


机器学习中常用的损失函数的整理
机器通过损失函数进行学习。这是一种评估特定算法对给定的数据 建模程度的方法。如果预测值与真实值之前偏离较远,那么损失函数便会得到一个比较大的值。在一些优化函数的辅助下,损失函数逐渐学会减少预测值与真实值之间的这种误差。
机器学习中的所有算法都依赖于最小化或最大化某一个函数,我们称之为“目标函数”。最小化的这组函数被称为“损失函数”。损失函数是衡量预测模型预测结果表现的指标。寻找函数最小值最常用的方法是“梯度下降”。把损失函数想象成起伏的山脉,梯度下降就好比从山顶滑下,寻找山脉的最低点(目的)。
在实际应用中,并没有一个通用的,对所有的机器学习算法都表现的很不错的损失函数(或者说没有一个损失函数可以适用于所有类型的数据)。针对特定问题选择某种损失函数需要考虑到到许多因素,包括是否有离群点,机器学习算法的选择,运行梯度下降的时间效率,是否易于找到函数的导数,以及预测结果的置信度等。
从学习任务的类型出发,可以从广义上将损失函数分为两大类——分类损失(Classification Loss)和回归损失(Regression Loss)。在分类任务中,我们要从类别值有限的数据集中预测输出,比如给定一个手写数字图像的大数据集,将其分为 0~9 中的一个。而回归问题处理的则是连续值的预测问题,例如给定房屋面积、房间数量,去预测房屋价格。


回归损失
1. 均方误差(Mean Square Error), 二次损失(Quadratic Loss), L2 损失(L2 Loss)
均方误差(MSE)是最常用的回归损失函数。其数学公式如:
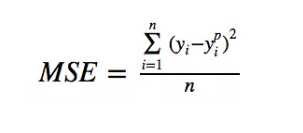
均方误差(MSE)度量的是预测值和实际观测值之间差的平方和求平局。它只考虑误差的平均大小,不考虑其方向。但由于经过平方,与真实值偏离较多的预测值会比偏离较少的预测值受到更为严重的惩罚。再加上 MSE 的数学特性很好,这使得计算梯度变得更容易。
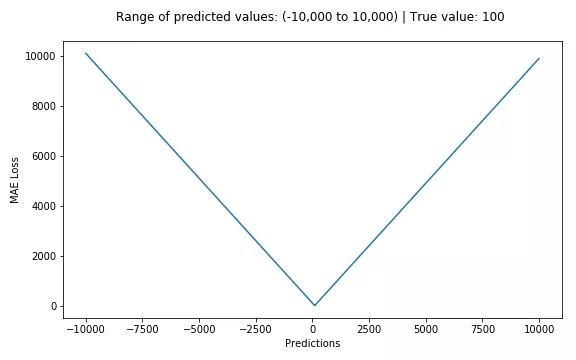
下面是一个MSE函数的图,其中真实目标值为 100,预测值在 -10,000 至 10,000之间。预测值(X轴)= 100 时,MSE 损失(Y轴)达到其最小值。损失范围为 0 至 ∞。

import numpy as np
y_true = np.array([0.000, 0.166, 0.333])
y_pre = np.array([0.000, 0.255, 0.986])
def rmse(predictions, targets):
differents = predictions - targets
differents_square = differents ** 2
mean_of_differents_square = differents_square.mean()
rmse_val = np.sqrt(mean_of_differents_square) # 计算平方根
return rmse_val
print("d is:" + str(["%.6f" % i for i in y_true])) # d is:['0.000000', '0.166000', '0.333000']
print("p is:" + str(["%.6f" % j for j in y_pre])) # p is:['0.000000', '0.255000', '0.986000']
rmse_val = rmse(y_pre, y_true)
print("rmse is " + str(rmse_val)) # rmse is 0.38049529125426335
