信息学奥赛一本通汇总
「基础算法」
第1章 递推算法
- 一般有具体的情境,可以通过直接的模拟转移过程来实现递推,T2,T4,T9
- 找到已知状态和所求状态的差别和联系,想办法将所求转化为已知进行转移,一般要用到分讨,T1,T3
- 根据题目将问题转化,增维,然后转化后进行递推,T8
第2章 贪心算法
- 一般像题目说什么全部都要满足,然后求最小代价这类题目是贪心,T1,T2,T3,T5,T6 若是什么选择一部分,获得最大代价,那么大抵可以往dp,反悔贪心上考虑
- 还有一类题型,有很多权值,每一个权值都可以选择不同的代价,所以肯定是权值最小的选最大的代价更优,经典模型,哈夫曼树,汽车匹配加油站模型,T4
- 字典序很容易出贪心,可能每次取最大值的本质注定它是个贪心吧,T7
- 根据运算的性质选择贪心方式,比如T8,或越或越多,与越与越少,于是就能决定贪心选择的长度
- 经典套路,每个物品代价相同,影响不同,所以每次贪心选择影响最小的物品更优T9
第3章 二分算法
- 典中典,最大值最小问题,T1
- 可以清晰的把数列分成一个具有单调性的问题,常见有奇偶,T2
- 答案为一个值,还有另外一个条件,求满足这个条件下值的最大(最小)值,因为条件不好搞,并且这个值具有单调性,只有满足条件和不满足条件这两种状态,于是就将求值问题转化为了给定值判断是否合法问题,T3,T4,T5,T6,T7,T8
第4章 深度搜索
- 直接按照题目限制和要传递的变量搜索即可,T1,T2
- 剪枝技巧1:当正确答案有且仅有一个时,对于枚举顺序的优化可以使得枚举次数变少,T3,T4
- 剪枝技巧2:可行性剪枝,一种方案如果枚举到一半已经不合法了,就去掉,T3
- 剪枝技巧3:上下界剪枝,对于枚举时做出的优化,根本不枚举一些本就不合法的枚举,常搭配数学技巧,T4
- 剪枝技巧4:最优性剪枝,因为当我们求出来一个答案后,如果后面搜索到的结果已经不具备比这个答案优的可能了的话,就剪掉好了,通常可以搭配上枚举顺序的优化
- 折半搜索,对于需要在一个序列中选出一些数然后来满足一个条件的问题,我搜一半,就可以直接判断另一半中哪一些是合法的,一般n<=40,T4
trick+1:如果是跟约数,因数相关的可以往质因数方面考虑,并且因为小一点的质因数有时具有很好的性质,所以只用枚举在一定范围的约数即可
第5章 广度搜索
- 对于题目中的各种技能(最多用多少次),不好操作的,可以作为一种状态下传,相当于多了一种转移方式,类似于分层图的思想,T3,T10
- 对于有多个终点可以建立虚点方便统计答案,T9
边权与bfs和spfa:
知州所众,spfa是最短路算法的一种,一个点可以重复入队,所以会导致复杂度劣于bfs
很关键的一点是因为其边权不固定,所以可能会出现之后遍历到的要比之前更优,就要重新计算了
然而bfs之所以稳定,是因为它只有一种边权,就是1
每次固定在队列里出现的点的深度最多相差1,并且深度小的是排在深度大的前面的,所以每次更新时保证了一定更新的是最优答案,其关键就在于队列里顺序是递增的
并且我们发现在没有负权边时我们只要保证队列里顺序时递增的就可以保证每更新到一个点一定是其的最优解(dij就是这个原理,证明详见最短路)
所以dij也可以理解为将bfs的队列改成优先队列,来保持队列内递增(大雾)
所以当边权有两种例如T4,0/1,我们可以把队列改成双端队列,这样让边权为0的加入在前面,边权为1的加入在后面,这样也可以保证队列的单调性,节省了排序或重复加入队列的复杂度
