
K8S权威指南学习之service
service的ClusterIP地址
既然每个Pod都会被分配一个单独的 IP 地址, 而且每个Pod都提供了 一个独立的Endpoint ( Pod IP-containerPort )以被客户端访问, 那么现在多个Pod副本组成了 一个集群来提供 服务, 客户端如何访问它们呢?传统 的做法是部署一个负载均衡器(软件或硬件),为这组 Pod开启一个对外的服务端口如8000端口, 并且将这些Pod的Endpoint 列表加入8000端口的转发列表中, 客户端就可以 通过 负载均衡器的对外 IP地址+8000端口 来访问此服务了。Kubernetes也是类似的做法, Kubernetes内部 在 每个Node上都运行了一套全局的虚拟负载均衡器自动注入并自动实时更新集群中所有Service的路由表,通过iptables或者IPVS机制,把对Service的请求转发到其后端对应的某个Pod实例上,并在内部实现服务的负载均衡与会话保持机制。 不仅如此, Kubernetes还采用了一种很巧妙又影响深远的设计一一ClusterIP地址。我们知道,Pod的Endpoint地址会随着Pod的销毁和重新创建而发生改变,因为新Pod的IP地址与之前旧Pod的不同。Service 一旦被创建, Kubernetes 就会自动为它分配一个全局唯一的虚拟 IP 地址一一ClusterIP 地址, 而且在 Service的整个生命周期内. 其ClusterIP地址不会发生改变, 这样一来, 每个服务就变成 了具备唯一 IP地址的通信节点, 远程服务之间的通信问题就变成了 基础的TCP网络通信问题。
任何分布式系统都会涉及 " 服务发现" 这个基础 问题, 大部分分布式系统都 通过提供特定的API来实现服务发现功能, 但这样做会导致平台的侵入性较强, 也增加了开发、 测试的难度。 Kubernetes则采用了直观朴素的思路轻松解决了这个棘手的问题: 只要用 Service的Name与ClusterIP地址 做 一个DNS域名映射即可。 比如我们定义一个MySQL Service, Service的名称是mydbserver,Service的端口是3306,则在代码中直接通过 mydbserver:3306即可访问此服务,不再需要任何API来获取服务的IP地址和端口信息。
之所以说ClusterIP地址是一种虚拟IP地址,原因有以下几点。
-
ClusterIP地址仅仅作用于Kubernetes Service这个对象,并由Kubernetes管理和分配IP地址(来源于ClusterIP地址池),与Node和Master所在的物理网络完全无关。
-
因为没有一个"实体网络对象"来响应,所以ClusterIP地址无法被Ping通。Cluster IP地址只能与ServicePort组成一个具体的服务访问端点,单独的ClusterIP 不具备TCP/IP通信的基础。
-
ClusterIP属于Kubernetes集群这个封闭的空间,集群外的节点要访问这个通信端口,则需要做一些额外的工作。
下面是名为tomcat-server.yaml的service定义文件,内容如下:
apiVersion: v1
kind: Service
metadata:
name: tomcat-service
spec:
ports:
-port: 8080
selector:
tier: frontend
以上代码定义了一个名为tomcat-service的Service,它的服务端口为8080,拥有tier=frontend标签的所有pod实例都属于它,运行下面的命令进行创建:
kubectl create -f tomcat-service.yaml
我们之前在tomcat-deployment.yaml里定义的tomcat的pod刚好拥有这个标签,所以刚才创建的tomcat-service已经对应了一个pod实例,运行下面的命令可以查看tomcat-service的endpoint列表,其中172.17.1.3是Pod的IP地址,8080端口是container暴露的端口:
kubectl get endpoints
运行下面的命令可以看到tomcat-service被分配的ClusterIP地址更多的信息。