print("rmse is %.6s" % rmse_val ) # rmse is 0.3804
2. 平均绝对误差(Mean Absolute Error), L1损失(L1 Loss)
平均绝对误差(MAE)是另一种用于回归模型的损失函数。和 MSE 一样,这种度量方法也是在不考虑方向(如果考虑方向,那将被称为平均偏差(Mean Bias Error, MBE),它是残差或误差之和)的情况下衡量误差大小。但和 MSE 的不同之处在于,MAE 需要像线性规划这样更复杂的工具来计算梯度。此外,MAE 对异常值更加稳健,因为它不使用平方。损失范围也是 0 到 ∞。
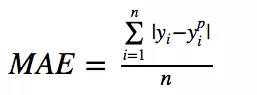
1 import numpy as np
2
3 y_true = np.array([0.000, 0.166, 0.333])
4 y_pre = np.array([0.000, 0.255, 0.986])
5
6 print("d is: " + str(["%.8f" % elem for elem in y_true]))
7 print("p is: " + str(["%.8f" % elem for elem in y_pre]))
8
9 def mae(predictions, targets):
10 differences = predictions - targets
11 absolute_differences = np.absolute(differences)
12 mean_of_absolute_differences = absolute_differences.mean()
13 return mean_of_absolute_differences
14
15 mae_error = mae(y_pre, y_true)
16 print("mae error is:", mae_error)
均方误差(MSE) VS 平均绝对误差(MAE)
具体来说,MSE计算更加简便,MAE对异常点(离群点)拥有更好的鲁棒性。
具体原因:当我们在训练一个机器学习模型的时候,我们的目标就是找到是损失函数达到极小值的点。当预测值等于真实值时,则损失函数达到最小。由于 MSE 对误差(e)进行平方操作(y_true - y_pre = e),当 e> 1,那么误差值会进一步增大。如果我们的数据中存在一个异常点,那么e 值将会很大,e的平方将会远远大于 |e|。这将使得和以 MAE 为损失的模型相比,以 MSE 为损失的模型会赋予更高的权重给异常点。例如用RMSE(MSE的平方根,同MAE在同一量级中)为损失的模型会以牺牲其他样本的误差为代价,朝着减小异常点误差的方向更新。然而这就会降低模型的整体性能。
如果训练数据被异常点所污染,那么MAE损失就更好用(比如,在训练数据中存在大量错误的反例和正例样本,在测试集中没有这个问题)。
直观上可以这样理解:对所有的观测数据,如果我们只给一个预测值来最小化 MSE,那么该预测值应该是所有目标值的均值。但是如果我们试图最小化 MAE,那么这个预测值就是所有目标值的中位数。众所周知,对异常值而言,中位数比均值更加鲁棒,因此MAE对于异常值也比MSE更稳定。然而MAE存在一个严重的问题(特别是对于神经网络):梯度更新始终相同,也就是说,即使对于很小的损失值,梯度值也有可能很大。这样不利于模型的学习。为了解决这个缺陷,可以使用变化的学习率,在损失接近最小值时降低学习率。而MSE在这种情况下的表现就很好,即便使用固定的学习率也可以有效收敛。MSE损失的梯度随损失增大而增大,而损失趋于0时则会减小。这使得在训练结束时,使用MSE模型的结果会更精确。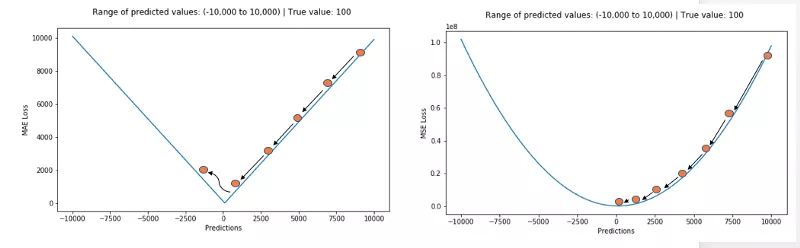
