

关于树(图论初步)
今天学了关于图论的最最最最基本的有关概念和性质,做一下简单的记录:
第一板块:
树的储存与遍历:
首先,树是什么???
其实简单点来说,树就相当于一个元素之间有确定关系的集合。其中每个元素都是一个结点,他们两两以特定的方式连接并相互关联,而树就是由递归定义与实现的。例如,下图就是一个典型的树:
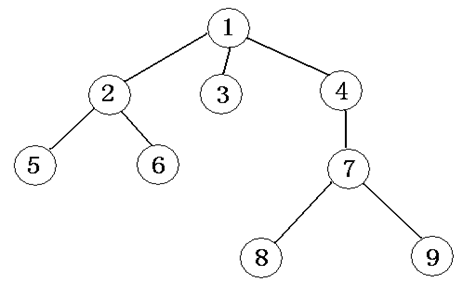
其中,元素1~9都是结点,而1上面没有结点与它连接,所以它就是一个特殊的结点——树根。
除了根结点,其他的结点能分成很多个互不相交的有限集合,而其中的几个互相连接的结点元素就可以组成一棵子树。
每一个结点的子树的个数,叫做这个结点的度,其实这个结点连接的有几个子结点它的度就是几,比如图中的4,他就有1个子节点,所以它的度就是1,而3下面没有跟它连接的子结点,所以它的度就是0。
特别的,如果这个结点的度是0,那这个结点就叫做叶节点,如图中的5,6,3,8,9就都是叶结点。
上面的结点是下面结点的父节点,下面的是上面的子结点,有相同父节点的子结点互为兄弟结点。
下面来道水题练练手:
要求先输入两个数 n、m,表示一棵树的结点数和边数,再输入m行,每行输入一个父节点 x 和一个x的子结点 y。现在要求输出树根,子结点最多的结点 和 此节点的子结点。(数据范围忽略)
思路其实就是桶的思想,先输入每个x和y,并记录y的父节点x。全部输入完之后再判断,如果没有父节点,那这个点就是树根。最后再用一个循环嵌套遍及每一个结点,记录他子结点的个数,找出最大值就好了。
代码如下:

1 #include<iostream> 2 using namespace std; 3 int n,m; 4 int tree[100]={0};//记录父节点 5 int ans,sum,maxn; 6 int main() 7 { 8 int x,y; 9 scanf("%d%d",&n,&m); 10 for(int i=1;i<=m;i++){ 11 scanf("%d%d",&x,&y); 12 tree[y]=x; 13 } 14 for(int i=1;i<=m;i++){ 15 if(tree[i]==0){ 16 printf("%d\n",i); 17 break; 18 } 19 } 20 for(int i=1;i<=n;i++){ 21 sum=0; 22 for(int j=1;j<=n;j++){ 23 if(tree[j]==i) sum++; 24 if(sum>maxn){ 25 maxn=sum; 26 ans=i; 27 } 28 } 29 } 30 printf("%d\n",ans); 31 for(int i=1;i<=n;i++){ 32 if(tree[i]==ans){ 33 printf("%d ",i); 34 } 35 } 36 return 0; 37 }
关于树的遍历,有好几种:
1、先序遍历:先访问根结点,再从左往右的访问每一棵子树,与DFS相似,在上图中遍历顺序就是125634789
2、后续遍历:先从左到右先遍历每一棵子树,最后访问根结点,在上图中遍历的顺序就是562389741
3、层次遍历:一层一层地遍历,在图上遍历的顺序就是123456789
4、叶结点遍历:上图按照这个思想访问的结果为:56389;
5、中序遍历:左儿子——父节点——右儿子(前提是必须是二叉树)。
关于二叉树:
二叉树是一种特殊的树形结构,除了叶节点,其余的每个节点的度都小于等于2,也就是说每个父节点都最多有两个子结点。下图是二叉树的五种形态:

