1. 常见的反爬虫和应对方法?
| 1. 基于身份识别进行反爬 |
| (1) 用户请求的headers |
| - headers知识补充: |
| - host:提供了主机名及端口号 |
| - Referer 提供给服务器客户端从那个页面链接过来的信息(有些网站会据此来反爬) |
| - Origin:Origin字段里只包含是谁发起的请求,并没有其他信息.(仅存于post请求) |
| - User agent: 发送请求的应用程序名(一些网站会根据UA访问的频率间隔时间进行反爬) |
| - proxies:代理,一些网站会根据ip访问的频率次数等选择封ip. |
| - cookie:特定的标记信息,一般可以直接复制,对于一些变化的可以选择构造. |
| (2) 通过请求参数来反爬 |
| 常见的有: |
| - 通过headers中的User-Agent字段来反爬、通过referer字段或者是其他字段来反爬。如果Python写的爬虫不加入User-Agent,在后台服务器是可以看到服务器的类型pySpider。 |
| - 通过cookie限制抓取信息,比如我们模拟登陆之后,想拿到登陆之后某页面信息,千万不要以为模拟登陆之后就所有页面都可以抓了,有时候还需要请求一些中间页面拿到特定cookie,然后才可以抓到我们需要的页面。 |
| - 最为经典的反爬虫策略当属“验证码”了。最普通的是文字验证码,因为是图片用户登录时只需输入一次便可录成功,而我们程序抓取数据过程中,需要不断的登录,手动输入验证码是不现实的,所以验证码的出现难倒了一大批人。当然还有滑块的,点触的的(比如12306的点触验等)。 |
| - 另一种比较常见的反爬虫模式当属采用JS渲染页面了。就是返回的页面并不是直接请求得到,而是有一部分由JS操作DOM得到,所以那部分数据我们也拿不到咯。 |
| |
| 2. 基于爬虫行为进行反爬 |
| (1) 基于请求频率或总请求数量的反扒,这是一种比较恶心又比较常见的反爬虫策略当属封ip和封账号,当你抓取频率过快时,ip或者账号被检测出异常会被封禁。被封的结果就是浏览器都无法登陆了,但是换成ip代理就没有问题。 |
| 问题:爬虫如何避免被封IP呢? |
| - 降低访问频率:反爬虫一般是在规定时间内IP访问次数进行的限制,可以限制每天抓取的页面数量和时间间隔。既能满足采集速度,也能不被限制IP。 |
| - 多线程采集:反爬虫一般是在规定时间内IP访问次数进行的限制,可以限制每天抓取的页面数量和时间间隔。既能满足采集速度,也能不被限制IP。 |
| - 使用代理IP:反爬虫一般是在规定时间内IP访问次数进行的限制,可以限制每天抓取的页面数量和时间间隔。既能满足采集速度,也能不被限制IP。 |
| - 对IP进行伪装:虽然大多网站都有反爬虫,但有一些网站对这方便比较忽略,这样就可以对IP进行伪装,修改X-Forwarded-for就可以避过。但如果想频发抓取,还是需要多IP。 |
| (2) 通过js实现跳转来反爬,js实现页面跳转,无法在源码中获取下一页url,需要多次抓包获取条状url,分析规律。 |
| (3) 通过蜜罐(陷阱)获取爬虫ip(或者代理ip),进行反爬。蜜罐的原理:在爬虫获取链接进行请求的过程中,爬虫会根据正则,xpath,css等方式进行后续链接的提取,此时服务器端可以设置一个陷阱url,会被提取规则获取,但是正常用户无法获取,这样就能有效的区分爬虫和正常用户。 |
| (4) 通过假数据反爬,向返回的响应中添加假数据污染数据库,通常假数据不会被正常用户看到。 |
| |
| 3. 基于数据加密进行反爬 |
| (1) 对响应中含有的数据进行特殊化处理(通常的特殊化处理主要指的就是css数据偏移/自定义字体/数据加密/数据图片/特殊编码格式等)。 |
| (2) 有一些网站的内容由前端的JS动态生成,由于呈现在网页上的内容是由JS生成而来,我们能够在浏览器上看得到,但是在HTML源码中却发现不了。这就需要解析关键js,获得数据生成流程,模拟生成数据。一般获取的数据是通过AJAX获取的,返回的结果是Json,然后解析Json获取数据。 |
| (3) 通过编码格式进行反爬,不适用默认编码格式,在获取响应之后通常爬虫使用utf-8格式进行解码,此时解码结果将会是乱码或者报错。解决思路:根据源码进行多格式解码,或者真正的解码格式。 |
| |
2. JavaScript 基本类型:
| number, string, boolean, symbol, undefind, null, Object |
3. 网络七层协议:
| 应用层: HTTP FTP DNS TFTP |
| 表示层: 数据加密 |
| 会话层: SQL RPC |
| 传输层: TCP UDP |
| 网络层: IP IPX |
| 数据链路层: ATM |
| 物理层: 电路 |
4. 如何实现全站数据爬取?
| 基于手动请求发送+递归解析 |
| 基于CrwalSpider(LinkExtractor,Rule) |
5. 爬取速度过快出现了验证码怎么处理?
| - 控制抓取速度,定时或随机sleep |
| - 定时或定量切换ip地址 |
| - 绕过验证码;在爬虫的时候遇到各种需要登录网址,也有验证码。就会手工的把cookie信息复制下来,加到请求头上就可以了。 |
| - 将许多验证码解算器集成到他的爬虫系统中(验证码识别服务供应商 Death by CAPTCHA 和 Bypass CAPTCHA 都允许用户通过调用API服务来进行自动打码,从而在抓取数据过程中自动解决验证码。) |
| - 将验证码返回打码,可采用人工或者打码平台。 |
6. 写爬虫是用多进程好?还是多线程好?为什么?
| IO密集型代码(文件处理、网络爬虫等),多线程能够有效提升效率; |
| 单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率。 |
| 在实际的数据采集过程中,既考虑网速和响应的问题,也需要考虑自身机器的硬件情况,来设置多进程或多线程,更多情况下爬虫适合多线程,爬虫是对网络操作属于 io 密集型操作适合使用多线程或者协程。 |
7. 什么是深度优先和广度优先?
| 默认情况下scrapy是深度优先; |
| - 深度优先:占用空间大,但是运行速度快 |
| - 广度优先:占用空间少,运行速度慢 |
8. 简述 requests模块的作用及基本使用?
