

requests进阶
requests进阶
三、requests模块处理cookie相关的请求
1 爬虫中使用cookie
为了能够通过爬虫获取到登录后的页面,或者是解决通过cookie的反扒,需要使用request来处理cookie相关的请求
1.1 爬虫中使用cookie的利弊
- 带上cookie的好处
- 能够访问登录后的页面
- 能够实现部分反反爬
- 带上cookie的坏处
- 一套cookie往往对应的是一个用户的信息,请求太频繁有更大的可能性被对方识别为爬虫
- 那么上面的问题如何解决 ?使用多个账号
1.2 requests处理cookie的方法
使用requests处理cookie有三种方法:
- cookie字符串放在headers中
- 把cookie字典放传给请求方法的cookies参数接收
- 使用requests提供的session模块
2、cookie添加在heades中
2.1 headers中cookie的位置
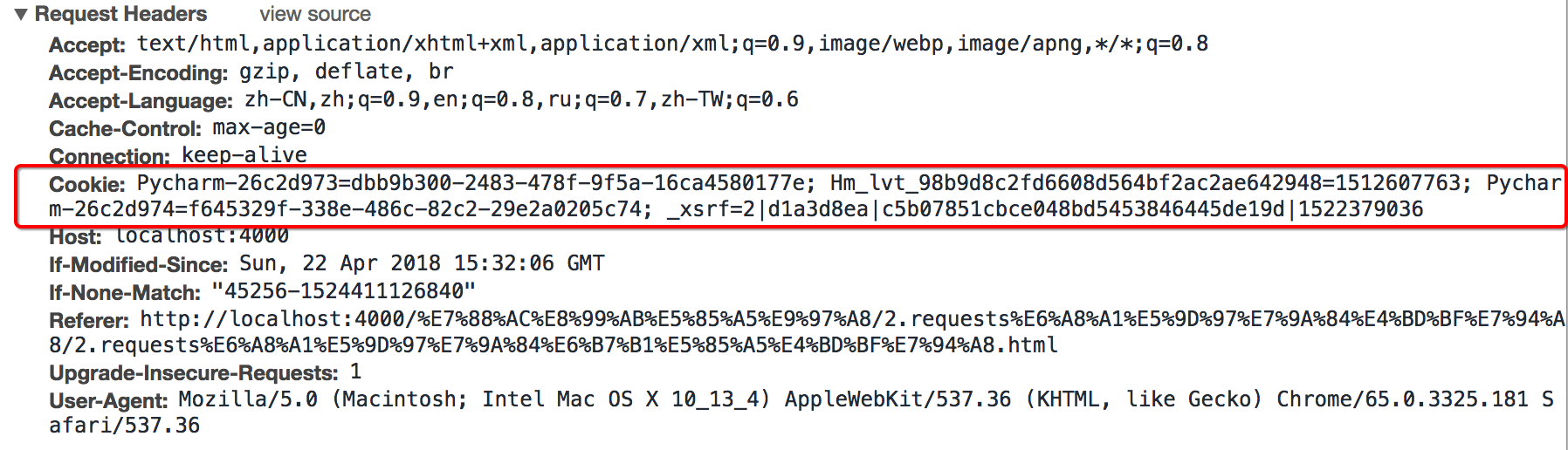
- headers中的cookie:
- 使用分号(;)隔开
- 分号两边的类似a=b形式的表示一条cookie
- a=b中,a表示键(name),b表示值(value)
- 在headers中仅仅使用了cookie的name和value
2.2 cookie的具体组成的字段

由于headers中对cookie仅仅使用它的name和value,所以在代码中我们仅仅需要cookie的name和value即可
2.3 在headers中使用cookie
复制浏览器中的cookie到代码中使用
headers = {
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Cookie":" Pycharm-26c2d973=dbb9b300-2483-478f-9f5a-16ca4580177e; Hm_lvt_98b9d8c2fd6608d564bf2ac2ae642948=1512607763; Pycharm-26c2d974=f645329f-338e-486c-82c2-29e2a0205c74; _xsrf=2|d1a3d8ea|c5b07851cbce048bd5453846445de19d|1522379036"}
requests.get(url,headers=headers)
