
K8S权威指南学习之service续
8.应用的配置问题
在此我们初步理解了三种应用建模的资源对象,总结如下:
- 无状态服务的建模:deployment。
- 有状态集群的建模:statefulset。
- 批处理应用的建模:job。
在进行应用建模时,应该如何解决应用在不同的环境中修改配置的问题呢?这就涉及到ConfigMap和secret两个对象。
ConfigMap顾名思义,就是保存配置项(key=value)的一个Map,它不能理解为编程语言的Map。
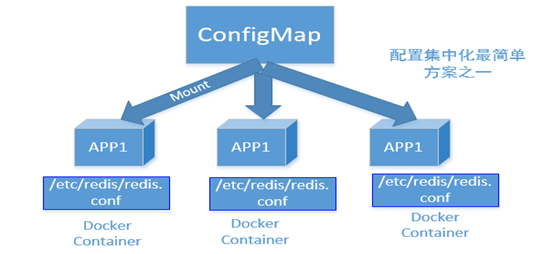
ConfigMap是分布式系统中"配置中心"的独特实现之一。我们知道,几乎所有应用都需要一个静态的配置文件来提供启动参数,当这个应用是一个分布式应用,有多个副本部署在不同的机器上时,配置文件的分发就成为一个让人头疼的问题,所以很多分布式系统都有一个配置中心组件来解决这个问题。但配置中心通常会引入新的API,从而导致应用的耦合和侵入。Kubernetes则采用了一种简单的方案来规避这个问题,如图所示,具体做法如下:
- 用户将配置文件的内容保存到ConfigMap中,文件名可作为key,value就是整个文件的内容,多个配置文件都可被放入同一个ConfigMap。
- 在建模用户应用时,在Pod里将ConfigMap定义为特殊的Volume进行挂载。在Pod被调度到某个具体Node上时,ConfigMap里的配置文件会被自动还原到本地目录下,然后映射到Pod里指定的配置目录下,这样用户的程序就可以无感知地读取配置了。
- 在ConfigMap的内容发生修改后,Kubernetes会自动重新获取ConfigMap的内容,并在目标节点上更新对应的文件。
接下来说说 Secret。Secret也用于解决应用配置的问题, 不过它解决的是对敏感信息的配置问题,比如数据库的用户名和密码、 应用的数字证书、 Token、 SSH密钥及其他需要保密的敏感配置 。对于这类敏感信息,我们可以创建一个Secret 对象,然后被Pod引用 。 Secret 中的数据要求以 BASE64编码格式存放。注意,BASE64编码并不是加密的。
在Kubernetes 1. 7版本以后, Secret中的数据才可以以加密的形式进行保存,更加安全。
9.应用运维的问题
本节说说与应用运维相关的几个重要对象。
首先就 是HPA ( Horizontal Pod Autoscaler),如果我们用Deployment来控制Pod的副本数量, 则可以通过手工运行 kubectl scale命令来实现Pod扩容或缩容 。如果仅仅到此为
止,则显然不符合谷歌对Kubernetes的定位目标---自动化、智能化。在谷歌看来,分布式系统要能够根据当前负载的变化自动触发水平扩容或缩容,因为这一过程可能是频繁发生、 不可预料的, 所以采用手动控制的方式是不现实的,因此就有了后来的HPA这个高级功能。我们可以将HPA理解为Pod横向自动扩容,即自动控制Pod数量的增加或减少。通过追踪分析指定Deployment控制的所有目标Pod的负载变化情况,来确定是否需要有针对性地调整目标Pod的副本数量,这是HPA的实现原理。Kubernetes内置了基于Pod 的CPU利用率进行自动扩缩容的机制,应用开发者也可以自定义度量指标如每秒请求数, 来实现自定义的 HPA功能。下面 是一个HPA定义的例子:
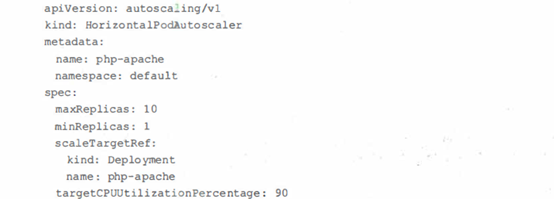
根据上面的定义,我们可以知道这个HPA控制的目标对象 是一个名为php-apache的Deployment里的Pod副本,当这些Pod副本的CPU利用率的值超过90%时,会触发自动动态扩容, 限定Pod的副本数量为1~10。 HPA很强大也比较复杂。
接下来就是VPA ( Vertical Pod Autoscaler ), 即垂直Pod自动扩缩容, 它根据容器资源使用率自动推测并设置Pod合理的CPU和内存的需求指标,从而更加精确地调度Pod,实现整体上节省集群资源的目标, 因为无须人为操作, 因此也进一步提升了运维自动化的水平。 VPA目前属于比较新的特性, 也不能与HPA共同操控同一组目标 Pod, 它们未来应该会深入融合。
