
实验五:全连接神经网络手写数字识别实验
实验目的】
理解神经网络原理,掌握神经网络前向推理和后向传播方法;
掌握使用pytorch框架训练和推理全连接神经网络模型的编程实现方法。
【实验内容】
1.使用pytorch框架,设计一个全连接神经网络,实现Mnist手写数字字符集的训练与识别。
【实验报告要求】
修改神经网络结构,改变层数观察层数对训练和检测时间,准确度等参数的影响;
修改神经网络的学习率,观察对训练和检测效果的影响;
修改神经网络结构,增强或减少神经元的数量,观察对训练的检测效果的影响。
import torch import torchvision from torch.utils.data import DataLoader
n_epochs = 3 batch_size_train = 64 batch_size_test = 1000 learning_rate = 0.01 momentum = 0.5 log_interval = 10 random_seed = 1 torch.manual_seed(random_seed)

train_loader = torch.utils.data.DataLoader( torchvision.datasets.MNIST('./data/', train=True, download=True, transform=torchvision.transforms.Compose([ torchvision.transforms.ToTensor(), torchvision.transforms.Normalize( (0.1307,), (0.3081,)) ])), batch_size=batch_size_train, shuffle=True) test_loader = torch.utils.data.DataLoader( torchvision.datasets.MNIST('./data/', train=False, download=True, transform=torchvision.transforms.Compose([ torchvision.transforms.ToTensor(), torchvision.transforms.Normalize( (0.1307,), (0.3081,)) ])), batch_size=batch_size_test, shuffle=True)
examples = enumerate(test_loader) batch_idx, (example_data, example_targets) = next(examples) print(example_targets) print(example_data.shape)
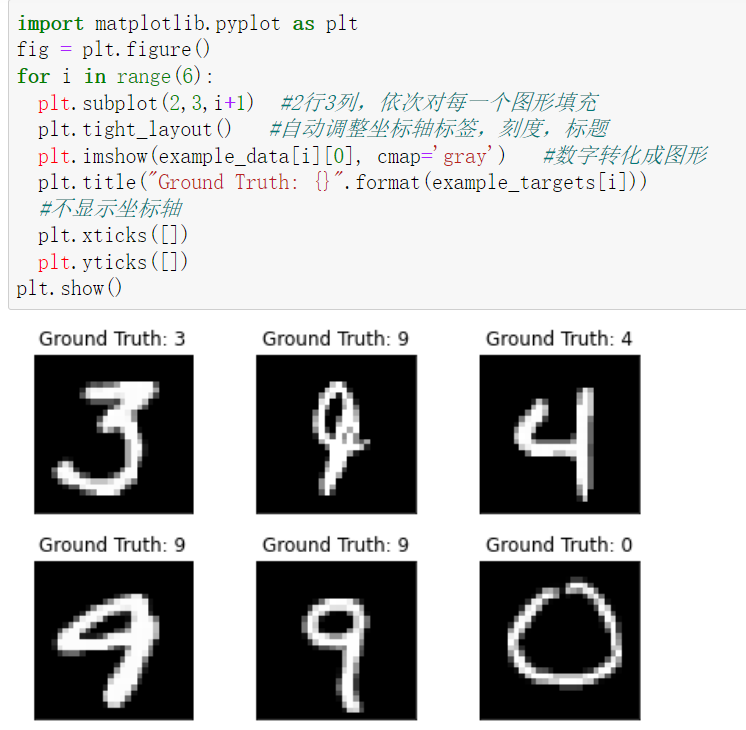
import matplotlib.pyplot as plt fig = plt.figure() for i in range(6): plt.subplot(2,3,i+1) #2行3列,依次对每一个图形填充 plt.tight_layout() #自动调整坐标轴标签,刻度,标题 plt.imshow(example_data[i][0], cmap='gray') #数字转化成图形 plt.title("Ground Truth: {}".format(example_targets[i])) #不显示坐标轴 plt.xticks([]) plt.yticks([]) plt.show()
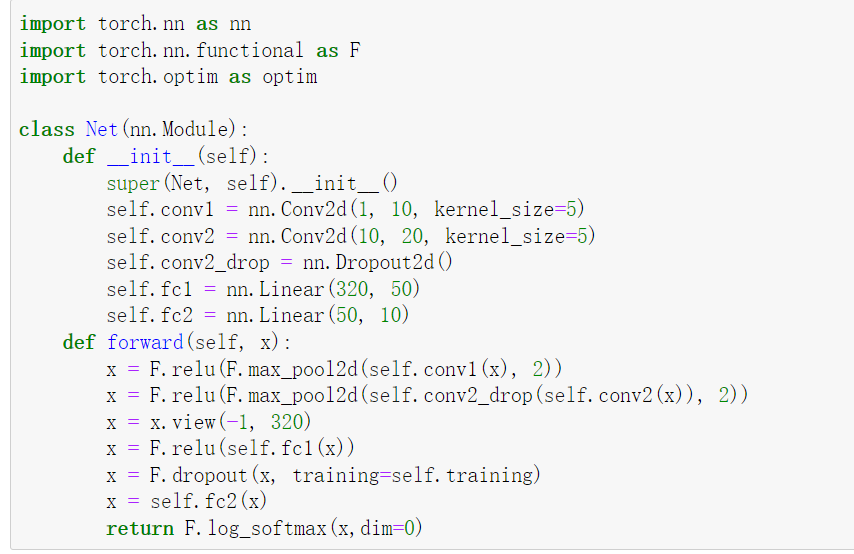
