强化学习笔记
强化学习
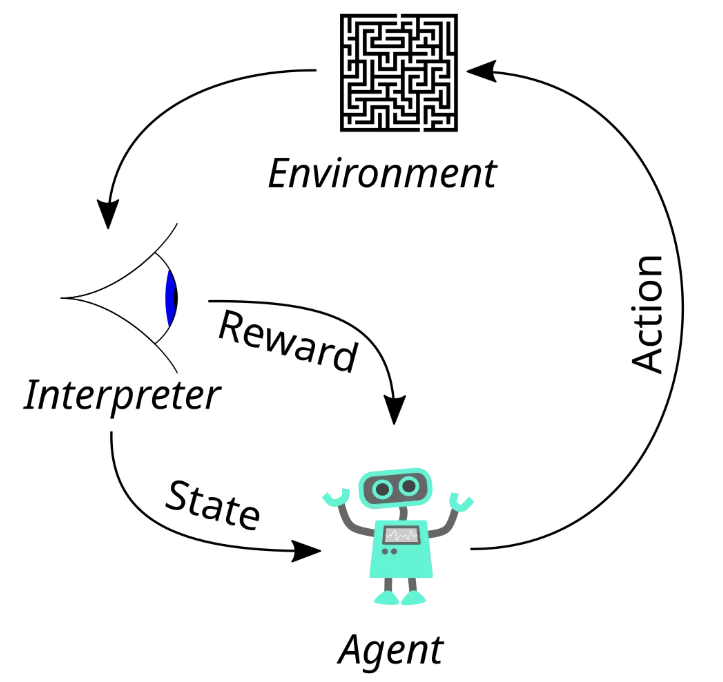
此笔记作为参考资料的补充,用于记录我在学习过程中不理解的地方。
请优先看西瓜书,里面讲解的更清晰。强烈推荐学习视频:深度强化学习背后的数学原理
强化学习的目标是:通过试错法找到一个最优策略 π,使智能体能够在不同状态下选择动作,从而最大化累积的折扣奖励。
马尔科夫决策
马尔可夫决策过程(Markov Decision Process, MDP)是强化学习问题的数学模型,用来描述一个具有随机性和决策性的环境。它由一个五元组⟨ S,A,P,R,γ ⟩表示,直接摘录了参考资料一中的描述:

其中状态转移遵循马尔可夫性,即:下一个状态 s′ 只依赖当前状态 s 和动作a,与过去的状态和动作无关。
这里需要强调的就是:无论是策略Π,或是奖励,或是状态s下采取动作a后状态转移至s',都有可能是概率的表示,不是一个确定的值。
累积奖励
学习的目的是使累计奖励最大化,长期累计奖励有很多种计算方法,常用的包括”T步累计奖励“和”γ折扣累积奖励“。”T步累计奖励“顾名思义,用T步之内的奖励的平均值来作为累积奖励,折扣累积奖励则在资料一给出定义。
策略
π(a∣s) 表示在状态 s 下选择动作 a 的概率。策略可以是确定性的(Deterministic)或随机的(Stochastic):
- 确定性策略:直接给出一个动作:
π(s)=a。例如:“在状态 s 下,始终选择动作 a”。 - 随机策略:是一个分布函数,给出每个动作被选取的概率:
π(a∣s)∈[0,1],且 ∑a∈A π(a∣s)=1。
状态值函数和状态动作值函数
在模型已知时,对于策略 π 能估计出策略的期望累积奖励。状态值函数Vπ(x) 表示从状态x出发,使用策略π所带来的累积奖励;状态动作价值函数Qπ(x, a) 表示从状态x出发,执行动作a后再使用策略π带来的累积奖励。
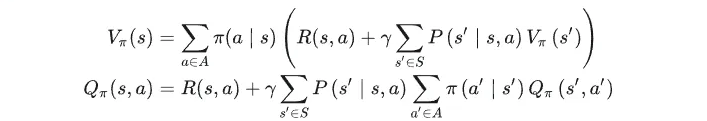
状态价值函数:状态动作价值函数的期望,每一个状态下有一定概率选择某一个动作。
状态动作价值函数:某一个状态下选择某一个动作的奖励和下一个状态的折扣价值的期望,一个动作有一定概率进入下一个状态。
最优值函数和最优动作值函数
需要强调的是,到目前为止我们假定的学习任务都是再有限状态空间上进行的,因此值函数是有限状态的”表格值函数“,即表格的形式保存值。所以更新过程,就是更新表格对应的值,而函数本身是不会改变的,这与深度学习中理解的更新参数不同。
最优值函数和最优动作值函数,是指最优策略下的值函数和动作值函数。核心只需要理解:
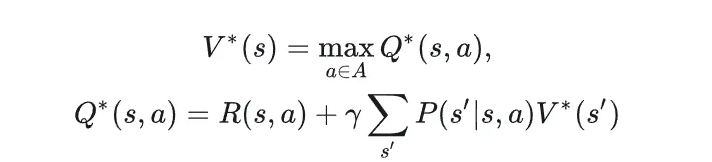
即可。
最优值函数表明:如果当下的策略是最优策略,那么值函数就是动作值函数的最大值。这是容易理解的,既然是最优策略,那么一定是一个确定性策略,在状态s下做出的行动a一定是使下一个状态的累积奖励最大的。
最优状态值函数:将最优策略下下一个状态的值函数替换为了最优策略下,下一个状态的最大动作状态值函数。
注意:动作值函数将作为策略更新的参考,也就是说,策略π(a∣s) 将更新为使动作值函数最大的动作。
手动推理