关于二叉树的性质:
1、在二叉树的第i层上最多有 2 的 i-1 次方个结点
证明:二叉树的第一层至多有2的零次方个结点,第2层至多有2的一次方个结点,因为每个节点最多有两个儿子,所以每一层都是上一层的结点数乘2,那第 i 层自然就是2^(i-1)个结点。
2、层数(深度)为k的二叉树最多有 2^k -1个结点
证明:由于第1层有2^0个结点,第2层有2^1个结点,那第k层至多有2^(k-1)个结点,
则总结点数就是:2^0+2^1+……+2^(k-1)=2^0+2^0+2^1+……+2^(k-1)-2^0=2^1+2^1+2^2+……+2^(k-1)-1=2^k -1
3、如果一棵二叉树叶结点数为n0,度为2的结点数为n2,则一定满足:n0=n2+1
证明:对于父节点一定对应两子结点的子树,设一共x层,那非子结点的个数就是前x-1层的个数,由性质2得出前x-1层的个数为2^(x-1)-1,由性质1得出第x层上的子结点个数为2^(x-1)个,所以两者相差1。
4、有n个结点的完全二叉树(最下层的叶节点左边是满的,右边可以为空,如下图)的深度为:floor(log2 n)+1
证明:设结点数是n,深度是k,由性质2得:n=2^(k-1)为指数函数,转换成对数函数就是:log2 n=k-1。即 k=floor((log2 n)+1),由于人家不一定是满的,要加一个下取整。
 (如图就是一棵完全二叉树)
(如图就是一棵完全二叉树)
5、对于任意的完全二叉树的某个标号为n的左结点,此结点的父节点的标号为n/2,兄弟结点的标号n+1,左儿子为2n,右儿子为2n+1。
那么我们怎么把一棵多叉树转换成一棵二叉树呢??
对于每一个根结点,把只保留它最左端的子结点与它相连,其他的结点与他的根结点断开,再与其左边的一个兄弟结点相连就好了。如下图:

一道简单的练习题:
q:一棵完全二叉树的结点总数是18,其叶节点数是?
a:由性质4得出此二叉树的层数为floor(log2 18)+1=5
由性质2的前4层(由于是完全二叉树,前4层一定是满的)的结点数是2^4 -1=15
所以最后一层有18-15=3个结点,最后一层的三个子结点用掉了上一层的2个父结点
第四层有2^(4-1)=8个子结点,用掉俩还剩6个没有子结点的结点,他们也是叶结点
所以一共有3+6=9个子结点
遍历二叉树的代码实现:
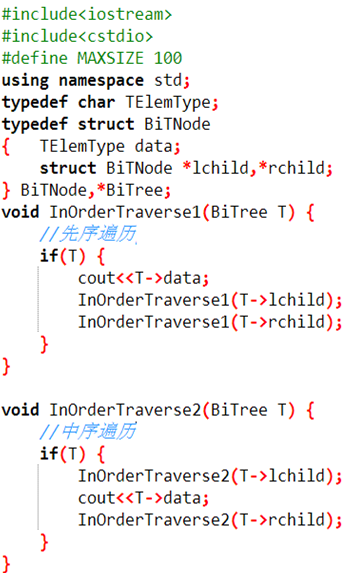
1.先序遍历:先访问根结点,再遍历左二叉树,最后遍历右二叉树。
1 void preorder(tree bt) //先序递归算法 2 { 3 if(bt) 4 { cout << bt->data; 5 preorder(bt->lchild); 6 preorder(bt->rchild); 7 } 8 }
2、中序遍历:先遍历左二叉树,再访问根结点,最后遍历右二叉树。
1 void inorder(tree bt) //中序遍历递归算法 2 { 3 if(bt) 4 { inorder(bt->lchild); 5 cout << bt->data; 6 inorder(bt->rchild); 7 } 8 }
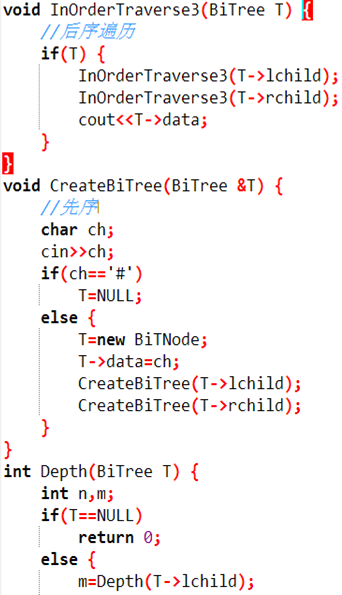
3、后序遍历:先遍历左二叉树,再遍历右二叉树,最后访问根结点。
1 void postorder(tree bt) //后序递归算法 2 { 3 if(bt) 4 { 5 postorder(bt->lchild); 6 postorder(bt->rchild); 7 cout << bt->data; 8 } 9 }
关于一棵表达式树,可以分别用先序,中序,后序遍历方法得到3钟不同的遍历结果:
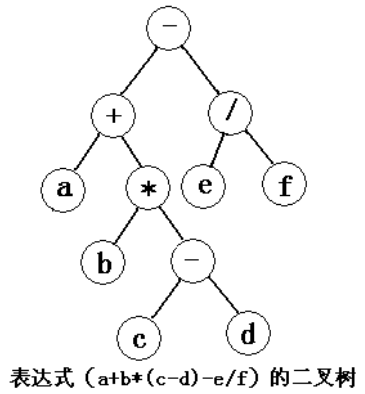
前缀表示(波兰式):- + a * b - c d / e f
中缀表示:a + b * ( c - d ) - e / f
后缀表示(逆波兰式):a b c d - * + e f / -
还有就是关于二叉树的唯一性:
知道先序或后序其中的一个和中序就可以确定一棵树,但是只知道先序和后序就不可以,比如:
二叉树基操:
1、建树

