
《基于深度卷积神经网络的实体关系抽取》笔记
研究背景:传统的基于机器学习的方法针对不同的自然语言处理任务时需要使用不同的统计模型和优化算法,涉及大量手工挑选任务相关特征,同时选择结果、受到传统自然语言处理工具的影响,易造成误差传播。
这篇论文是基于CNN的模型,做出了两个小的改进:1.在初始输入为词向量和位置向量的基础上增加了类别关键词特征。2.在池化层选择分段最大池化策略,而不是一般的最大池化策略。
解决的问题:解决了传统的实体关系抽取模型学习之前需要人工手动的选取一些离散的特征, 特征的有效性和数量是依赖专家经验来判断。特征的选择过程依赖自然语言处理(NLP) 具,费时费力, 易造成错误传播等问题。
采用的方法:用深度卷积神经网络来抽取。
本文的突出特点是:
1.提出基于句子的衡量词重要性的TP-ISP算法,即通过该算法得到每个类别中各个词的tpisp值,利用从大到小排序选取排名前三的词作为该关系类别的关键词特征。减少了现有的使用深度学习的方法中仅依赖单-词询量学习特征的不足
2.采用分段最大池化策略,减少了一般的最大池化策略对于信息的丢失。
取得的成果:本文的模型在英文和中文语料中都使得实体关系抽取结果得到了很大的提升。
目前实体关系抽取抽取方法主要分为:
1.基于模式匹配
2.基于词典驱动
3.基于机器学习(简单高效,是主流方法)
机器学习又分为有监督学习和无监督学习:
无监督学习:预先不需要大量的标注语料,多用于开放域的关系抽取,可扩展性强,但性能相对较差,容易引入过多的噪声
有监督学习:针对特定领域,需预先定义关系类别:
①基于特征的关系抽取
②基于核函数的关系抽取
③基于深度学习
类别关键词特征的抽取:
一个类别的关键词往往可以很好地表征该类别的关键信息,因此许多研究将关键词策略引入到识别、分类等任务中。
TF-IDF算法常用来衡量一个字词对于一 份文件的重要程度,字词的重要程度正比于它在某文件中出现的频率,由于当前关于实体关系抽取问题的数据集中经常面对的是短文本句子,与文件不同,所以基于TF-IDF 思想,该文提出了一种基于句子的多类别的衡量词重要性的统计方法TP-ISP。
TP-ISP的思想:
1.计算包含某个词的关系实例所占该类别所有实例的比重,根据比重来衡量该词的重要性。比重越大,该词越重要。
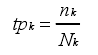 nk表示在某个类别中包含该词的实例数,Nk 表示该类别总的实例数。
nk表示在某个类别中包含该词的实例数,Nk 表示该类别总的实例数。
2.计算包含该词的实例在其他类别中分布的稀疏性。在其他类别中分布的越少越好,避免关键词是“的、得、了”之类的语气词。
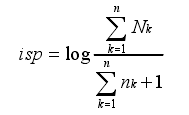 分子表示数据集中所有的实例数,分母表示包含该词的实例数,结果加1,防止分母为0。
分子表示数据集中所有的实例数,分母表示包含该词的实例数,结果加1,防止分母为0。
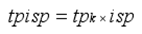
