数据结构
单调栈和单调队列
可以理解为笛卡尔树但是更多时候单调栈会更好做。
PKUWC2020 火山哥和分数
有一个分式,其中 \(a\) 为每个位置的值,\(p\) 表示每个除号的优先级。\(q\) 次询问 \(a_{l-1}/a_l/\dots/a_r\),每个除号按优先级计算。
找到优先级最低的除号,分成上下两半去做。先看上部分,从第一个除号(\(p_l\))开始看,找到下一个比它大的然后依次去做。相当于 \(\frac{a_{l-1}}{\prod \dots}\)。而这个东西最后一定会走到最大的除号,就一定不会走到下半部分。容易发现这会形成一个树形结构,可以差分 \(O(1)\) 计算。关于这个树形结构如何维护边权,其实就是求一个小区间的答案。还是一样的做法,求出最大值。前一部分已经在之前做完了,而后一部分其实就是一条边,那也做完了。
再来看下面的部分,还是类似的思路搞一棵树,但是你发现这个贡献好像是交错的,注意这个部分即可。求边权还是一样的思路,找到最大值,下面的部分是之前求过的,而上面的部分其实就是一条边。
[NOI2005] 瑰丽华尔兹
[NOI2011] NOI 嘉年华
[BJOI2017] 树的难题
并查集
关于并查集的基础操作这里不再赘述,这里介绍一些用法。
初始时有 \(n\) 个点,依次增加 \(m\) 条边。计算每对点时在什么时候联通的。
求出任意点对的和。\(1\le n\le 10^6.\)
使用并查集,同时统计集合(子树)的大小,同时路径压缩且安置合并复杂度是 \(O(n\alpha(n))\)。
给一个长度为 \(n\) 的
01序列 \(a_1,\ldots,a_n\),一开始全是 \(0\),接下来进行 \(m\) 次操作:令 \(a_x=1\);
求 \(a_x,a_{x+1},\ldots,a_n\) 中左数第一个为 \(0\) 的位置。
经典题,如果连续一段的 \(1\) 就合并在一起。这样并查集查询的时候就可以查到下一个不是 \(1\) 的地方了。这个题也可以很轻松的上树,注意到操作一的区间操作也是均摊正确的。
给出三个长度为 \(n\) 的正整数序列 \(a,b,c\)。枚举 \(1\le i\le j\le n\),求 \(a_i\cdot b_j\cdot \min_{i\le k\le j}c_k\) 的最大值。
关于 \(c\) 数列的处理有很多方法,这里介绍并查集的方法。相当于点灯,从大到小枚举 \(c\),把枚举到的点亮,然后连成一片的就是合法的 \(a,b\) 区间。用 rmq 就可以求出 \(a,b\) 的最大值了。
可撤销并查集。
也不能随意删除某一个操作,只能从后往前撤销。经常用在分治算法中,把操作记下来然后使用按秩合并的并查集,把合并操作撤销即可。
堆
堆是一棵完全二叉树,满足其父亲总是大于(或小于)儿子。一般的堆满足插入删除在对数复杂度内做到。而最基础的操作就是向上向下调整法。具体来说,我们把要插入的节点放在最后,如果它比他的父亲要大,我们就把他和他的父亲交换。一直换到他应该在的地方。而删除只能删除根节点,将根节点与最后一个节点交换位置,直接删除。然后新的根节点向下调整,与较大的子节点交换位置。容易发现两个做法的复杂度都是树高,也就是 \(O(\log n)\)。
可并堆
这里只介绍一种可并堆——左偏树。
一些记号与定义
val:每个节点的权值,堆按这个排序。
外节点:没有左孩子或右孩子或都没有的节点。
dist:空节点的 \(dist\) 是 \(0\),外节点的 \(dist\) 是 \(1\),其余节点的 \(dist\) 为到最近的外节点的距离。
一棵左偏树的 \(dist\):记堆顶的 \(dist\) 为这课左偏树的 \(dist\)。
性质
左偏树顾名思义就是朝左偏的树。它在满足堆性质的基础上还要满足左孩子的 \(dist\) 大于等于右孩子的 \(dist\)。
在合并时全部怼到右孩子去就可以保证在 \(O(\log)\) 的时间复杂度内合并了。
显然,对于一个非外节点的 \(dist\) 等于其右孩子的 \(dist+1\)。
合并
合并时左偏树最重要的一步,我们以小根堆为例。
假设我们要合并两个堆的堆顶分别是 \(u,v\)。
于是我们为了满足小根堆的性质找出 \(val\) 较小的点做为新左偏树的顶点,这里不妨设其为 \(u\)。于是基于启发式合并的思想,我们把 \(u\) 的右孩子和 \(v\) 合并,递归去做就可以了。
因为一棵左偏树的 dist 最多是 \(ceil(\log{n})\),每次合并必有一棵左偏树的 \(dist\) 减 \(1\),所以这样合并的复杂度是\(O(\log{n}+\log{m})\)。
合并完有可能打破左偏树的性质,要更新。
int Merge(int u, int v) {
if (!u || !v) return u | v;
if (val[u] > val[v]) swap(u, v);
rson[u] = merge(rson[u], v);
if (dist[lson[u]] < dist[rson[u]]) swap(lson[u], rson[u]);
dist[u] = dist[rson[u]] + 1;
return u;
}
一些操作
类似线段树合并,也可以打懒标记学会 pushdown。结合例题理解。
[SCOI2011] 棘手的操作
有 \(N\) 个节点,标号从 \(1\) 到 \(N\),这 \(N\) 个节点一开始相互不连通。第i个节点的初始权值为 \(a_i\),接下来有如下一些操作:
U x y: 加一条边,连接第 \(x\) 个节点和第 \(y\) 个节点;A1 x v: 将第 \(x\) 个节点的权值增加 \(v\);A2 x v: 将第 \(x\) 个节点所在的连通块的所有节点的权值都增加 \(v\);A3 v: 将所有节点的权值都增加 \(v\);F1 x: 输出第 \(x\) 个节点当前的权值;F2 x: 输出第 \(x\) 个节点所在的连通块中,权值最大的节点的权值;F3: 输出所有节点中,权值最大的节点的权值。
搞一个类似并查集的找祖先操作,并且写一个类似线段树的 pushdown 操作。合并操作就用左偏树来搞。时间复杂度 \(O(n\log n)\)。
[BalticOI 2004]Sequence 数字序列
给定一个整数序列 \(a_1, a_2, \cdots , a_n\),求出一个递增序列 \(b_1 < b_2 < ··· < b_n\),使得序列 \(a_i\) 和 \(b_i\) 的各项之差的绝对值之和 \(|a_1 - b_1| + |a_2 - b_2| + \cdots + |a_n - b_n|\) 最小。
\(1\le n\le 10^6.\)
