Kubernetes部署集群Mysql服务----【Mysql主从复制+读写分离】
前言:
微服务技术是现在非常流行的一种技术,许许多多的大公司采用微服务架构,这样可以对它们的业务随时进行拓展或者缩减服务量。
具体的微服务架构了解可以自己百度了解,本文记录的主要是使用Kubernetes对Mysql集群服务进行搭建。
Mysql集群服务描述:
1.搭建一个主从复制的Mysql集群
2.一个主节点“Master” 多个从节点“Slave”
3.所有的写操作,只能在主节点上执行;
4.读操作可以在所有节点上执行
5.从节点需要能水平扩展; (注:本文的存储券pv采用的nfs服务,如果想对节点进行拓展需要添加PV券。)(这点后续待完善)
图形描述:
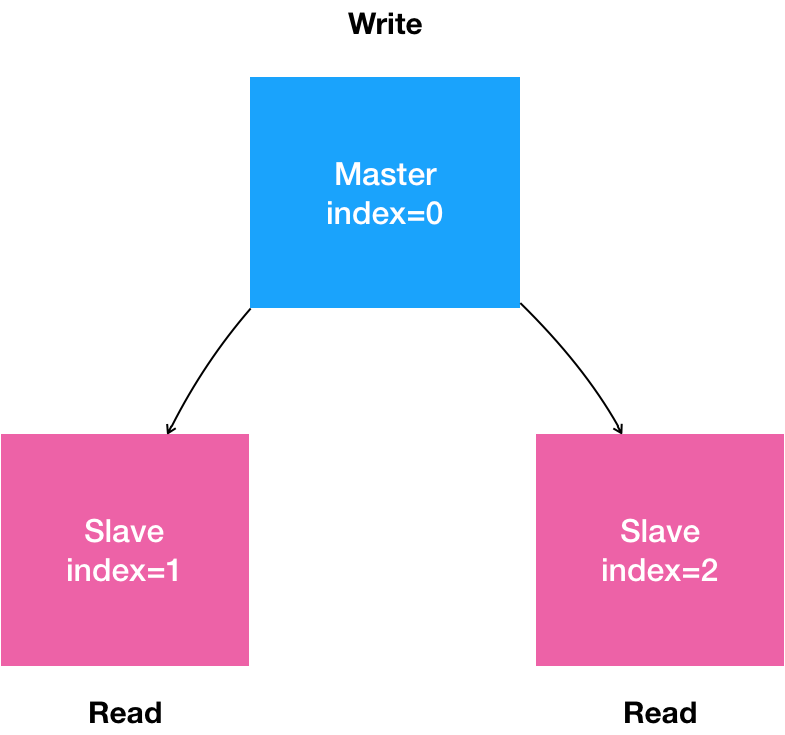
分析情况:
首先我们部署的Mysql服务是主从复制+读写分离的,那么在主从的节点上肯定就是有区别的,所以我们在部署Pod的时候需要将它们区分开。
在搭建这套服务的时候有三个需要重点问题:
第1个问题: 区分开Master和Slave节点的配置文件
第2个问题:在Slave节点开始运行的时候需要克隆前一个节点的数据(这里采用的是StatefulSet进行部署,所以是有序的,节点2克隆节点1,节点1克隆节点0以此类推)
第3个问题:在设置好配置文件和同步好数据之后,就需要在 Slave 节点第一次启动之前,需要执行一些初始化 SQL 操作(绑定上Master节点开始主从复制)
代码实现:
目录:
1.拉取所需镜像(pull-google.com.sh)
2.配置数据持久化(PersistentVolume)
3.配置Master和Slave节点所需的不同配置信息(ConfigMap)
4.创建Mysql对外服务(Service)
5.定义Mysql容器(StatefulSet)
1.拉取所需镜像:
下面是拉取gcr.io镜像源脚本并拉取镜像
[root@k8s-m~ ]# cat /usr/local/bin/pull-google.com.sh
image=$1
echo $1
img=`echo $image | sed 's/k8s\.gcr\.io/anjia0532\/google-containers/g;s/gcr\.io/anjia0532/g;s/\//\./g;s/ /\n/g;s/_/-/g;s/anjia0532\./anjia0532\//g' | uniq | awk '{print ""$1""}'`
echo "docker pull $img"
docker pull $img
echo "docker tag $img $image"
docker tag $img $image
[root@k8s-m~ ]# chmod +x /usr/local/bin/pull-google.com.sh
[root@k8s-m~ ]# pull-google.com.sh gcr.io/google-samples/xtrabackup:1.0
2.我使用的是NFS服务进行资源存储。我直接将NFS服务器装在了Master主节点上,如果有条件的也可以专门制作一台NFS服务器。
由于我们搭建的是Mysql服务集群,所以就涉及到了数据持久化。那么这里准备了三个持久化硬盘提供给一个Master和两个Slave节点使用。
# 在master上安装nfs服务
[root@master ~]# yum install nfs-utils -y
在配置好NFS服务器之后,接下来就是配置好PV存储券:
这里我配置了三个存储券:然后都是存在kerry命名空间下的
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-a
namespace: kerry
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
- ReadOnlyMany
#persistentVolumeReclaimPolicy: Retain
persistentVolumeReclaimPolicy: Recycle
nfs:
server: 192.168.29.200
path: /net/mysql-0