2、删树

3、插点
我来模拟一下,假设现在我有一个排好序了的二叉树,排序规则是对于任意一个子树根,他的左子树上的结点都比子树根小,右子树上的结点都比它大。
那我现在就用一个递归,如果输入的数比根结点小那就递归左子树,如果大就递归右子树,直到找到合适的位置就把他加进去

4、查找
其实也跟插点的思想差不多,类似于二分查找,找到就返回该点,找不到就返回NULL

来几道题练练手吧
注意!!下面的操作均用到指针!!!当然,如果你不想用指针的话,那就直接往下滑吧!!!
【问题描述】
由于先序、中序和后序序列中的任一个都不能唯一确定一棵二叉树,所以对二叉树做如下处理,将二叉树的空结点用·补齐,称为原二叉树的扩展二叉树,扩展二叉树的先序和后序序列能唯一确定其二叉树。
现给出扩展二叉树的先序序列,要求输出其中序和后序序列。
【输入样例】
ABD..EF..G..C..
【输出样例】
DBFEGAC
DFGEBCA
题解如下:


【问题描述】
以二叉链表作存储结构,建立一棵二叉树,并输出该二叉树的先序、中序、后序遍历序列、高度和结点总数。
【输入样例】
12##3## //#为空
【输出样例】
123 //先序
213 //中序
231 //后序
2 //高度
3 //结点总数
题解如下:

——————————————————————————手动分隔线—————————————————————
下面是不用指针的:
输入一棵树的前缀和中缀,求后缀:
代码如下:
1 #include<iostream> 2 #include<cstring> 3 #include<cstdio> 4 #define ll long long 5 using namespace std; 6 char qian[100005],zhong[100005]; 7 int q[100005],z[100005],a[100005]; 8 int cnt=0; 9 void find(int start,int end) 10 { 11 if(start>end){ 12 return; 13 } 14 cnt++; 15 if(start==end){ 16 cout<<char(z[q[cnt]]+'a'-1); 17 return; 18 } 19 //等于的话说明我现在只有一个字母了,这个字母就是最左的那个字母,我把它输出,然后返回再继续找 20 int t=cnt; 21 find(start,q[t]-1); 22 find(q[t]+1,end); 23 cout<<char(z[q[t]]+'a'-1); 24 } 25 int main(){ 26 scanf("%s%s",qian+1,zhong+1); 27 //先输入前序和中序 ,从下标1开始 28 int len=strlen(qian+1); 29 //这里要加上个1 30 for(int i=1;i<=len;i++){ 31 a[zhong[i]-'a']=i; 32 } 33 //记录每个字母在中序中的位置 34 //比如我第一个输入的是c,那么c在中序中的位置就是: 35 //a['c'-'a']=1,即c对应的在中序排列中的位置是第1个 36 for(int i=1;i<=len;i++){ 37 z[i]=zhong[i]-'a'+1; 38 //记录的是一个字母在中序排列中的对应的下标 39 //比如还是c,他的下标就是'c'-'a’+1=3 40 q[i]=a[qian[i]-'a']; 41 //现在遍历前缀表达式的每一个字母,比如现在我在i=2的时候遍历到c, 42 //那也就是说q[2](前缀表达式中的第2位的字母c他在中缀表达式中的位置是q[2]) 43 //记录q[2]= a[qian[2]-'a'],( a[qian[i]-'a']就是中序第i个字符在前序的位置 44 } 45 find(1,strlen(qian+1)); 46 //从第一位到最后一位开始找 47 return 0; 48 }
思路是这样的:
首先记录前缀和中缀,找到前缀在中缀中的位置:
建立一个a数组代表中缀的每个字母在在中缀中的位置,也就是 a[zhong[i]-'a']=i,也就是说中缀表达式中的第 i 个位置的字符,他的位置是 i 。
然后建立了一个z数组,代表中缀表达式中的第 i 个位置的字符他对应的数字大小;
再建立一个q数组,代表前缀表达式中的第 i 个字符在中缀表达式中的位置。
然后定义一个查找函数,定义一个前和一个后代表查找的范围,由于后缀是“左——右——头”,我要先找到那个没有儿子的左叶结点和右结点,之后再查找子树的根结点
因为前序是先头再其他,所以从前缀表达式的第一个字符开始,找到他在中缀表达式中的位置,以其为断点将中缀表达式分成两段,左段就是左子树,右段就是右子树,一直找下去,直到前和后一样了,也就说明这个点就是最左端的叶结点,输出它,也就是输出前缀表达式中的这个字符对应的位置在中缀表达式中的值对应的字符,再返回。继续找,找完之后再找右边的,道理跟他一样,在输出右边的字符,最后在输出子树的根节点就好。
输入中缀和后缀,求前缀:
思路跟前面那道题很相像,但有一点不同的是,根结点在后缀的最后,所以我们要倒着找,但这就导致了一个问题:如果倒着找,那就成先找右儿子再找左儿子了,要是这样的话要想找到下一个子树的根结点就要跳着找。针对这种问题,我们可以通过区间求找的方式解决,具体解决过程的方法解析我放下面代码里了
代码如下:
1 #include<iostream> 2 #include<string> 3 #include<cstring> 4 #include<cstdio> 5 using namespace std; 6 string zhong,hou; 7 void find(int zl,int zr,int hl,int hr); //区间查找,待会再讲 8 int main() 9 { 10 cin>>zhong>>hou; 11 find(0,zhong.size(),0,hou.size());//就是找 12 return 0; 13 } 14 void find(int zl,int zr,int hl,int hr) 15 //这四个分别代表:中序左端,中序右端,后序左端,后序右端 16 { 17 cout<<hou[hr-1];//后序的最后一个肯定是(当前子树的)根结点,那就先输出它! 18 int p=zhong.find(hou[hr-1]); 19 //和上一题的思路一样,就是找到后序的最后一个(也就是子树的根结点)在中序中的位置。 20 if(p>zl) find(zl,p,hl,hl+p-zl); 21 //要分段了,在左边我们要找的是从左端到根结点 22 //关键就是下一个根结点就不是后序中的下一个了 23 //所以我们要找到跳一段后的后序区间。 24 //我们知道的是左端是hl,因为这两段的长度是一样的(你可以枚举画图并试图自己理解一下),所以可以列出等式: 25 // p-zl=x(我设的后序右端位置)-hl,解得:x=hl+p-zl 26 if(p+1<zr) find(p+1,zr,hr+p-zr,hr-1); 27 //这个也一样,也是两个区间的长度相同,我就不再推了 28 }
还有就是以先序顺序输入一棵二叉树,让输出先序、中序、后序排列、层数和总结点数
思路我在下面写的很明白了(吧?),这里就不说了,直接看吧
1 #include<iostream> 2 #include<cstdio> 3 #define ll long long 4 using namespace std; 5 int num,maxn;//代表结点总数、高度 6 char s; 7 8 struct t{ 9 int data,father,lson=0,rson=0,h=0; 10 }tree[100005]; 11 //data代表当前结点的数值,father代表他爹的下标 12 13 void build(int father,bool right) 14 //这个函数主要是为了找出最高高度(maxn)和总结点数(num) 15 //father记录下标,right判断是他爹的左儿子还是右儿子 16 //如果right是0就是左儿子,1就是右儿子 17 { 18 cin>>s; 19 if(s=='\n') 20 return; 21 if(s!='#'){ 22 ++num; 23 //num记录到了第几个下标,也是目前一共读入了多少个 24 int t=num; 25 tree[t].father=father; 26 //当前位置的结点的爸爸就是他的爸爸 27 tree[t].data=s-'0'; 28 tree[t].h=tree[father].h+1; 29 maxn=max(tree[t].h,maxn); 30 if(right==0)//如果是左儿子 31 tree[father].lson=t;//他爸爸的左儿子就是它 32 else 33 tree[father].rson=t;//他爸爸的右儿子就是它 34 35 build(t,0);//他要当爹,找他左儿子 36 build(t,1);//让它当爹,找右儿子 37 } 38 else return; 39 } 40 41 void xian(int now) 42 //这个now代表的是当前状态 43 { 44 cout<<tree[now].data; 45 //由于是先序,就先输出爸爸 46 if(tree[now].lson!=0){ 47 xian(tree[now].lson); 48 } 49 //为啥要判断左儿子是不是等于0呢? 50 //因为他只有有左儿子才能输出对吧 51 //一开始我把俩儿子定义成0,如果这个点他有了下标 52 //那就是说一开始就已经遍历过它了 53 //那他就是个儿子,要不他啥也不是,那我就不输出他啦!!! 54 if(tree[now].rson!=0){ 55 xian(tree[now].rson); 56 } 57 //跟刚才一样 58 } 59 60 void zhong(int now) 61 //跟我刚才解释的先序一样,只不过顺序变成了: 62 //左儿子——他爹——右儿子 63 { 64 if(tree[now].lson!=0){ 65 zhong(tree[now].lson); 66 } 67 cout<<tree[now].data; 68 if(tree[now].rson!=0){ 69 zhong(tree[now].rson); 70 } 71 } 72 73 void hou(int now) 74 { 75 if(tree[now].lson!=0){ 76 hou(tree[now].lson); 77 } 78 if(tree[now].rson!=0){ 79 hou(tree[now].rson); 80 } 81 cout<<tree[now].data; 82 } 83 //还是跟刚才一样哈哈哈 84 85 int main() 86 { 87 build(0,0); 88 //一开始啥也没有,右边那个我定义成啥都行 89 //反正他当不了儿子 ,我根本没必要管他 90 xian(1); 91 cout<<'\n'; 92 zhong(1); 93 cout<<'\n'; 94 hou(1); 95 cout<<'\n'; 96 cout<<maxh<<'\n'; 97 cout<<num<<'\n'; 98 //完美的输出 99 return 0; 100 }
(我终于凑够一百行啦!!!)
下面就是第二板块:
图的储存遍历及拓扑排序
图的相关概念:
如果数据元素集合中的各元素之间存在某些特定的关系,那么此数据结构称为图
一般的,我们将元素抽形成顶点(用V表示),对应关系抽象成边(用E表示)
还有就是图的分类:
无向图:也就是没有方向的图,但元素之间可以互相到达。如图(A)就是一个无向图
有向图:就是有方向的图,他的边是有箭头的,只能沿着箭头的方向走。如图(B)就是一个无向图
带权图:就是每条边都有权重,包括有向带权图和无向带权图,也称为网,如图(C)就是一个带权图