两个做法:一种是可并堆,一种是 slope trick。
考虑贪心先把问题转化为单调不降,如果序列是单调不降的,那么答案就可以是 \(0\)。序列是单调不升的,那么就全部取中位数最优。那我把序列分成一段一段的,每一段是单调不升的。但是这样还要求分段后每一段的中位数是单调递增的,否则合并更优(有新的中位数)。
[APIO2016] 烟火表演
树状数组
用于维护可差分可合并的信息,有代码量小常数小的优势。当然能干的东西完全被线段树取代,但是在部分简单的时候可以减少码量。
求前缀和类似信息:将一段前缀,按照二进制拆分成 \(\log n\) 段信息,每一个位置记录最低二进制位的那一段信息。结合 \(\operatorname{lowbit}\) 操作,可以快速实现。
lowbit(x)=x&(-x)
树状数组上倍增
可以优化一般的二分,具体可以参考下面的题目。
[CTSC2018] 混合果汁
看到这些条件想到二分答案,当然多个人就整体二分,这不是本文的重点。二分玩答案后就只用考虑价格和体积的问题,当然是越实惠越好,所以先买价格低的。那么这个时候就又需要一个二分,来确定需要买到多少价位的。如果二分套树状数组复杂度是 \(O(\log ^2V)\) 的,但是树状数组其实给了我们一个天然的二分条件。从大往小枚举二进制位,然后判断当前总和体积是否满足。这样看就只有一个 for 循环,复杂度为 \(O(\log n)\)。
线段树
分治信息 线段树要求能维护的信息是含幺半半群。也就是能写成矩阵乘法的东西。
线段树的重点是把区间分裂成若干个小区间,再把这些区间的信息合并。这些区间的信息也由更小的子区间信息合并而成。
对于一个区间 \([l,r]\),将其分成两个子区间 \([l,\lfloor\frac{l+r}{2}\rfloor],[\lfloor\frac{l+r}{2}\rfloor+1,r]\)。把每个区间当做树上的节点,左端点等于右端点的区间就是叶子结点,除了叶子结点每个节点有两个儿子分别是他分裂的两个子区间。
复杂度分析:显然树的高度是 \(O(\log n)\) 的。而一个区间每层最多可以用四个小区间表示,所以区间查询也是 \(O(\log n)\)。
例 II 洛谷3374 【模板】树状数组 1
如题,已知一个数列,你需要进行下面两种操作:
- 将某一个数加上 \(x\)
- 求出某区间每一个数的和
懒标记
考虑线段树的区间修改,显然不可能给区间里的每个数暴力修改。采用标记思想,在修改的节点打上标记,下次经过他的时候把标记下传给他的儿子。这时标记和信息就需要可下传性。
例 III 洛谷3372 【模板】线段树 1
如题,已知一个数列,你需要进行下面两种操作:
- 将某区间每一个数加上 \(k\)。
- 求出某区间每一个数的和。
例 IV 洛谷3373 【模板】线段树 2
如题,已知一个数列,你需要进行下面三种操作:
- 将某区间每一个数乘上 \(x\)
- 将某区间每一个数加上 \(x\)
- 求出某区间每一个数的和
这里需要注意的是标记合并的顺序,维护两个标记 \(add,mul\),在加法的时候 \(add+=x\),乘法的时候 \(add*=x,mul*=x\)。也就是先乘后加。
维护标记的重点就是需要保证下传标记后这个节点的信息必须是正确的
标记永久化
刚刚说的懒标记是需要下传的,我们也可以让标记永久存在在节点上,查询的时候把遍历到的节点上的标记合并即可。
如题,已知一个数列,你需要进行下面两种操作:
- 将某区间每一个数加上 xx;
- 求出某一个数的值。
位运算线段树
常数更小的非递归线段树,主要用来卡常数(貌似代码写起来也更短)。但是 zkw 线段树没法处理有运算符优先级的问题(比如线段树模板2)。
把线段树填充成满二叉树,那么就可以直接找到叶子结点。我们令 \(N\) 是叶子结点个数,那么 \(N+i\) 就是第 \(i\) 个数对应的叶子结点。为了最后一个节点不超出边界,我们这么得到 \(N=2^{\lceil\log_2{n+1}\rceil}\)。
单点修改的时候不停的跳父亲即可。
考虑区间询问和修改。我们记 \(lc=l-1+N,rc=r+1+N\),这两个指针不断的往上跳,直到跳到两者父亲相同(或者一个是 \(0\),一个是 \(1\))停止。这时 \(lc\) 的每个从左儿子跳上来时的右儿子或者 \(rc\) 的每个右儿子跳上来的左儿子,的并就是我们要找的区间。其实根据我们刚刚的推论每层最多只有 \(4\) 个。
对于修改,显然我们需要标记永久化。记录每个节点里面有多少被修改的节点,更改值即可。
这样子写线段树 1:
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int maxn = 1e5 + 5;
int n, m, N;
ll sum[maxn << 2], add[maxn << 2];
void modify(int l, int r, ll v)
{
int lnum = 0, rnum = 0, len = 1, lc, rc;
for (lc = l - 1 + N, rc = r + 1 + N; lc ^ rc ^ 1; lc >>= 1, rc >>= 1, len <<= 1)
{
sum[lc] += v * lnum;
sum[rc] += v * rnum;
if (~lc & 1) sum[lc ^ 1] += len * v, add[lc ^ 1] += v, lnum += len;
if (rc & 1) sum[rc ^ 1] += len * v, add[rc ^ 1] += v, rnum += len;
}
for (; lc; lc >>=1 , rc >>= 1)
{
sum[lc] += v * lnum;
sum[rc] += v * rnum;
}
}
ll query(int l, int r)
{
int lnum = 0, rnum = 0, len = 1, lc, rc;
ll ret = 0;
for (lc = l - 1 + N, rc = r + 1 + N; lc ^ rc ^ 1; lc >>= 1, rc >>= 1, len <<= 1)
{
ret += add[lc] * lnum;
ret += add[rc] * rnum;
if (~lc & 1) ret += sum[lc ^ 1], lnum += len;
if (rc & 1) ret += sum[rc ^ 1], rnum += len;
}
for (; lc; lc >>=1 , rc >>= 1)
{
ret += add[lc] * lnum;
ret += add[rc] * rnum;
}
return ret;
}
int main()
