
多线程与高并发 Synchronize
(1)概念:计算机的核心是CPU,它承担了所有的计算任务。它就像一座工厂,时刻在运行。假定工厂的电力有限,一次只能供给一个车间使用。也就是说,一个车间开工的时候,其他的车间必须停工。背后的含义就是,单个CPU一次只能运行一个任务。
- 进程就好比工厂车间,它代表CPU所能处理的单个任务。任一时刻,CPU总是运行一个进程,其它进程处于非运行状态
- 一个车间里,可以有很多工人。他们协同完成一个任务!(线程就好比车间里的工人。一个进程可以包括多个线程)
- 车间里的空间是工人们共享的,比如许多房间是每个工人都可以进出的。这象征一个进程的内存空间是共享的,每个线程都可以使用这些共享内存
- 可是每个房间的大小不同,有些房间最多只能容纳一个人,比如厕所。里面有人的时候,其他人就不能进去了。这代表一个线程使用某些共享内存时,其他线程必须等他结束,才能使用这一块内存
- 一个防止他人进入的简单方法,就是门口加一把锁。先到的人锁上门,后到的人看到上锁,就在门口排队,等锁打开在进去。这就叫“互斥锁”(Mutual exclusion,缩写Mutex),防止多个线程同时读写某一块内存区域
- 还有些房间,可以同时容纳n个人,比如厨房。也就是说,如果人数大于n,多出来的人只能在外面等着。这好比某些内存区域,只能供给固定数目的线程使用
- 解决方法,就在门口挂n把锁。进去的人就取一把钥匙,出来时再把钥匙挂回原处。后到的人发现钥匙架空了,就知道必须在门口排队等着了。这种做法就叫“信号量”(Semaphore),用来保证多个线程不会互相冲突
(2)创建线程的几种方式:
https://www.cnblogs.com/xiaoxi/p/8303574.html(Future Callable FutureTask)讲解
package day_01; import java.util.concurrent.*; /** * @author: zdc * @date: 2020-03-18 */ public class _1HowToCreateThread { //1.继承Thread类,覆写run方法 static class MyThread extends Thread { @Override public void run() { System.out.println("hello mythread"); } } //2.实现Runnable接口,实现run方法 static class MyRun implements Runnable{ @Override public void run() { System.out.println("hello myrun"); } } //3.实现Callable接口,实现call方法 static class MyCall implements Callable<String>{ @Override public String call() throws Exception { System.out.println("hello mycall"); return "sucess"; } } public static void main(String[] args) throws ExecutionException, InterruptedException { //1 new MyThread().start(); //2 new Thread(new MyRun()).start(); //3 new Thread(()-> System.out.println("hello my lambda")); //4 futuretask callable FutureTask<String> futureTask = new FutureTask<>(new MyCall()); Thread t = new Thread(futureTask); t.start(); System.out.println(futureTask.get()); //阻塞式 //5 future callable threadpool ExecutorService executorService = Executors.newCachedThreadPool(); Future<String> future = executorService.submit(new MyCall()); System.out.println(future.get()); //6 submit有返回值,而execute没有 runnable threadpool executorService.execute(new MyRun()); executorService.shutdown(); } }
(3) yield join讲解
yield()方法:暂停当前正在执行的线程对象,并执行其他线程。
yield()应该做的是让当前运行线程回到可运行状态,以允许具有相同优先级的其他线程获得运行机会。因此,使用yield()的目的是让相同优先级的线程之间能适当的轮转执行。但是,实际中无法保证yield()达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。
结论:yield()从未导致线程转到等待/睡眠/阻塞状态。在大多数情况下,yield()将导致线程从运行状态转到可运行状态,但有可能没有效果。
jion()方法:线程实例的join()方法可以使得一个线程在另一个线程结束后再执行,即也就是说使得被调用的线程可以阻塞当前线程执行;