trick+1:当边权较小时w<=10,然后用最短路容易炸时,我们可以将边权拆点,将一条边拆成若干条边权为1的边和一些点,然后跑bfs即可
spfa相当于是暴力转移,所以大抵适用于所有情况,没有更新顺序,一个点若是被更新了答案,那么只好再次入队更新其他答案
这样就很好理解了
bfs与dfs:
对于具体情景问题的话是一般有固定的用法的:
本人最喜欢用到的还是dfs来解决问题,递归的比较舒服,大部分情况都能胜任
然而只有在图上跑的时候显然dfs是不合适的,这时就要采取bfs
谈一下对于二叉树情况的复杂度:
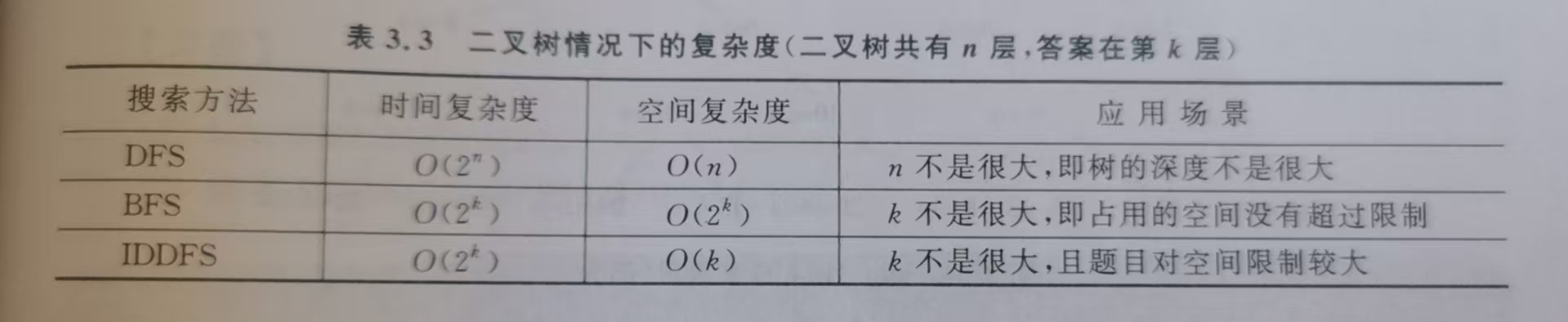
对于这种情况,dfs复杂度过高,bfs空间过曝的情况,可以采用IDA*算法
「字符串算法」
第1章 字符串处理
没啥好讲的,只要把字符穿char,string基础搞好就行了
第2章 Hash 和 Hash 表
- 将一堆数或字符串转化为一个数,方便比较,T1,T4,T5,T6,T7,T8,T9,T10
- 对于回文比较问题,可以通过二分+哈希解决,T2,T3
第3章 KMP 算法
- 因为nxt具有很好的前缀后缀相同的性质,所以有一些限制很奇怪的题,大抵可以往这方面考虑,T2,T3,T6
- 对于子串问题,显然kmp只能胜任固定一个端点来找另一个端点的工作,所以字串问题只能枚举左端点,然后kmp寻找右端点,T4,T5
- 把匹配的多维限制转化为一个可以比较的值是很常见的转化方法,我们需要找到其能满足限制所隐含的条件来做文章,T8,T9
第4章 字典树
- 对于在一堆字符串中匹配出前缀这类问题很适用,T1,T4,T5,T6,T8
- 把一个二进制串看成只包含0/1的字符串,然后进行各种异或问题,就是相当于在树上越远离越好,也非常经典,T2,T3,T7,T9
第5章 AC自动机
- 用于在好多个字符串和一个字符串进行子串比较时使用,T1,T7
- 对于那种无法保证每个单词的长度的题,我们暴力往上跳会超时,所以需要打上懒标记,然后按照拓扑序上传标记,T2,T3
- 由于AC自动机构成一棵树的结果,所以可以在上面进行深搜,dp等操作,T5,T6,T8,T10
trick+1:在kmp或AC自动机时之前所匹配的j是适用的可回退的,例T4
「图论」
第1章 并查集
- 带权并查集,一般处理需要维护并查集内部关系的题,例如把吃与被吃关系看成0/1的权值,T2,T3,T9
- 对于一个零散的数列,每次只合并,然后要快速求出一个点上下第一个没有被合并到的点,可以用并查集,T4,T8
- 对于很多删边操作,然后判断连通的问题,可以先离线下来,然后加边,并查集判断,T5,T6
第2章 最小生成树
- 建立虚点,支持一些不需要联通的操作把它变成最小生成树,T2,
- 动态维护最小生成树,每加入一条边,只需要在上一次的最小生成树的边集中加一条边然后跑最小生成树即可,T3
- 最小生成树是基于边权跑的,可以将点权和边权转化为边权考虑,T5,T8
第3章 最短路径
- 对于那种有特殊操作的题,我们可以先考虑dp转移操作次数什么的,然后就和bfs差不多,分层图最短路,T4,T8
- 给出一些具有传递性的关系,再查询一些关系,可以用floyd传递闭包实现,T5
- 最短路往往搭配二分使用,因为满足单调性,加一条边不会使得最短路变长,减一条边不会使得最短路变短,T6,T9
trick+1:当我们有一些特殊边,我们要算从一个点到另一个点最少经过多少条特殊边,则可以将特殊边的边权设为1,非特殊边边权为0,做最短路,T7
第4章 强连通分量