{
scanf("%d%d", &n, &m);
for (N = 1; N <= n + 1; N <<= 1);
for (int i = N + 1; i <= N + n; i++) scanf("%lld", sum + i);
for (int i = N - 1; i; i--) sum[i] = sum[i << 1] + sum[i << 1 | 1];
while (m--)
{
int op, l, r;
ll x;
scanf("%d%d%d", &op, &l, &r);
if (op == 1)
{
scanf("%lld", &x);
modify(l, r, x);
}
else
{
printf("%lld\n", query(l, r));
}
}
return 0;
}
大概快了 100 ms。
权值线段树
线段树的节点代表值域,每个节点相当于一个桶,用来表示一个区间的数的出现次数。权值线段树很大一部分时间用来代替平衡树,在值域很小的时候权值线段树其实把平衡树偏序了,但是当值域较大时权值线段树需要动态开点,所以空间复杂度比平衡树更劣。
更复杂的信息
尝试用简单的方法描述线段树维护的东西,可以看成每个节点维护了一个 \(val\),这是一个向量,然后两个子节点的 \(val\) 可以合并。每个节点还有一个标记 \(tag\),可以把这看成一个矩阵。将一个 \(tag\) 赋给一个节点时就是做一个矩阵乘法。而线段树题目所要解决的问题就是设计 \(val,tag\) 和乘法的规则。
- 维护 \(val\) 合并的例子
例 5 P4513 小白逛公园
单点修改,询问区间最大子段和
其实这种问题思考方式和动态规划很像。比如说我们要求最大子段和,那我们肯定要维护这个东西,记作 \(ms\)。那思考合并两个区间的时候最大子段和可以看成什么东西。
在左区间中的,在右区间中的以及跨过两个区间的。前两者已经知道了,而最后一项可以拆成两部分——在左侧的和在右侧的。那么我们可以维护左侧和右侧前缀和以及后缀和的最大值。
这个怎么合并呢?如果整个后缀和都在第二个区间里,那直接继承,否则跨过了中间,又可以拆成两个部分,第一个部分是左儿子的后缀最大值,第二部分是右儿子的区间和。所以我们还需要维护一个区间和。
至此所有值都可以互相推导,不需要再维护更多的值。
\(n\) 个点,\(m\) 个询问。给你一棵树的括号序列,输出它的直径。
有 \(m\) 次询问,每次询问表示交换两个括号,输出交换两个括号后的直径(保证每次操作后都为一棵树)
容易发现树上一条路径一定形如 ))...)((...(。也就是对于任意子段,去掉匹配了的括号后还剩下的部分。而这个东西还是不太好表示,我们有如下引理:
这个值等于 \(\max\limits_{k=l}^{r-1}s_{k+1,r}-s_{l,k}\),其中 \(s_{i,j}\) 代表把 ( 看成 \(1\),) 看成 \(-1\) 后区间 \([i,j]\) 的和。
证明 一定可以找到最后一个 ),当 \(k\) 取到这个位置时 \(s_{k+1,r}-s_{l,k}\) 显然就是答案。接下来证明这个值是最大的。在这个体系里面所有被匹配掉的括号贡献都是 \(0\),最后没被匹配掉的括号,\(k\) 往左往右都会变小,得证。
那么现在就是要求 \(\max\limits_{l,r} \max\limits_{k\in [l,r)}s_{k+1,r}-s_{l,k}\),即 \(\max\limits_{l,k,r}s_{k+1,r}-s_{l,k}\)。类似最大子段和,这个也可以用线段树来维护。
简单分类讨论 \(k\) 是取在区间中点的左边还是右边即可。
- 维护 \(tag\) 合并的例子
一个最经典大家又都熟悉的例子是区间最值操作。
- 单侧递归合并
区间查询前缀最大值的和
维护区间的答案,合并的时候,显然拿左儿子最大值 \(mx_{ls}\) 放到右儿子去匹配。所以还需要记录区间最大值。在右儿子的子树内二分,如 \(mx_{ls}\) 不大于某左儿子的最大值,显然右边部分不会变,直接返回即可。可以用整个减去左区间答案得到。否则左边部分全部变成 \(mx_{ls}\)。对于会变那个部分递归去做。
区间赋值,区间加,区间查询前缀最大值和自身乘积的和
- 李超树
HEOI2013 Segment
要求在平面直角坐标系下维护两个操作:
- 在平面上加入一条线段。记第 \(i\) 条被插入的线段的标号为 \(i\)。
- 给定一个数 \(k\),询问与直线 \(x = k\) 相交的线段中,交点纵坐标最大的线段的编号。
考虑对于每个区间维护这个区间中点的答案,即这个区间的中点在哪条线段取到最优。
然后考虑加入一个线段,先依据定义比较 \(mid\) 处的取值,如果更优就更新这个线段,然后依据斜率判断这个线段在哪个子区间中有可能更优,继续递归即可。由于最多只会有一个交点,所以只会往一侧递归。
由于一开始的线段要拆成 \(O(\log n)\) 个线段,所以复杂度应该为 \(O(n\log^2n)\)。而如果我们加入的直线,复杂度则为严格的 \(O(n\log n)\)。
而这个其实在干一个类似标记永久化的事情,所以查询的时候应该查一整条链。
CEOI2017 Building Bridges
优化转移方程 \(f_{i}=\min_{j=1}^{i-1}f_{j}+(h_i-h_j)^2+w_{i}\)
- 线段树合并分裂
线段树合并是一种思想,也不知道是谁先把它搞到线段树上的。考虑现在有 \(n\) 个节点,任意两个节点可以合并。那么如果每进行一次合并,节点数就会变少,于是复杂度就得到了保证。这种思想运用到分块上也是可以的。
P4556 [Vani有约会]雨天的尾巴 /【模板】线段树合并
P5327 [ZJOI2019]语言
P5298 [PKUWC2018]Minimax
P6773 [NOI2020] 命运
- 线段树优化建图
如果连边是 \([a,b]\to [c,d]\),那可以用线段来优化建边。其实就是虚点的思想,用线段树上 \(log\) 个区间来拆解要连边的区间。
进行单点与单点连有向边,进行单点与区间连有向边,进行区间与单点连有向边。然后求最短路。
建两棵树,一棵从父亲连向儿子叫做 A,另一颗从儿子连向父亲是 B。当要连边的时候从 B 连到一个虚点,再从虚点连向所有 A 树上的区间连边。
在一条直线上有 \(n\) 个炸弹,每个炸弹的坐标是 \(x_i\),爆炸半径是 \(r_i\),当一个炸弹爆炸时,如果另一个炸弹所在位置 \(x_j\) 满足:\(\mid x_j-x_i\mid \le r_i\),那么,该炸弹也会被引爆。
现在,请你帮忙计算一下,先把第 \(i\) 个炸弹引爆,将引爆多少个炸弹呢?