kubectl get svc tomcat-service -o yaml
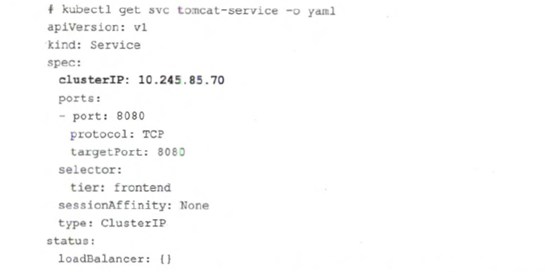
在 spec.ports 的定义中,targetPort 属性用来确定提供该服务的容器所暴露(Expose)的端口号,即具体的业务进程在容器内的 targetPort 上提供 TCP/IP 接人; port 属性则定义了 Service 的端口。 前面定义 Tomcat 服务时并没有指定 targetPort,所以 targetPort 默认与 port 相同。除了正常的 Service,还有一种特殊的 Service-Headless Service,只要在 Service 的定义中设置了 clusterIP: None,就定义了一个 Headless Service,它与普通 Service 的关键区别在于它没有 ClusterIP 地址, 如果解析 Headless Service 的 DNS 域名, 则返回的是该 Service 对应的全部 Pod 的 Endpoint 列表,这意味着客户端是直接与后端的 Pod 建立 TCP/IP 连接进行通信的, 没有通过虚拟 ClusterIP 地址进行转发, 因此通信性能最高,等同于 "原生网络通信"
接下来看看 Service 的多端口问题。 很多服务都存在多个端口, 通常一个端口提供业务服务, 另一个端口提供管理服务, 比如 Mycat、Codis等常见中间件。 Kubernetes Service 支持多个 Endpoint,在存在多个 Endpoint 的情况下, 要求每个 Endpoint 都定义一个名称进行区分。 下面是 Tomcat 多端口的 Service 定义样例:


4.service的外网访问问题
前面提到,服务的ClusterIP地址在Kubernetes集群内才能被访问,那么如何让集群 外的应用访问我们的服务呢?这也是一个相对复杂的 问题。耍弄明白这个问题的解决思路和解决方法,我们需要先弄明白 Kubernetes的三种IP,这三种IP分别如下。
Node IP: Node 的IP地址。
Pod IP:Pod的IP地址
Service IP:service的IP地址
首先,node ip是kubernetes集群中每个节点的物理网卡的IP地址,是一个真实存在的物理网络,所有属于这个网络的服务器都能通过这个网络直接通信,不管其中是否有部分节点不属于这个kubernetes集群。这也表明kubernetes集群之外的节点访问kubernetes集群内的某个节点或者TCP/IP服务时,都必须通过Node IP通信。
其次, Pod IP是每个Pod的IP地址, 在使用Docker作为容器支持引擎的情况下, 它是Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟二层网络。前面说过,Kubernetes要求位于不同Node上的 Pod都能够彼此直接通信, 所以Kubernetes中 一个Pod里的容器访问另外 一个Pod里的容器时, 就是通过 PodIP所在的 虚拟二层网 络进行通信的, 而真实的TCP/IP流量是通过Node IP所在的物理网卡流出的。
行通信的, 而真实的TCP/IP流量是通过Node IP所在的物理网卡流出的。
在Kubernetes集群内,Service的ClusterIP地址属于集群内的地址,无法在集群外直接使用这个地址。为了解决这个问题,Kubernetes首先引入了NodePort这个概念,Nodeport也是解决集群外的应用访问集群内服务的直接,有效的常见做法。
以tomcat-service为例,在Service的定义里做如下扩展即可(见代码中的粗体部分):


其中, nodePort:31002 这个属性表明手动指定 tomcat-service 的 NodePort 为 31002,否则 Kubernetes 会自动为其分配一个可用的端口。 接下来在浏览器里访问 http://<nodePort IP>:31002/,就可以看到 Tomcat 的欢迎界面了, 如图
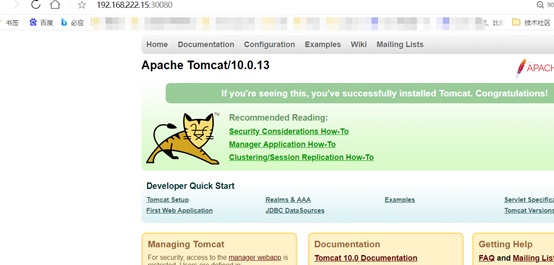