| 作用:使用requests可以模拟浏览器发送的请求。 |
| 基本使用: |
| - 发送get请求:requests.get() |
| - 发送post请求:requests.post() |
| - 读取请求返回内容:requests.text() |
| - 保存cookie:requests.cookie() |
9. 协程的适用场景?
| 当程序中存在大量不需要CPU的操作时(即IO使用较多情况下)。 |
10. 解析网页的解析器使用最多的是哪几个?
| re正则匹配 |
| python自带的html.parser模块 |
| 第三方库BeautifulSoup(重点学习) |
| 以及lxml库 |
11. hashlib 密码加密
| def get_hex(value): |
| md5_ = hashlib.md5() |
| md5_.update(value.encode('utf-8')) |
| return md5_.hexdigest() |
12. 解释在多任务异步协程中事件循环(loop)的作用是什么?
| 可以将注册在其内部的任务对象表示的特定操作进行异步执行; |
13. 代理失效了怎么处理?
| 设置一个代理池(一个列表放了多个代理服务器的ip),实现代理切换等操作,来实现实时使用新的代理 ip,来避免代理失效的问题。 |
14. 关于 response.text 乱码问题
| response的常用属性: |
| - 获取字符串类型的响应正文:response.text |
| - 获取bytes类型的响应正文:response.content |
| - 响应正文字符串编码:response.encoding |
| - 状态码:response.status_code |
| - 响应头:response.headers |
| Accept: text/html,image/* |
| Accept-Charset: ISO-8859-1 |
| Accept-Encoding: gzip,compress |
| Accept-Language: en-us,zh- |
| Host: www.it315.org:80 |
| Referer: http://www.it315.org/index.jsp |
| User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0) |
| Cookie:name=eric |
| Connection: close/Keep-Alive |
16. HTTP协议和HTTPS协议的区别?
| HTTP协议是使用明文数据传输的网络协议,明文传输会让用户存在一个非常大的安全隐患。端口80 |
| HTTPS协议可以理解为HTTP协议的安全升级版,就是在HTTP的基础上增加了数据加密。端口443 |
| HTTPS协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议要比HTTP协议安全。 |
17. 关于响应常见的响应码?
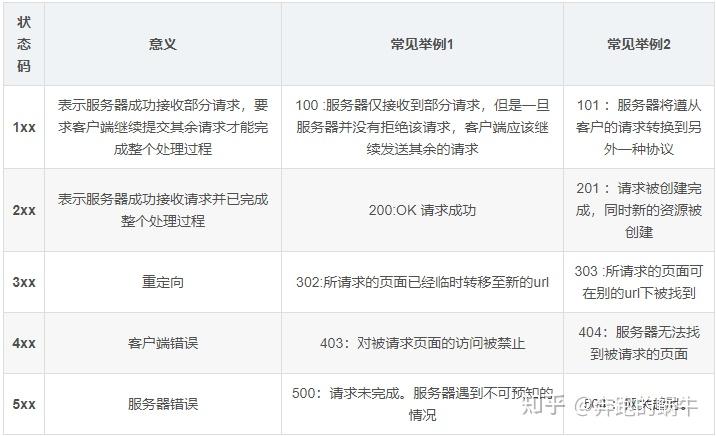
18. 实现模拟登录的方式有哪些?
| - 直接使用已知的Cookie访问 |
| 先用浏览器登录,获取浏览器里的cookie字符串,然后封装至请求头。 |
| - 模拟登录后用session保持登录状 |
| 使用session模拟登陆后,就会自动存储一个cookie次从而保持住登录状态。 |
| - 使用Selenium+PhantomJS访问 |
| Selenium库提供了find_element(s)_by_xxx的方法来找到网页中的输入框、按钮等元素。 |
| 其中xxx可以是id、name、tag_name(标签名)、class_name(class),也可以是xpath(xpath表达式)等等。当然还是要具体分析网页源代码。 |
19. 用的什么框架,为什么选择这个框架?
| scrapy |
| 基于twisted异步io框架,是纯python实现的爬虫框架,性能是最大的优势 |
| 可以加入request和beautifulsoup |
| 方便扩展,提供了很多内置功能 |
| 内置的cssselector和xpath非常方便 |
| 默认深度优先 |
| pyspider:爬虫框架,基于PyQuery实现的 |
| - 优势: |
| 可以实现高并发的爬取数据, 注意使用代理 |
| 提供了一个爬虫任务管理界面, 可以实现爬虫的停止,启动,调试,支持定时爬取任务; |
| 代码简洁 |
| - 劣势: |
| 可扩展性不强; |
| 整体上来说一些结构性很强的,定制性不高,不需要太多自定义功能时用pyspider即可,一些定制性高的,需要自定义一些功能时则使用 Scrapy。 |
| |
20. scrapy的去重原理 (指纹去重到底是什么原理?)
| 需要将dont_filter设置为False开启去重,默认是False; |
| 对于每一个url的请求,调度器都会根据请求的相关信息加密得到一个指纹信息,并且将指纹信息和set()集合中得指纹信息进行比对,如果set()集合中已经存在这个数据,就不在将这个Request放入队列中。如果set()集合中没有,就将这个Request对象放入队列中,等待被调度。 |
21. scrapy中间件有几种类?你用过哪些中间件?
| scrapy的中间件理论上有三种(SchdulerMiddleware,SpiderMiddleware,DownloaderMiddleware) |
| 在应用上一般有以下两种: |
| - 爬虫中间件SpiderMiddleware: 主要功能是在爬虫运行过程中进行一些处理; |
| - 下载器中间件DownloaderMiddleware: 主要功能在请求到网页后,页面被下载时进行一些处理; |
22. scrapy如何实现持久化存储?
| 解析数据—将解析的数据封装到item中—将item提交管道—在管道中持久化存储—开启管道 |
23. scrapy 和 scrapy-redis 有什么区别?为什么选择 redis 数据库?
| 主要区别: |
| - scrapy是一个Python爬虫框架,爬取效率极高,具有高度定制性,但是不支持分布式。 |
| - scrapy-redis一套基于redis数据库、运行在scrapy框架之上的组件,可以让scrapy支持分布式策略,Slaver端共享Master端redis数据库里的item队列、请求队列和请求指纹集合。 |
| |
| 选择 redis 数据库: |
| - 因为redis支持主从同步,而且数据都是缓存在内存中的,所以基于redis的分布式爬虫,对请求和数据的高频读取效率非常高。 |
24. scrapy-redis组件中如何实现的任务的去重?
