
记一次nfs报错排查
- 过程
业务主机5月6日上午9.20左右系统报错nfs服务端主机未响应。
影响:业务受到影响,无法进入此nfs所挂载目录。
处理:重启后恢复。
- 系统配置
系统版本:centos7.6
内存:32G
CPU:32核
磁盘类型:NFS挂载,业务使用卷
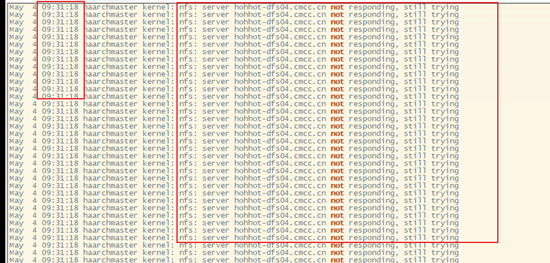
- 系统日志报错nfs: server host not responding, still trying
时间点2022.5.6,9点20分左右
![]()
根据报错提示字面意思为 nfs:服务器主机没有响应,仍在尝试,报错出现时间段没有发现系统的其它异常报错。
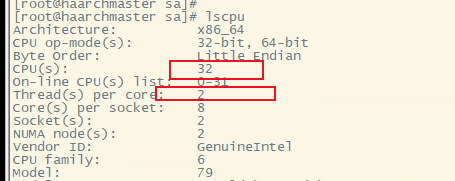
cpu为32核2双线程的配置
![]()
- 分析该时间段的性能日志
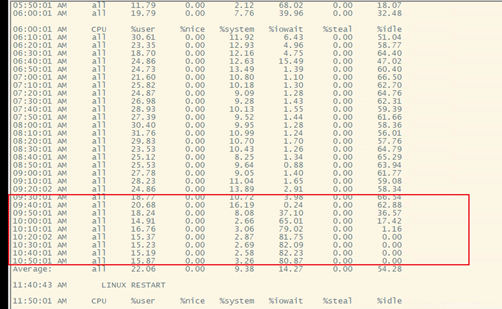
- 查看cpu和iowait状态
发现9:30开始iowait逐渐升高至80以上,cpu空闲率不断下降至0。
初步确定当时的cpu几乎没有空闲。
![]()
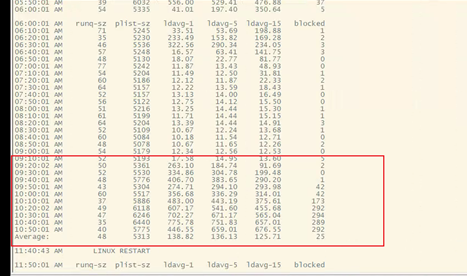
- 查看load负载
发现从9:10-20左右load开始飙升,pilst显示进程和线程数量增加明显,比5200平均多出500-1000的数量,从blocked列可以看到等待io处理完成的数量也在急剧增高,数量在200-300,正常时是只有0-10之间,几乎处于阻塞状态,说明io请求迟迟没有得到处理,因主机后面重启,无法查看当时的进程详细,这边认为是业务进程数量增加导致。
![]()
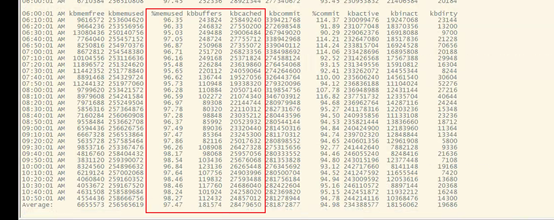
- 查看内存情况
物理内存使用较多,不过主要在cache中,内存没有问题。
![]()
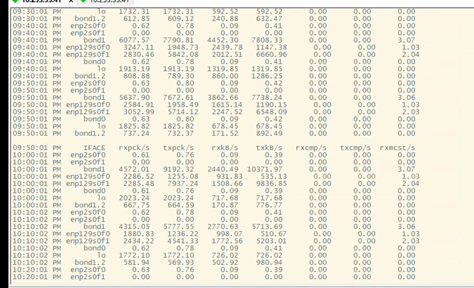
- 查看网络设备情况
并未出现丢包情况。
![]()
![]()
- 结果
经过排查nfs客户端分析:从历史性能看到,业务进程数量急剧增加,cpu使用率和iowait处于超负荷状态,io请求几乎处于阻塞状态,导致业务受到影响。
建议:1.确定nfs服务端当时的状况。
2.业务请求是否合理,导致进程数量和io请求队列急剧增高。
3.业务进程是否存在关联性,例如,死锁,io资源等待和竞争等


 浙公网安备 33010602011771号
浙公网安备 33010602011771号