
python自动化接口开发一
-
接口自动化开发
使用request模块实现网页接口自动化开发,利用chrome分析网站接口的请求信息,根据请求信息使用request实现http请求,从而实现网页接口自动化开发。
-
分析网站接口
接口自动化是通过查找网站接口, 然后以代码的形式来模拟浏览器来发送请求, 从而与网站服务器之间实现数据交互。 浏览器查找元素是在开发者工具的Element标签页完成的, 而网站的接口查找与分析是在开发者工具的Network标签页。
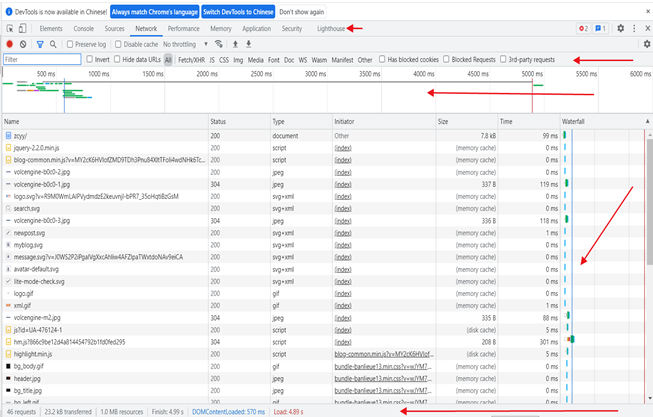
在Network 标签页可以看到页面向服务器请求的信息、请求的大小以及加载请求花费的时间。 从发起网页请求后, 分析每个HTTP请求都可以得到具体的请求信息(包括状态、类型、大小、所用时间、Request和Response等〉。 Network结构组成如图
图上的Network包括了5个区域, 每个区域的说明如下。
![]()
controls : 控制Network的外观和功能。
Filter: 将Request Table的资源内容分类显示。各个分类说明如下:
All: 返回当前页面全部加载的信息,就是一个网页全部所需要的代码,图片等请求。
XHR:筛选Ajax的请求链接信息,Ajax核心对象XMLHTTPRequest,XHR取决于XMLHTTPRequest的缩写。
JS: 主要筛选javascript文件。
CSS:主要是CSS样式内容。
Img:网页加载的图片,爬取图片的URL都可以在这里找到。
Media:网页加载的媒体,如MP3,RMVB等音频视频文件资源。
Doc:HTML文件,主要用于响应当前URL的网页内容。
Overview:显示获取到请求的时间轴信息,主要是对每个请求信息在服务器的响应时间进行记录。这个主要是为网站开发优化方面提供数据库参考。
Requests Table:按前后顺序显示网站的请求资源,单击请求信息可以查看该详细内容。
Summary:显示的总的请求数,数据传输量,加载时间信息。
在5个区域中, Requests Table是核心部分, 主要作用是记录每个请求信息。 但每次网站出现刷新时, 请求列表都会清空井记录最新的请求信息, 如用户登录后发生 304 跳转,就会清空跳转之前的请求信息并捕捉跳转后的请求信息。
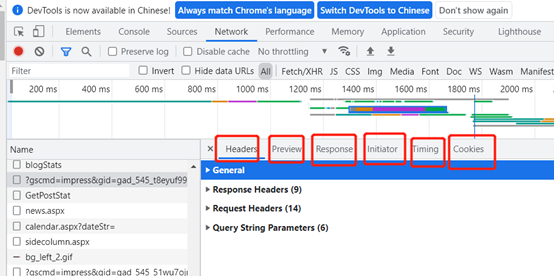
对于每条请求信息, 可以单击查看该请求的详细内容, 每条请求信息划分为以下5个标签。 如图
![]()
一个请求信息包含了Headers、Preview、Response、Cookies,initiator和Timing标签。分析接口主要看Headers、Preview和Response标签即可,说明如下:
Headers:该请求的HTTP头信息
Preview:根据所选择的请求类型(JSON、图片、文本)显示相应的预览。
Response:显示HTTP的Response信息。
Initiator 标记请求是由哪个对象或进程发起的(请求源)。
Parser: 请求由Chrome的HTML解析器时发起的。
Redirect:请求是由HTTP页面重定向发起的。
Script:请求是由Script脚本发起的。
Other:请求是由其他进程发起的,比如用户点击一个链接跳转到另一个页面或者在地址栏输入URL地址。
Cookies :显示资源HTTP的Request和Response过程中的Cookies信息。
Timing :显示资源在整个请求生命周期过程中各部分花费的时间。
Headers标签划分为以下4部分。
1.General:记录请求链接、请求方式和请求状态码.