| a. 内部会使用以下配置进行连接Redis |
| |
| |
| |
| |
| |
| |
| b. 去重规则通过redis的集合完成,集合的Key为: |
| key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())} |
| 默认配置: |
| DUPEFILTER_KEY = 'dupefilter:%(timestamp)s' |
| c. 去重规则中将url转换成唯一标示,然后在redis中检查是否已经在集合中存在 |
| from scrapy.utils import request |
| from scrapy.http import Request |
| req = Request(url='http://www.cnblogs.com/wupeiqi.html') |
| result = request.request_fingerprint(req) |
| print(result) |
| PS: |
| - URL参数位置不同时,计算结果一致; |
| - 默认请求头不在计算范围,include_headers可以设置指定请求头 |
| 示例: |
| from scrapy.utils import request |
| from scrapy.http import Request |
| req = Request(url='http://www.baidu.com?name=8&id=1',callback=lambda x:print(x),cookies={'k1':'vvvvv'}) |
| result = request.request_fingerprint(req,include_headers=['cookies',]) |
| print(result) |
| req = Request(url='http://www.baidu.com?id=1&name=8',callback=lambda x:print(x),cookies={'k1':666}) |
| result = request.request_fingerprint(req,include_headers=['cookies',]) |
| print(result) |
25. 通用爬虫的工作流程
| 抓取网页:通过搜索引擎将待爬取的URL加入到通用爬虫的URL队列中,进行网页内容的爬取。 |
| 数据存储:将爬取下来的网页保存到本地,这个过程会有一定的去重操作,如果某个网页的内 容大部分内容都会重复,搜索引擎可能不会保存。 |
| 预处理:提取文字,中文分词,消除噪音(比如版权声明文字,导航条,广告等)。 |
| 设置网站排名,为用户提供服务。 |
26. 有GLF锁为什么还要有互斥锁?
| - 为什么设计GLF锁? |
| Python 在设计之初就考虑到要在解释器的主循环中,同时只有一个线程在执行,即在任意时刻,只有一个线程在解释器中运行。对Python 虚拟机的访问由全局解释器锁(GIL)来控制,正是GIL锁能保证同一时刻只有一个线程在运行。 |
| - 宏观微观考虑GLF锁? |
| GIL是宏观的操作。比如在一个4核的环境下,只有一个核是运行着线程,而其他三个核是空的。GIL是线程锁,针对线程,而不是进程 |
27. 死锁问题
| - 同一个线程先后两次调用lock,在第二次调用时,由于锁已经被自己占用,该线程会挂起等待自己释放锁,由于该线程已被挂起而没有机会释放锁,因此 它将一直处于挂起等待状态,变为死锁; |
| - 线程A获得了锁1,线程B获得了锁2,这时线程A调用lock试图获得锁2,结果是需要挂起等待线程B释放锁2,而这时线程B也调用lock试图获得锁1,结果是需要挂起等待线程A释放锁1,于是线程A和B都在等待对方释放自己才释放,从而造成两个都永远处于挂起状态,造成死锁。 |
28. MongoDB和传统的关系型数据库区别?
| - 传统数据库特点是存储结构化数据,数据以行为单位,每行的数据结构和类型相同 |
| - MongoDB存储的是文档,每个文档得结构可以不相同,能够更便捷的获取数据。 |
| - MongoDB的集合不需要提前创建,可隐式创建,而关系型数据库的表需要提前定义 |
| - mongo第三方支持丰富。(这是与其他的NoSQL相比,MongoDB也具有的优势) |
| - mongodb不支持事务操作 |
| - mongodb支持大容量的存储,占用空间过大 |
29. 移动端数据如何抓取?
30. 什么是栈溢出?怎么解决?
| 因为栈一般默认为1-2m,一旦出现死循环或者是大量的递归调用,在不断的压栈过程中,造成栈容量超过1m而导致溢出。 |
| 栈溢出的情况有两种: |
| - 局部数组过大。当函数内部数组过大时,有可能导致堆栈溢出 |
| - 递归调用层次太多。递归函数在运行时会执行压栈操作,当压栈次数太多时,也会导致堆栈溢出。 |
| 解决方法: |
| - 用栈把递归转换成非递归。 |
| - 增大栈空间。 |
31. JSON数据
JSON 的本质:是一个字符串,JSON是对JS对象的字符串表达式,它使用文本形式表示一个JS对象的信息。
JSON 使用:
| ① json.dumps(Python的list或者dict),将Python的list或者dict返回为一个JSON字符串; |
| ② json.loads(json字符串),将JSON字符串返回为Python的list或者dict; |
| ③ json.dump(list/dict,fp),将Python的list或者dict转为一个JSON字符串,保存到文件中; |
| ④ json.load(fp) ,从JSON文件中读出JSON数据,并转换为Python的list或者dict。 |
32. 常见反爬及其应对措施总结
| (1)通过user-agent来判断是否是爬虫 |
| 通过伪装请求头中的user-agent来解决。若user-agent被检测到,可以找一些常见的的user-agent放入列表,然后每次爬取随机选一个。 |
| (2)通过访问频率来判断是否是一个爬虫 |
| 可以通过设置请求时间间隔; |
| (3)爬取频繁将ip进行封禁 |
| 可以使用代理IP来解决; |
| (4)当一定时间内的总请求数超过上限,弹出验证码 |
| - 简单的图形验证码: |
| 可以使用tesseract来处理,也可以使用最新的一个muggle_ocr来处理,识别率还凑合,对于复杂的可以去打码平台。 |
| - 滑块验证码: |
| 通过selenium+浏览器获取滑块的滑动间距,然后捕捉滑块按钮,按照人体的规律(一般是先快后慢)拖动滑块 |
| - 其他验证码:打码平台解决 |
| (5)cookie限制 |
| - 对于cookie有效时间长的,可以通过手动登录,然后把cookie添加至headers里。 |
| - 对于cookie有效时间短的,爬虫每次启动时可以通过selenium登录后获取cookie,然后放到headers里。 |
| 其他须知: |
| - 有的cookie登录前后字符串不变,可能是对方网站后台加的判断 |
| - 有的cookie和设备是进行绑定的,可通过多个设备机器进行解决 |
| - 有的cookie和IP进行绑定,可通过代理ip解决 |
| (6)js加密 |
| - 可以使用selenium+phantomjs来加载js获取数据 |
| - 通过浏览器的debug来逐步搞清参数生成逻辑(常见的有无限debugger,js混淆等等) |
33. 客户端请求(Get和Post区别)
| (1)组成:请求行、请求头部、空行、请求数据四个部分组成 |
| (2)请求方法Get/Post |
| (3)Get和Post的区别 |
| GET和POST本质上就是TCP链接,并无差别。但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。 |
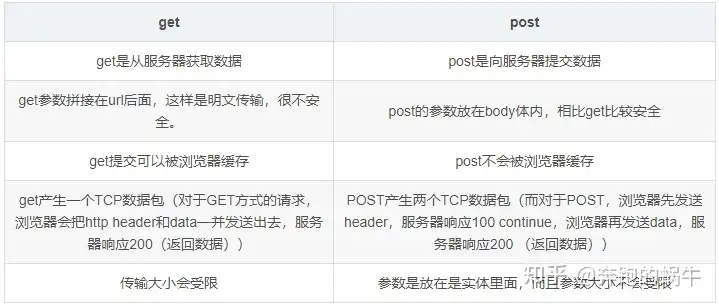
34. 快照和日志两者如何选择?