- 将有环图缩点为无环图,然后按拓扑序dp,T1,T3,T9
- 有向图独有的最小生成树,指的是问所有点能直接或间接的,T6
trick+1:对于有用的点可以重新建图,没有用的点直接扔掉,例如:T9
「数据结构」
第1章 堆的应用
- 动态维护最值,T1,T2,T5
- 对于堆中的删除,我们很不好操作,所以可以维护一个可删堆,若堆顶相同则删除,T3,T7
- 很多反悔贪心都要使用堆实现,因为反悔的一定是询问过的最值,T4,T6,T8
trick+1:字典序高位越大越好,所以具有贪心性质,很多字典序的题直接考虑贪心,例:T3
第2章 树状数组
- 首先支持维护动态前缀问题,对于广义上来说只支持单修单查(这里的广义包括前缀最值等),但是由于前缀和自身性质,在维护区间和时可以做到单修区查甚至区修区查,T1,T4,T5,T6
- 有二维限制的一般直接第一维排序,第二维在树状数组上前缀查询(一般要离散化),这就是经典的二维数点,T2,T3,T7,T8
trick+1:对于两层 \(\sum\) 可以拆出来,拆成一层,例: \(\sum_{i=1}^n\sum_{j=1}^ia[i]=\sum_{i=1}^na[i]*(n-i+1)\)
trick+1:给两个堆,每次可以将一个堆的堆顶移动到另一个堆顶,维护堆顶,可以将两个堆首接起来,然后形成一个数列,将左边的堆顶移动到右边,就将堆顶的指针往左移动一位即可,T9
第3章 RMQ问题
- 用于处理静态区间查询任务,并且区间重复运算并不会答案产生影响的问题,例如:区间最值,gcd,T1,T2,T3,T5,T7,T9,T8
- 矩阵处理静态区间查询任务,用二维ST表,T4
trick+1:当二维st表问题出现“每个询问的方阵的较长边不超过较短边的两倍”,时你会发现其实长和宽都是在一个log级别上的,只需要维护一个log级别长度的正方形即可,T6
第4章 线段树
- 用于区间修改,区间查询的区间问题,支持维护不可重复贡献问题和可重复贡献问题,例如加法和最值,T1,T2
- 对于一些特殊的区间问题,需要转化的,因为线段树是每次只会将两个区间合并,所以考虑维护什么东西可以使得 \(O(1)\) 合并两个小区间可以得出大区间的答案,T3,T10
- 懒标记的使用可以保证在下一次查询/修改前会先考虑之前的标记,所以可以在上面做文章,T4
- 在值域很小而操作很复杂时可以开很多棵线段树,分别维护每一个值所在的位置,然后根据题目需求手动删改,T5
- 对于一种操作,不能区间统一操作,只能单点进行,例如对每个数取模,开根号,仔细观察就会发现一些性质,然后我们不得不暴力修改每一个点,然后这时我们就需要控制每一个数暴力修改的次数,例如对于开根号,开几次就变成0/1,如果区间内都是0/1就不必要再操作了,例如取模运算,一个数(有效取模)取log次,就变成0/1了,所以一个区间的最大值小于模数,就一定不能在这个区间进行有效取模,这类题型最重要的就是控制暴力次数,也可以看作剪枝,T7
- 有的单点查询,区间复杂修改问题可以通过线段树维护差分数组实现,T8
- 对于相邻合并问题,长得就是一棵线段树,直接维护即可,T9
trick+1:树上通常依赖对于子树修改查询问题时,根据一个子树内dfs序连续,可以将其转化为区间问题,通常搭配线段树使用,T6
第5章 LCA 问题
- 使用倍增来预处理lca,T1,T5
- 将图上问题转化为树上维护问题,一般使用最大/最小生成树(有可能生成森林,注意建立虚点),T2,T4
- 树上差分需要用到lca来解决,树上差分一般是路径上所有值加上某个值时需要使用,T3