将得到的各类别中每个词按照其tpisp的值进行降序排列,tpisp 值越大,表明该词对于所属类别具有更强的表征能力。
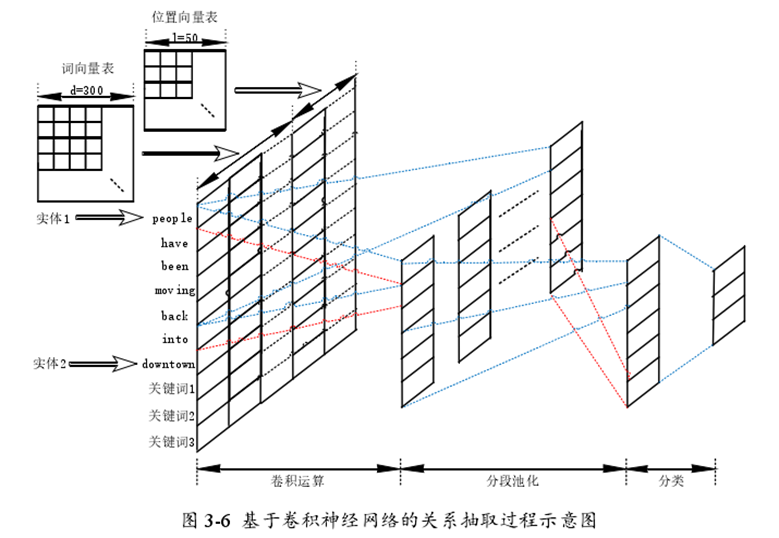
在原始词向量和位置向量的基础上,引入类别关键词特征作为网络的输入特征,并没有借助外部词典WordNet,也未使用自然语言处理工具,如:词性标注(POS) 、命名实体识别(NERs) 等。同时结合分段最大池化策略,取得了很好的分类效果。
英文关系抽取:
选用的英文数据集:
1.ACL 组织在2010语义评测会议中的评测任务8, SemEval-2010 Task8: Multi-Way Classification of Sematic Relation Between Pairs of Nominals:
在数据集SemEval- 2010Task8中,包含了10717个带有注释的实例,其中有8000个训练实例,2717个测试实例。每个实例中具有关系的两个实体都已经被标注出来,且这两个实体仅属于一种关系类型。 该数据集中共有9种带有方向的关系。
2. 2007 语义评测会议中的评测任务 4,SemEval-2007 Task 4:Classification of Semantic Relations between Nominals:
SemEval-2007 Task 4 数据集中共有 7 种不带方向的关系类别,共包含 1529 个带注释的实例,同样每个实例中的两个实体都已被标注,其中有 980 个训练实例和 549 个测试实例。





评价的指标:
实验中使用数据集官方文档中的评价指标宏平均 F1(macro-averaged F1)值进行评价。要计算 macro-averaged F1 值,首先要得到各个类别的准确率(Precision)、召回率(Recall)和 F1 值
 TPi 为被正确分为第 i 类实例个数,FPi 为被错误分为第 i 类的实例数,FNi 为本属于第i类实例被分为其他类别的实例数
TPi 为被正确分为第 i 类实例个数,FPi 为被错误分为第 i 类的实例数,FNi 为本属于第i类实例被分为其他类别的实例数
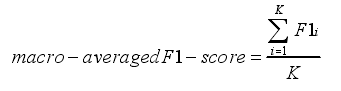 K 为总的类别数
K 为总的类别数
中文关系抽取:
选用的中文数据集:COAE2016 评测活动任务三
该任务要求在给定句子中识别出包含实体关系的句子,并判断实体关系类型。限定实体关系类型为 10 类,包含出生日期、出生地、毕业院校等关系类型
该实验语料中包含 988 个训练实例和 483 个测试实例,共包含 9 种关系类别
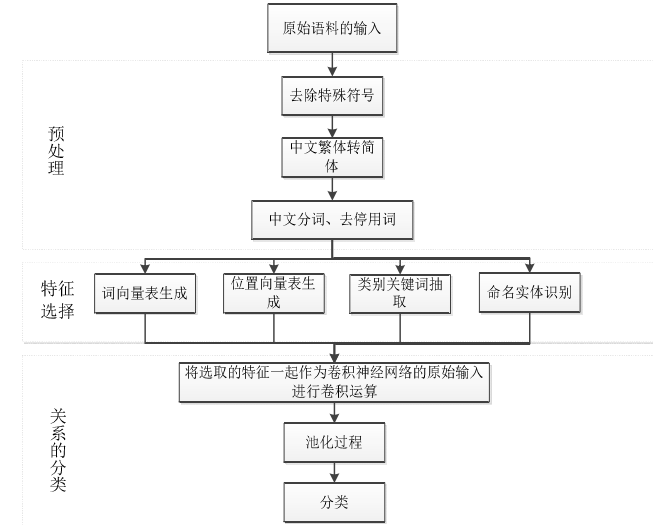
语料预处理过程主要包括:
(1)去除文本数据中的特殊符号以及一系列标点符号;
(2)对于语料中出现的繁体字,为了阅读的方便和后续的向量匹配,均将其转换
为简体字;
(3)抽取出标注好的实体,添加到用户词典中然后进行分词、去停用词。
该文使用的是开源的 python 结巴分词工具,通过在该工具中添加停用词表可以在分词的过程中将停用词去掉。