NodePort 的实现方式是, 在 Kubernetes 集群的每个 Node 上都为需要外部访问的 Service 开启一个对应的TCP 监听端口,外部系统只要用任意一个Node的 IP地址+NodePort 端口号即可访问此服务,在任意 Node 上运行 netstat 命令,就可以看到有 NodePort 端口被 监听:

但NodePort还没有完全解决外部访问Service的所有问题,比如负载均衡问题。假如在我们的集群中有10个Node,则此时最好有一个负载均衡器,外部的请求只需访问 此负载均衡器的IP地址,由负载均衡器负责转发流量到后面某个Node的NodePort上,如图所示。
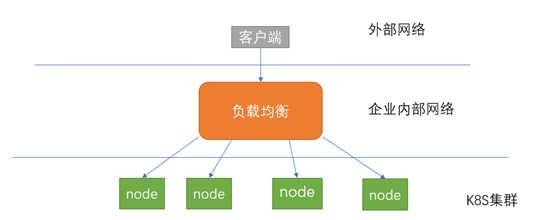
图中的负载均衡器组件独立于Kubernetes集群之外,通常是一个硬件的负载均衡器,也有以软件方式实现的,例如HAProxy或者Nginx。对于每个Service,我们通常 需要配置一个对应的负载均衡器实例来转发流量到后端的Node上,这的确增加了工作量 及出错的概率。于是Kubernetes提供了自动化的解决方案,如果我们的集群运行在谷歌的公有云GCE上,那么只要把Service的"type=NodePort改为"type=LoadBalancer", Kubernetes就会自动创建一个对应的负载均衡器实例并返回它的IP地址供外部客户端使用。其他公有云提供商只要实现了支持此特性的驱动,则也可以达到以上目的。此外,也有MetalLB这样的面向私有集群的Kubernetes负载均衡方案。
NodePort的确功能强大且通用性强,但也存在一个问题,即每个Service都需要在Node 上独占一个端口,而端口又是有限的物理资源,那能不能让多个Service共用一个对外端口呢?这就是后来增加的Ingress资掠对象所要解决的问题。在一定程度上,我们可以把 Ingress的实现机制理解为基于Nginx的支持虚拟主机的HTTP代理。下面是一个Ingress 的实例:

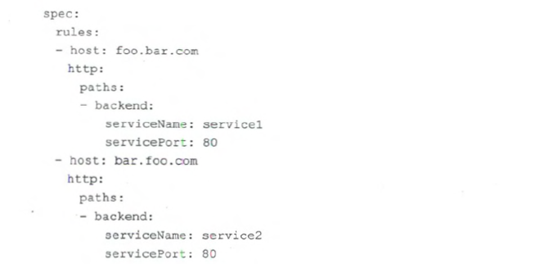
在以上 Ingress 的定义中, 到虚拟域名 first.bar.com 请求的流量会被路自到 service1,到 second.foo.com 请求的流量会被路由到 service2。 通过上面的例子, 我们也可以看出, Ingress 其实只能将多个 HTTP ( HTTPS )的 Service "聚合 ", 通过虚拟域名或者 URL Path 的特征进行路由转发功能。考虑到常见的微服务都采用了 HTTP REST 协议,所以 Ingress 这种聚合多个 Service 并将其暴露到外网的做法还是很有效的。
6.有状态的应用集群
我们知道 , Deployment 对象是用来实现无状态服务的多副本自动控制功能的,那么有状态的服务,比如 ZooKeeper 集群、 MySQL 高可用集群( 3 节点集群)、 Kafka 集群等是怎么实现自动部署和管理的呢?这个问题就复杂多了,这些一开始是依赖 StatefulSet 解决的,但后来发现对于一些复杂的有状态的集群应用来说, StatefulSet 还是不够通用和强大,所以后面又出现了 Kubernetes Operator。
我们先说说StatefulSet。 StatefulSet 之前曾用过 PetSet 这个名称, 很多人都知道,在IT 世界里, 有状态的应用被类比为宠物( Pet ), 无状态的应用 则被类比为牛羊, 每个宠物在主人那里都是 "唯一的存在" ,宠物生病了 , 我们是要花很多钱去治疗的, 需要我们用心照料, 而无差别的牛羊则没有这个待遇。 总结下来, 在有状态集群中一般有如下特殊共性。
-
每个节点都有固定的身份ID, 通过这个ID,集群中的成员可以相互发现并通信。
-
集群的规模是比较固定的, 集群规模不能随意变动。
-
集群中的每个节点都是有状态的, 通常会持久化数据到永久存储中, 每个节点在重启后都需要使用原有的持久化数据。
-
集群中成员节点的启动顺序(以及关闭顺序)通常也是确定的。
-
如果磁盘损坏, 则集群里的某个节点无法正常运行, 集群功能受损。