完全图:在无向图中,每两个点之间都有一条边。若是有向图,每两个顶点之间都存在着方向相反的两条边。其实就是说边已经满了,不能再加了
那我们就可以推出:
一个n阶的完全无向图含有 n*(n-1)/2 条边;(也就是n+n-1+n-2+...+1的等差数列求和)
一个n阶的完全有向图含有 n*(n-1) 条边;(也就是无向图的边数再乘2)
而当一个图的边数接近完全图,那他就是一个稠密图,如果边数并不多,那他就是一个稀疏图
如果一条路径上的点除了起点和终点可以相同外,其它顶点均不相同,则称此路径为一条简单路径;起点和终点相同的简单路径称为回路(也叫环),图中1—2—3就是一条简单路径,人家的长度是2(就是之间边的数目),然而1—3—4—1—3就不是一个简单路径

如果两个顶点间有边连接(也就是有路径),那他们就是联通的。
连通图:如果在一个无向图中,任意两个顶点之间都是连通的,则称该无向图为连通图。否则称为非连通图
联通分量:就是在一个无向图中的最大联通子图
下图标注0123的就是一个连通分量:

那啥是强联通呢??
就是强迫他联通,连通图是建立在无向图的基础上的,而强联通建立在有向图的基础上:
强连通图:在一个有向图中,对于任意两个顶点U和V,都存在着一条从U到V的有向路径,同时也存在着一条从V到U的有向路径,则称该有向图为强连通图
强连通分量:一个有向图的强连通分量定义为该有向图的最大的强连通子图
那连通图和环有啥区别呢?
连通图是说每两个元素之间都是连接的,而环是所有元素只要连接在一起就好
举个例子:下图是一个环,但不是一个连通图,因为5和2 , 5和3 , 5和1.........都没连起来

图的存储:
两种方法:1、邻接矩阵 2、邻接表
一、邻接矩阵:
就是建一个二维矩阵G,对于不带权的图,G[i][j]代表的就是序号为 i 的点和序号为 j 的点之间是否有路径,如果有就等于1,没有就是0,对于自己,也是相当于没有路径,比如:

它对应的邻接矩阵就是:
0,0,1,1(1跟1之间没有路径,跟2也没有,跟3有,跟4也有)
0,0,1,0
1,1,0,1
1,0,1,0
对于带权的图,如果两点之间有路径,那对应的G[i][j]就是这条路径的边权大小。然而如果之间没有路径,那对应的就是正无穷(随便啥都可以,只要够奇葩就能保证这个数不等于任何一条边权),比如:

