
数据采集第三次实践
数据采集与技术融合作业 3
102220122-张诚坤
gitee链接:https://gitee.com/zhang-chengkun666/data-collection-and-fusion/issues/IBBX6P
作业①
要求
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用 scrapy 框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数 2 位)、总下载的图片数量(尾数后 3 位)等限制爬取的措施。
核心代码
- weather_spider.py:
import scrapy
from scrapy import Request
from scrapy.crawler import CrawlerProcess
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
import sys
sys.path.append('D:\\张诚坤aaa老母猪批发\\weather_images')
from weather_images.pipelines import WeatherImagesPipeline
class WeatherSpider(scrapy.Spider):
name = 'weather_spider'
allowed_domains = ['weather.com.cn']
start_urls = ['http://weather.com.cn/']
def parse(self, response):
# 解析页面并提取图片 URL
# 假设图片在 img 标签中
images = response.css('img::attr(src)').getall()
for image_url in images:
if image_url.startswith('http'):
yield Request(image_url, callback=self.save_image)
def save_image(self, response):
# 保存图片到本地
image_guid = response.url.split('/')[-1]
yield {
'image_urls': [response.url],
'image_name': image_guid
}
class WeatherImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths
return item
# 配置 Scrapy 设置
process = CrawlerProcess(settings={
'ITEM_PIPELINES': {'weather_images.pipelines.WeatherImagesPipeline': 1},
'IMAGES_STORE': 'D:\\张诚坤aaa老母猪批发\\images',
'CONCURRENT_REQUESTS': 22, # 控制并发请求数量
'DOWNLOAD_DELAY': 1, # 控制下载延迟
'CLOSESPIDER_ITEMCOUNT': 122, # 控制下载的图片数量
'CLOSESPIDER_PAGECOUNT': 22, # 控制总页数
})
# 启动爬虫
process.crawl(WeatherSpider)
process.start()
- pipelines.py:
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
class WeatherImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths
return item
- settings.py:
BOT_NAME = 'weather_images'
SPIDER_MODULES = ['weather_images.spiders']
NEWSPIDER_MODULE = 'weather_images.spiders'
# 管道设置
ITEM_PIPELINES = {
'weather_images.pipelines.WeatherImagesPipeline': 1,
}
# 图片存储路径
IMAGES_STORE = 'D:\\张诚坤aaa老母猪批发\\images'
# 多线程
CONCURRENT_REQUESTS = 32
# 单线程
# CONCURRENT_REQUESTS = 1
DOWNLOAD_DELAY = 1
CLOSESPIDER_ITEMCOUNT = 122
CLOSESPIDER_PAGECOUNT = 22
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = "weather_images (+http://www.yourdomain.com)"
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
实验结果
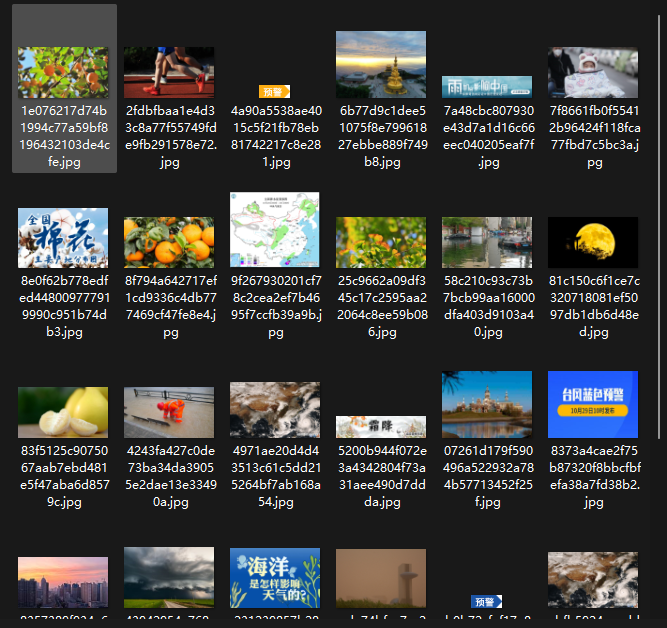
实验心得
在编写这个天气图片爬虫的过程中,我深刻体会到 Scrapy 框架的强大与灵活性。它不仅简化了网页数据抓取和图片下载的过程,还通过异步处理机制提高了效率。通过使用 Scrapy 的 ImagesPipeline,我能够轻松地提取图片 URL 并下载存储图片,同时通过配置并发请求数量和下载延迟,有效控制了爬虫对目标网站的压力。此外,Scrapy 的中间件和管道机制使得数据处理和存储变得非常灵活,进一步提升了爬虫的可扩展性和可维护性。
作业②
要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用 scrapy 框架 + Xpath + MySQL 数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
主要代码
- stocks.py:
import scrapy
import json
from scrapy.exceptions import CloseSpider
from stock_scraper.items import StockScraperItem
class StockSpider(scrapy.Spider):
name = 'stocks'
allowed_domains = ['eastmoney.com']
start_urls = [
'https://push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409840494931556277_1633338445629&pn=1&pz=10&po=1&np=1&fltt=2&invt=2&fid=f3&fs=b:MK0021&fields=f12,f14,f2,f3,f4,f5,f6,f7,f8,f9,f10,f11,f18,f15,f16,f17,f23'
]
def parse(self, response):
try:
# 解析 JSON 数据
json_response = response.json()
data = json_response.get('data', {})
stock_diff = data.get('diff', [])
if not stock_diff:
self.logger.warning("No stock data found in the response.")