第6章 倍增问题
- 倍增也可以解决单调性问题,对于一个具有单调性的序列,利用单调性决定跳或不跳,T1
- 利用倍增来维护一段信息,然后整合在一起,经典应用ST表,倍增求lca,T2,T3,T4,T5
「动态规划」
第1章 背包问题
- 解决选一些物品,获得一些价值,但是每个物品又有代价,在总代价小于某个值的情况下,使得价值最大的问题,通常情况下以记录代价来进行转移,变式有多重背包,完全背包,分组背包等,T1,T2,T3,T6,T7
- 对于有捆绑关系的背包,我们别无选择,把几个捆在一起的物品看成一个,然后0/1背包,转移时分类讨论捆绑装哪个即可,T5
trick+1:询问一个序列中的数哪些可以被其它数拼成,我们可以先对序列排个序,因为小的数一定不可能被比其大的数拼成,T2
trick+1:当状态只有0/1两种时,如果状态是1的话是之前已经可以转移过来的,所以可以弃之不顾并且尽量沿用之前的选择是最优的,我们可以利用这个性质来搞点事情,比如状态只有0/1时记录连续转移的次数以达成对多重背包的优化,T4
trick+1:对概率问题不要无从下手,通常总方案数可以通过数学公式得出,然后合法方案数也可以通过dp,递推得出,相除即可,T8
trick+1:背包如果有一件物品是必选的,那么我们就要把这一层截胡,就是状态全设为-inf,只有,这一层能转移过来的才有值,T9
dp与爆搜:
我时常在考虑一个问题,dp到底比爆搜优化在哪里?
我给出的解答是,dp保证了你一定是从最优状态往下一个状态转移的,所以我们要做的事就是要设计一个无后效性的状态,使得列出来一个完全架空的转移
而爆搜就与你前者的选择息息相关,或许是当你发现这个爆搜与前者的选择没有那么相关时,就摘出来几项相关的量,设计dp状态即可
我觉的大部分dp状态设计都可以从刚刚的“摘出来”理论解释,比如:背包摘出来了体积,状压摘出来了所有点选或不选的状态,数位dp摘出来了这一位之前的贡献,树形dp则有一大部分记录下来了子树中的状态
尾巴:T10还没有做
第2章 区间DP
- 小区间合并成大区间,需要考虑相邻项合并的转移即可,然后区间合并时要枚举断点,所以是三层循环,T1,T6
- 由于题目限制,多了一些合并区间的方式,不单单是简单的拼凑两个区间,还有整块小区间往外拓展的转移,T2
- 有一种题是删掉几个数后这几个物品的左右就变成相邻的了,这时我们就可以另外在维护一下每个区间是否可以全部删去(有时可以通过如果能获得的最大价值就是区间的价值总和,则这一段区间一定能被删去来判断)或者是直接加上全部删去的贡献,然后如果可以的话,就再考虑将区间左右两边连着一起删,T4,T7
- 二维区间dp,没啥好说的,T5,T8
trick+1:对于转移较复杂的区间dp,我们可以考虑将大区间拆分成小区间,具体拆分过程可以只拆一个端点,T3
trick+1:把两个排列选到分别选到的位置 \(i,j\) 当成区间dp来看,然后再分别枚举两个排列的前面来转移,T9
尾巴:T10还没有搞明白差个题解
第3章 数位DP
- 用于统计在一个范围内,满足某个性质的数码出现了几次,通常我喜欢用记忆化搜索实现,然后从高位到低位依次下传有无前导零,卡没卡上界,高位是否满足题目给的条件等等,T1,T2,T3,T6
- 当把小于n的计数改成第n小的,我们可以二分,来强制转化为小于n的计数,T5
尾巴:T4,T7,T8,T9还没有写
第4章 树形DP
- 经典树上问题,然后一般是从一个点的子节点转移信息到父节点,T1,T2