thread.Join把指定的线程加入到当前线程,可以将两个交替执行的线程合并为顺序执行的线程。
比如在线程B中调用了线程A的Join()方法,直到线程A执行完毕后,才会继续执行线程B。
package day_01; import java.util.Timer; import java.util.concurrent.TimeUnit; /** * @author: zdc * @date: 2020-03-18 */ public class _2YieldAndJoin { public static void main(String[] args) { // testYied(); testJoin(); } /* Thread.yield()方法作用是:暂停当前正在执行的线程对象,并执行其他线程。 yield()应该做的是让当前运行线程回到可运行状态,以允许具有相同优先级的其他线程获得运行机会。 因此,使用yield()的目的是让相同优先级的线程之间能适当的轮转执行。但是,实际中无法保证yield()达到让步目的, 因为让步的线程还有可能被线程调度程序再次选中。 结论:yield()从未导致线程转到等待/睡眠/阻塞状态。在大多数情况下,yield()将导致线程从运行状态转到可运行状态,但有可能没有效果。*/ public static void testYied(){ new Thread(()->{ for (int i = 0; i < 100; i++) { System.out.println("A"+i); if (i%10==0) Thread.yield(); } }).start(); new Thread(()->{ for (int i = 0; i < 10; i++) { System.out.println("B"+i); if (i%10==0) Thread.yield(); } }).start(); } //当前线程调用别的线程join后,当前线程会等待被调用的线程运行完再去执行。 static void testJoin(){ Thread t1 = new Thread(()->{ for (int i = 0; i < 10; i++) { System.out.println("a"+i); try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } }); t1.start(); new Thread(()->{ for (int i = 0; i < 100; i++) { System.out.println("b"+i); if(i==5){ try { t1.join(); } catch (InterruptedException e) { e.printStackTrace(); } } try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } }).start(); } }
(4)线程的状态转换
1:新建状态 当我们new出一个线程 并,并没有start时
2:Runnable状态:当线程调用start方法后。 此时又可分为Ready就绪态和Running运行态。
- 就绪态:线程被扔进CPU的等待队列排队等待执行
- 运行态:当CPU真正运行该线程时。
package day_01; import java.util.concurrent.TimeUnit; /** * @author: zdc * @date: 2020-03-18 */ public class _3ThreadState { public static void main(String[] args) { Thread thread = new Thread(new MyRunnable()); System.out.println(thread.getState()); thread.start(); System.out.println(thread.getState()); } static class MyRunnable implements Runnable{ @Override public void run() { for (int i = 0; i < 10; i++) { System.out.println("hahah"); try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } } } }
3:Terminated结束状态
4:在Runnable这个状态中有一些其他状态的变迁。
- TimedWaiting等待 Thread.Sleep() 、TimeUnit.SECONDS.sleep() 、o.wait(time)等
- Waiting等待 o.wait() t.jion() lockSupport.park()等
线程挂起的概念:CPU调度执行线程时。从runing态扔出去就叫挂起。
(5)wait和notify的区别
最主要是sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。
sleep不出让系统资源;wait是进入线程等待池等待,出让系统资源,其他线程可以占用CPU。一般wait不会加时间限制,因为如果wait线程的运行资源不够,再出来也没用,要等待其他线程调用notify/notifyAll唤醒等待池中的所有线程,才会进入就绪队列等待OS分配系统资源。sleep(milliseconds)可以用时间指定使它自动唤醒过来,如果时间不到只能调用interrupt()强行打断。