| 推荐两种共同使用: |
| 1)如果Redis仅仅是用来做为缓存服务器的话,我们可以不使用任何的持久化。 |
| 2)一般情况下我们会将两种持久化的方式都开启。redis优先加载AOF文件来回复数据。RDB的好处是快速。 |
| 3)在主从节点中,RDB作为我们的备份数据,只在salve(从节点)上启动,同步时间可以设置的长一点,只留(save 900 1)这条规则就可以了。 |
| 4)开启AOF的情况下,主从同步是时候必然会带来IO的性能影响,此时我们可以调大auto-aof-rewrite-min-size的值,比如5GB。来减少IO的频率 |
| 5)不开启AOF的情况下,可以节省IO的性能影响,这是主从间通过RDB持久化同步,但如果主从都挂掉,影响较大。 |
35. 在dump rdb过程中,aof如果停止同步,会不会丢失?
| 不会,所有的操作缓存在内存的队列里,dump完成后,统一操作。 |
36. aof重写是指什么?
| 由于日志保存的是所有操作命令,导致存的日志会过大,而且数据库中有可能数据进行过删除,因此日志中的一些命令就相当于无效,因此日志先会删除,然后内存中的数据会逆化成命令,再重新写入到日志文件中,以解决 aof日志过大的问。 |
37. 如果rdb文件和aof文件都存在,优先用谁来恢复数据?
| 在这种情况下,当Redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件完整。 |
38. 恢复时rdb和aof哪个恢复的快?
| rdb快,因为其是数据的内存映射,直接载入到内存,而aof是命令,需要逐条执行。 |
39. 当在浏览器输入一个url,为什么可以加载出一个页面?为什么抓包的过程中请求一个url,出现很多的资源请求?
| - 当我们在浏览器输入一个url,客户端会发送这个url对应的一个请求到服务器获取内容 |
| - 服务器收到这个请求,解析出对应内容,之后将内容封装到响应里发送到客户端 |
| - 当客户端拿到这个html页面,会查看这个页面中是否有css、js、image等url,如果有,在分别进行请求,获取到这些资源。 |
| - 客户端会通过html的语法,将获取到的所有内容完美的显示出来。 |
40. 分布式爬虫主要解决什么问题?
| - 给爬虫加速; |
| - 解决了单个 ip 的限制, |
| - 宽带的影响 |
| - 以及 CPU 的使用情况 |
| - IO等一系列操作 |
41. MySQL的索引在什么情况下失效?
| - 如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因),要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引。 |
| - 对于多列索引,不是使用的第一部分,则不会使用索引。 |
| - like查询以%开头。 |
| - 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引。 |
| - 如果MySQL估计使用全表扫描要比使用索引快,则不使用索引。 |
42. 数据结构的分类

43. 数据库优化的方式?
| - 设计表的时候严格根据数据库的设计范式来设计数据库; |
| - select 后尽量不使用*; |
| - 尽量不使用嵌套查询,使用连接查询或者where查询; |
| - sql关键词尽量使用大写; |
| - 尽量使用逻辑外交不使用物理外键; |
| - 给查询频繁的字段添加索引,并且遵循最左原则(尽量将首选关键字段放在最前边); |
| - 垂直分库分表:把一些不经常读的数据或者结果复杂的表拆分成多张表,较少磁盘I/O操作; |
| - 水平分库分表:于数据量庞大的表,使用水平分库分表; |
| - 使用缓存,把经常访问到的数据而且不需要经常变化的数据放在缓存中,能节约磁盘IO; |
| - 优化硬件; |
| - 主从分离读写;采用主从复制把数据库的读操作和写入操作分离开来。 |
44. 什么是敏捷开发?
| 敏捷开发以用户的需求进化为核心,采用迭代、循序渐进的方法进行软件开发。 |
| 在敏捷开发中,软件项目在构建初期被切分成多个子项目,各个子项目的成果都经过测试,具备可视、可集成和可运行使用的特征。换言之,就是把一个大项目分为多个相互联系,但也可独立运行的小项目,并分别完成,在此过程中软件一直处于可使用状态。 |
45. 定时任务
| 1.可以设计一个定时的类,使用时间模块(time,datetime),比如爬取时候获取当前时间,再当前时间多久后再爬取 |
| 2.使用linux的crontab的计划任务 |
| crontab -l 列出所有的定时任务 看不到配置文件中写的定时任务 |
| crontab -e 新增计划任务 跟上面的区别在于 没有用户名 |
| crontab -r 清空计划任务 |
| 分 时 日 月 周 命令 |
| |
| 举例使用: |
| * * * * * 命令 每分每时每天每月每周 执行这个命令 |
| 0-59 0-23 1-31 1-12 0-6 0是 周天 1-6 周一到周六 |
| 0 2 * * * mysqldump 每天的2点备份数据库 |
| 0 2 * * 2 sync 每个周二的2点做数据同步 |
| 0 8 15 * * /home/jsgz.py 每个月15号的八点给大家算工资 |
| 0 */2 * * * /home/camera.py 每隔2个小时执行一次查看摄像头 |
| 0 8,12,18 * * 1-5 kq.py 每周1-5 的 8点 12点 18点 执行打卡 |
| 0 8 * * * * spider.sh 每天 8点爬虫 |
46. 验证码的解决?
