垃圾对象,进行全部清除。因此需要回收的对象多,则需要复制的对象少,复制算法效率就越高。
缺点:
- 浪费一般的内存空间
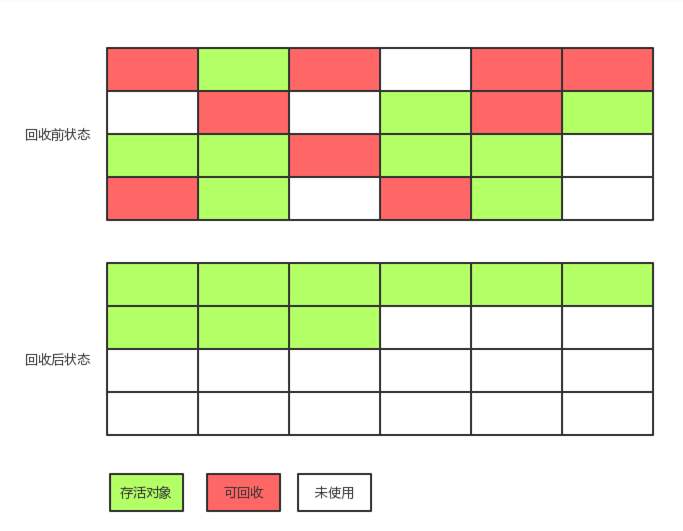
改进复制算法
原来的复制算法对空间浪费太严重了,在java新生代串行垃圾回收器中,对复制算法进行了改进。新生代分为eden区,from区和to区3部分,其中from区和to区像原来的复制算法一样,每次GC进行角色互换,互相复制,这两个区也叫survivor区。对于比原来多出来的eden区,每次GC时,都将eden区中存活的对象复制到from区/to区(使用哪个区就复制到哪个区)。也就是每次都是从eden区和from区复制到to区或者从eden区和to区复制到from区。
这种改进的复制算法有什么优点:
- 保留了原来复制算法的空间连续性的优点
- 又避免的大量的内存空间浪费
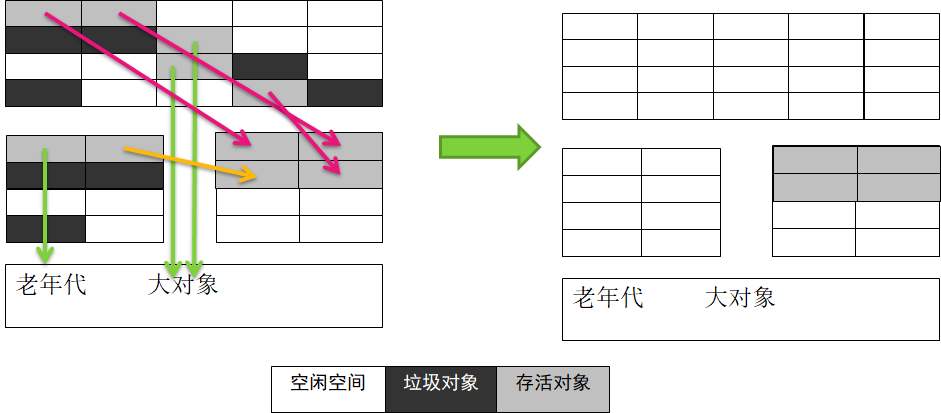
标记压缩法
标记压缩法是一种老年代的回收算法,它在标记清除算法的基础上做了一些优化。就是在进行完标记后,不急着清除未标记对象,而是将标记的不连续的存活对象压缩到内存块的一端,然后清理其他的内存空间。
优点:
- 避免了碎片的产生
分代算法
分代算法将堆空间分为新生代和老年代,所有新建对象都会放入新生代的内存区域,大约90%的新建对象会很快被回收,因此新生代适合使用复制算法。对象经过几次回收后,依然存活的话就会进入老年区,老年区一般使用标记清除算法和标记压缩算法。
-
卡表
为了支持新生代的高频率的新生代回收,虚拟机使用一种叫卡表的数据结构。卡表是一个比特位的集合,每个比特位用来表示老年代的某一区域的对象是否有对新生代对象的引用。当卡表的标记位为1的时候,表示有对新生代的引用,当为0是,没有对新生代的引用。所以当需要进行新生代GC时,只要扫描卡表位为1的老年代空间即可,这样可以大大加快新生代的回收速度。
分区算法
分区算法将整个堆空间划分成连续的不同的小区间。每个区间都独立使用、独立回收。这种算法可以控制一次回收多少个小区间。相同条件下,堆空间越大,一次GC时所需要的时间就越长,从而产生停顿也越长,分区算法可以分局期待停顿时间,每次合理地回收若干个小区间,而不是整个堆空间,从而减少一次GC所产生的停顿时间。