return
# 遍历股票数据
for stock in stock_diff:
item = StockScraperItem()
item['stock_code'] = stock.get('f12', 'N/A')
item['stock_name'] = stock.get('f14', 'N/A')
item['latest_price'] = self._parse_float(stock, 'f2', 0.0)
item['change_percent'] = self._parse_float(stock, 'f3', 0.0)
item['change_amount'] = self._parse_float(stock, 'f4', 0.0)
item['volume'] = stock.get('f5', '0')
item['turnover'] = stock.get('f6', '0')
item['amplitude'] = self._parse_float(stock, 'f7', 0.0)
item['high'] = self._parse_float(stock, 'f15', 0.0)
item['low'] = self._parse_float(stock, 'f16', 0.0)
item['open_price'] = self._parse_float(stock, 'f17', 0.0)
item['yesterday_close'] = self._parse_float(stock, 'f18', 0.0)
yield item
except json.JSONDecodeError as e:
self.logger.error(f"Failed to parse JSON: {e}")
raise CloseSpider("Invalid JSON response")
except Exception as e:
self.logger.error(f"An error occurred: {e}")
raise CloseSpider("An unexpected error occurred")
def _parse_float(self, stock_data, key, default=0.0):
value = stock_data.get(key)
if value is None:
return default
try:
return float(value)
except (ValueError, TypeError):
self.logger.warning(f"Invalid value for key '{key}': {value}")
return default
- pipelines:
import mysql.connector
from scrapy.exceptions import DropItem
import pymysql
class MySQLPipeline:
def open_spider(self, spider):
# 读取数据库设置
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd="192837465", db="stocks",
charset="utf8") #############
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.opened = True
self.count = 0
# 创建存储股票数据的表
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS stock (
stock_code VARCHAR(20),
stock_name VARCHAR(255),
latest_price FLOAT,
change_percent FLOAT,
change_amount FLOAT,
volume VARCHAR(20),
turnover VARCHAR(20),
amplitude FLOAT,
high FLOAT,
low FLOAT,
open_price FLOAT,
yesterday_close FLOAT,
PRIMARY KEY(stock_code)
)
''')
self.con.commit()
def close_spider(self, spider):
# 关闭数据库连接
self.cursor.close()
self.con.close()
def process_item(self, item, spider):
# 插入数据到表中
try:
self.cursor.execute('''
REPLACE INTO stock (stock_code, stock_name, latest_price, change_percent, change_amount, volume,
turnover, amplitude, high, low, open_price, yesterday_close)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
''', (
item['stock_code'], item['stock_name'], item['latest_price'], item['change_percent'],
item['change_amount'], item['volume'], item['turnover'], item['amplitude'], item['high'],
item['low'], item['open_price'], item['yesterday_close']
))
self.con.commit()
except mysql.connector.Error as e:
spider.logger.error(f"Error saving item to MySQL: {e}")
raise DropItem(f"Error saving item: {e}")
return item
- settings:
# Scrapy settings for stock_scraper project
BOT_NAME = 'stock_scraper'
SPIDER_MODULES = ['stock_scraper.spiders']
NEWSPIDER_MODULE = 'stock_scraper.spiders'
# 配置管道
ITEM_PIPELINES = {
'stock_scraper.pipelines.MySQLPipeline': 300,
}
# 数据库配置
MYSQL_HOST = 'localhost' # 数据库主机
MYSQL_DATABASE = 'stock' # 数据库名
MYSQL_USER = 'root' # 数据库用户
MYSQL_PASSWORD = '789789789' # 数据库密码
# 用户代理
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0'
# 其他设置
REDIRECT_ENABLED = False
LOG_LEVEL = 'DEBUG'
# 配置最大并发请求数
CONCURRENT_REQUESTS = 16
CONCURRENT_REQUESTS_PER_DOMAIN = 8
# 设置下载延迟,避免过于频繁的请求
DOWNLOAD_DELAY = 1 # 每个请求之间延迟 1 秒
# 启用和配置 AutoThrottle 扩展
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_START_DELAY = 5 # 初始下载延迟
AUTOTHROTTLE_MAX_DELAY = 60 # 高延迟情况下的最大下载延迟
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Scrapy 每个远程服务器并行发送的平均请求数
- items.py:
import scrapy
class StockScraperItem(scrapy.Item):
stock_code = scrapy.Field()
stock_name = scrapy.Field()
latest_price = scrapy.Field()
change_percent = scrapy.Field()
change_amount = scrapy.Field()
volume = scrapy.Field()
turnover = scrapy.Field()
amplitude = scrapy.Field()
high = scrapy.Field()
low = scrapy.Field()
open_price = scrapy.Field()
yesterday_close = scrapy.Field()
实验结果
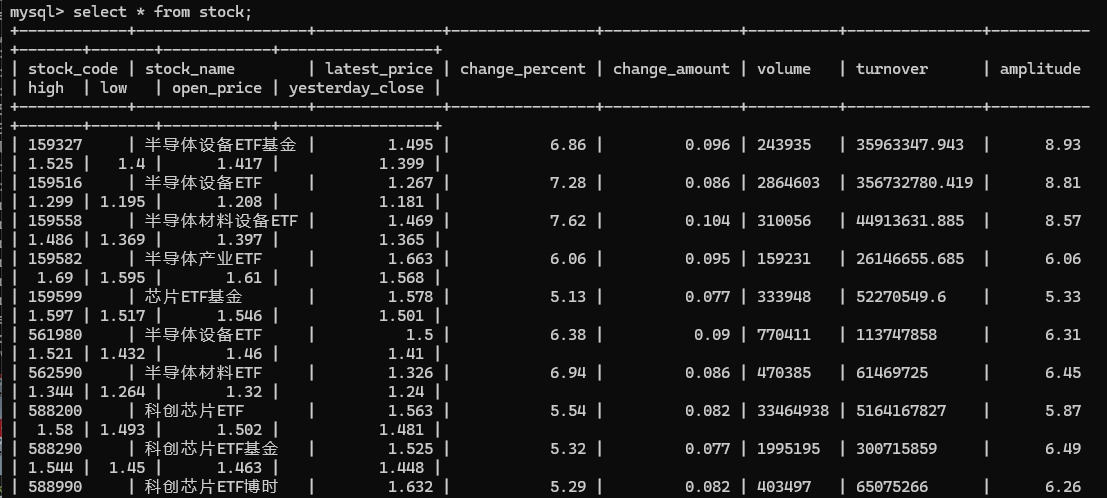
实验心得
在开发这个股票数据爬虫的过程中,我深入掌握了 Scrapy 框架的 JSON 解析、数据提取和错误处理机制,并通过自定义管道将数据高效地存储到 MySQL 数据库中。爬虫通过异步请求和错误处理机制,确保了数据的完整性和爬虫的稳定性。同时,使用 pymysql 库连接数据库并执行批量插入操作,显著提升了数据存储的效率。这次实践让我对 Scrapy 框架的灵活性和数据库操作有了更深入的理解,并为未来处理更复杂的爬虫任务打下了坚实的基础。
作业③
要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用 scrapy 框架 + Xpath + MySQL 数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
主要代码
- boc_spider.py:
import scrapy
from boc_spider.boc_spider.items import BocExchangeRateItem
from bs4 import BeautifulSoup
class ExchangeRateSpider(scrapy.Spider):
name = "boc_spider"
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
try:
soup = BeautifulSoup(response.body, 'lxml')
table = soup.find_all('table')[1]
rows = table.find_all('tr')
rows.pop(0) # 移除表头
for row in rows:
item = BocExchangeRateItem()
columns = row.find_all('td')
item['currency'] = columns[0].text.strip()
item['cash_buy'] = columns[1].text.strip()
item['cash_sell'] = columns[2].text.strip()
item['spot_buy'] = columns[3].text.strip()
item['spot_sell'] = columns[4].text.strip()
item['exchange_rate'] = columns[5].text.strip()
item['publish_date'] = columns[6].text.strip()