如果异常点会影响业务、并且需要被检测出来,那么我们应该使用 MSE。另一方面,如果我们认为异常点仅仅代表数据损坏,那么我们应该选择 MAE 作为损失。总而言之,处理异常点时,L1损失函数更稳定,但它的导数不连续,因此求解效率较低。L2损失函数对异常点更敏感,通过令其导数为0,可以得到更稳定的封闭解。
二者兼有的问题是:在某些情况下,上述两种损失函数都不能满足需求。例如,若数据中90%的样本对应的目标值为150,剩下10%在0到30之间。那么使用MAE作为损失函数的模型可能会忽视10%的异常点,而对所有样本的预测值都为150。这是因为模型会按中位数来预测。而使用MSE的模型则会给出很多介于0到30的预测值,因为模型会向异常点偏移。上述两种结果在许多商业场景中都是不可取的。这些情况下应该怎么办呢?最简单的办法是对目标变量进行变换。而另一种办法则是换一个损失函数。如Huber损失,Log-Cosh损失,分位数损失。也有些时候可以将利用MAE与MSE训练出的模型进行融合。
3. 平均偏差误差(mean bias error)
与其它损失函数相比,这个函数在机器学习领域没有那么常见。它与 MAE 相似,唯一的区别是这个函数没有用绝对值。用这个函数需要注意的一点是,正负误差可以互相抵消。尽管在实际应用中没那么准确,但它可以确定模型存在正偏差还是负偏差。
![]()
4. 平滑的平均绝对误差(Huber Loss)
Huber Loss对数据异常点的敏感度低于均方误差损失,它降低了对离群点的惩罚程度。它在0处可导。基本上它是绝对误差,当误差很小时,误差是二次形式的。误差何时需要变成二次形式取决于超参数(delta),该超参数可以进行微调。当 𝛿 ~ 0时, Huber Loss 接近 MAE,当 𝛿 ~ ∞(很大的数)时,Huber Loss 接近 MSE。
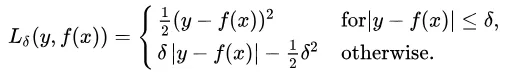
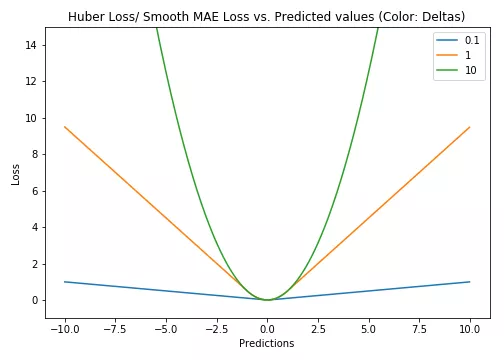
delta 的选择至关重要,因为它决定了你认为哪些数据是异常点。大于 delta 的残差用 L1 最小化(对较大的异常点较不敏感),而小于 delta 的残差则可以“很合适地”用 L2 最小化。
使用 MAE 训练神经网络的一个大问题是经常会遇到很大的梯度(梯度保持不变),使用梯度下降时可能导致训练结束时错过最小值。对于 MSE,梯度会随着损失接近最小值而降低,从而使其更加精确。在这种情况下,Huber Loss可能会非常有用,因为它会在最小值附近弯曲,从而降低梯度。另外它比 MSE 对异常值更鲁棒。因此,它结合了 MSE 和 MAE 的优良特性。但是,Huber Loss 的问题是我们可能需要迭代地训练超参数delta。
import numpy as np def hu(y_true, y_pre, delta): loss = np.where( np.abs(y_true - y_pre ) <= delta, 0.5 * ((y_true - y_pre) ** 2), delta * np.abs(y_true - y_pre) - 0.5 * (delta ** 2) ) return np.sum(loss)
5. Log-Cosh Loss
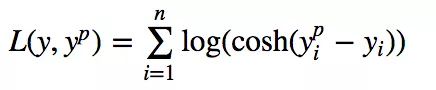
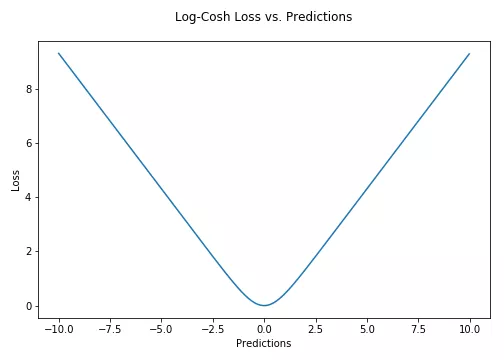