评估一个策略,才能进而决定使用哪一个策略,上述推理演示了使用矩阵乘的方式求解,但是当状态-动作空间很大时,这种方式显然行不通,于是有了策略迭代和值迭代方法。
策略迭代和值迭代
这一部分建议看西瓜书P381的伪代码,下面只说明两个方法之间的关系和区别。
根据前面的推理可以知道,策略迭代和值迭代的前提是你知道那几个概率,比如状态转移概率,奖励的概率。
策略迭代
策略迭代分为两大步骤:策略评估和策略改进,两者交替进行,逐步改进策略直到收敛。

值迭代

总结
策略迭代是先计算当前的状态值函数,再计算状态行为值函数,根据状态行为值函数更新策略,直到两次策略不改变。
值迭代一直在更新状态值函数,直到状态值函数的改变小于阈值,根据最优状态值函数计算最优状态-行为值函数,再更新策略。
免模型学习
现实的强化学习任务中,难以知道有几种状态,执行了某一种行为之后的状态转移概率,奖励函数等等,因此有了免模型学习。在书上,我们会看到模型已知这个词多次出现,所谓模型已知就是状态转移概率和奖励函数已知。
当模型已知时,从状态值函数V到状态动作值函数Q很简单,因为我们知道动作的奖励值和状态转移概率,使用贝尔曼方程计算。而模型未知时,只能在过程中逐渐发现各个状态,并且估计个状态-动作值函数。
在值迭代和策略迭代中,由于状态转移概率已知,所以可以通过状态值函数计算状态动作值函数,并选择动作-状态值函数最大的动作。但是在免学习模型中,我们的模型是未知的,因此用Q(s|a)的最大值表示V(s')。
蒙特卡洛强化学习
中心思想就是,执行选择的动作,用多次采样的平均来代替期望。因此这里提出了轨迹的概念,执行当前的策略T步之后获得轨迹:<s0, a0, r1, s1, a, r2……sT-1, aT-1, rT> 。

轨迹中出现的每一个状态-动作,记录其后的奖励值之和,记录多条轨迹之后,将平均值作为状态-动作值函数的估计。这样的方式可能会出现一个问题,某一个状态只有一个动作,所以轨迹是相同的,为了产生不同的轨迹,策略以ε的概率均匀选择动作,以1-ε的概率使用最优策略。
这里引入了”同策略“和”异策略“的概念,同策略蒙特卡洛强化学习算法最终产生的时ε-贪心策略,异策略的强化学习算法在策略改进时使用的是原策略,而算法评估时使用的是ε-贪心策略。西瓜书在这里给出的证明是为了说明,可以由ε-贪心策略的累积奖励估计原策略的累积奖励(类似于概率论里的估计值的概念),估计方法就是16.28的公式。在下面的伪代码里,主要的变化也就是累积奖励的变化。
时序差分学习
蒙特卡洛强化学习的方法可以看作是未经优化的最直观的免模型学习方法,用多次结果的统计值作为总体结果的估计值。由于是无模型学习,我们不可避免地需要使用采样,但是不再像蒙特卡洛方法一样使用多个采样轨迹,对轨迹统计完后再对Q进行更新。因此时序差分学习希望借鉴值迭代方法,利用第t+1次的采样结果对Q(t)进行增量式的更新。
与蒙特卡罗方法相似,时许差分学习也分为同策略算法和异策略算法,同策略算法即Sarsa算法,异策略就是Q-learning算法。

状态价值值函数的推导在西瓜书P387,以下是Q-learning算法,算法核心是对Q值的更新,使Q值逐渐逼近最优值:

值函数近似
在之前的强化学习方法都是对有限状态进行学习,但是现实的强化学习任务往往是无穷个状态且是连续状态空间,因此考虑使用线性函数来表示值函数。使用最小二乘法来度量值函数与真实的值函数之间的误差,梯度下降法更新值函数。由于不知道最优的值函数,因此用当前估计的值函数代替真实的值函数。
参考资料
- 强化学习入门笔记——Q-learning从理论到实践 - 知乎
- 西瓜书——第16章强化学习
- 基础离线算法:Q-Learning算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号