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-b
namespace: kerry
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
- ReadOnlyMany
#persistentVolumeReclaimPolicy: Retain
persistentVolumeReclaimPolicy: Recycle
nfs:
server: 192.168.29.200
path: /net/mysql-1
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-c
namespace: kerry
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
- ReadOnlyMany
#persistentVolumeReclaimPolicy: Retain
persistentVolumeReclaimPolicy: Recycle
nfs:
server: 192.168.29.200
path: /net/mysql-2
3.创建configMap配置字典(以为有主从复制和读写分离的区分,所以在配置信息上也有所不同)
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
namespace: kerry
labels:
app: mysql
data:
master.cnf: |
# 主节点Mysql的配置文件
#master.cnf开启了log-bin,即:使用二进制文件的方式进行主从复制,这是一个标准的设置
[mysqld]
log-bin
slave.cnf: |
# 从节点Mysql的配置文件
#slave.cnf开启了super-read-only,代表的是从节点会拒绝除了主节点的数据同步操作之外的所以写操作
# 即:它对用户是只读的
[mysqld]
super-read-only
4.创建Mysql对外服务(这里配置了三个SVC)
4.1这个Service负责统一管理所有的Mysql服务Pod
apiVersion: v1
kind: Service
metadata:
name: mysql-headless
namespace: kerry
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
clusterIP: None
selector:
app: mysql
4.2这个Service负责统一管理拥有读权限的Pod
apiVersion: v1
kind: Service
metadata:
name: mysql-read
namespace: kerry
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
targetPort: 3306
nodePort: 30036
type: NodePort
selector:
app: mysql
4.3这个Service负责统一管理拥有读写权限的Pod,也就是Master节点pod
apiVersion: v1
kind: Service
metadata:
name: mysql-readwrite
namespace: kerry
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
targetPort: 3306
nodePort: 30006
selector:
statefulset.kubernetes.io/pod-name: mysql-ss-0
type: NodePort
5.定义Mysql容器(配置StatefulSet)(最重要的一步,)
在配置Pod模板呢,首先涉及到了四个模块
InitContainers:
1.初始化Mysql配置文件(为Master和slave节点配置上对应的配置信息 (.cnf) )
2.克隆Mysql数据(为当前节点配置上一个节点的数据) 【0-Master节点不需要,1-Slave节点配置0-Master的,2-Slave节点配置1-Slave节点的,以此类推】
Containers:
3.Mysql数据库(配置上存活探针等等...)