很直观的想法是直接把每个点向能炸到的点都连一条边,然后缩点dag再dp一下求出每个点能炸到的最左端和最右端。
我们发现每个点能引爆的点一定在某个区间内,所以我们容易想到线段树优化建图。
建一棵线段树,从父节点连向它的两个子节点一条有向边。
对于每个节点,计算出它自己爆炸的范围,然后向线段树上代表这个区间的那些点连边。
这个节点其实用线段树上的叶节点即可,不用再建新的节点。
然后跑一遍tarjan强连通分量缩点,每个新点要记录改分量里能炸到的最远的左右端点。
之后我们还有跑一点dag dp,用每个节点能到达的点更新其左右端点。
注意这里不能直接拓扑,要在反图上拓扑,因为这里直接拓扑时孩子是没有更新的(虽然能过。。。)
查询时直接返回对应scc的左右端点的差即可。
平衡树
所有平衡树都在干一件事——让树高(期望或均摊)尽量小。
fhq-treap
treap 是堆+二叉搜索树的合称。给每个点随机分配一个权值,使treap同时满足堆性质和二叉搜索树性质。fhq treap不需要旋转,重点就两个操作:merge 和 split。
这篇博客写得很全:https://www.luogu.com.cn/blog/85514/fhq-treap-xue-xi-bi-ji
关于fhq-treap复杂度的证明:
在引入了随机优先级后,Treap 就相当于以随机顺序插入得到的二叉搜索树,
考虑每个节点 \(i\) 在什么情况下会成为 \(x\) 的祖先。即 \(i\) 到 \(x\) 之间的节点优先级都小于 \(i\)。那么 \(x\) 的期望深度即为 \(1+\sum_{i=1}^{x-1}\frac{1}{x-i}+\sum_{i=x+1}^{n}\frac{1}{i-x}=O(\log n)\)。
替罪羊树
思想很简单,设置一个平衡因子 \(\alpha\),如果一个点的某个儿子,占到了子树大小的α,则认为不平衡,重构这个子树。别的不说,知道这个复杂度是均摊证明的就行。
splay
学习笔记:https://baijiahao.baidu.com/s?id=1613228134219334653&wfr=spider&for=pc
每次对一个节点进行操作的时候把这个点旋转至根
动态开点平衡树
也就是把所有没用到的节点放到一起,用到了再把其断开。
例 P3285 [SCOI2014]方伯伯的OJ
有一个长度为 \(n\) 的序列,以及 \(m\) 次操作。
- 把 \(x\) 的编号换成 \(y\) 并输出 \(x\) 的排名。
- 把 \(x\) 提升到第一
- 把 \(x\) 降到最后
- 查询排名为 \(k\) 的人
\(1\le n\le 10^8,1\le m\le 10^5\)。
split 的部分我们每个节点其实相当于维护了一段。
动态开点平衡树的具体操作就是如果我们需要搞一个用户,我们先找到它所在的节点,这个节点可能代表一段连续编号的区间,并且一定包含改用户,然后把这个节点分裂成三个节点(可以新建三个节点也可以垃圾回收),再merge会平衡树里。可以发现这样做的空间复杂度是 \(O(m)\) 的。
可是这道题还比较毒瘤的一点是它只告诉你用户编号,这时我们需要一个映射把用户编号映射到平衡树上的节点,而我们又不可能一对一的映射,因为这在分裂节点时的时间复杂度是不对的。有一个trick是只记录每个节点右端点所在节点,然后再map中二分找,找到第一个大于等于当前询问编号的肯定就是和当前询问编号在同一节点的。
可持久化
treap 的复杂度不依赖均摊,所以可以直接可持久化。需要注意的是在split,merge,pushdown这些需要修改节点权值的时候,就需要新建节点(其实如果merge之前必然split的话就不需要新建)。
需要注意的是,假如在可持久化的过程中涉及到复制一棵Treap,复制出来的Treap的随机优先级会与原本的Treap完全一样,这可能会导致后续操作的Treap不再平衡。目前OI界中常用的解决方法是,不存储节点的随机优先级,而是在需要比较优先级时再依据节点的子树大小随机地返回结果。
例 WC2016鏖战表达式
交互题。
给定一个表达式,有 \(k\) 种运算符,优先级按标号从小到大。每种运算符都是二元运算符,且都满足交换律和结合律。
要支持以下操作:
- 修改一个操作数
- 修改一个运算符。
- 区间翻转。
每次修改都是基于之前某个版本。要求每次修改完后,输出表达式的值。
通过交互的方式强制在线。
每次你需要求 \((a\operatorname{or}b)\) 的时候,都需要调用一次 F 函数。该函数最多调用 \(10^7\) 次。
KD Tree
KD-Tree 是一种用来解决高维问题的数据结构,本质上是一个二叉树的结构在不同层以不同维度来排序。考虑现在我们有许多高维点,KD-Tree 的节点代表一个包括子树内高维点的高维立方体。这个高维立方体可以用每一维的最大最小值来表示。
考虑当前是第 \(i\) 层,那么以 \(i\bmod k+1\) 维排序,取出排完序的中位数,比其小的递归构造左儿子,比其大的构造成为右儿子。容易发现这样每次一半,树高是 \(\log n+O(1)\) 的,注意不是 \(O(\log n)\)。个人建议写成 Leafy 的形式,即线段树的形式。
以 2D-Tree 为例,把节点分成三类:
- 与查询矩形无交的。
- 完全包含于查询矩形的。
- 与查询矩形有交的。
前两个直接返回,后者继续递归。我们考虑连续的 \(2\) 层,一条直线最多经过两个划分出来的矩形,所以 \(T(n)=2T(\frac{n}{4})+O(1)\),也就是 \(T(n)=O(n^{\frac{1}{2}})\)。同理可得,\(k\) 维情况复杂度 \(O(n^{1-\frac{1}{k}})\)。
下面来处理右插入的情况,显然插入会使得树不平衡,需要重构。
- 找到一棵最大的子树不平衡时拍扁重构。不过 skip2004 指出这样做会使深度变为 \(O(\log n)\) 而非 \(\log n+O(1)\)(并且这不能使用 Leafy 的写法,必须写成替罪羊树)。
- 插入根号个然后重构一次。
对于“区间”修改,既然都线段树式了直接打标记然后下传即可。
P4148 简单题
1 x y A\(1\le x,y\le N\),\(A\) 是正整数。将格子x,y里的数字加上 \(A\)。2 x1 y1 x2 y2\(1 \le x_1 \le x_2 \le N\),\(1 \le y_1\le y_2 \le N\)。输出 \(x_1, y_1, x_2, y_2\) 这个矩形内的数字和3无 终止程序