如果通过Deployment控制 Pod副本 数量来实现以上有状态的集群,我们就会发现上述很多 特性大部分难以满足,比如Deployment 创建的Pod因为Pod的名称是随机产生的, 我们事先无法为每个Pod都确定唯一不变的ID, 不同Pod的启动顺序也无法保证, 所以在集群中的某个成员节点岩机后, 不能在其他节点 上随意 启动一个新的Pod实例。另外, 为了能够在其他节点上恢复某个失败的节点 , 这种集群中的Pod需要挂接某种共享存储, 为了解决有状态集群这种复杂的特殊应用的建模, Kubernetes引人了专门的资源对象- StatefulSet。StatefulSet 从本质上来说, 可被看作Deployment/RC的一个特殊变种,它有如下特性。
-
StatefulSet里的每个Pod都有稳定、唯一的网络标识, 可以用来发现集群内的其他成员。假设Statefu!Set的名称为kafka, 那么第1个Pod 叫kafka-0, 第2个叫kafka-1,以此类推。
-
StatefulSet控制的Pod副本的启停顺序是受控的,操作第n个Pod时,前n-1个Pod已经是运行且准备好的状态。
-
StatefulSet里的Pod采用稳定的持久化存储卷,通过PV或PVC 来实现,删除Pod时默认不会删除与 StatefulSet相关的存储卷(为了保证数据安全)。
StatefulSet除了要与PV卷捆绑使用,以存储Pod的状态数据,还要与Headless Service 配合使用, 即在每个 StatefulSet定义中都要声明它属于哪个Headless Serviceo StatefulSet 在Headless Service的基础上又为 Stateful Set控制的每个Pod实例都创建了一个DNS 域名 , 这个域名的格式如下:
$ (podname) . $ (headless service name)
比如一个3节点的Kafka的 StatefulSet 集群 对应的Headless Service的名称为kafka, StatefulSet的名称为kafka, 则StatefulSet里3个Pod的DNS 名称分别为kafka-0.kafka、 kafka-1.kafka、 kafka-2.kafka, 这些DNS 名称可以直接在集群的配置文件中固定下来。
StatefulSet的建模能力有限, 面对复杂的有状态集群时显得力不从心, 所以就有了后来的Kubernetes Operator 框架和众多的Operator 实现了。需要注意的是, Kubernetes Operator框架并只是面向普通用户的,而是面向Kubernetes平台开发者的。平台开发者借助Operator框架提供的API,可以更方便地开发一个类似StatefulSet的控制器。在这个控制器里 ,开发者通过编码方式实现对目标集群的自定义操控,包括集群部署、故障发现及集群调整等方面都可以实现有针对性的操控,从而实现更好的自动部署和智能运维功能。从发展趋势来看未来主流的有状态集群基本都会以Operator 方式部署到Kubernetes集群中。
7.批处理应用
除了无状态服务、 有状态集群、 常见的第三种应用, 还有批处理应用。批处理应用的特点是 一个或多个进程处理一组数据(图像、 文件、 视频等), 在这组数据都处理完成后, 批处理任务自动结束。为了支持这类应用,Kubernetes引入了新的资源对象-Job,下面是一个计算圆周率的经典例子:

Jobs控制器提供了两个控制并发数的参数: completions和parallelism, completions 表示需要运行任务数的总数,parallelism表示并发运行的个数,例如设置parallelism为1 则会依次运行任务,在前面的任务运行后再运行后面的任务。 Job 所控制的Pod副本是短暂运行的,可以将其视为一组容器 ,其中的每个 容器都仅运行一次。当 Job控制的所 有Pod 副本都运行结束时,对应的Job也就结束了。Job在实现方式上与Deployment等副本控制器不同,Job生成的Pod副本是不能自动重启的,对应Pod副本 的 restartFolicy都被设置为Never,因此, 当对应的Pod副本都执行完成时,相应的 Job也就完成了控制使命。后来,Kubernetes增加了CronJob, 可以周期性地执行某个任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号