4.初始化SQL操作(在Slave节点第一次启动之前,需要执行初始化SQL操作,使之绑定上Master节点主从同步)
大致的框架
在开始码代码之前,我们要先为 StatefulSet 对象规划出大致的框架,如下图所示:
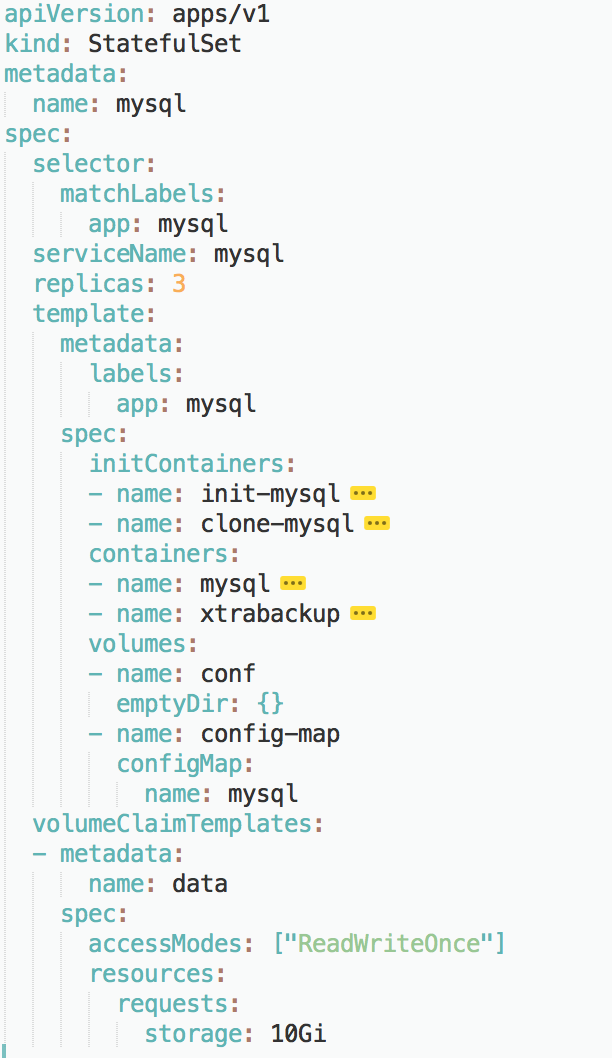
具体实现代码:
下面所用到的两个镜像:Mysql,xtrabackup,都是从私人仓库(Harbor)中拉取的。
如果想跟本文一样使用私人仓库进行部署镜像可学习此文章:Harbor私人仓库的安装与应用
如果想从公共仓库拉取,可替换为:
image: mysql:5.7
image: gcr.io/google-samples/xtrabackup:1.0 《==这个镜像是来自国外仓库,如果访问不到的话用上面1模块进行拉取所需镜像
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql-ss
namespace: kerry
spec:
selector:
matchLabels:
app: mysql
serviceName: mysql-headless
replicas: 3
template:
metadata:
namespace: kerry
labels:
app: mysql
spec:
initContainers:
- name: init-mysql
image: 192.168.29.197/kerry/mysql:5.7
command:
- bash
- "-c"
- |
set ex
# 从hostname中获取索引,比如(mysql-1)会获取(1)
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
echo [mysqld] > /mnt/conf.d/server-id.cnf
# 为了不让server-id相同而增加偏移量
echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf
# 拷贝对应的文件到/mnt/conf.d/文件夹中
if [[ $ordinal -eq 0 ]]; then
cp /mnt/config-map/master.cnf /mnt/conf.d/
else
cp /mnt/config-map/slave.cnf /mnt/conf.d/
fi
volumeMounts:
- name: conf
mountPath: /mnt/conf.d
- name: config-map
mountPath: /mnt/config-map
- name: clone-mysql
image: 192.168.29.197/kerry/xtrabackup:latest
command:
- bash
- "-c"
- |
set -ex
# 整体意思:
# 1.如果是主mysql中的xtrabackup,就不需要克隆自己了,直接退出
# 2.如果是从mysql中的xtrabackup,先判断是否是第一次创建,因为第二次重启本地就有数据库,无需克隆。若是第一次创建(通过/var/lib/mysql/mysql文件是否存在判断),就需要克隆数据库到本地。
# 如果有数据不必克隆数据,直接退出()
[[ -d /var/lib/mysql/mysql ]] && exit 0
# 如果是master数据也不必克隆
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
[[ $ordinal -eq 0 ]] && exit 0
# 从序列号比自己小一的数据库克隆数据,比如mysql-2会从mysql-1处克隆数据
ncat --recv-only mysql-ss-$(($ordinal-1)).mysql-headless 3307 | xbstream -x -C /var/lib/mysql
# 比较数据
xtrabackup --prepare --target-dir=/var/lib/mysql
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
containers:
- name: mysql
image: 192.168.29.197/kerry/mysql:5.7
env:
- name: MYSQL_ALLOW_EMPTY_PASSWORD
value: "1"
ports:
- name: mysql
containerPort: 3306
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
resources:
requests:
cpu: 50m
memory: 50Mi