强制在线了,就不太好写成 Leafy 的形式,所以得单独加点。这里再说一种二进制分组式的。复杂度比根号重构好,并且查询的复杂度是正确的。就是采用类似 \(2048\) 的合并方法,每次合并就重构,这样每个数会被重构 \(O(\log n)\) 次,所以总的建树复杂度就是 \(O(n\log^2n)\)。
考虑扫描线,记录每个点最早在哪出现(也就是编号最小的矩形)。每次查询直接 KD-Tree,每个点打一个标记是哪个矩形,然后如果有标记就搞掉。这样要维护答案不太好搞,使用分块根号平衡。
[CH弱省胡策R2] TATT
四维空间真是美妙。现在有 \(n\) 个四维空间中的点,请求出一条最长的路径,满足任意一维坐标都是单调不降的。
[CTSC2015] 葱
[APIO2018] 选圆圈
kd-tree 分治
和线段树分治本质没有区别,就是把修改拆成若干部分挂树上。
[PA2011] Kangaroos
优化建图
[NOI2019] 弹跳
分块
Intro to Blocks
新瓶新酒,把之前所有遇到的分块的零零散散的内容都总结一下。
我也是不是啥数据结构大师,所以这篇 Tutorial 可能也没有啥深层次的理解。
可能有一些不属于分块的东西。本文芝士可能没有太明确的学习顺序,所以是可以乱序学的。
分块思想
其实也没有什么牛逼的东西,分块这个算法其实是一个思想,不是什么一定是 \(O(n\sqrt{n})\) 的什么算法。分块其实就是平衡思想,有的时候我们把信息分成若干个组,在组与零散的点中找平衡,这就是分块的基本思想。
那么需要解决的问题题就是组内信息的处理,组与组之间,组和零散信息之间如何合并。
自然根号
一些不需要特殊构造就存在根号结构。
数论分块
不想讲太多,结论就是 \(\lfloor\frac{n}{i}\rfloor\) 只有 \(O(\sqrt{n})\) 种不同的取值,且相同取值的数连续。\([l,\lfloor\frac{n}{\lfloor\frac{n}{l}\rfloor}\rfloor]\) 这一段的值都是 \(lfloor\frac{n}{l}\rfloor\)。
关于具体的证明可以看这里:https://oi-wiki.org/math/number-theory/sqrt-decomposition/
例 CQOI2007 余数求和
先来道简单一点的练练手
例 洛谷P6583 回首过去
https://www.cnblogs.com/zcr-blog/p/13157072.html
数论分块常用于莫比乌斯反演等数论题里,这里不过多解释。
和中不同数
设有 \(n\) 个数 \(a_1,a_2,\dots a_n\),他们的和是 \(m\),那么 \(n\) 个数最多有 \(O(\sqrt{m})\) 种不同的数。
启发式思想
https://www.luogu.com.cn/problem/P5576
结合字符串问题
https://www.luogu.com.cn/blog/command-block/str-ji-lu-cf204e-little-elephant-and-strings
https://www.luogu.com.cn/blog/command-block/str-ji-lu-loj6681-yww-yu-shu-shang-di-hui-wen-chuan
根号分治
暴力思想
假设一个问题有两种不同的方法,可以得到两种不同的复杂度,这个时候将数据分成两类,每类用适当的做法,以做到平衡总的复杂度的方法,就是根号分治。
为什么叫做暴力思想,因为通常有一种做法是暴力,另一种做法是另一种暴力/xyx
例 CF103D Time to Raid Cowavans
假设 \(n,q\) 同阶。两种暴力,一种是直接往后跳,复杂度 \(O(\frac{n}{k})\) 还有一种是枚举 \(k\),然后从后往前扫一遍 dp,复杂度 \(O(nk)\),于是平衡一下,取 \(k=\sqrt{n}\),小于的部分做第二种暴力,大于的部分做第一种暴力,复杂度为 \(O(n\sqrt{n})\)。注意这题的空间限制,所以不能开桶,要离线。有一点卡常。
例 CF1580C Train Maintenance
赛时没做出来真的可惜,当时还是太菜了。设定阈值 \(B=\sqrt{n}\),如果 \(x+y>B\) 就暴力跳然后差分。否则对于每个 \(x+y\) 维护一个数组,代表一个 \(x+y\) 周期每天维修的车的数量,然后在查询的时候枚举所有 \(\le B\) 的 \(x+y\),算出这个位置在周期里是第几个即可。
例 CF1039D You Are Given a Tree
这大概就是根号分治的暴力思想,接下来我们来看一些具体的应用场景(套路)。
对次数分治
例 CF444D DZY Loves Strings
https://www.luogu.com.cn/problem/P8330
对度数分治
对长度分治
https://www.luogu.com.cn/problem/CF587F
习题
IOI2009 regions
由于所有地区出现次数和是 \(n\),所以直接对出现次数分治,对于 \(r_1\) 出现次数大于 \(\sqrt{n}\) 的,暴力在树上扫一遍,就可以对于每个点求出有多少个祖先是 \(r_1\) 了。否则我们可以直接枚举每个 \(r_1\),然后记录他有多少个后代是 \(r_2\)。这可以离线枚举每个 \(r_2\),那这样就是有 \(O(n)\) 次修改,\(O(n\sqrt{n})\) 次询问,值域分块平衡复杂度,不会值域分块的可以先看后面值域分块的部分。
看到这种与 \(p\) 的大小有直接关系的题可以想想根号分治。思想其实很简单,就是设定一个阈值 \(k\),把大于其的和小于其的分开来讨论。对于这道题我们很容易想到一个暴力建边跑最短路的方法:从 \(b_i \rightarrow b_i + s \times p_i\) 连一条长度为 \(|s|\) 的边,我们将阈值设为 \(\sqrt{n}\),那么对于大于其的 \(p_i\) 最多会连 \(\sqrt{n}\) 条边。剩下的不是很好办,我们发现剩下的最多有 \(\sqrt{n}\) 个,我们考虑每 \(p_i\) 个点直接连一条边,不过这是错的,因为这个边是有向的。接下来就很妙了,建一个分层图,每个 \(p_i \le \sqrt{n}\) 都建一个,每层之间按上述方法连边,建一个第 \(0\) 层代表原来的图,如果有一只doge的 \(p_i \le \sqrt{n}\),那么就从第 \(0\) 层的 \(b_i\) 连向 \(p_i\) 层的 \(b_i\),代表其可以随意跳 \(p_i\),再从每一层的 \(b_i\) 连向第 \(0\) 层的 \(b_i\) 以方便换一只doge跳。