注意:
cookie有过期时间 ,所以直接复制浏览器中的cookie可能意味着下一程序继续运行的时候需要替换代码中的cookie,对应的我们也可以通过一个程序专门来获取cookie供其他程序使用;当然也有很多网站的cookie过期时间很长,这种情况下,直接复制cookie来使用更加简单
3、使用cookies参数接收字典形式的cookie
- cookies的形式:字典
cookies = {"cookie的name":"cookie的value"}
- 使用方法:
requests.get(url,headers=headers,cookies=cookie_dict)
-
实例(爬取雪球网)
在网络中找到当前请求的网址 点击cookies 将当前的k,value复制到代码中
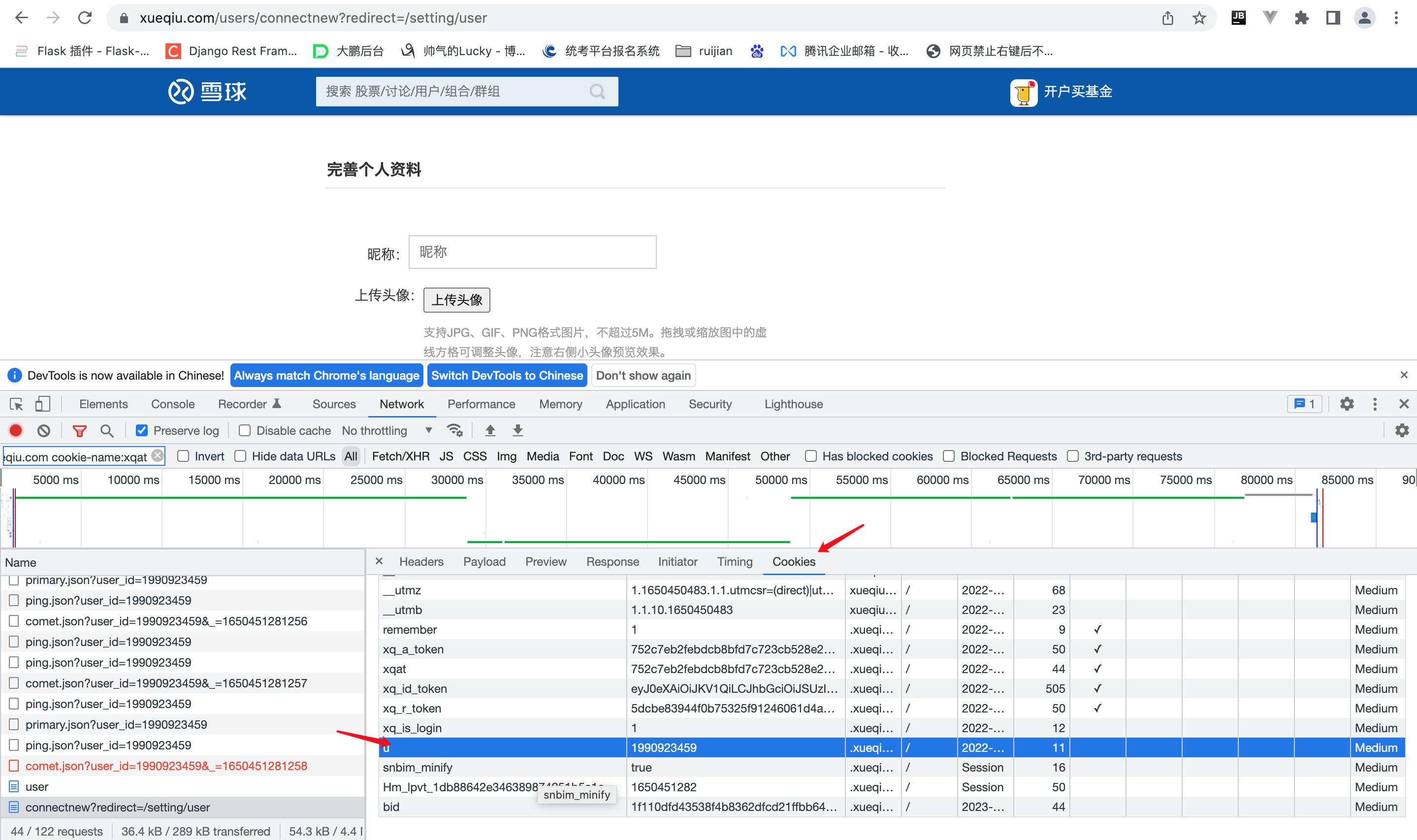
cookie_dict = { 'u': '1990923459', 'bid': '1f110dfd43538f4b8362dfcd21ffbb64_l27g4lfl', 'xq_is_login': '1', 'xq_r_token': '5dcbe83944f0b75325f91246061d4a2a01999367' }完整代码
import requests # 携带cookie登录雪球网 抓取完善个人资料页面 headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36', 'Referer': 'https://xueqiu.com/u/1990923459', 'Host': 'xueqiu.com', } url = 'https://xueqiu.com/users/connectnew?redirect=/setting/user' cookie_dict = { 'u': '1990923459', 'bid': '1f110dfd43538f4b8362dfcd21ffbb64_l27g4lfl', 'xq_is_login': '1', 'xq_r_token': '5dcbe83944f0b75325f91246061d4a2a01999367' } res = requests.get(url, headers=headers, cookies=cookie_dict) with open('雪球网.html', 'w') as f: f.write(res.content.decode('UTF-8')) print(res.content.decode('UTF-8'))成果
