加州高速路网PeMS数据下载
1.查看交通监测站点分布
需要先注册账号
点击Inventory
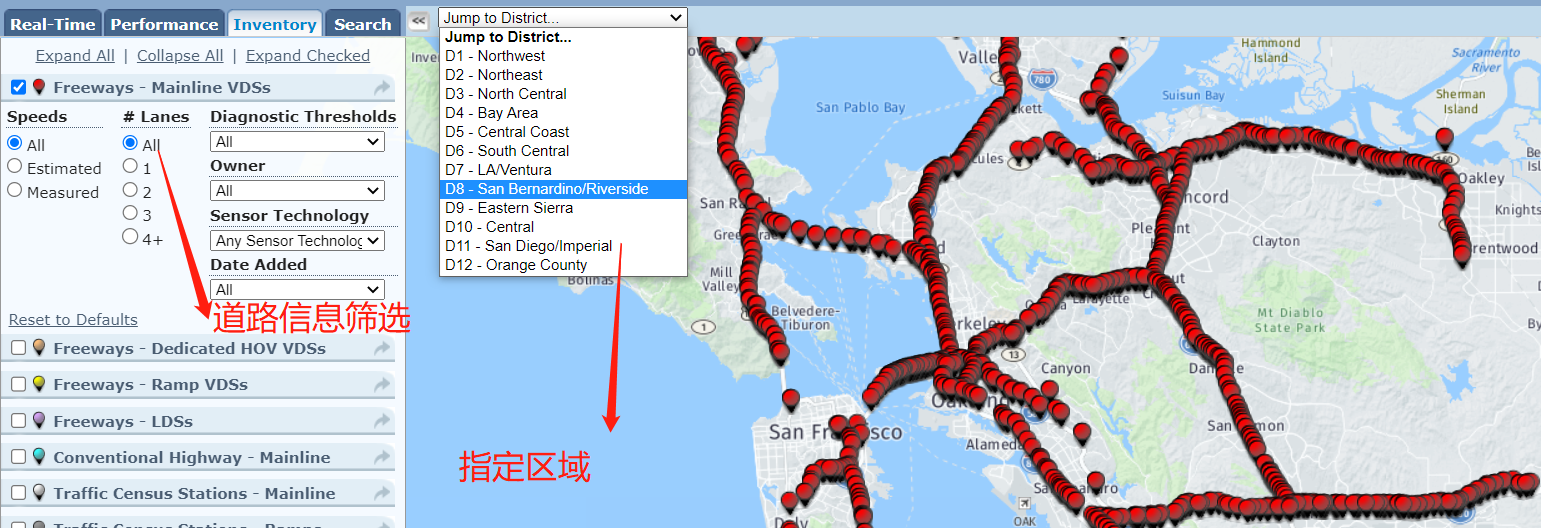
Lanes:如果选2,假设道路方向从东到西,就代表这条道路上包括两个可行使车道(比如慢车道和快车道)
2.下载指定车辆检测站点的交通数据
方式1:
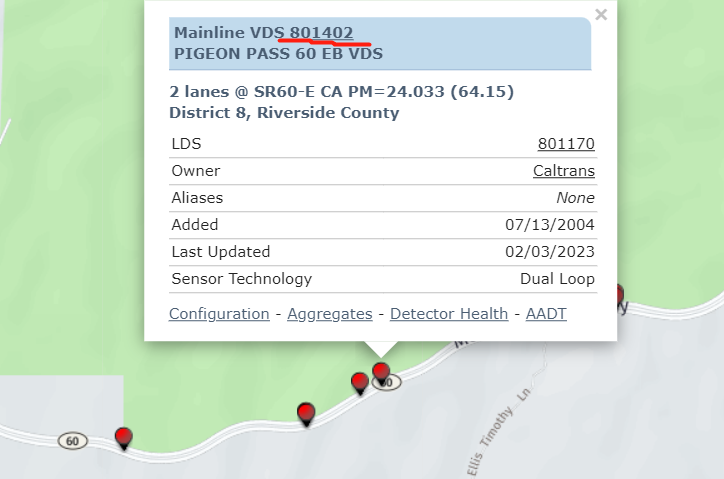
第一步:选中要下载的车辆检测站点的编号并点击
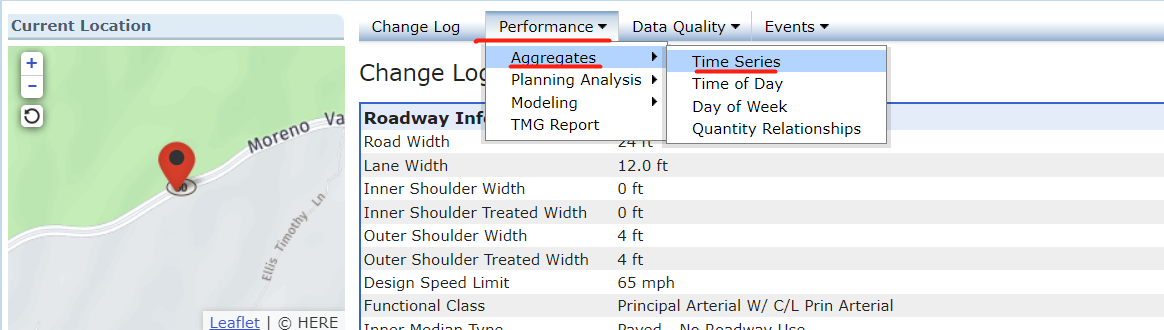
第二步:找到页面跳转后的Time Series
第三步:设置条件,导出数据文件
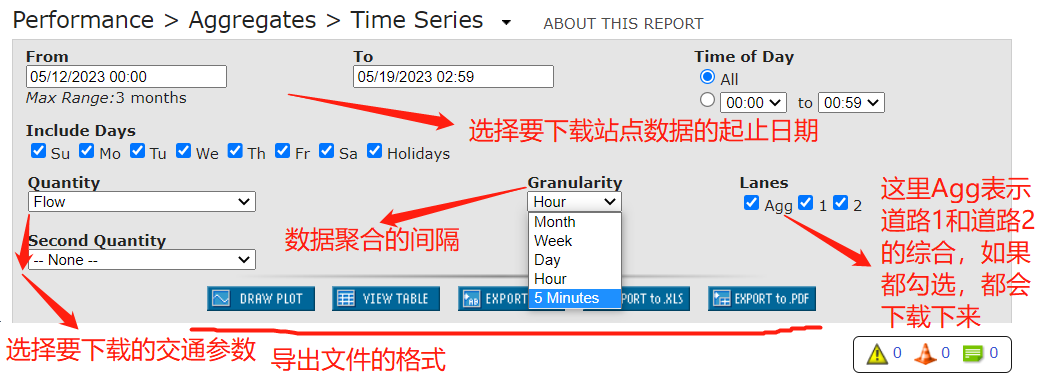
方式一缺陷:如果要下载以5Minutes为聚合时间的数据每次好像只让下载一周的,如果下载长时间的话,需要分多次下载。
方式2:直接下载数据文件
第一步:在主页home页面找到Data Clearinghouse并点击
第二步:筛选要下载的数据文件,进行下载
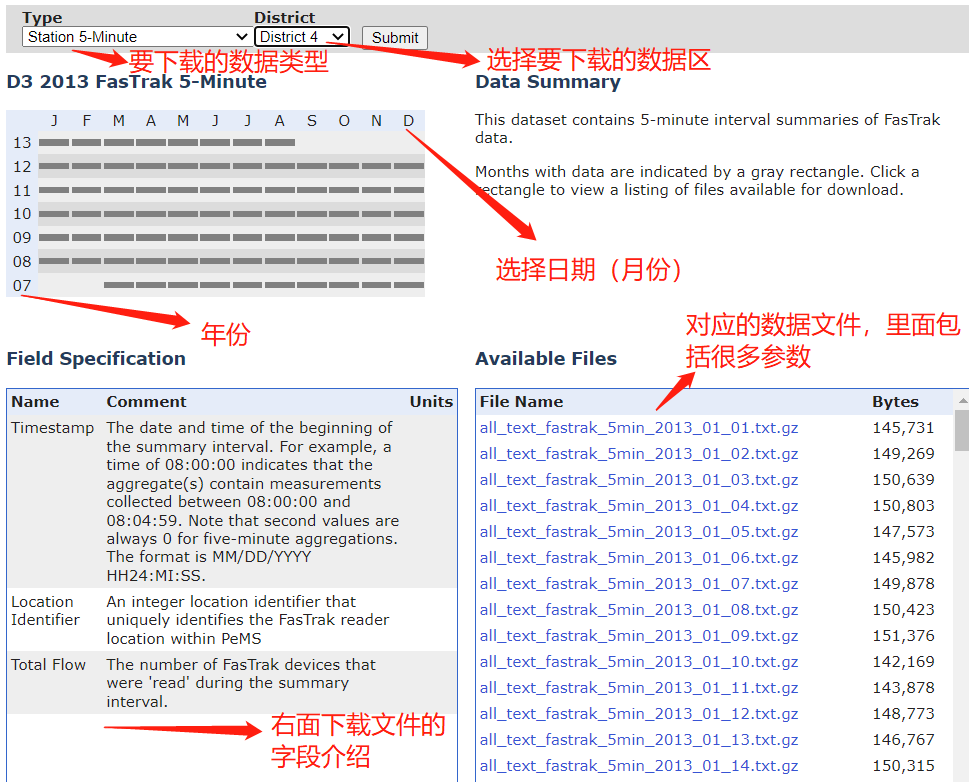
这下载的是对应区的全部车辆检测站点数据,如果需要收集某个站点检测器的特定时段的数据(以天为单位),例如要下载一个月的数据
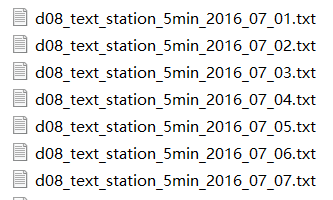
下载的数据txt文件:(截图仅列出了7.1-7.7一周的数据(只是为了展现文件命名),下面代码是以7.1-7.31一个月的数据为研究对象)
附上python代码(主要功能:从下载的指定区域的一个月的数据文件中筛选出指定的车辆检测站一个月的数据)