https://www.luogu.com.cn/problem/P5397
莫队
莫队的本质是路径规划,可以证明 \(k\) 维路径规划可以做到 \(O(n^{\frac{2k-1}{k}})\)
普通莫队
给你个一个长度为 \(n\) 的序列和 \(q\) 次询问,每次询问给你一个 \(l,r\),问在原序列区间 \([l,r]\) 内有多少个不同的数。可以离线。\(1 \le n,q \le 10^5\)。
算法1
在线做,每次遍历 \(l \rightarrow r\),统计每个数出现的次数,如果一个数的出现次数从 \(0 \rightarrow 1\) 的话答案就加一,如果从 \(1 \rightarrow 0\) 的话,答案就减一。这个算法的时间复杂度是:\(O(len \times q)\),\(len\) 是单次查询的区间长度,如果出题人用py造数据的话最优是可以单次 \(O(1)\)做的。
算法2
假设我们知道区间 \([1,5]\) 的答案,我们现在需要求出 \([2,6]\),那只需把 \(1\) 减掉,把 \(6\) 加上就可以在 \(O(1)\) 的时间内解决了。可是很遗憾这也是错的。只需搞一个 \([1,2], [9999,10000], [1,2], [9999,10000] \cdots\) 就可以卡死这个算法。
算法3
在算法2的提示下我们发现如果把询问离线,然后再排序就可以减少很多不必要的计算。如何来设计这个排序方法来达到最优的复杂度呢?这就是莫队做的事。
把原数列分块,块长为 \(\sqrt{n}\),最后一个块不够没关系。对询问排序时先按左端点所在块从小到大排序,对于同一块内的按右端点从小到大排序。
这样子如果我们可以在很短的时间内(通常是 \(O(1)\) 或者 \(O(\log{n}\)))从区间 \([l,r]\) 扩展到区间 \([l \pm 1,r \pm 1]\),对于一个块内左端点的扩展为 \(O(n)\)(从左到右再从右到左这样一直做),共有 \(\sqrt{n}\) 个块,所以左端点扩展的时间复杂度为 \(O(n\sqrt{n})\),因为右端点是有序的,所以每个块内右端点扩展最多是 \(O(n)\),所以右端点扩展的时间复杂度也为 \(O(n\sqrt{n})\),总的时间复杂度也就是 \(O(n\sqrt{n})\)了。
如果按上述排序方法可能不够快,原因是我们的右端点每次都是从最小到最大。如果我们可以让其从最小到最大再从最大到最小这样子可以省去很多冗余计算。即排序时相同块如果是奇数编号从小到大,偶数编号从大到小。
从这个例子我们可以看出普通的普通的莫队算法可以解决的问题:
只有询问且相互独立,可以快速从区间 \([l,r]\) 扩展到区间 \([l \pm 1,r \pm 1]\),允许离线。
关于块长和复杂度
之前的块长讲错了qaq,设快长为 \(t\),询问为 \(m\),序列长为 \(n\),则时间复杂度应为 \(O(mt + \frac{n^2}{t})\),由均值不等式可得当 \(mt=\frac{n^2}{t}\) 即 \(t=\frac{n\sqrt{m}}{m}\) 时有最小值 \(O(n\sqrt{m})\)。此时如果取块长为 \(\sqrt{n}\) 的话时间复杂度是 \(O((n+m)\sqrt{n})\) 的,\(m\) 比 \(n\) 大很多时有明显的优势。
练习
回滚莫队
首先我们要理解回滚的意思。
回滚指的是程序或数据处理错误,将程序或数据恢复到上一次正确状态的行为(以上摘自百度百科
简单来说就是撤销操作。回滚莫队是用来解决扩展容易删除难或删除容易扩展难的问题(如果都难就别用莫队了。
第一种情况:扩展易,删除难。
例题:歴史の研究
因为接口问题这题再luogu上可能无法提交,但也不妨碍我们做题。
考虑莫队怎么扩展,我们发现想从\(l \rightarrow l-1\)或\(r \rightarrow r+1\)只用算出取值和之前的最大值比较就行。可是删除操作就不太好做了,你有可能删掉的就是之前的最大值。当然,估计可以用维护次大值的方法,但这样太麻烦了,我们考虑稍微暴力一点的做法。
首先排序的时候先按l的块排,同一块内的按r从小到大,这样r就不会减少了。对于l的部分,我们先重置答案为r跑的答案,然后我们每次都从当前询问的l跑到当前块的最后来增加,这样子也就只有增加操作。然后就是回滚的部分了,把l增加的值删掉就行了。
每到一个不同的块r可能会变小,这时要重置r的答案然后所有r的值也用删掉。时间复杂度还是\(O(n\sqrt{n})\)
第二种情况:扩展难,删除易
这题我没写,思路纯属口胡。
此题删除一个数,看它剩余的个数是不是0,如果是则和当前最小值比较一下就行。
然后类似情况1。对于每一块我们按r从大到小排序,然后再从当前块最左端加到序列末尾,求一遍最小值(\(O(n)\))。之后r就从n开始删,l每次从左端点删到当前询问的l,然后再复原即可。
回滚莫队可以看成l和r分开来做的一种莫队,使得r单调,l每次暴力且范围较小。
带修莫队
例题:[国家集训队]数颜色
其实懂了最基础的莫队其他版本都是在其基础上稍微修改。
因为有了修改操作,我们不妨在每个询问再加上一维“已经修改了几次”,即时间维。
于是变成了三维莫队
类比普通莫队,我们先按l所在块排序,再按r所在块排序,最后按t从小到大排。
对于普通的l和r的扩展就和以前一样。
对于t的扩展如果修改在当前区间内则改掉然后重新把这个点加进去,所以我们就要记录每个修改是从什么改成什么,撤销就把它改回去就行。
时间复杂度的分析:
当块长为\(n^{\frac{2}{3}}\)次方时最优,为\(O(n^{\frac{5}{3}})\)。
至于例题的扩展部分因为太模板了就不讲了。
例题的代码(很良心了)
树上莫队
欧拉序实现路径统计
欧拉序有两种,另外一种可以用来求lca,千万别搞混了。
这种欧拉序我们在进入这棵子树时添加,出子树时再加进去得到,比如下图。
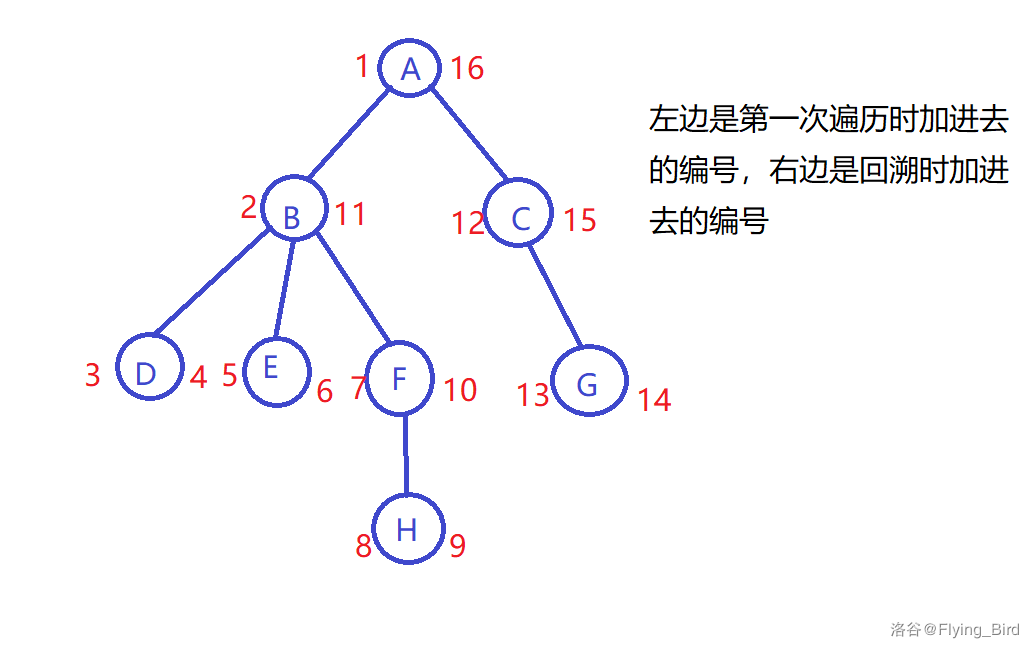
容易发现这是个2n的序列。我们得到的序列是:ABDDEEFHHFBCGGCA
然后我们便把树变成了一个序列,可以转换成序列上的查询问题。