- 树上背包,在子节点之中选一些节点获得最大价值,T4
trick+1:可以通过两次dfs来找到树上的最长距离的两个点,并且每个节点到树上最远的节点也是这两个端点之一的端点,T3
trick+1:对于求树上一些路径的权值和,可以单独求出每条边被经过的次数,T5
trick+1:树上求经过一个点的最长链,可以把这个点作为根然后再求一下子树內的最长链和次长链拼在一起,T6
trick+1:求树上连通块个数也可以用树形dp解决,T7
尾巴:T8,T9没有写
第5章 状压DP
- 求解集合问题:子集问题/排列问题,然后首先可以考虑暴力,暴力中要用到所有点的状态,经典的状压dp,T1
- 对于图上问题,我们考虑,在暴力时我们不知需要维护到过哪些点,还需要维护目前在哪一个点,T2
trick+1:当状态不只有两种时应该怎么办,不能进行 \(O(1)\) 比较了,那就预处理一下,状压dp的关键就是要使用 \(o(1)\) 比较,T3
trick+1:当你发现对于所有状态都枚举的话会超时,但是又发现合法状态很少时,我们可以先预处理出合法状态来减少枚举时间,T4
trick+1:如果要枚举一个状态所有的子集,可以使用 for(int j=i;j;j=i&(j-1)) ,T5,T8
trick+1:对于关键点问题,我们不用考虑其他的点,把关键点之间的关系预处理出来,然后在关键点之间考虑即可,T6
trick+1:对于求比值最大问题,要么就是使用0/1分数规划,要么就是用状压,已知各个节点的状态,你会发现本质上都是已知分子/分母,来求另一项的最大/最小值,T7
第6章 单调队列
- 单调队列求序列中每一个固定长度的字段的最值,T1,T7
- 优化dp使用,特征有求历史最值(不带修),并且随着右端点往右移,左端点只增不减,然后就设计状态再把无关项提出来维护单调队列即可,但是单调队列优化dp的题的精髓不在于优化,而是dp设计,下面详细展开,T8,T9
- 一般的题目都会有一个长度为n的序列,然后给你m次转移的机会,你就直接设二维dp状态即可,T2,T4
- 当有效节点个数很少,无效节点很多时,我们只在有效节点之间转移即可,T5
trick+1:当转移时从之前的dp状态转移过来的代价不一样,但是只有0/1时,我们可以考虑将单调队列中的相同元素删去,然后只考虑前两项即可,因为前一项必定小于后一项,并且前一项至多+1,T3
trick+1:太巧妙的trick,以至于我一直记忆犹新,如果转移是求 \(dp[i]=\max\{dp[k]+\max\{a_k,\dots,a_i\}\}\) 这里的 \(dp\) 数组是递增的,且此时 \(\max\{a_k,\dots,a_i\}\) 是随着 \(k\) 的增大而呈阶梯状下降的,所以我们会发现我们可以将每一个阶梯所对应的最大的 \(dp\) 在状态加起来,然后放在堆里,就能求出最小值了
「数学基础」
第1章 矩阵快速幂
- 先把递推式子列出来,然后再根据公式列出矩阵,然后往里套就行了,T2,T4,T6
- 邻接矩阵的转移方式(类floyd),和矩阵乘法一模一样,如果在有一个很大的转移次数的话,就可以直接矩阵快速幂加速优化了,T3,T5
- 广义矩阵乘法:满足 \(\oplus_{k=1}^n(A_{i,k} \otimes B_{k,j})\) 然后 \(\oplus\) 满足交换律,结合律,$\otimes $ 满足结合律,\(\oplus\) 满足对 $\otimes $ 的分配率,常见的有矩阵套矩阵,\(\oplus\) 最值和 \(\otimes\) 加减,T4,T5