| 1.输入式验证码 |
| 解决思路:这种是最简单的一种,只要识别出里面的内容,然后填入到输入框中即可。这种识别技术叫OCR,这里我们推荐使用Python的第三方库,tesserocr。对于没有什么背影影响的验证码如图2,直接通过这个库来识别就可以。但是对于有嘈杂的背景的验证码这种,直接识别识别率会很低,遇到这种我们就得需要先处理一下图片,先对图片进行灰度化,然后再进行二值化,再去识别,这样识别率会大大提高。 |
| 验证码识别大概步骤: |
| 转化成灰度图 |
| 去背景噪声 |
| 图片分割 |
| 2.滑动式验证码 |
| 解决思路:对于这种验证码就比较复杂一点,但也是有相应的办法。我们直接想到的就是模拟人去拖动验证码的行为,点击按钮,然后看到了缺口 的位置,最后把拼图拖到缺口位置处完成验证。 |
| 第一步:点击按钮。然后我们发现,在你没有点击按钮的时候那个缺口和拼图是没有出现的,点击后才出现,这为我们找到缺口的位置提供了灵感。 |
| 第二步:拖到缺口位置。我们知道拼图应该拖到缺口处,但是这个距离如果用数值来表示?通过我们第一步观察到的现象,我们可以找到缺口的位置。这里我们可以比较两张图的像素,设置一个基准值,如果某个位置的差值超过了基准值,那我们就找到了这两张图片不一样的位置,当然我们是从那块拼图的右侧开始并且从左到右,找到第一个不一样的位置时就结束,这是的位置应该是缺口的left,所以我们使用selenium拖到这个位置即可。这里还有个疑问就是如何能自动的保存这两张图?这里我们可以先找到这个标签,然后获取它的location和size,然后 top,bottom,left,right = location[‘y’] ,location[‘y’]+size[‘height’]+ location[‘x’] + size[‘width’] ,然后截图,最后抠图填入这四个位置就行。具体的使用可以查看selenium文档,点击按钮前抠张图,点击后再抠张图。最后拖动的时候要需要模拟人的行为,先加速然后减速。因为这种验证码有行为特征检测,人是不可能做到一直匀速的,否则它就判定为是机器在拖动,这样就无法通过验证了。 |
| 3.点击式的图文验证 和 图标选择 |
| 图文验证:通过文字提醒用户点击图中相同字的位置进行验证。 |
| 图标选择: 给出一组图片,按要求点击其中一张或者多张。借用万物识别的难度阻挡机器。 |
| 这两种原理相似,只不过是一个是给出文字,点击图片中的文字,一个是给出图片,点出内容相同的图片。 |
| 这两种没有特别好的方法,只能借助第三方识别接口来识别出相同的内容,推荐一个超级鹰,把验证码发过去,会返回相应的点击坐标。 |
| 然后再使用selenium模拟点击即可。具体怎么获取图片和上面方法一样。 |
| |
47. “极验”滑动验证码如何破解?
| 破解核心思路: |
| 1、如何确定滑块滑动的距离? |
| 滑块滑动的距离,需要检测验证码图片的缺口位置 |
| 滑动距离 = 终点坐标 - 起点坐标 |
| 然后问题转化为我们需要屏幕截图,根据selenium中的position方法并进行一些坐标计算,获取我们需要的位置 |
| 2、坐标我们如何获取? |
| 起点坐标: |
| 每次运行程序,位置固定不变,滑块左边界离验证码图片左边界有6px的距离 |
| 终点坐标: |
| 每次运行程序,位置会变,我们需要计算每次缺口的位置 |
| 怎么计算终点也就是缺口的位置? |
| 先举个例子,比如我下面两个图片都是120x60的图片,一个是纯色的图片,一个是有一个蓝色线条的图片(蓝色线条位置我事先设定的是60px位置),我现在让你通过程序确定蓝色线条的位置,你怎么确定? |
| |
| 答案: |
| 遍历所有像素点色值,找出色值不一样的点的位置来确定蓝色线条的位置 |
| 这句话该怎么理解?大家点开我下面的图片,是不是发现图片都是由一个一个像素点组成的,120×60的图片,对应的像素就是横轴有120个像素点,纵轴有60个像素点,我们需要遍历两个图片的坐标并对比色值,从(0,0)(0,1)…一直到(120,60),开始对比两个图片的色值,遇到色值不一样的,我们return返回该位置即可 |
| |
48. 爬虫多久爬一次,爬下来的数据是怎么存储?
| 1. 以json格式存储到文本文件 |
| 这是最简单,最方便,最使用的存储方式,json格式保证你在打开文件时,可以直观的检查所存储的数据,一条数据存储一行,这种方式适用于爬取数据量比较小的情况,后续的读取分析也是很方便的。 |
| 2. 存储到excel |
| 如果爬取的数据很容易被整理成表格的形式,那么存储到excel是一个比较不错的选择,打开excel后,对数据的观察更加方便,excel也可以做一些简单的操作,写excel可以使用xlwt这个库,读取excel可以使用xlrd,同方法1一样,存储到excel里的数据不宜过多,此外,如果你是多线程爬取,不可能用多线程去写excel,这是一个限制。 |
| 3. 存储到sqlite |
| sqlite无需安装,是零配置数据库,这一点相比于mysql要轻便太多了,语法方面,只要你会mysql,操作sqlite就没有问题。当爬虫数据量很大时,需要持久化存储,而你又懒得安装mysql时,sqlite绝对是最佳选择,不多呢,它不支持多进程读写,因此不适合多进程爬虫。 |
| 4. 存储到mysql数据库 |
| mysql可以远程访问,而sqlite不可以,这意味着你可以将数据存储到远程服务器主机上,当数据量非常大时,自然要选择mysql而不是sqlite,但不论是mysql还是sqlite,存储数据前都要先建表,根据要抓取的数据结构和内容,定义字段,这是一个需要耐心和精力的事情。 |
| 5. 存储到mongodb |
| 我最喜欢no sql 数据库的一个原因就在于不需要像关系型数据库那样去定义表结构,因为定义表结构很麻烦啊,要确定字段的类型,varchar 类型数据还要定义长度,你定义的小了,数据太长就会截断。 |
| mongodb 以文档方式存储数据,你使用pymongo这个库,可以直接将数据以json格式写入mongodb, 即便是同一个collection,对数据的格式也是没有要求的,实在是太灵活了。 |
| 刚刚抓下来的数据,通常需要二次清洗才能使用,如果你用关系型数据库存储数据,第一次就需要定义好表结构,清洗以后,恐怕还需要定义个表结构,将清洗后的数据重新存储,这样过于繁琐,使用mongodb,免去了反复定义表结构的过程。 |