主要修改的地方:目标检测器ID,文件存储路径path_dir1 ,path_dir2,要下载的数据字段
import pandas as pd
import numpy as np
def getData(path, detector_id):
list_data = []
data = pd.read_table(path, sep = ',', header = None).values
for i in range(data.shape[0]):
if data[i, 1] == detector_id:
list_data.append(data[i, :])
list_data = np.array(list_data)
# 时间戳
time_step = np.expand_dims(list_data[:, 0], axis=1)
# 检测器站点
detector = np.expand_dims(list_data[:, 1], axis=1)
# 车流量
flow = np.expand_dims(list_data[:, 9], axis=1)
day_data = np.concatenate([time_step, detector, flow], axis=1)
return day_data
if __name__ == '__main__':
# 这里需要改成你自己下载的数据文件所在目录(以下载31天的数据为例)
# path_dir1 是1-9天的文件前缀
# path_dir2 是10-31天的文件前缀
path_dir1 = "./d08_text_station_5min_2016_07_0"
path_dir2 = "./d08_text_station_5min_2016_07_"
# 填入需要下载的车辆检测站的ID,多个的话依次在列表中列出即可
# 注意:detector_id 类型是数值不是字符串
for detector_id in [801404, 801400, 801397]:
print(str(detector_id)+"号站点检测器的数据开始收集...")
month_data = []
for i in range(1, 10):
path = path_dir1 + str(i)+".txt"
day_data = getData(path, detector_id)
month_data.append(day_data)
print(str(detector_id)+"号站点检测器的第"+str(i)+"天数据已收集完成...")
for i in range(10, 32):
path = path_dir2 + str(i) + ".txt"
day_data = getData(path, detector_id)
month_data.append(day_data)
print(str(detector_id) + "号站点检测器的第" + str(i) + "天数据已收集完成...")
month_data_resize = np.reshape(month_data, newshape=(-1, 3))
# 将对应站点的数据存储到CSV文件
pd.DataFrame(month_data_resize).to_csv("./"+str(detector_id)+".csv")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号