邻接矩阵为:
+∞,5,8,+∞,3
5,+∞,2,+∞,6
8,2,+∞,10,4
+∞,+∞,10,+∞,11
3,6,4,11,+∞
代码实现:
1 #include<iostream> 2 using namespace std; 3 int k,e; 4 double g[1001][1001]; 5 int main() 6 { 7 int m,n; 8 cin>>m>>n; 9 for(int i=1;i<=m;i++){ 10 for(int j=1;j<=n;j++){ 11 g[i][j]=0x7fffffff;//初始化,对于带权的图就先附最大值,待会如果没路径的话就直接不用变了 12 // g[i][j]=0;//对于无权边,那就初始化成0 13 } 14 } 15 int i,j,w; 16 cin>>e; 17 //对于带权的图: 18 for(int k=1;k<=e;k++){ 19 scanf("%d%d%d",&i,&j,&w); 20 g[i][j]=w; 21 g[j][i]=w;//如果是一个无向图,由于两个点是相互的对应的,即具有对称性 22 //当然,如果不是无向图,那句不加这一句了 23 } 24 //对于不带权的图 25 for(int k=1;k<=e;k++){ 26 scanf("%d%d",&i,&j); 27 g[i][j]=1; 28 g[j][i]=1; 29 } 30 return 0; 31 }
方法二:邻接表
首先记录一个二维数组g,g[i][0]表示点 i 出度的数量,g[i][j]表示点 i 发出的第 j 条边是通向哪个顶点

我们可以简单模拟一下
现在输入:“1 2” 代表这条边的起点和终点,即 from=1,to=2
edge[1].next= head[from] = 0 (因为head[]初始化是0),那么第一条边的上一条边(也就是它的前驱就是0)
edge[1].to= 2,就是这条边的终点是2
head[1] = num_edge=1,即到了下一条边的时候head[from]=1做准备
再输入“1 3”,代表第二条边的from=1,to=3
edge[2],next= head[1]=1, head[1]刚才更新过了就是1
edge[2].to=3.就是这条边的终点是3
head[1]=num_edge=2
再输入“3 4”
edge[3].next=head[3]=1;
edge[3].to=4
head[3]=num_edge=0
最后输入“3 5”
edge[4].next=head[3]=3
edge[4],to=5
head[4]=num_edge=4
然后就模拟完了
那要这些数组有啥用??
不难发现,对于几个父节点一样的点,最左边的那个他的next值是0,也就是说,我们从该点出发的最后一条边开始找,找完就找他的前驱,一直找到某个节点他的next值是0
我现在想求每个点的出度,就是刚才的方法,现在我从head[i]开始找,也就是从该点出发的最后一条边开始找,在找这条边的前驱(前一条边),每找到一个符合要求的就让cnt 加1,直到一个节点他的next值是0,也就是说他是最后一个了,那我不就找完了吗!!!
来到例题:计算每个点的出度:
输入
5
0 0 0 0 1
1 0 1 0 0
1 0 0 1 0
0 0 0 0 1
0 0 0 0 0
输出
v0 v1 v2 v3 v4
1 2 2 1 0

方法1:邻接矩阵
这个我就不用多说了吧
1 #include<iostream> 2 using namespace std; 3 int i,j,k,e,n; 4 double g[101][101];//全为0 不通 5 int a[100];//统计数组 6 int main() 7 { int i,j,n; 8 cin>>n; //邻接矩阵存储 9 for(int i=1;i<=n;i++) 10 for(int j=1;j<=n;j++) 11 cin>>g[i][j]; 12 13 for(int i=1;i<=n;i++) 14 { int tot=0; //统计每行数字1 出度 15 for(int j=1;j<=n;j++) 16 if(g[i][j]>0) tot++; 17 a[i]=tot; //按行统计存储 18 } 19 cout<<"V0 V1 V2 V3 V4"<<endl; 20 for(int i=1;i<=n;i++) 21 cout<<a[i]<<" "; 22 return 0; 23 }
方法二:邻接表
上面解释过了
1 #include<iostream> 2 using namespace std; 3 struct Edge{ 4 int next;//代表这条边的上一条边的编号,是为了记录它的前驱 5 int to;//代表这条边到达的点的编号 6 }edge[1001]; 7 int head[1001];//代表从该点出发的最后一条边的编号 8 int num_edge;//代表边的编号 9 void add_edge(int from,int to){ 10 //开始建图 ,我会输入两个点分别是from和to,分别代表这条边的起点和终点,代表着一条新边 11 edge[++num_edge].next=head[from]; 12 //记录前驱,方便最后搜索 13 edge[num_edge].to=to; 14 head[from]=num_edge; 15 //刷新下一条边的前驱就是他了 16 } 17 18 int main() 19 { 20 num_edge=0; 21 scanf("%d %d",&n,&m); //读入点数和边数 22 for(int i=1;i<=m;i++){ 23 scanf("%d %d",&u,&v); //u、v之间有一条边 24 add_edge(u,v); 25 } 26 int j,chudu[maxn]; 27 for(int i=0;i<n;i++){ 28 //求出每一个顶点的出度 29 int tot=0; 30 j=head[i]; 31 while (j!=0){ 32 tot++; 33 j=edge[j].next; 34 } 35 //这些点的爹一样 36 // 所以我就用刚才记录的前驱找他是多少个人的爹,那他的出度就是几 37 chudu[i]=tot; 38 } 39 cout<<"v0 v1 v2 v3 v4"<<endl; 40 for(int i=0;i<=4;i++) cout<<chudu[i]<<" "; 41 return 0; 42 }
还有就是图的便利:
其实无非就是dfs和bfs呗,直接上题:
输入左图,访问它!