| |
49. HTTPS有什么优点和缺点?
| 1. 优点:相比于http,https可以提供更加优质保密的信息,保证了用户数据的安全性,此外https同时也一定程度上保护了服务端,使用恶意攻击和伪装数据的成本大大提高。 |
| 2. 缺点:缺点也同样很明显,第一https的技术门槛较高,多数个人或者私人网站难以支撑,CA机构颁发的证书都是需要年费的,此外对接Https协议也需要额外的技术支持;其二,目前来说大多数网站并不关心数据的安全性和保密性,其https最大的优点对它来说并不适用;其三,https加重了服务端的负担,相比于http其需要更多的资源来支撑,同时也降低了用户的访问速度;第四,目前来说Http网站仍然大规模使用,在浏览器侧也没有特别大的差别,很多用户不关心的话根本不感知。 |
| |
50. HTTPS是如何实现安全传输数据的?
| 1. 首先https的服务端必须要拥有一个CA认证合法授权的证书,没有这个证书,客户端在访问该服务器时就会提醒用户这个网站是不受信任的。只有通过CA认证的服务器才是可靠的,这保证了用户在访问服务器的安全性。浏览器会保持一个信任的CA机构列表,通过这些机构出查询所访问的服务器提供的证书是否合法。 |
| 2. 如果此时发现证书是合法OK的,那么就从这个服务器端的证书中获取到了加密秘钥,这个加密秘钥会沟通商议出一个随机的对称秘钥,服务端在传输信息使用该秘钥进行加密。而客户端在收到这部分信息后,在浏览器侧通过之前得到的对称秘钥进行解密,相反如果客户端想要向服务端发送消息时也是如此。 |
51. 谈一谈你对Selenium和PhantomJS了解
| selenium |
| Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等主流浏览器。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。 |
| 它的功能有: |
| 框架底层使用JavaScript模拟真实用户对浏览器进行操作。测试脚本执行时,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样,从终端用户的角度测试应用程序。 |
| 使浏览器兼容性测试自动化成为可能,尽管在不同的浏览器上依然有细微的差别。 |
| 使用简单,可使用Java,Python等多种语言编写用例脚本 |
| 也就是说,它可以根据指令,做出像真实的人在访问浏览器一样的动作,比如打开网页,截图等功能。 |
| |
| phantomjs |
| (新版本的selenium已经开始弃用phantomjs, 不过有时候我们可以单独用它做一些事情) |
| 是一个基于Webkit的无界面浏览器,可以把网站内容加载到内存中并执行页面上的各种脚本(比如js)。 |
| |
52. 描述下scrapy框架运行的机制?
| 从start_urls里获取第一批url并发送请求,请求由引擎交给调度器入请求队列,获取完毕后,调度器将请求队列里的请求交给下载器去获取请求对应的响应资源,并将响应交给自己编写的解析方法做提取处理:1. 如果提取出需要的数据,则交给管道文件处理;2. 如果提取出url,则继续执行之前的步骤(发送url请求,并由引擎将请求交给调度器入队列…),直到请求队列里没有请求,程序结束。 |
| |
53. 谈谈你对Scrapy的理解?
| Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取的数据内容。Scrapy使用了Twisted一部网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。 |
| |
| scrapy框架的工作流程: |
| |
| 首先Spider(爬虫)将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduer(调度器)。 |
| Scheduler(排序,入队)处理后,经ScrapyEngine(引擎),DownloaderMiddlewares(下载器中间件,可选,主要有User_Agent,Proxy代理)交给Downloader(下载器)。 |
| Downloader(下载器)向互联网发送请求,并接受下载响应(response)。将响应(response)经ScrapyEngine(引擎),SpiderMiddlewares(爬虫中间件,可选)交给Spiders(爬虫)。 |
| Spiders(爬虫)处理response(响应界面),提取数据并将数据经ScrapyEngineScrapyEngine(引擎)交给ItemPipeline保存(可以是本地,也可以是数据库)。提取url重新经ScrapyEngineScrapyEngine(引擎)交给Scheduler(调度器)进入下一个循环。直到无Url请求程序停止结束。 |
| 优点: |
| scrapy是异步的; |
| 采取可读性更强的xpath代替正则; |
| 强大的统计和log系统; |
| 支持shell方式,方便独立调试; |
| 写middleware,方便写一些统一的过滤器; |
| 通过管道的方式存入数据库。 |
| 缺点: |
| 基于python的爬虫框架,扩展性比较差; |
| 基于 twisted 框架,运行中的exception是不会干掉reactor(反应器),并且异步框架出错后是不会停掉其他任务的,数据出错后难以察觉 |
| |
54. 图片、视频爬取怎么绕过防盗连接
| 因为一些网站在解决盗链问题时是根据Referer的值来判断的,所以在请求头上添加Referer属性就好(可以填爬取网站的地址)。 |
| 另外Referer携带的数据 是用来告诉服务器当前请求是从哪个页面请求过来的。 |
| URL url = new URL(""); |
| // 获得连接 |
| URLConnection connection = url.openConnection(); |
| connection.setRequestProperty("Referer", "http://www.xxx.com"); |
| |
55. 用什么数据库存爬下来的数据?部署是你做的吗?怎么部署?