-
存储类
存储类的资源对象主要包括Volume、 Persistent Volume、 PVC和StorageClass。
首先看看基础的存储类资源对象-----Volume(存储卷)
Volume是Pod中能够被多个容器访问的共享目录。Kubernetes中的Volume概念、用途和目的与Docker中的Volume比较类似,但二者不能等价。首先,Kubernetes中的 Volume 被定义在Pod上, 被一个Pod里的多个容器挂载到具体的文件目录下;其次, Kubemetes 中的Volume与Pod的生命周期相同, 但与容器的生命周期不相关, 当容器终止或者重启时,volume中的数据也不会丢失;最后,Kubemetes支持多种类型的Volume,例如GlusterFS、 Ceph等分布式文件系统。
Volume的使用也比较简单, 在大多数情况下, 我们先在Pod上声明一个volume,然后在容器里引用该Volume并将其挂载( Mount )到容器里的某个 目录下。举例来说,若我们要给之前的TomcatPod增加一个名为datavol的 Volume, 并将其挂载到容器的/mydata-data目录下,则只对Pod的定义文件做如下修正即可(代码中的粗体部分):
![]()
![]()
Kubemetes 提供了非常丰富的 Volume 类型供容器使用, 例如临时目录、 宿主机目录、 共享存储等, 下面对其中一些常见的类型进行说明。
- emptyDir
一个 emptyDir 是在 Pod 分配到 Node 时创建的。从它的名称就可以看出,它的初始内容为空,并且无须指定宿主机上对应的目录文件, 因为这是 Kubernetes 自动分配的一个目录,当Pod从 Node 上移除时emptyDir 中的数据也被永久移除。 emptyDir的一些用途如下。


- 临时空间, 例如用于某些应用程序运行时所需的临时目录, 且无须永久保留。
- 长时间任务执行过程中使用的临时目录。
-
一个容器需要从另一个容器中获取数据的目录(多容器共享目录)。
在默认情况下,emptyDir使用的是节点的存储介质,例如磁盘或者网络存储。还可以使用 emptyDir.medium 属性, 把这个属性设置为 Memory", 就可以使用更快的基于内存的后端存储了。 需要注意的是,这种情况下的 emptyDir 使用的内存会被计入容器的内存消耗, 将受到资源限制和配额机制的管理。
-
hostPath
hostPath为在 Pod 上挂载宿主机上的文件或目录,通常可以用于以下几方面。
- 在容器应用程序生成的日志文件需要永久保存时, 可以使用宿主机的高速文件系统对其进行存储。
- 需要访问宿主机上 Docker 引擎内部数据结构的容器应用时, 可以通过定义hostPath 为宿主机/var/lib/docker 目录,使容器内部的应用可以直接访问 Docker 的文件系统。
在使用这种类型的 Volume 时, 需要注意以下几点。
- 在不同的 Node上具有相同配置的 Pod, 可能会因为宿主机上的目录和文件不同,而导致对Volume上目录和文件的访问结果不一致。
- 如果使用了资源配额管理,则Kubernetes无法将hostPath在宿主机上使用的资源纳入管理。
在下面的例子中使用了宿主机的/data目录定义了一个hostPath类型的Volume:

-
公有云Volume
公有云提供的Volume类型包括谷歌公有云提供GCEPersistentDisk、 亚马逊公有云提供的AWS Elastic Block Store ( EBS Volume )等。 当我们的Kubernetes集群运行在公有云上或者使用公有云厂家提供的Kubernetes集群时, 就可以使用这类Volume。
- 其他类型的volume
- iscsi:将iSCSI存储设备上的目录挂载到Pod中。
- nfs:将NFSServer上的目录挂载到Pod中。
- glusterfs:将开源GlusterFS网络文件系统的目录挂载到Pod中。
- rbd:将Ceph块设备共享存储(Rados Block Device )挂载到Pod中。