2.Response Headers:服务器端的响应头.其参数说明如下:
Cache-Control:指定缓存机制,优先级大于Last-Modified.
-
Connection:包含很多标签列表,其中最常见的是Keep-Alive和Close,分别用于向服务器请求保持TCP连接和断开TCP连接。
-
Content-Encoding:服务器通过这个头告诉浏览器数据的压缩格式
-
Content-Length:服务器通过这个头告诉浏览器回送数据的长度。
-
Content-Type:服务器通过这个头告诉浏览器回送数据的类型.
-
Date:当前时间值
-
Keep-Alive:在Connection为Keep-Alive时,该字段才有用,用来说明服务器估计保留连接的时间和允许后续几个请求复用这个保持着的连接。
-
Server:服务器通过这个头告诉浏览器服务器的类型.
-
Vary:明确告知缓存服务器按照Accept-Encoding字段的内容分别缓存不同的版本.
-
3.Request Headers:用户的请求头。其参数说明如下。
Accept;告诉服务器客户端支持的数据类型。
Accept-Encoding:告诉服务器客户端支持的数据压缩格式.
Accept-Charset:可接受的内容编码UTF-8.
Cache-Control:缓存控制, 服务器控制浏览器要不要缓存数据.
Connection:处理完这次请求后, 是断开连接还是保持连接。
Cookie:客户可通过Cookie向服务器发送数据, 让服务器识别不同的客户端.
Host:访问的主机名.
Referer:包含一个URL, 用户从该URL代表的页画出发访问当前请求的页面, 当浏览器向Web服务器发送请求的时候, 一般会带上Referer, 告诉服务器请求是从哪个 页面URL过来的, 服务器借此可以获得一些信息用于处理。
User-Agent:中文名为用户代理, 简称UA, 是一个特殊字符串头, 使得服务器能 够识别客户使用的操作系统及版本、 CPU类型、 浏览器及版本、 浏览器渲染引擎、 浏览器语言、 浏览器插件等.
4.Query String Parameters:请求参数。 将参数按照一定的形式(GET和POST)传递给服务器, 服务器接收其参数进行相应的响应, 这是客户端和服务端进行数据交互的主要 方式之一 .
Preview和Response标签的内容是 一致的, 只不过 两者的显示方式有所不同。
如果返回的结果是图片, 那么Preview 可显示图片内容, Response则无法显示。
如果返回的是HTML或JSON, 那么两者皆能显示, 但在格式上可能会存在细微的差异。
-
Requests概述及安装
Request是一个很实用的HTTP客户端,常用于网络爬虫的接口自动化测试。语法简单易懂,符合python优雅,简洁的特性,兼容python2,python3。
requests可通过pip安装
windows系统:pip install requests
linux系统:pip install request
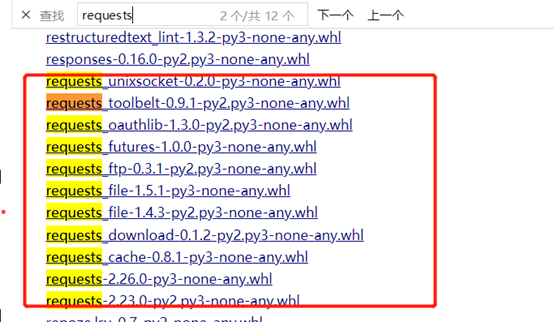
还可以去www.lfd.uci.edu/~gohlke/pythonlibs,按ctrl+F搜索关键字requests。
![]()
下载最下面那个,解压,然后把解压的文件放到python的安装目录Lib/site-packages中即可。
还可以使用pip安装这个文件,例如放在了D盘:D\下。
输入pip install requests2.23.0-py2.py3-none-any.whl
完成安装后,在cmd下运行python查看信息。如下:
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号