item['publish_time'] = columns[7].text.strip()
yield item
except Exception as err:
self.logger.error(f"An error occurred: {err}")
- pipelines:
import pymysql
from scrapy.exceptions import DropItem
class BocExchangeRatePipeline(object):
def __init__(self, mysql_host, mysql_db, mysql_user, mysql_password, mysql_port):
self.mysql_host = mysql_host
self.mysql_db = mysql_db
self.mysql_user = mysql_user
self.mysql_password = mysql_password
self.mysql_port = mysql_port
@classmethod
def from_crawler(cls, crawler):
return cls(
mysql_host=crawler.settings.get('MYSQL_HOST'),
mysql_db=crawler.settings.get('MYSQL_DB'),
mysql_user=crawler.settings.get('MYSQL_USER'),
mysql_password=crawler.settings.get('MYSQL_PASSWORD'),
mysql_port=crawler.settings.get('MYSQL_PORT'),
)
def open_spider(self, spider):
self.connection = pymysql.connect(
host=self.mysql_host,
user=self.mysql_user,
password=self.mysql_password,
db=self.mysql_db,
port=self.mysql_port,
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
def close_spider(self, spider):
self.connection.close()
def process_item(self, item, spider):
with self.connection.cursor() as cursor:
sql = """
INSERT INTO exchange_rates (currency, cash_buy, cash_s```python
ell, spot_buy, spot_sell, exchange_rate, publish_date, publish_time)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
"""
cursor.execute(sql, (
item['currency'],
item['cash_buy'],
item['cash_sell'],
item['spot_buy'],
item['spot_sell'],
item['exchange_rate'],
item['publish_date'],
item['publish_time']
))
self.connection.commit()
return item
- settings:
BOT_NAME = "boc_spider"
SPIDER_MODULES = ["boc_spider.spiders"]
NEWSPIDER_MODULE = "boc_spider.spiders"
MYSQL_HOST = 'localhost'
MYSQL_DB = 'boc_db'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '789789789'
MYSQL_PORT = 3306
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
ITEM_PIPELINES = {
'boc_spider.pipelines.BocExchangeRatePipeline': 300,
}
ROBOTSTXT_OBEY = True
- items.py:
import scrapy
class BocExchangeRateItem(scrapy.Item):
currency = scrapy.Field()
cash_buy = scrapy.Field()
cash_sell = scrapy.Field()
spot_buy = scrapy.Field()
spot_sell = scrapy.Field()
exchange_rate = scrapy.Field()
publish_date = scrapy.Field()
publish_time = scrapy.Field()
实验结果
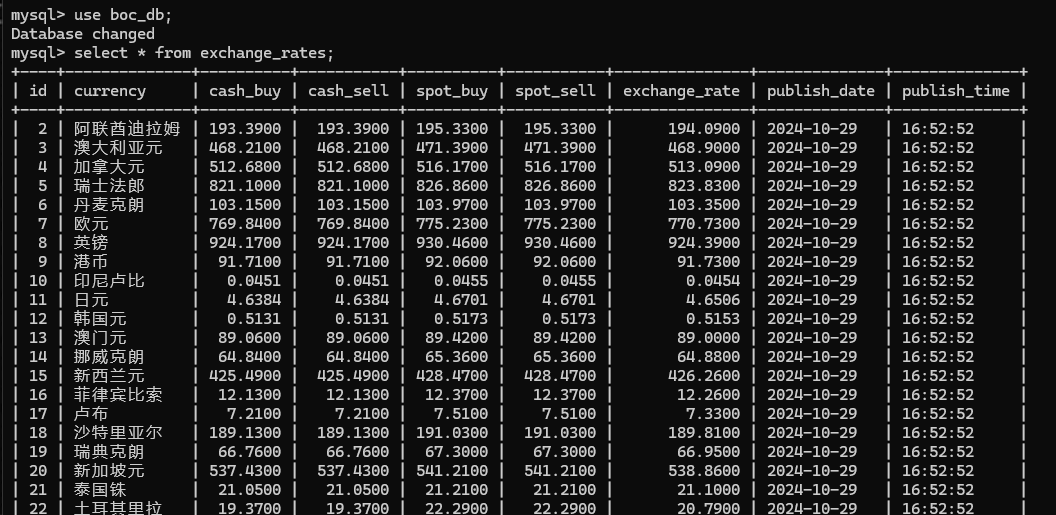
实验心得
在开发这个中国银行外汇牌价爬虫的过程中,我熟练运用了 Scrapy 框架和 BeautifulSoup 进行网页解析和数据提取,并通过自定义管道将抓取到的汇率数据高效存储到 MySQL 数据库中。爬虫通过解析多层嵌套的 HTML 表格结构,成功提取了多种货币的现汇和现钞买入卖出价,并记录了汇率的发布日期和发布时间。数据管道部分,我通过 pymysql 库实现了与 MySQL 数据库的连接和数据插入操作,确保了数据的完整性和一致性。这次实践让我对 Scrapy 框架的灵活性和数据库操作有了更深入的理解,并为未来处理更复杂的网页数据抓取任务积累了宝贵经验。


