python+unittest+ddt数据驱动进行接口自动化测试
所谓数据驱动测试,简单的理解为数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变。通过使用数据驱动测试的方法,可以在需要验证多组数据测试场景中,使用外部数据源实现对输入输出与期望值的参数化,避免在测试中使用硬编码的数据。因此只需要创建一个测试脚本就可以处理上表的测试数据和条件的组合,使用数据驱动的模式,根据业务逻辑分解测试数据,并且定义变量,使用外部的excel里的数据使其参数化,从而避免使用源测试脚本中的固定数据,这种方式可以将测试脚本与测试数据分开,使得测试脚本在不同的数据集合下高度复用。
数据驱动的模式不仅可以帮助增加类似复杂条件场景下的测试覆盖,还可以极大的减少对测试代码的编写和维护工作。
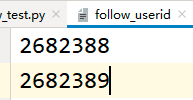
如下业务是:用户登录某个软件系统后,对其他用户进行关注。具体流程是:调用登录接口获取session,然后调取关注接口把session和userid作为参数进行传递,我们把需要关注的用户的userid存放在一个文件中,作为驱动数据。如下两个userid:
# 定义一个函数,获取数据,并且把每组数据作为一个列表放在一个大列表中。
def test_data(path):
with open(path, encoding="utf-8", mode="r") as f:
data = f.readlines()
mydata = []
for line in data:
new_line = []
new_line.append(line.strip())
mydata.append(new_line)
f.close()
return mydata
返回的结果:[['2682388'], ['2682389']]
首先导入需要用到的API
import requests
import unittest
import json
from ddt import ddt, data, unpack # ddt需要通过pip安装
# 获取登录session
def login():
login_url = "http://xxx/xxx/xxx/xxx/login_process/"
data = {"user_name": "xxx",
"avatar_file": "xxx",
"mobile": "12233445567"
}
# 获取返回信息
content = requests.post(login_url, data=data)
# 将bytes类型转换为字典
re = json.loads(content.text)
return re["rsm"]["yme__user_login"], re["rsm"]["yme__Session"]
@ddt # 定义ddt数据驱动
class AFollow(unittest.TestCase):
# 初始化测试用例
def setUp(self) -> None:
# 被测接口地址
self.follow_url = "http://xxx/xxx/xxx/xxx/user_follow/"
def tearDown(self) -> None:
pass
@data(*test_data(r"\\data\follow_userid")) # 获取测试数据,对数据解包前面需要一个*
@unpack 对数据进行解包,解包后数据就变成了这种形式:['2682388'], ['2682389'],每组数据就是一条测试用例
def test_case01(self, user_id):
# 定义需要传入的参数,程序运行时这条用例会执行两次,
# 分别['2682388']和['2682389']作为测试数据执行测试
"""
关注新用户
"""
content = requests.post(self.follow_url, self.get_session(user_id))
print(json.loads(content.text), type(json.loads(content.text)))
re = json.loads(content.text)
self.assertEqual(re["rsm"]["msg"], "关注成功") # 断言
@data(*test_data(r"\\data\follow_userid"))
@unpack
def test_case02(self, user_id):
"""
关注已经关注的用户(重复关注用户)
"""
content = requests.post(self.follow_url, self.get_session(user_id))
print(json.loads(content.text), type(json.loads(content.text)))
re = json.loads(content.text)
self.assertEqual(re["rsm"]["msg"], "关注失败")
@ddt
class CancelFollow(unittest.TestCase):
def setUp(self) -> None:
self.cancel_follow_url = ""http://xxx/xxx/xxx/xxx/user_follow_del/"
def tearDown(self) -> None:
pass
@data(*test_data(r"\\data\follow_userid"))
@unpack
def test_case01(self, user_id):
"""
取消关注用户
"""
content = requests.post(self.cancel_follow_url, self.get_session(user_id))
print(json.loads(content.text), type(json.loads(content.text)))
re = json.loads(content.text)
self.assertEqual(re["rsm"]["msg"], "取消关注成功", "取消关注失败!")
if __name__ == '__main__':
unittest.main()
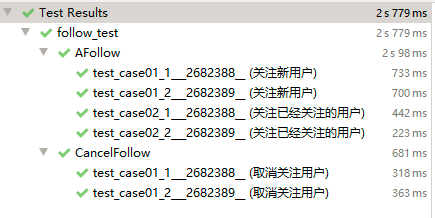
运行测试成功
![]()
再调试的过程中遇到了如下错误:
wrapper
add_test(
TypeError: add_test() argument after ** must be a mapping, not str
def test_data(path):
with open(path, encoding="utf-8", mode="r") as f:
data = f.readlines()
mydata = []
for line in data:
mydata.append(line.strip())
f.close()
return mydata
返回结果:['2682388', '2682389']
原因是,在获取数据时,没有将每组数据单独存放在一个列中,解包后测试数据变成了字符串。
所以需要把每组数据放在一个列表中,再把所有组数据放在一个大列表中,也可以放在元组中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号