- gitRepo:通过挂载一个空目录,并从Git库克隆(clone )一个gitrepository以供Pod使用。
- configmap:将配置数据挂载为容器内的文件。
- secret:将Secret数据挂载为容器内的文件。
动态存储管理
Volume属于静态管理的存储,即我们需要事先定义每个Volume,然后将其挂载到Pod中去用, 这种方式存在很多弊端, 典型的弊端如下。
- 配置参数烦琐,存在大量手工操作,违背了Kubernetes自动化的追求目标。
-
预定义的静态Volume可能不符合目标应用的需求,比如容量问题、性能问题。
所以Kubernetes后面就发展了存储动态化的新机制,来实现存储的自动化管理。相关的核心对象(概念)有三个:Persistent Volume (简称PV, StorageClass、PVC。
PV表示由系统动态创建( dynamically provisioned )的一个存储卷,可以被理解成Kubernetes集群中某个网络存储对应的一块存储,它与Volume类似,但PV并不是被定义在Pod上的, 而是独立于Pod之外定义的。 PV目前支持的类型主要有gcePersistentDisk、 AWSElasticBlockStore、 AzureFile、 AzureDisk、 FC ( Fibre Channel )、 NFS、iSCSI、 RBD (Rados Block Device )、 CephFS、 Cinder、 GlusterFS、 Vsphere Volume、 Quobyte Volumes 、 VMware Photon、 Portworx Volumes 、 ScaleIO Volumes、 HostPath、 Local等 。
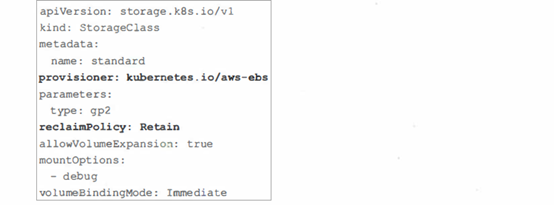
我们知道,Kubernetes支持的存储系统有多种,那么系统怎么知道从哪个存储系统中 创建什么规格的PV存储卷呢?这就涉及StorageClass与PVC。 StorageClass用来描述和定义某种存储系统的特征,下面给出一个具体的例子:
![]()
从上面的例子可以看出,StorageClass有几个关键属性:provisioner、 parameters和 reclaimPolicy,系统 在动态创建PV时会用到这几个参数。简单地说,provisimer代表了创建PV 的第三方存储插件,parameters是创建PV时的必要参数,reclaimPolicy则表明了PV回收策略, 回收策略包括删除或则保留。需要注意的是,StorageClass的名称会在 PVC ( PV Claim )中出现, 下面就是一个典型的PVC定义:
![]()
![]()
PVC正如其名,表示应用希望申请的PV规格,其中重要的属性包括accessModes(存储访问模式)、storageClassName(用哪种StorageClass来实现动态创建)及resources(存储的具体规格)。
有了以StorageClass与PVC为基础的动态PV管理机制, 我们就很容易管理和使用Volume了, 只要在Pod里引用PVC即可达到目的 , 如下面的例子所示:


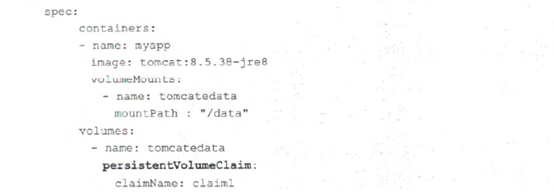
除了动态创建PV,PV动态扩容,快照及克隆的能力也是kubernetes的开发者们正在要研发的的新的高级特性。
-
安全类
安全始终是kubernetes发展过程中的一个关键领域。
从本质上来说 , Kubernetes可被看作一个多用户共享资源的资掠管理系统 , 这里的资源主要是各种Kubernetes里的各类资源对象, 比如Pod、 Service、 Deployment等。 只有通过认证的用户才能通过Kubernetes的APIServer查询 、 创建及维护相应的资源对象, 理解这一点很关键。