livenessProbe:
exec:
command: ["mysqladmin", "ping"]
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
readinessProbe:
exec:
command: ["mysql", "-h", "127.0.0.1", "-e", "SELECT 1"]
initialDelaySeconds: 5
periodSeconds: 2
timeoutSeconds: 1
- name: xtrabackup
image: 192.168.29.197/kerry/xtrabackup:latest
ports:
- name: xtrabackup
containerPort: 3307
command:
- bash
- "-c"
- |
set -ex
# 确定binlog 克隆数据位置(如果binlog存在的话).
cd /var/lib/mysql
# 如果存在该文件,则该xrabackup是从现有的从节点克隆出来的。
if [[ -s xtrabackup_slave_info ]]; then
mv xtrabackup_slave_info change_master_to.sql.in
rm -f xtrabackup_binlog_info
elif [[ -f xtrabackup_binlog_info ]]; then
[[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1
rm xtrabackup_binlog_info
echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\
MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.in
fi
if [[ -f change_master_to.sql.in ]]; then
echo "Waiting for mysqld to be ready (accepting connections)"
until mysql -h 127.0.0.1 -e "SELECT 1"; do sleep 1; done
echo "Initializing replication from clone position"
mv change_master_to.sql.in change_master_to.sql.orig
mysql -h 127.0.0.1 <<EOF
$(<change_master_to.sql.orig),
MASTER_HOST='mysql-ss-0.mysql-headless',
MASTER_USER='root',
MASTER_PASSWORD='',
MASTER_CONNECT_RETRY=10;
START SLAVE;
EOF
fi
exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \
"xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root"
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
resources:
requests:
cpu: 10m
memory: 10Mi
volumes:
- name: conf
emptyDir: {}
- name: config-map
configMap:
name: mysql
imagePullSecrets:
- name: docker-secret
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 0.1Gi
总结:
0自此Mysql集群服务就已经部署完了,当前唯一的一个问题就是由于我们的PV是NFS服务提供的,PV都是已经写死的,如果说我们要增加Mysql会出现没有多的PV提供使用,但是减少Mysql功能还是有的
也.就是说,我们只有3个pv提供使用,Mysql节点顶天也就3个,如果还要多的话就得添加多PV提供Pod绑定了。
参考文档:https://www.cnblogs.com/luoahong/p/12857783.html 《== 这个博客为详解版,对于其中各个部分分析透彻
参考文档:https://blog.csdn.net/qq_38900565/article/details/102486100 《== 这边博客为实用版,直接照搬代码就可以跑起来Demo,方便实践理解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号