中文词向量表的训练:该文选用 word2vec 中的 Skip-gram 模型生成词向量。Skip-gram 模型是一种利用一个词来预测其周围词的概率的模型。
特征选取:位置向量特征和类别关键词特征
关系分类:将人工提取的显性特征作为网络的初始输入,依次经过卷积运算、分段池化作用和全连接层,然后将最终得到的特征一起进入 softmax 分类器进行分类。

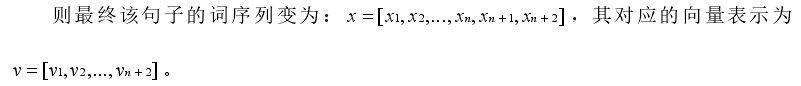
评价标准:对于多分类抽取问题,使用各类综合性能作为最终的评测标准 :
Ravg(Macro-averaged R)
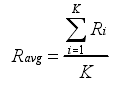
Pavg(Macro-averaged P)
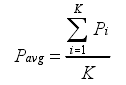
其中Pi 和Ri 分别表示某个类别的召回率和准确率,K 为总的类别数
F1avg(Macro-averaged F1)
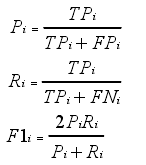 TPi 为被正确分为第 i 类实例个数,FPi 为被错误分为第 i 类的实例数,FNi 为本属于第i类实例被分为其他类别的实例数
TPi 为被正确分为第 i 类实例个数,FPi 为被错误分为第 i 类的实例数,FNi 为本属于第i类实例被分为其他类别的实例数
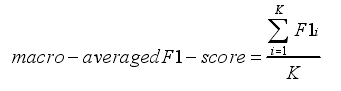 K 为总的类别数
K 为总的类别数
中文实体关系抽取任务所面对的挑战:
1.由于中文分词工具的有限性,在具体的实验语料中许多人名、地名、日期、数量等无法正确识别出来。
2.实体关系抽取中的特征选择依赖于自然语言处理工具的处理结果,中文语义结构复杂,抽取中会遇到不可避免的错误。
3.没有成熟的训练词向量的模型以及训练好的中文词向量表,而英文中相关的技术成熟,而且存在多种预先训练好的词向量表。

这篇论文是一篇硕士毕业论文,是基于她之前发表的一篇小论文改进的,但是毕业论文介绍性的东西太多,核心内容还在小论文上,但是她的小论文上是对英文关系的抽取,毕业论文后面加的中文关系抽取的讲解并不是很详细,而且选取的数据集比较小,抽取出来的关键词很随意的感觉,并没有英文关系类别那么严谨。并且,实验效果并不是很明显,基本上才提升了0.6%左右,效果很小,很难保证在其他数据集下也能有提升,该文也没有提供实验代码以及她提出的TP-ISP算法的代码,实验可信度不高。
综上而言,该论文的思想还是可以借鉴的,可以从以下几个方面改进:
1.该文对使用传统的CNN的模型并没有做出改进,可以尝试使用RNN等神经网络模型
2.可以采取其他算法来抽取类别关键词,因为她提出的TP-ISP算法抽取出来的关键词可信度并不高,还会引起噪音。
3.也可以在输入上做出改进,除了原有的词向量、位置向量和类别关键词特征,再增加其他的输入内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号