| 分布式爬虫的部署 |
| 1.下载scrapy_redis模块包 |
| 2.打开自己的爬虫项目,找到settings文件,配置scrapy项目使用的调度器及过滤器 |
| 3.修改自己的爬虫文件 |
| 4.如果连接的有远程服务,例如MySQL,Redis等,需要将远程服务连接开启,保证在其他主机上能够成功连接 |
| 5.配置远程连接的MySQL及redis地址 |
| 6.上面的工作做完以后,开启我们的redis服务器 |
| 进入到redis文件下打开我们的cmd窗口:输入:redis-server redis.windows.conf |
| 如果出现错误: |
| 解决方法:在命令行中运行 |
| redis-cli |
| 127.0.0.1:6379>shutdown |
| not connected>exit |
| 然后重新运行redis-server redis.windows.conf,启动成功! |
| 7.修改redis.windows.conf配置文件,修改内容如下: |
| |
| bind: (当前电脑IP) (192.168.40.217) |
| |
| protected-mode: no |
| 8.所有爬虫都启动之后,部署redis-server服务的电脑再打开一个命令窗口,输入redis-cli.exe -h 127.0.0.1(如果是自己的ip改成自己的IP地址) -p 6379连上服务端 |
| 9.连上之后会有127.0.0.1:6379>这样的字样提示,然后输入如下命令 |
| 10.lpush 爬虫文件里面自己定义的爬虫名字:start_urls 爬虫的网址 |
| 12.数据写不进去数据库里面: |
| - 修改MySQL的my.ini文件,以MySQL8为例 |
| - 路径在C:\ProgramData\MySQL\MySQL Server 8.0 |
| - 找到sql-mode="STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION"这一行 |
| - 把里面的STRICT_TRANS_TABLES,删除,逗号也删除,保存文件 |
| - 修改过之后需要重启mysql服务 |
| - 在windows命令窗口中使用net stop mysql80先停止服务,再使用net start mysql80启动服务 |
| - 如果my.ini文件不修改,爬虫的数据写入不了数据库 |
| |
56. 增量爬取
(1) 缓存
通过开启缓存,将每个请求缓存至本地,下次爬取时,scrapy会优先从本地缓存中获得response,这种模式下,再次请求已爬取的网页不用从网络中获得响应,所以不受带宽影响,对服务器也不会造成额外的压力,但是无法获取网页变化的内容,速度也没有第二种方式快,而且缓存的文件会占用比较大的内存,在setting.py的以下注释用于设置缓存。这种方式比较适合内存比较大的主机使用。
(2) 对item实现去重
| |
| def process_BookItem(self,item): |
| bookItemDick = dict(item) |
| try: |
| self.bookColl.insert(bookItemDick) |
| print("插入小说《%s》的所有信息"%item["novel_Name"]) |
| except Exception: |
| print("小说《%s》已经存在"%item["novel_Name"]) |
| |
| def process_ChapterItem(self,item): |
| try: |
| self.contentColl.insert(dict(item)) |
| print('插入小说《%s》的章节"%s"'%(item['novel_Name'],item['chapter_Name'])) |
| except Exception: |
| print("%s存在了,跳过"%item["chapter_Name"]) |
| def process_item(self, item, spider): |
| ''' |
| if isinstance(item,ChaptersItem): |
| self.process_ChaptersItem(item) |
| ''' |
| if isinstance(item,BookItem): |
| self.process_BookItem(item) |
| if isinstance(item,ChapterItem): |
| self.process_ChapterItem(item) |
| return item |
| |
两种方法判断mongodb中是否存在已有的数据,一是先查询后插入,二是先设置唯一索引或者主键再直接插入,由于mongodb的特点是插入块,查询慢,所以这里直接插入,需要将唯一信息设置为”_id”列,或者设置为唯一索引,在mongodb中设置方法如下
| db.集合名.ensureIndex({"要设置索引的列名":1},{"unique":1}) |
需要用什么信息实现去重,就将什么信息设置为唯一索引即可(小说章节信息由于数据量比较大,用于查询的列最好设置索引,要不然会非常慢),这种方法对于服务器的压力太大,而且速度比较慢,我用的是第二种方法,即对已爬取的url进行去重
(3) 对url实现去重
| class UrlFilter(object): |
| |
| def __init__(self): |
| self.settings = get_project_settings() |
| self.client = pymongo.MongoClient( |
| host = self.settings['MONGO_HOST'], |
| port = self.settings['MONGO_PORT']) |
| self.db = self.client[self.settings['MONGO_DB']] |
| self.bookColl = self.db[self.settings['MONGO_BOOK_COLL']] |
| |
| self.contentColl = self.db[self.settings['MONGO_CONTENT_COLL']] |
| def process_request(self,request,spider): |
| if (self.bookColl.count({"novel_Url":request.url}) > 0) or (self.contentColl.count({"chapter_Url":request.url}) > 0): |
| return http.Response(url=request.url,body=None) |
但是又会有一个问题,就是有可能下次开启时,种子url已经被爬取过了,爬虫会直接关闭,后来想到一个笨方法解决了这个问题,即在pipeline.py里的open_spider方法中再爬虫开启时删除对种子url的缓存
| def open_spider(self,spider): |
| self.bookColl.remove({"novel_Url":"http://www.23us.so/xiaoshuo/414.html"}) |
57. 什么是分布式存储?