对于每个点我们记录它第一次遍历的序号记为\(L_i\),第二次回溯的编号记为\(R_i\)。然后我们发现对于每个询问\(u,v\),若\(u\)是\(v\)的祖先,即其最近公共祖先为\(u\),那么区间\([L_u, L_v]\)中出现一次的点均为路径上的点(注意这里是出现一次的点)。为了不出现v是u的祖先这种情况,我们可以强制u的L更小,即交换了u,v。如果不是的话,我们发现路径上的点即为区间\([R_u,L_v]\)中只出现一次的点并上它们的lca。
至于怎么实现,我们可以维护一个数组来维护某个点有没有被改过,如果被改过就把改的删掉,如果没有就改。
先序实现子树统计
子树一定是一段连续的区间,然后就没了。
一个简单的询问的树上加强版,树上的子树可以分为是当前根的祖先和其它,第二种不用变,第一种与树上儿子取个补集就行。
树上带修莫队
套在一起就行了。
一些处理技巧
主要是扩展不易想到
考虑扩展的性质(这也是最难的),降低时间复杂度。实在不行就回滚(或者莫队二离
先把所有的信息统计出来,再求答案。这时可以对值域分块然后在\(O(\sqrt{n})\)的复杂度内求解。
多个区间的询问,考虑容斥拆区间拆成\([1,x],[1,y]\)的形式,本质上只有一个区间\([x,y]\)。
用bitset来帮助处理,[Ynoi2016]掉进兔子洞
一些例题
看起来可以莫队做,关键是如何扩展删除。
删除可以看做减去扩展的,所以我们只考虑扩展的。
因为左边扩展是和右边一样的所以我们只考虑右边。
我们记录每个数 \(a_i\) 前面第一个小于它的数 \(a_j\),显然 \((j,i]\) 这一部分都是 \(a_i\)。我们跳到 \(j\) 继续做刚刚的事。这是一个朴素的想法,显然一个单调上升的序列就可以把我们卡成 \(n^2\)。
我们发现这其实形成了一个树形结构。那么显然我们可以在树上做前缀和,然后倍增找到第一个。单次扩展时间复杂度稳定 \(O(\log{n})\)。可是这样子过不去这题,实测 \(0\) 分。
我们发现这个最浅节点一定是最小的节点,于是可以rmq \(O(1)\) 做,然后这题就做完了。
扫描线莫队(莫队二次离线)
前言
咕了很久想学,今天终于有时间来看了。
解决的问题
对于一般的莫队,我们一般要求单次扩展需要 \(O(1)\) 的复杂度,但是通过二次离线莫队(扫描线莫队),我们可以在 \(O(nk)\) 的时间复杂度,\(O(n)\) 的空间复杂度内预处理所有扩展,其中 \(O(k)\) 是向外扩展一次的复杂度。当然二次离线莫队还有一些别的要求,我会在之后的部分提到。
思想
考虑莫队向右扩展(其他类似)的过程,将 \((l,r)\to (l,r+1)\)。会有 \(r+1\) 对区间 \([l,r]\) 产生贡献,
Template & Practice
关于跑莫队的部分,我们把所有询问存到一个 vector 里面,分别代表(对第一种做解释) \(F(q[i].l,r)\) 到 \(F(l-1,r)\),系数是 \(1/-1\),然后对第 \(i\) 个询问做贡献。\(p\) 数组是 \(F(x,x-1)\),注意到大部分时候 \(F(x,x)=F(x,x-1)\) 所以只需预处理一种。
for(int i=1,l=1,r=0;i<=m;i++){
if(l>q[i].l)vec[r].pb(q[i].l,l-1,1,i);
while(l>q[i].l)q[i].ans-=p[--l];
if(r<q[i].r)vec[l-1].pb(r+1,q[i].r,-1,i);
while(r<q[i].r)q[i].ans+=p[++r];
if(l<q[i].l)vec[r].pb(l,q[i].l-1,-1,i);
while(l<q[i].l)q[i].ans+=p[l++];
if(r>q[i].r)vec[l-1].pb(q[i].r+1,r,1,i);
while(r>q[i].r)q[i].ans-=p[r--];
}
例 \(1\) LG4887
给定长为 \(n\) 的序列 \(a\) 和 \(m\) 组询问,查询区间 \([l,r]\) 中有多少 \(popcount(a_i\bigoplus a_j)=k\)
没有强制在线,\(1\le n,m\le 10^5,0\le a_i< 16384\)。
考虑预处理出所有 \(popcount(i)=k\) 的数 \(b\),注意到 \(a\bigoplus b=c\Leftrightarrow a=b\bigoplus c\),于是就很好处理了。
注意如果 \(F(x,y)\) 的 \(x\le y\) 且 \(k=0\) 那么 \(x\) 不能对自己做贡献,要减去 \(1\)。
例2 LG5047
给定长为 \(n\) 序列 \(a\) 和 \(m\) 次询问,每次询问一个区间的逆序对数
\(1\le n,m\le 10^5,1\le a_i\le 10^9\)
首先可以离散化,然后容易发现每次扩展只需知道一个区间里有几个数比它大(小),这显然可以拆成两部分,所以可以莫队二次离线。扫描线的时候使用根号分治,可以做到 \(O(1)\) 询问。
操作分块
操作分块主要应用在一类修改不好做的数据结构问题中。具体来讲,我们每 \(B\) 个操作分成一个组,做完这个组后进行对整体的重构。修改对询问的贡献分成两个部分,第一部分是之前的块对询问的贡献,由于已经重构,所以这个贡献是静态的。第二个部分是块内的贡献,这一部分不会超过块大小,所以可以直接暴力处理。
有些时候块内暴力也不是很容易,这个时候需要用回滚莫队的思想。
直接讲起来很抽象,不妨看几道题。
例 CF1588F Jumping Through the Array
问题很显然可以被看成是在置换环上做。但是这个置换环会变化,但每次变换的其实很少,所以考虑对操作进行分块。对于块里面的修改,我们把这些点看成关键点,而所有跟在关键点后面的点在这个块的修改里面都会和关键点同步修改查询,所以这些点其实可以缩成一个点,这样就只有 \(O(B)\) 个点了,直接暴力操作。
由于修改的最多只有 \(O(B)\) 个环,所以直接询问的时候直接枚举每个缩起来的点,查询这个点和询问区间的交集大小。code
例 APIO2019 桥梁
首先对操作分块,对于不用修改的边,建立kruscal重构树。然后每次询问的时候找到可以到的被修改的边,这个时候就扩展了可以到的点。然后继续找下去,复杂度 \(O(B\log n)\),那么总的复杂度就是 \(O(\frac{n^2\log n}{B}+nB\log n)\),取 \(B=\sqrt{n}\),得到复杂度 \(O(n\sqrt{n}\log n)\)。
我这个方法有点麻烦,其实不用显性地建出克鲁斯卡尔重构,排序之后按顺序加入并查集,再配合一个可撤销并查集即可。code
例 Ynoi2019 魔法少女网站
序列分块
数列分块入门
数列分块入门1
