编码
二进制的编码
计算机内部是由集成电路这种电子部件构成的,电路只可以表示两种状态——通电、断电
因为这个特性,计算机内部只能处理二进制。那为什么我们能在计算机上看到字母和特殊字符呢?
如果我们用一个二进制数字表示一个字符,比如说用“0100 0001”来表示A。
根据这个对应关系,我们制作一个表格,这个表格里一个二进制数字对应一个字符。
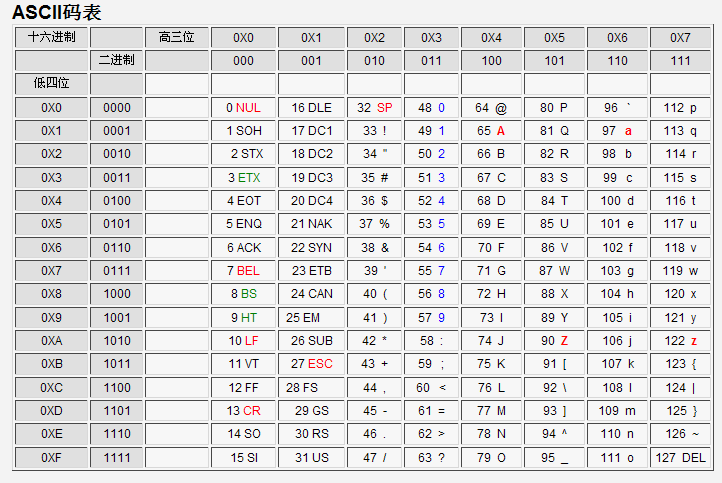
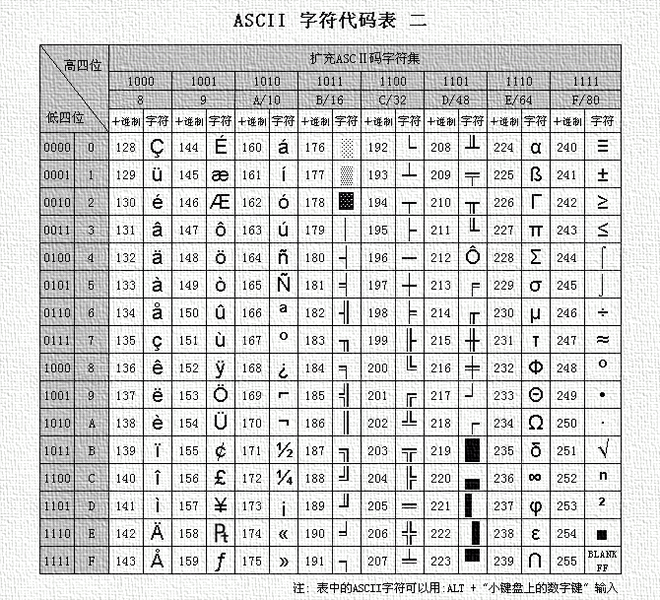
这就是编码。
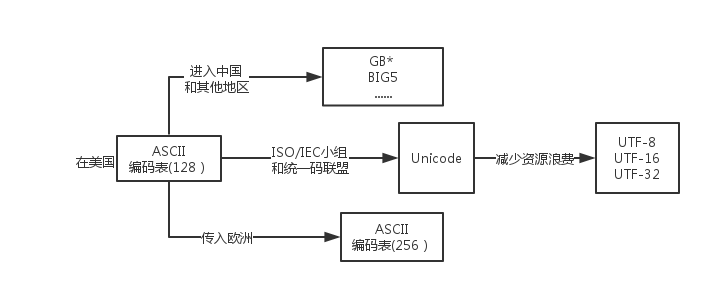
这套编码叫ASCII(美国(国家)信息交换标准(代)码),使用7个或8个二进制位进行编码的方案,最多可以给256个字符。使用了ASCII码,不同的计算机之间就可以实现数据的标准化。
但是ASCII使用的时候有一些限制。他最多之可以表示256个字符。如果有其他的字符就无能为力了。ASCII只能表示26个基本的拉丁字母、阿拉伯数字和英式标点。因此也只能用于显示现代美国英语。
后来计算机世界开始有了其他语言,ASCII码已经无法满足需求。后来不同语言的人各自为自己定制了一套属于自己的编码,同时与ASCII保持兼容。这些编码统称MBCS,到了这里大家都开始好似用双字节。(中国的叫GB*,比如GBK).
在后来有人开始觉得,这么多编码,有些编码之间还不兼容,太让人头大了,于是有这么一群人就坐在一起想出了一个办法:所有的语言都使用同一种编码,这种编码就是Unicode。 Unicode使用最少2个字节(1个字节=1BYTE=8bit=一个长度为8的二进制数) 来表示字母和符号等,有时候是4个字节。这样就解决了上面遇到的问题。
Unicode又叫万国码,是业界的一种标准。但是有人又觉得如果我要表示一个ASCII里的字符,使用unicode来表示不是太浪费空间了吗,于是就有人想出了另外一种解决方案——UTF-8。
UTF-8是对Unicode编码的压缩和优化,最大的特点是它采用了变长的编码方式,他不再是最少使用2个字节,而是将所有的字符进行分类。ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存…