import torch.nn as nn import torch.nn.functional as F import torch.optim as optim class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 10, kernel_size=5) self.conv2 = nn.Conv2d(10, 20, kernel_size=5) self.conv2_drop = nn.Dropout2d() self.fc1 = nn.Linear(320, 50) self.fc2 = nn.Linear(50, 10) def forward(self, x): x = F.relu(F.max_pool2d(self.conv1(x), 2)) x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2)) x = x.view(-1, 320) x = F.relu(self.fc1(x)) x = F.dropout(x, training=self.training) x = self.fc2(x) return F.log_softmax(x,dim=0)
network = Net() optimizer = optim.SGD(network.parameters(), lr=learning_rate, momentum=momentum)
train_losses = [] train_counter = [] test_losses = [] test_counter = [i*len(train_loader.dataset) for i in range(n_epochs + 1)]
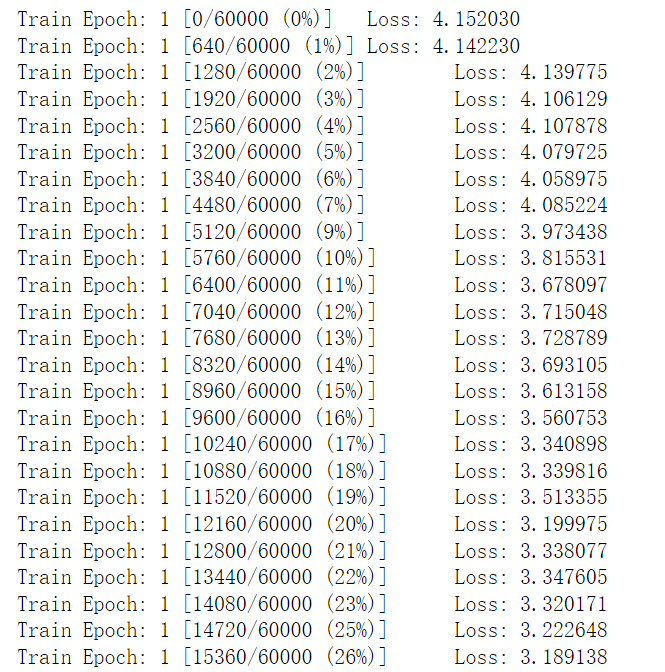
def train(epoch): network.train() for batch_idx, (data, target) in enumerate(train_loader): optimizer.zero_grad() output = network(data) loss = F.nll_loss(output, target) loss.backward() optimizer.step() if batch_idx % log_interval == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) train_losses.append(loss.item()) train_counter.append( (batch_idx*64) + ((epoch-1)*len(train_loader.dataset))) torch.save(network.state_dict(), './model.pth') torch.save(optimizer.state_dict(), './optimizer.pth') train(1)
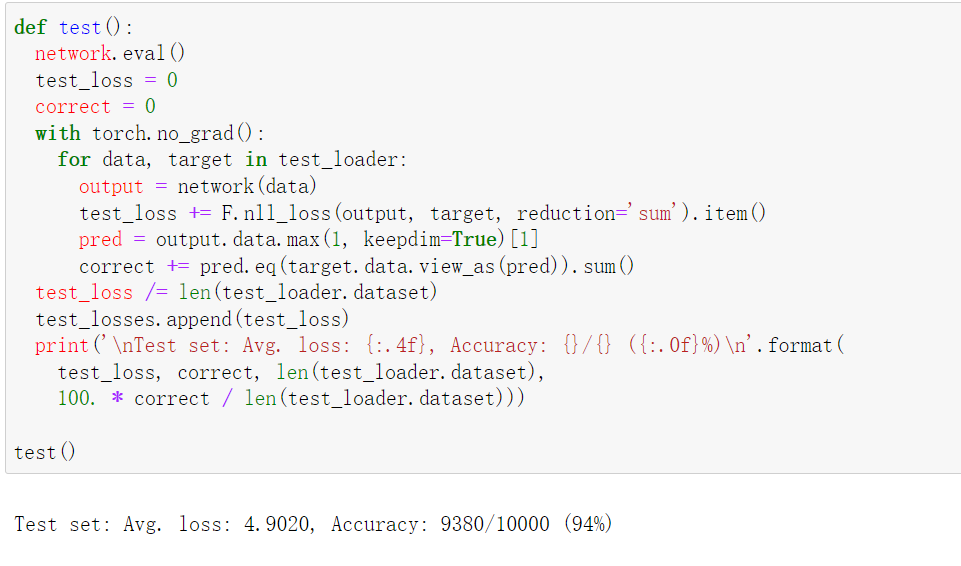
def test(): network.eval() test_loss = 0 correct = 0 with torch.no_grad(): for data, target in test_loader: output = network(data) test_loss += F.nll_loss(output, target, reduction='sum').item() pred = output.data.max(1, keepdim=True)[1] correct += pred.eq(target.data.view_as(pred)).sum() test_loss /= len(test_loader.dataset) test_losses.append(test_loss) print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset))) test()


修改神经网络的学习率,观察对训练和检测效果的影响;
学习率设置太大会造成网络不能收敛,在最优值附近徘徊,也就是说直接跳过最低的地方跳到对称轴另一边,从而忽视了找到最优值的位置,学习率设置太小,网络收敛非常缓慢,会增大找到最优值的时间,也就是说从山坡上像蜗牛一样慢慢地爬下去。虽然设置非常小的学习率是可以到达,但是这很可能会进入局部极值点就收敛,没有真正找到的最优解。
修改神经网络结构,增强或减少神经元的数量,观察对训练的检测效果的影响。
一般条件下,在调参合理的情况下,层数和神经元数越多,正确率越高,但随之对应的是,容易出现过拟合


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律