过于基础,直接上代码。
数列分块入门2
如果一个块是有序的那么我们显然可以二分查找,而如果一整个块同时加上某个数是不会改变相对顺序的。所以我们每次只在修改不完整的块时从新sort那个区间。查询时对于完整每个块二分,每个不完整直接暴力,如果块长为 \(\sqrt{N}\) 的话时间复杂度是:\(O(n\sqrt{N}\log{\sqrt{N}})\)。
数列分块入门3
类似数列分块2,二分找到一个最大就行。
数列分块入门4
这题恐怕是分块最最基础的操作了。
对于分块萌新我还是讲一下吧。
类似线段树的操作(希望你学过线段树),我们把区间分成很多个块,线段树是\(\log{n}\)个,我们分块就更暴力一点,直接在原数组上分\(\sqrt{n}\)个块。每个块都可以直接操作,而多余的边角料不会超过\(\sqrt{n}\)直接暴力就好。时间复杂度为\(O(n\sqrt{n})\)
数列分块入门5
开方操作不会有很多次,如果一个块内的数都是0或1这个块就不用执行开方操作,否则暴力开方。可以证明最多不超过6次。
数列分块入门6
这题我觉得块状链表可做。
块状链表就是一个链表,每个指向一个长度为\(\sqrt{n}\)级别的数组,具体结构如下图所示。
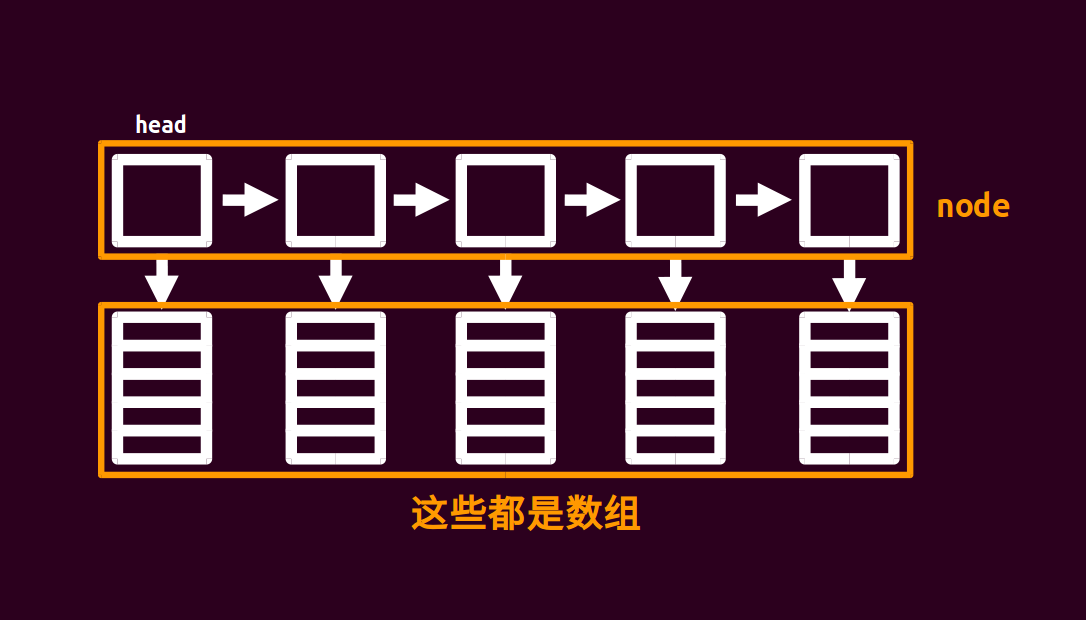
具体操作我们每个数组开\(2 \times \sqrt{n}\),要支持分裂操作,其实就是当前大小大于等于 \(2 \times \sqrt{n}\) 就新建一个node,把后面的放进去。
插入就暴力找到改在哪个位置插入,这是\(O(\sqrt{n})\)的,查询也就是暴力就行,块状链表所有操作都是\(O(\sqrt{n})\)。
此题还可用平衡树维护区间来做,用fhq-treap可以很简单地维护。
数列分块入门7
线段树经典题,看看我们能不能用类似的方法用分块做。
其实是一样的,乘法操作就一起乘就好了。
数列分块入门8
好像和第5题一样,不太会证复杂度
数列分块入门9
只会回滚莫队,哭了。
值域分块
块状链表
树分块
二维分块
杂题
References
这篇总结的实在太全了 分块指北 Dr.Zhou
还有 cmd 大佬的总结 分块相关杂谈
析合树
定义&性质
连续段
对于一个排列 \(p\) 的一个区间 \([l,r]\),如果将其中的元素拿出来重拍可以形成一个有序的序列,那么称这个区间是一个连续段。容易发现一个区间的连续段数量是 \(O(n^2)\) 级别的。
对于一个连续段有 \(\max-\min=r-l\),\(|x_i-x_j|=1\) 的 \((i,j)\) 数量也是 \(r-l\) 这种平凡性质。
连续段有一个性质,设 \(A,B\) 是两个相交且互不包含的连续段,则 \(A\cup B\),\(A \cap B\) 都是连续段。这两条性质很重要所以我们简略证明一下。
证明:
考虑反正法,设中间交的部分不是连续段,那么一定缺了一个位置,这个位置必须在左边和右边都有出现,而这又是个排列所以矛盾,得证。
然后我们容易发现中间交的部分是一段前缀或后缀,并且对于两遍相反,所以得证。
并且我们还得到了一个结论设两个相交连续分别是 \([a,b],[c,d]\),这里用值域区间来代表一个连续段,\(a<c<b<d\),那么它们的并是 \([a,d]\),交是 \([c,b]\)。
记一个排列 \(p\) 的所有连续段集合是 \(I_p\),其中 \(I\) 是 Interval 的首字母。
本原段
定义本原段是不存在和自己相交的连续段的连续段。一些平凡的性质:\([i,i]\) 是本原段,\([1,n]\),也就是整个排列是本原段。
所有本原段是不交的,我们对此很熟悉——它形成了一个树形结构。有时把树转换成数列会好做,但这时把排列转换成树可以体现更多性质。
这样所有的连续段都可以表示成若干本原段的并或者自己就是本原段。
析合树
我们把所有本原段建出一棵树,把这棵树称为析合树。树上的点分为析点和合点。
- 儿子排列
把树上的儿子离散化(区间的离散化)后所成排列。
- 合点
儿子排列是顺序或逆序的。
- 析点
其他点,包括叶节点。
对于非叶节点有如下性质:
对于一个合点,其不平凡的儿子排列的区间都构成一个连续段,对于一个析点都不构成。原因是如果存在一个极长的且不为本身的这么一个区间,那它就是一个本原段,与所有本原段构成析合树的定义不符。
这里有一点绕,我们是先有本原段然后才有析合树最后有析点和合点的定义,所以如果违背了最初的定义就不可能有这么一个结构。貌似与很多结构是逆过来的。
还有一些平凡的性质:对于非叶节点,合点至少两个孩子,而析点至少四个孩子。
注意,析点儿子排列的任意非平凡区间都不是连续段
然后容易发现所有连续段都可以由以下两种方法构成:
-
是一个树上的节点
-
是一个合点的儿子排列的非平凡区间
构造
一般都直接考虑增量。用一个栈来维护现在析合树森林的根。考虑我们现在要新加入一个点,假设这个点能成为栈顶的儿子就连边,将栈顶重新作为新加入的点。
如何判断?首先栈顶一定是个合点,否则不满足析点的定义(新加点一定是前缀或者后缀)。然后再考虑这个合点原来儿子的顺序什么的。
如果不能做儿子,那就做兄弟。考虑能否合并。如果可以就新建一个点代表合并后的点并取代原先栈顶的位置,同时弹栈作为新加入的点。这个新建的点一定是合点。
如果兄弟都做不了,那就能揽多少人就搞多少人组成一个大的连续段,然后搞一个析点父亲。复杂度进出栈各一次乍一看 \(O(n)\),可其实这是在每次都可以完成第三种合并的前提下。考虑维护一个值 \(L_r\) 代表以 \(r\) 结尾的最小的 \(l\) 使得 \([l,r]\) 是个连续段。这爱咋维护都行,就扫描线扫一遍用个线段树维护一下 \(\min,\max\) 或者 \(|x_i-x_j|=1\) 的 \((i,j)\) 个数都行。这样复杂度就是 \(O(n\log n)\)。
析合树形态计数
NEERC2018 Interval-Free Permutations
还有个名字——春天,在积雪下结一成形,抽枝发芽
但这里只考虑这个弱化版。(谁来教教拉格朗日反演)
考虑这个序列析合树的形态,必然是根为析点且有 \(n\) 个孩子(且都是叶子)。那么正难则反,考虑减去根是合点和根只有 \([4,i-1]\) 个孩子的情况。
首先考虑合点,升序降序数量相同所以不妨只考虑升序。那么只需确定第一个孩子的情况,后面爱咋排咋排,因为肯定不会形成析点了。
然后考虑枚举析点儿子个数,根据析点性质其儿子排列即为此题所求。所以只需再算一个将排列划分 \(j\) 段的方案数,可以 dp。
一些常用数据结构维护方法
请参考 数据结构。