输入
8
0 1 1 0 0 0 0 0
1 0 0 1 0 0 0 0
1 0 0 0 0 1 1 0
0 1 0 0 0 0 0 1
0 1 0 0 0 0 0 1
0 0 1 0 0 0 0 0
0 0 1 0 0 0 0 0
0 0 0 1 1 0 0 0
输出:
V1 V2 V4 V8 V5 V3 V6 V7即他们的顺序
其实就是跑一边dfs,其他没啥了,直接上题解吧
1 #include<iostream> 2 using namespace std; 3 int n,m; 4 int a[100][100]; 5 int vis[100];//标记数组 6 void dfs(int u) 7 { cout<<"V"<<u<<" "; 8 vis[u]=1; //访问标记 9 for(int i=1;i<=n;i++) 10 if(a[u][i]==1&&vis[i]==0) dfs(i); 11 } 12 int main() 13 { cin>>n; //邻接矩阵存储 14 for(int i=1;i<=n;i++) 15 for(int j=1;j<=n;j++) 16 cin>>a[i][j]; 17 dfs(1); //选定V1开始dfs遍历。 18 return 0; 19 }
还有就是
思路就是这样,我就不细写了

对于非连通图,就把每个点全都跑一边就行了
来道题吧(其实就是深搜(或广搜题))
现在有x个公司,一共有n个人(编号从1~n),下面输入m条信息,输入两个人的编号,代表他们认识,而且认识具有传递性,就是说a认识b,b认识c,则a认识c,而且相互认识的人·都在一个公司,两个人不认识就属于不同的公司,问最多有多少个公司
其实我可以换种思想考虑,用无向图把关系表示出来,求无向图的联通数量
1 #include <cstdio> 2 const int maxn=10010; 3 int a[maxn][maxn]; 4 int vis[maxn]; 5 int n,m,cnt; 6 void dfs(int k){ 7 vis[k]=1; //访问标记 8 for(int i=1;i<=n;i++) 9 if(!vis[i]&&a[k][i]) dfs(i); 10 } 11 int main(){ 12 scanf("%d%d",&n,&m); 13 int x,y; 14 for(int i=1;i<=m;i++){ 15 scanf("%d%d",&x,&y); 16 a[x][y]=a[y][x]=1; 17 } 18 for(int i=1;i<=n;i++)if(!vis[i]){ 19 dfs(i); 20 cnt++; 21 } 22 printf("%d\n",cnt); 23 return 0; 24 }
终于到拓扑排序了!!!
首先,啥是拓扑排序?
首先我们要知道某些概念:
1.AOV网,就是有向无环图,拓扑排序只适用于它

在日常生活中,一项大的工程可以看作是由若干个子工程(这些子工程称为“活动” )组成的集合,这些子工程(活动)之间必定存在一些先后关系,即某些子工程(活动)必须在其它一些子工程(活动)完成之后才能开始,我们可以用有向图来形象地表示这些子工程(活动)之间的先后关系。
子工程(活动)为顶点,子工程(活动)之间的先后关系为有向边,这种有向图称为“顶点活动网络” ,又称“AOV网”
箭头由A指向B代表必须先到A再到B,顺序不能反。
那他为啥必须是个无环的图呢?