| 传统定义:分布式存储系统是大量 PC 服务器通过 Internet 互联,对外提供一个整体的服务。 |
| 分布式存储系统具有以下的几个特性: |
| 可扩展 :分布式存储系统可以扩展到几百台甚至几千台这样的一个集群规模,系统的 整体性能线性增长。 |
| 低成本 :分布式存储系统的自动容错、自动负载均衡的特性,允许分布式存储系统可 以构建在低成本的服务器上。另外,线性的扩展能力也使得增加、减少服务器的成本低, 实现分布式存储系统的自动运维。 |
| 高性能 :无论是针对单台服务器,还是针对整个分布式的存储集群,都要求分布式存 储系统具备高性能。 |
| 易用 :分布式存储系统需要对外提供方便易用的接口,另外,也需要具备完善的监 控、运维工具,并且可以方便的与其他的系统进行集成。 |
| 布式存储系统的挑战主要在于数据和状态信息的持久化,要求在自动迁移、自动容 错和并发读写的过程中,保证数据的一致性。 |
| 容错:如何可以快速检测到服务器故障,并自动的将在故障服务器上的数据进行迁移 |
| 负载均衡:新增的服务器如何在集群中保障负载均衡?数据迁移过程中如何保障不影 响现有的服务。 |
| 事务与并发控制:如何实现分布式事务。 |
| 易用性:如何设计对外接口,使得设计的系统易于使用。 |
| |
58. 爬取下来的数据如何去重,说一下scrapy的具体的算法依据。
| 通过 MD5 生成电子指纹来判断页面是否改变 |
| nutch 去重。nutch 中 digest 是对采集的每一个网页内容的 32 位哈希值,如果两个网页内容完 全一样,它们的 digest 值肯定会一样。 |
| 数据量不大时,可以直接放在内存里面进行去重,python 可以使用 set()进行去重。当去重数据 需要持久化时可以使用 redis 的 set 数据结构。 |
| 当数据量再大一点时,可以用不同的加密算法先将长字符串压缩成 16/32/40 个字符,再使用 上面两种方法去重。 |
| 当数据量达到亿(甚至十亿、百亿)数量级时,内存有限,必须用“位”来去重,才能够满足需 求。Bloomfilter 就是将去重对象映射到几个内存“位”,通过几个位的 0/1 值来判断一个对象是 否已经存在。 |
| 然而 Bloomfilter 运行在一台机器的内存上,不方便持久化(机器 down 掉就什么都没啦),也不 方便分布式爬虫的统一去重。如果可以在 Redis 上申请内存进行 |
| Bloomfilter,以上两个问题就都能解 决了。 |
| simhash 最牛逼的一点就是将一个文档,最后转换成一个 64 位的字节,暂且称之为特征字,然后 判断重复只需要判断他们的特征字的距离是不是小于n(根据经验这个 n 一般取值为 3),就可以判断两个 文档是否相似。 |
| 可见 scrapy_redis 是利用 set 数据结构来去重的,去重的对象是 request 的 fingerprint(其实 就是用 hashlib.sha1()对 request 对象的某些字段信息进行压缩)。其实 fp 就是 request 对象加密 压缩后的一个字符串(40 个字符,0~f)。 |
| |
| |
| |
| |
| if not request.dont_filter and self.df.request_seen(request): |
| Requests对象,RFPDupeFilter对象 |
| |
| -写一个类,继承BaseDupeFilter类 |
| -重写def request_seen(self, request): |
| -在setting中配置:DUPEFILTER_CLASS = '项目名.dup.UrlFilter' |
| |
| |
| -增量爬取(100链接,150个链接) |
| -已经爬过的,放到某个位置(mysql,redis中:集合) |
| -如果用默认的,爬过的地址,放在内存中,只要项目一重启,就没了,它也不知道我爬过那个了,所以要自己重写去重方案 |
| -你写的去重方案,占得内存空间更小 |
| -bitmap方案 |
| -BloomFilter布隆过滤器 |
| |
| |
| from scrapy.http import Request |
| from scrapy.utils.request import request_fingerprint |
| |
| |
| requests1=Request(url='https://www.baidu.com?name=lqz&age=19') |
| requests2=Request(url='https://www.baidu.com?age=18&name=lqz') |
| |
| ret1=request_fingerprint(requests1) |
| ret2=request_fingerprint(requests2) |
| print(ret1) |
| print(ret2) |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| def request_seen(self, request): |
| |
| |
| fp = self.request_fingerprint(request) |
| |
| if fp in self.fingerprints: |
| return True |
| |
| self.fingerprints.add(fp) |
| if self.file: |
| self.file.write(fp + os.linesep) |
| |
59. 爬取数据后使用哪个数据库存储数据的,为什么?
- 数据同步插入数据库
在pipelines.py中引入数据库连接模块:
__init__是对数据进行初始化,定义连接信息如host,数据库用户名、密码、数据库名称、数据库编码, 在process_item中进行插入数据操作,格式都是固定的
| class MysqlPipeline(object): |
| def __init__(self): |
| self.conn = MySQLdb.connect('127.0.0.1', 'root', 'root', 'jobbole', charset='utf8', use_unicode=True) |
| self.cursor = self.conn.cursor() |
| def process_item(self, item, spider): |
| insert_sql = 'INSERT INTO jobbole_article (`title`, `create_date`, `url`, `url_object_id`, `content`, `front_image_path`, `comment_nums`, `fav_nums`, `praise_nums`, `tags`) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s)' |
| self.cursor.execute(insert_sql, (item['title'], item['create_date'], item['url'], item['url_object_id'], item['content'], item["front_image_path"], item['comment_nums'], item['fav_nums'], item['praise_nums'], item['tags'])) |
| self.conn.commit() |
| |
最后在settings.py中把MysqlPipelint()加入到系统中,需要注意的是优先级要小于之前加入处理图片路径的优先级
(先进行ArticleimagePipeline的处理,再进行MysqlPipeline处理)
| ITEM_PIPELINES = { |
| 'articlespider.pipelines.ArticlespiderPipeline': 300, |
| 'articlespider.pipelines.ArticleimagePipeline': 1, |
| 'articlespider.pipelines.MysqlPipeline': 4, |
| } |
| |
- 异步插入数据库
异步操作需要引入twisted:
| from twisted.enterprise import adbapi |
| import MySQLdb |
| import MySQLdb.cursors |
| |
| class MysqlPipeline(object): |
| def __init__(self, dbpool): |
| self.dbpool = dbpool |
| |
| @classmethod |
| def from_settings(cls, settings): |
| dbparms = dict( |
| host = settings["MYSQL_HOST"], |
| db = settings["MYSQL_DBNAME"], |
| user = settings["MYSQL_USER"], |
| passwd = settings["MYSQL_PASSWORD"], |
| charset='utf8', |
| cursorclass=MySQLdb.cursors.DictCursor, |
| use_unicode=True, |
| ) |
| dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms) |
| |
| return cls(dbpool) |
| |
| def process_item(self, item, spider): |
| |
| query = self.dbpool.runInteraction(self.do_insert, item) |
| query.addErrback(self.handle_error) |
| |
| def handle_error(self, failure): |
| print(failure) |
| |
| def do_insert(self, cursor, item): |
| |
| insert_sql = 'INSERT INTO jobbole_article (`title`, `create_date`, `url`, `url_object_id`, `content`, `front_image_path`, `comment_nums`, `fav_nums`, `praise_nums`, `tags`) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s)' |
| cursor.execute(insert_sql, (item['title'], item['create_date'], item['url'], item['url_object_id'], item['content'], item["front_image_path"], item['comment_nums'], item['fav_nums'], item['praise_nums'], item['tags'])) |
| |



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~