Log-cosh是另一种用于回归问题的损失函数,它比L2更平滑。它的计算方式是预测误差的双曲余弦的对数。
对于较小的x,log(cosh(x))近似等于(x^2)/2,对于较大的x,近似等于abs(x)-log(2)。这意味着‘logcosh’基本类似于均方误差,但不会受到偶尔出现的极端不正确预测的强烈影响。它具有Huber Loss 的所有优点,和 Huber Loss 不同之处在于,其处处二次可导。
二阶可导的优势:许多机器学习模型的实现(如XGBoost)使用牛顿方法来寻找最优解,而牛顿法就需要求解二阶导数(Hessian)。对于像 XGBoost 这样的机器学习框架,二阶可导函数更有利。但 Log-chsh Loss 并不完美。它仍然存在梯度和 Hessian 问题,比如误差很大的话,一阶梯度和Hessian会变成定值,这就导致XGBoost出现缺少分裂点的情况。
def log_cosh(y_true, y_pre): loss = np.log(np.cosh(y_pre - y_true)) return np.sum(loss)
6. Quantile Loss 分位数损失函数

γ是所需的分位数,其值介于0和1之间。
该损失函数对预测值大于真实值和小于真实值的惩罚是不一样的。
当时,该损失等价于MAE
当时,该损失对预测值小于真实值的情况惩罚更大
当时,该损失对预测值大于真实值的情况惩罚更大
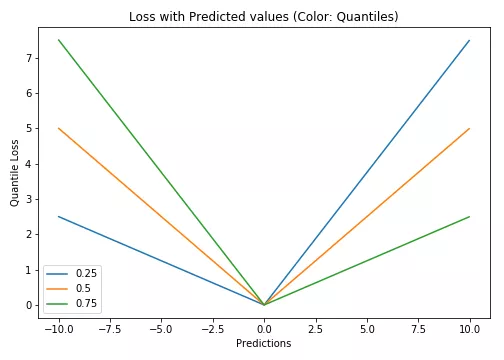
要理解分位数损失函数,首先要理解MAE,MAE是拟合中位数的损失函数(即离差绝对值的期望在中位数处取得最低)
而中位数就是分位数的一种。
另外,我们考虑一种回归问题。以一元回归为例,在众多数据中,我们可以拟合一条曲线,这条曲线告诉我们对于某个x可能的拟合结果y=f(x)。即使真实值y不是f(x),也应该在f(x)附近,此时,我们的预测是一个点。
但是,我们如果想要获取一个y的范围呢?即对于x,我想知道y的大致范围。因为很多时候,我们不需要精确值,反而更需要一个范围值。此时,我们需要预测一个线段。
那怎么做呢?
其实如果我们能分别获得y的0.1分位数与0.9分位数的拟合,那么两者之间的部分就是我们需要的,它预测了y的80%的取值范围
分类损失
1. Hinge Loss, 多分类 SVM 损失
简言之,在一定的安全间隔内(通常是 1),正确类别的分数应高于所有错误类别的分数之和。因此 hinge loss 常用于最大间隔分类(maximum-margin classification),最常用的是支持向量机。尽管不可微,但它是一个凸函数,因此可以轻而易举地使用机器学习领域中常用的凸优化器。
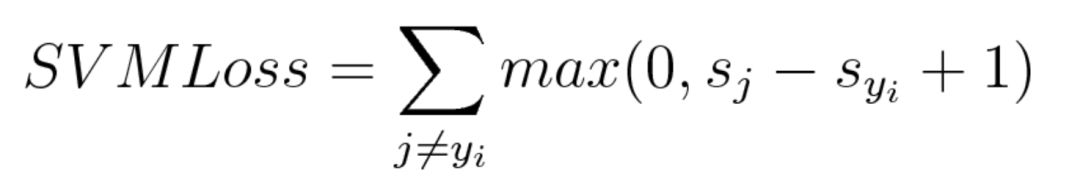
2. 交叉熵损失函数, 负对数似然
这是分类问题中最常见的设置。随着预测概率偏离实际标签,交叉熵损失会逐渐增加。
![]()
注意,当实际标签为 1(y(i)=1) 时,函数的后半部分消失,而当实际标签是为 0(y(i=0)) 时,函数的前半部分消失。简言之,我们只是把对真实值类别的实际预测概率的对数相乘。还有重要的一点是,交叉熵损失会重重惩罚那些置信度高但是错误的预测值。(负对数损失函数和交叉熵损失函数是等价的)
参考:
https://www.jianshu.com/p/437a0dfd06cf
https://www.jiqizhixin.com/articles/091202?from=synced&keyword=%E6%8D%9F%E5%A4%B1%E5%87%BD%E6%95%B0