- T1,T7,T8,T9都是快速幂的题,不赘述
第2章 质数和约数
- 线性筛素数,T1
trick+1:非常经典,我们要筛掉 \((L,R)\) 中的素数,然而 \(R\) 特别大,\(R-L\) 却在可控范围内,我们发现一个性质,一个合数必定能被一个小于其根号的质数删掉,那么我们就用小于 \(\sqrt R\) 的所有质数来筛里面的所有数即可,但是复杂度怎么保证呢?考虑一个数至多有 \(log\) 个质因子,就解决了吗,T2
trick+1:当一个很多未知量的方程出现的时候,并且要求说所有为质量都是正整数时,我们就可以转化一下,通过对某个已知两转化乘一些变量乘积的性质来进行质因数分解,然后来求解,注:当求解解的个数时可以使用正约数公式,T3,T6
trick+1:在 2e9 的范围内,一个数不同的质因子个数不会超过10个,T4
trick+1:取模运算的转化:\(k\mod n=k- \left \lfloor \frac {k}{n} \right \rfloor \times n\),T5
trick+1:如果有类似于对一个数对进行 \((a,a+b),(a+b,b)\) 那一定就是更相减损术,并且可以使用辗转相除法优化,T8
trick+1:把求gcd改为求两个数的因子相同的最大值,T10
第3章 同余问题
- 线性同余方程,求解 \(ax\equiv c\pmod b\),首先要满足 \(c|\gcd(a,b)\),然后用扩展欧几里得求得 \(x\),最后的解还要 $x'=x\times (c/\gcd(a,b)) $,T1,T6,T8
- 对于求约数个数,约数和之类的问题,都可以先质因子分解,然后再将质因子组合找规律进行求解,T2
- 线性求逆元,递推求解,推式子时只要将模数拆分代入即可,T3
- 中国剩余定理,用于求解同余方程组问题,T4,T7
trick+1:把序列和问题转化为两个前缀和数组相减问题,T5
尾巴:不清楚T9那个模数不是质数时如何操作的
第4章 组合数学
- 二项式定理计算展开式的系数,T1
- 如果求一个很大的组合数,并且需要取模,预处理出模数以内的组合数,然后再用卢卡斯定理递推求解,T2
- 对于两个相互独立的情况求总方案,可以先单独求出答案,再相乘,T5
trick+1:当出现这种状况时 \(x=n/m \pmod p\) 然而 p 不是质数,那么我们可以把p质因数解,然后分别在每个质数下求解,再求一个中国剩余定理,T3
trick+1:n个球,分成k段,可以看成放k-1个隔板,T4
trick+1:当求什么递减序列时,可以将值域进行隔板,T6
尾巴:T4高精不敢恭维,T7,T8没做
第5章 博弈论
- NIM游戏,T1
- 分讨时可以讨论奇偶,因子等等,T2
- SG函数,T3,T4
尾巴:说实话,博弈论还有很多问题没有解答,那就等以后再回头来看吧,T5,T6,T7,T8,T9
第6章 期望问题
- 最重要的:期望的线性限制,很容易将两个期望问题独立开求解,也就是把期望真正看成一个有实际意义的值,T1,T4,T5
- 当一个有实际意义的值转化为分数的规则是固定的时,我们不妨把期望分数改为期望的值,例如T2期望长度
- 路径总长度的期望转化为每一条路走过的期望之和,T3
尾巴:T6,T7,T8尚未解决
后记
一本通高效进阶耗时好几个月终于完成,虽然有几个尾巴,但是总体来讲完成的质量很高,完结撒花!!!
—————2025.1.30

 浙公网安备 33010602011771号
浙公网安备 33010602011771号