kubernetes里的用户有两类:我们开发的运行在Pod里的应用;普通用户 , 如典型的 kubectl命令行工具, 基本上由指定的运维人员(集群管理员)使用。在更多的情况下,我们开发的Pod应用需要通过APIServer查询、创建及管理其他相关资源对象 , 所以这类用户才是Kubernetes的关键用户。为此,Kubernetes设计了ServiceAccount这个特殊的资源对象, 代表Pod应用的账号,为Pod提供必要的身份认证。在此基础上,Kubernetes进一步实现和完善了基于角色的访问控制权限系统一-RBAC ( Role-Based Access Control )。
在默认情况下, Kubernetes在每个命名空间中都会创建-个默认的名称为default 的Service Account,因此Service Account是不能全局使用的,只能被它所在命名空间中的Pod 使用。 通过以下命令可以查看集群中的所有Service Account:
![]()
Service Account是通过Secret 来保存对应的用户(应 用)身份凭证的,这些凭证信息有CA根证书数据(ca.crt)和签名后的Token信息(Token)。在Token信息中就包括了对应的Service Account的名称, 因此API Server通过接收到的Token信息 就能确定 Service Account的身份。在默认情况下,用户创建一个Pod时,Pod会绑定对应 命名空间中的default这个Service Account作为其"公民身份证". 当Pod里的容器被创建时, Kubernetes会把对应的Secret对象中的身份信息(ca.crt、 Token等)持久化保存到 容器里固定位置的本地文件中 , 因此当容器里的用户进程通过Kubernetes提供的客户端API去访问 API Server 时,这些API会自动读取这些身份信息文件 ,并将其附加到HTTPS请求中传递给APT Server 以完成身份认证逻辑。在身份认证通过以后 ,就涉及 " 访问授权" 的问题, 这就是RBAC要解决的问题了。
首先我们要学习的是Role这个资源对象,包括Role与ClusterRole两种类型的角色。角色定义了一组特定权限的规则 ,比如可以操作某类资源对象。 局限于某个命名空间的角色由Role对象定义, 作用于整个Kubernetes集群范围内的角色则通过ClusterRole对象定 义。 下面是Role的一个例子, 表示在命名空间default中定义一个Role对象 , 用于授予对Pod资源的读访问权限, 绑定到该Role的用户则具有对Pod资源的get、watch和list权限:
![]()
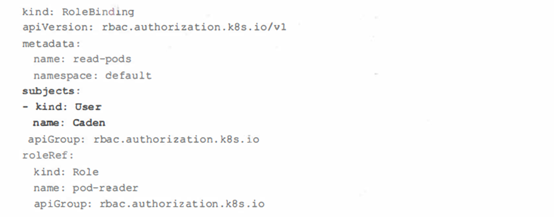
接下来就是如何将Role与具体用户绑定(用户 授权)的问题了。 我们可以通过RoleBinding与ClusterRoleBinding来解决这个问题。下面是一个具体的例子,在命名空间 default中将"pod-reader"角色授予用户"Caden",结合对应的Role的定义,表明这一授 权将允许用户"Caden:"从命名空间default中读取pod。
![]()
在RoleBinding中使用subjects(目标主体)来表示要授权的对象,这是因为我们可以授权三类目标账号:Group(用户组)、User(某个具体用户)和Service Account ( Pod应用所使用的账号)。
在安全领域,除了以上针对APIServer访问安全相关的资源对象,还有一种特殊的资对象。源对象-NetworkPolicy(网络策略),它是网络安全相关的资源对象,用于解决用户应用之间的网络隔离和授权问题。NetworkPolicy是一种关于Pod间相互通信,以及Pod与其他网络端点间相互通信的安全规则设定。
Network.Policy资源使用标签选择Pod,并定义选定Pod所允许的通信规则。在默认情况下,Pod间及Pod与其他网络端点间的访问是没有限制的,这假设了Kubernetes集群被 一个厂商(公司/租户)独占,其中部署的应用都是相互可信的,无须相互防范。但是,如果存在多个厂商共同使用一个Kubernetes集群的情况,则特别是在公有云环境中,不同厂商的应用要相互隔离以增加安全性,这就可以通过NetworkPolicy来实现了。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号