4是1的前驱,想完成1,必须先完成4。然而3是4的前驱,而2是3的前驱,1又是2的前驱。
最后造成想完成1,必须先完成1本身,这显然出现了矛盾。
那他的算法怎么实现呢?
首先找到入度为0的点输出,因为他没有爹,完成就没有前提
然后删除此点及以此点为起点的所有关联边
然后重复一下操作,一直到不存在入度为0的点为止
这样的话就衍生出来了一个新的用处,它可以判断这个有向图是否有环:
因为如果有环的话,组成环的点永远无法被输出,这样我只要判断输出的点的数目与顶点数是否相等,
如果不相等,说明有环,相等就是没环。
那啥实现?可以用栈的思想
a) 数据结构:indgr[i]: 顶点i的入度,stack[ ]: 栈
b) 初始化:top=0 (栈顶指针置零)
c) 将初始状态所有入度为0的顶点压栈
d) I=0 (计数器)
e) while 栈非空(top>0)
i. 栈顶的顶点v出栈;top-1; 输出v;i++;
ii. for v的每一个后继顶点u
1. indgr[u]--; u的入度减1
2. if (u的入度变为0) 顶点u入栈
f) 算法结束
来几道例题试试?
T1、家谱树:
有一个家族辈分很乱(是真的很乱)给出每个人的孩子的信息(
第1行一个整数N(1<=N<=100),表示家族的人数。接下来N行,第i行描述第i个人的儿子, 每行最后是0表示描述完毕。)。
现在要求输出一个序列,使得每个人的后辈都比那个人后列出。
这个题跟拓扑排序有啥关系???
举个样例画个图看看?
5
0
4 5 1 0
1 0
5 3 0
3 0

那我们不难看出,应该首先把最小的,也就是没有人指的元素先输出,再将除了最大的人指外没人指的输出,依次类推就好,那这不就保证大的先出,比他小的后出了吗?!那这就是拓扑排序!!!
1 #include<cstdio> 2 #include<iostream> 3 using namespace std; 4 int a[101][101],c[101],r[101],ans[101]; 5 int i,j,tot,temp,num,n,m; 6 int main() 7 { cin>>n; 8 for(i=1;i<=n;i++) 9 { 10 do 11 {cin>>j; 12 if(j!=0) 13 { 14 c[i]++;//c[i]用来存i的出度个数 15 a[i][c[i]]=j;//i的第某个入度是j 16 r[j]++;//r[j]用来存j的入度个数 17 } 18 }while(j!=0); 19 } 20 for(i=1;i<=n;i++) 21 if(r[i]==0) 22 ans[++tot]=i;//把图中所有入度为0的点入栈 23 do //栈用一维数组ans[]表示 24 { 25 temp=ans[tot]; 26 cout<<temp<< " "; 27 tot--;num++;//栈顶元素出栈输出 28 for (i=1;i<=c[temp];i++) 29 { 30 r[a[temp][i]]--; 31 if(r[a[temp][i]]==0) //如果入度减1后变成0 32 ans[++tot]=a[temp][i]; //将这个后继点入栈 33 } 34 }while(num!=n);//如果输出的点的数目num等于n,说明算法结束 35 return 0; 36 }
T2、奖金
先输入员工个数n,要求数m
再输入m行,每行代表一个要求,包括两个数字a,b,代表a员工的工资比b高
已知每名员工奖金最少为100且必须是整数,请输出最少总奖金
这道题也可以用拓扑的方法来想,如果a的奖金比b多,那就让b指向a(不反过来是因为最初输出的时候是想让工资少的先输出,后面依次地推再让奖金加1,反过来的话我不好判断工资最高的人工资是多少)
代码如下:
1 #include<iostream> 2 using namespace std; 3 int a[10001][301]={0} , into[10001]; 4 int m,n,money, ans[10001]; 5 void init()//读入并构建图,统计入度 6 { 7 int i,x,y; 8 cin>>n>>m; //n员工m代表 9 for(i=1;i<=m;i++) //m次询问 10 { 11 cin>>x>>y; 12 a[y][0]++; //记录邮y引出边的数目 13 a[y][a[y][0]]=X;//y的某个入度是x 14 into[x]++;//记录入度 15 } 16 } 17 bool topsort( ) 18 { 19 int t,tot,k,i,j; 20 tot=0;k=0; 21 while(tot<n)//tot项点个数 22 { 23 t=0;//用来判断有无环 24 for(i=1;i<=n;i++) 25 if(into[i]==0) 26 { 27 tot++; 28 t++; 29 money+=100; 30 ans[t]=i; 31 into[i]=0xfffffff; 32 } 33 if(t==0)return false;//存在环 34 money+=k*t; 35 k++; 36 for(i=1;i<=t;i++)//去掉相连的边 37 for(j=1;j<=a[ans[i]][0];j++) 38 into[a[ans[i]][j]]--; 39 } 40 return true; 41 } 42 int main() 43 { 44 init(); 45 money=0; 46 if(topsort()) cout<<money<<endl; 47 else cout<<"Poor Xed"<<endl; 48 return 0; 49 } 50

反正我是学不懂了,就先记录到这吧
拜拜!!!
2022/3/24
第1行一个整数N(1<=N<=100),表示家族的人数。 接下来N行,第i行描述第i个人的儿子。 每行最后是0表示描述完毕。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具