Thread.Sleep(0)的作用是“触发操作系统立刻重新进行一次CPU竞争”。
(6)sychronized
1.只给写加锁,而未给读加锁,会产生脏读现象。
2.sychronized是可重入的 m1(m2) m1和m2方法都加了相同的锁。 锁对象上有数字记录加了几次。
3.异常锁:当程序出现异常后,锁将被释放。 因次需要在出现异常处catch处理。
package day_01; import java.util.concurrent.TimeUnit; /** * @author: zdc * @date: 2020-03-18 */ public class _5Account { String name; double balance; public synchronized void set(String name, double balance) throws InterruptedException { this.name = name; TimeUnit.SECONDS.sleep(2); this.balance = balance; } public double getBalance(String name) { return this.balance; } public static void main(String[] args) throws InterruptedException { _5Account account = new _5Account(); new Thread(() -> { try { account.set("zzz", 58); } catch (InterruptedException e) { e.printStackTrace(); } }).start(); TimeUnit.SECONDS.sleep(1); System.out.println(account.getBalance("zzz")); TimeUnit.SECONDS.sleep(1); System.out.println(account.getBalance("zzz")); } }
sychronized锁升级的概念
Synchronized实现原理
我们要知道对象在内存中的布局:
已知对象是存放在堆内存中的,对象大致可以分为三个部分,分别是对象头、实例变量和填充字节
知对象是存放在堆内存中的,对象大致可以分为三个部分,分别是对象头、实例变量和填充字节。
对象头的主要是由MarkWord和Klass Point(类型指针)组成,其中Klass Point是是对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例,Mark Word用于存储对象自身的运行时数据。如果对象是数组对象,那么对象头占用3个字宽(Word),如果对象是非数组对象,那么对象头占用2个字宽。(1word = 2 Byte = 16 bit)
实例变量存储的是对象的属性信息,包括父类的属性信息,按照4字节对齐
填充字符,因为虚拟机要求对象字节必须是8字节的整数倍,填充字符就是用于凑齐这个整数倍的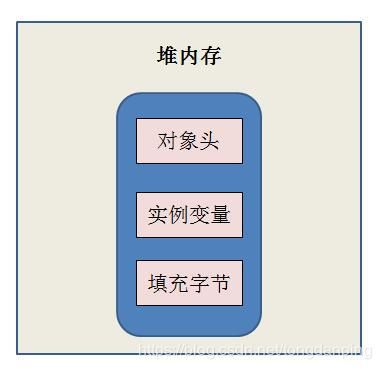
Synchronized不论是修饰方法还是代码块,都是通过持有修饰对象的锁来实现同步,那么Synchronized锁对象是存在哪里的呢?答案是存在锁对象的对象头的MarkWord中。那么MarkWord在对象头中到底长什么样,也就是它到底存储了什么呢?
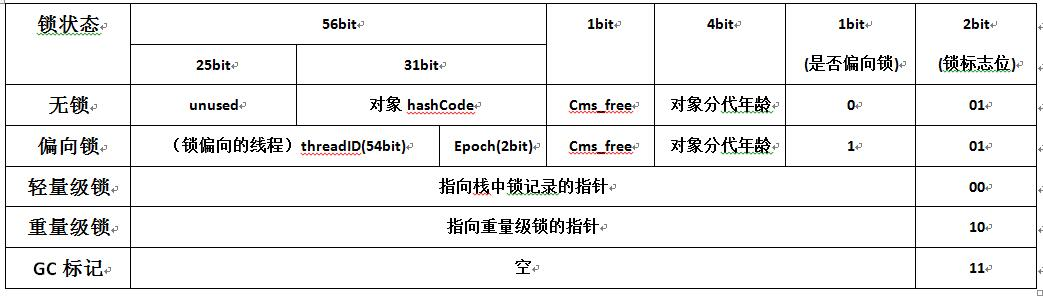
锁升级
https://blog.csdn.net/tongdanping/article/details/79647337
锁的4中状态:无锁状态、偏向锁状态、轻量级锁状态(自旋锁)、重量级锁状态
(1)偏向锁:
为什么要引入偏向锁?
因为经过HotSpot的作者大量的研究发现,大多数时候是不存在锁竞争的,常常是一个线程多次获得同一个锁,因此如果每次都要竞争锁会增大很多没有必要付出的代价,为了降低获取锁的代价,才引入的偏向锁。
偏向锁的升级
当线程1访问代码块并获取锁对象时,会在java对象头和栈帧中记录偏向的锁的threadID,因为偏向锁不会主动释放锁,因此以后线程1再次获取锁的时候,需要比较当前线程的threadID和Java对象头中的threadID是否一致,如果一致(还是线程1获取锁对象),则无需使用CAS来加锁、解锁;如果不一致(其他线程,如线程2要竞争锁对象,而偏向锁不会主动释放因此还是存储的线程1的threadID),那么需要查看Java对象头中记录的线程1是否存活,如果没有存活,那么锁对象被重置为无锁状态,其它线程(线程2)可以竞争将其设置为偏向锁;如果存活,那么立刻查找该线程(线程1)的栈帧信息,如果还是需要继续持有这个锁对象,那么暂停当前线程1,撤销偏向锁,升级为轻量级锁,如果线程1 不再使用该锁对象,那么将锁对象状态设为无锁状态,重新偏向新的线程。
偏向锁的取消:
偏向锁是默认开启的,而且开始时间一般是比应用程序启动慢几秒,如果不想有这个延迟,那么可以使用-XX:BiasedLockingStartUpDelay=0;
如果不想要偏向锁,那么可以通过-XX:-UseBiasedLocking = false来设置;
(2)轻量级锁(自旋锁)
为什么要引入轻量级锁?