4、使用requests.session处理cookie
前面使用手动的方式使用cookie,那么有没有更好的方法在requets中处理cookie呢?
requests 提供了一个叫做session类,来实现客户端和服务端的会话保持
会话保持有两个内涵:
- 保存cookie,下一次请求会带上前一次的cookie
- 实现和服务端的长连接,加快请求速度
4.1 使用方法
session = requests.session()
response = session.get(url,headers)
session实例在请求了一个网站后,对方服务器设置在本地的cookie会保存在session中,下一次再使用session请求对方服务器的时候,会带上前一次的cookie
4.2 动手练习:模拟登陆
-
17k小说网 https://passport.17k.com/
-
打码平台
思路分析
- 准备url地址和请求参数
- 构造session发送post请求
- 使用session请求个人主页,观察是否请求成功
5、小结
- cookie字符串可以放在headers字典中,键为Cookie,值为cookie字符串
- 可以把cookie字符串转化为字典,使用请求方法的cookies参数接收
- 使用requests提供的session模块,能够自动实现cookie的处理,包括请求的时候携带cookie,获取响应的时候保存cookie
四、requests模块的其他方法
1、requests中cookirJar的处理方法
使用request获取的resposne对象,具有cookies属性,能够获取对方服务器设置在本地的cookie,但是如何使用这些cookie呢?
1.1 方法介绍
- response.cookies是CookieJar类型
- 使用requests.utils.dict_from_cookiejar,能够实现把cookiejar对象转化为字典
1.2 方法展示
import requests
url = "http://www.baidu.com"
#发送请求,获取resposne
response = requests.get(url)
print(type(response.cookies))
#使用方法从cookiejar中提取数据 等同于 dict(response.cookies)
cookies = requests.utils.dict_from_cookiejar(response.cookies)
print(cookies)
输出为:
<class 'requests.cookies.RequestsCookieJar'>
{'BDORZ': '27315'}
注意:
在前面的requests的session类中,我们不需要处理cookie的任何细节,如果有需要,我们可以使用上述方法来解决
2、requests处理证书错误
经常我们在网上冲浪时,经常能够看到下面的提示:
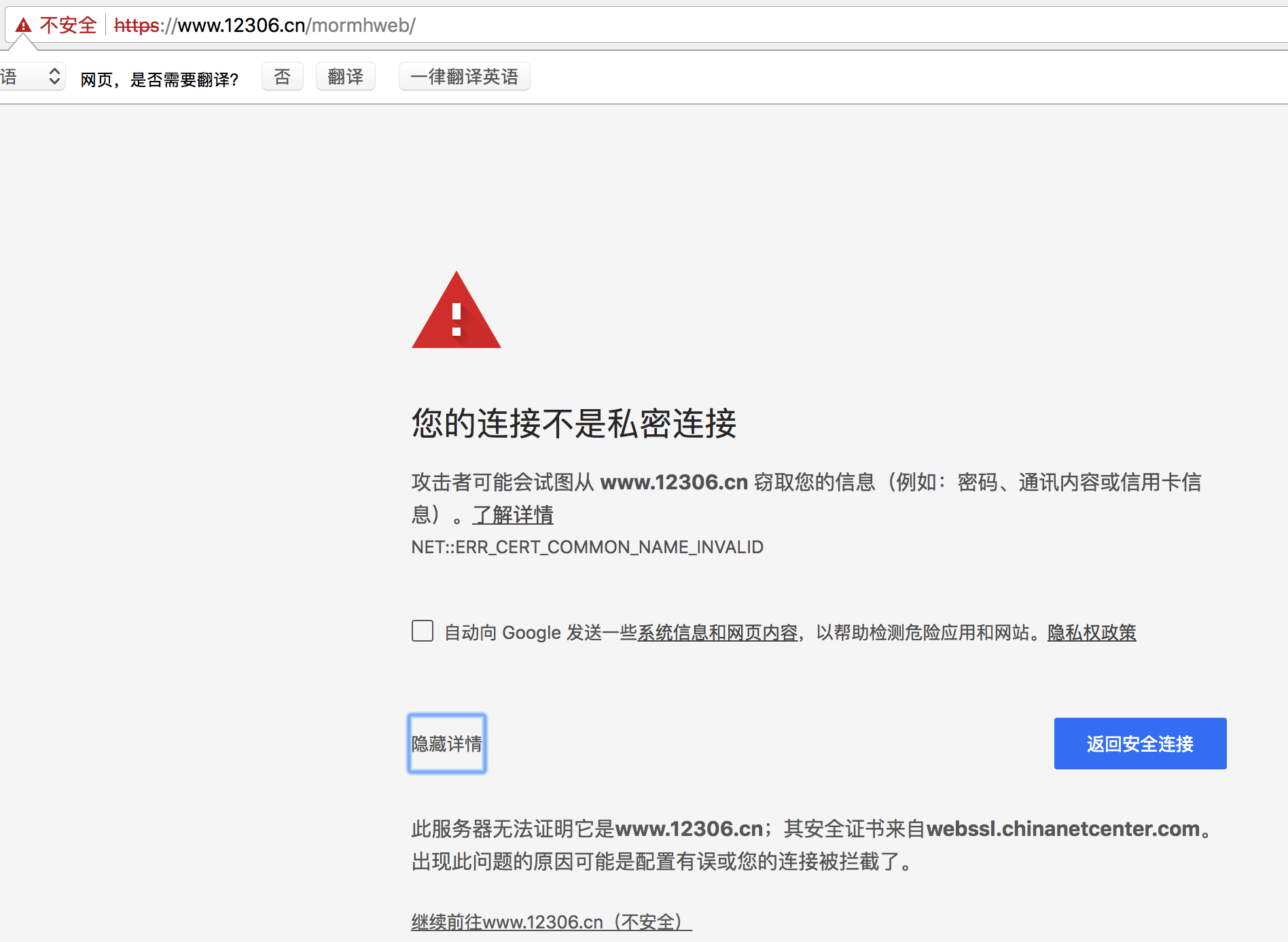
出现这个问题的原因是:ssl的证书不安全导致
2.1 代码中发起请求的效果
那么如果在代码中请求会怎么样呢?
import requests
url = "https://www.12306.cn/mormhweb/"
response = requests.get(url)
返回证书错误,如下:
ssl.CertificateError ...
2.2 解决方案
为了在代码中能够正常的请求,我们修改添加一个参数
import requests
url = "https://www.12306.cn/mormhweb/"
response = requests.get(url, verify=False)
3、超时参数的使用
在平时网上冲浪的过程中,我们经常会遇到网络波动,这个时候,一个请求等了很久可能任然没有结果
在爬虫中,一个请求很久没有结果,就会让整个项目的效率变得非常低,这个时候我们就需要对请求进行强制要求,让他必须在特定的时间内返回结果,否则就报错
3.1 超时参数使用方法如下:
response = requests.get(url,timeout=3)
通过添加timeout参数,能够保证在3秒钟内返回响应,否则会报错
注意:
这个方法还能够拿来检测代理ip的质量,如果一个代理ip在很长时间没有响应,那么添加超时之后也会报错,对应的这个ip就可以从代理ip池中删除
本文来自博客园,作者:生而自由爱而无畏,转载请注明原文链接:https://www.cnblogs.com/zczhaod/p/17755639.html