轻量级锁考虑的是竞争锁对象的线程不多,而且线程持有锁的时间也不长的情景。因为阻塞线程需要CPU从用户态转到内核态,代价较大,如果刚刚阻塞不久这个锁就被释放了,那这个代价就有点得不偿失了,因此这个时候就干脆不阻塞这个线程,让它自旋这等待锁释放。
轻量级锁什么时候升级为重量级锁?
线程1获取轻量级锁时会先把锁对象的对象头MarkWord复制一份到线程1的栈帧中创建的用于存储锁记录的空间(称为DisplacedMarkWord),然后使用CAS把对象头中的内容替换为线程1存储的锁记录(DisplacedMarkWord)的地址;
如果在线程1复制对象头的同时(在线程1CAS之前),线程2也准备获取锁,复制了对象头到线程2的锁记录空间中,但是在线程2CAS的时候,发现线程1已经把对象头换了,线程2的CAS失败,那么线程2就尝试使用自旋锁来等待线程1释放锁。
但是如果自旋的时间太长也不行,因为自旋是要消耗CPU的,因此自旋的次数是有限制的,比如10次或者100次,如果自旋次数到了线程1还没有释放锁,或者线程1还在执行,线程2还在自旋等待,这时又有一个线程3过来竞争这个锁对象,那么这个时候轻量级锁就会膨胀为重量级锁。重量级锁把除了拥有锁的线程都阻塞,防止CPU空转。
*注意:为了避免无用的自旋,轻量级锁一旦膨胀为重量级锁就不会再降级为轻量级锁了;偏向锁升级为轻量级锁也不能再降级为偏向锁。一句话就是锁可以升级不可以降级,但是偏向锁状态可以被重置为无锁状态。
(3)这几种锁的优缺点(偏向锁、轻量级锁、重量级锁)

锁粗化
按理来说,同步块的作用范围应该尽可能小,仅在共享数据的实际作用域中才进行同步,这样做的目的是为了使需要同步的操作数量尽可能缩小,缩短阻塞时间,如果存在锁竞争,那么等待锁的线程也能尽快拿到锁。
但是加锁解锁也需要消耗资源,如果存在一系列的连续加锁解锁操作,可能会导致不必要的性能损耗。
锁粗化就是将多个连续的加锁、解锁操作连接在一起,扩展成一个范围更大的锁,避免频繁的加锁解锁操作。
锁消除
Java虚拟机在JIT编译时(可以简单理解为当某段代码即将第一次被执行时进行编译,又称即时编译),通过对运行上下文的扫描,经过逃逸分析,去除不可能存在共享资源竞争的锁,通过这种方式消除没有必要的锁,可以节省毫无意义的请求锁时间
(7)volatile https://www.jianshu.com/p/ccfe24b63d87
如果一个变量被volatile修饰了,那么肯定可以保证每次读取这个变量值的时候得到的值是最新的,但是一旦需要对变量进行自增这样的非原子操作,就不会保证这个变量的原子性了。
举个栗子
一个变量i被volatile修饰,两个线程想对这个变量修改,都对其进行自增操作也就是i++,i++的过程可以分为三步,首先获取i的值,其次对i的值进行加1,最后将得到的新值写会到缓存中。
线程A首先得到了i的初始值100,但是还没来得及修改,就阻塞了,这时线程B开始了,它也得到了i的值,由于i的值未被修改,即使是被volatile修饰,主存的变量还没变化,那么线程B得到的值也是100,之后对其进行加1操作,得到101后,将新值写入到缓存中,再刷入主存中。根据可见性的原则,这个主存的值可以被其他线程可见。
问题来了,线程A已经读取到了i的值为100,也就是说读取的这个原子操作已经结束了,所以这个可见性来的有点晚,线程A阻塞结束后,继续将100这个值加1,得到101,再将值写到缓存,最后刷入主存,所以即便是volatile具有可见性,也不能保证对它修饰的变量具有原子性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号