
python编辑ASNI编码的.b3dm文件遇到的问题
一、目的
需要处理一批后缀为".b3dm"的三维模型文件,对文件中的字符数据进行修改,然后将数据保存交给下一个人继续处理模型文件。
二、踩坑过程
1.第一次直接使用默认的编码读取,报错:'gbk' codec can't decode byte 0xc8 in position 8: illegal multibyte sequence

2.指定编码为'utf-8'同样报错不能解码
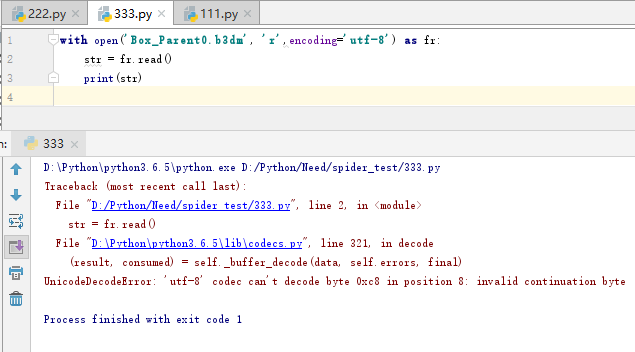
3.于是想到字符集中可能是有无法识别的中文字符,用了一下error='ignore'
可以看到前半部分解码正确,输出了正确的字符,后半部分无法正确解码但是忽略了报错,所以输出了乱码。
查了一下.b3dm文件是由字符和图片、gif等共同组成的,那图片不能正确解码就能说明白了,因为图片是二进制的。
到这里按理说可以了,因为只需要处理文件中的字符内容,不需要对gif图进行修改,字符内容正确解码了可以按需要修改。但是修改之后用图形软件打开该文件发现gif图也变了,说明刚才读取该文件虽然没有修改gif,但是在一顿读写编码过程中二进制格式的gif部分也被修改了。这样的结果是不能接受的。
4.又用python验证了一下,使用刚才的读取方法读文件,不做任何修改,直接写入文件。再使用filecmp模块对结果文件和源文件进行对比,看文件是否被改变。

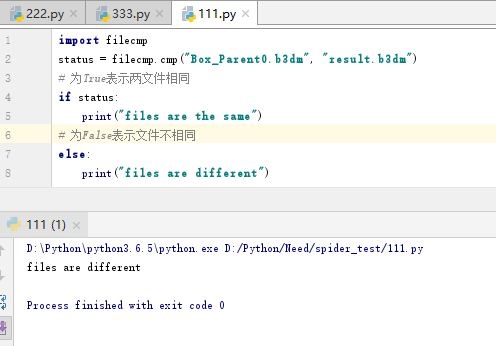
可以看到未做任何数据修改,但是结果文件result.b3dm和源文件Box_Parent0.b3dm文件已经不相同了。
5.由于有gif图,所以只能以二进制读取,二进制保存,这样才不会改变文件内容。但是二进制读取的结果,我并不能对其中的字符内容进行编辑,所以还得进行解码。
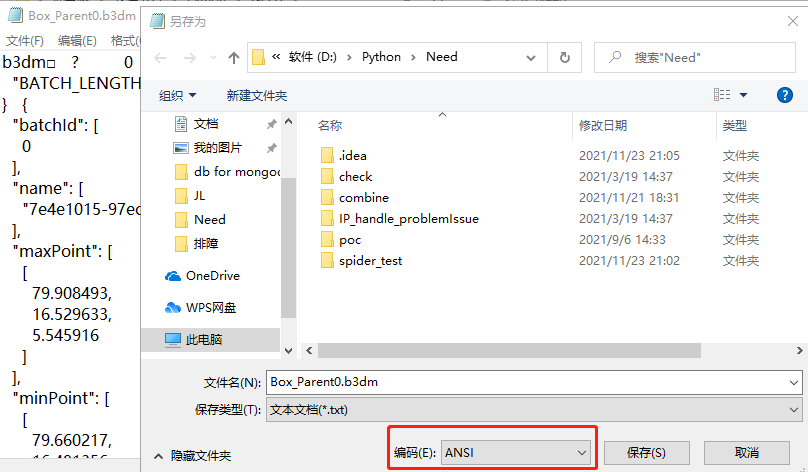
又想到记事本可以查看文件的编码方式,于是用记事本打开目的文件,选择另存为,看到了编码格式是"ASNI"。
6. 所以这次使用rb进行二进制读文件,并以"raw_unicode_escape"方式进行解码人眼成可读的str,再以"raw_unicode_escape"将处理后的str编码回bytes并以wb进行bytes写入。由于是想对比此方式是否会对文件进行改变,所以没有编辑字符内容。
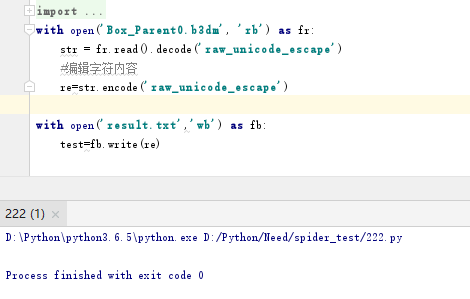
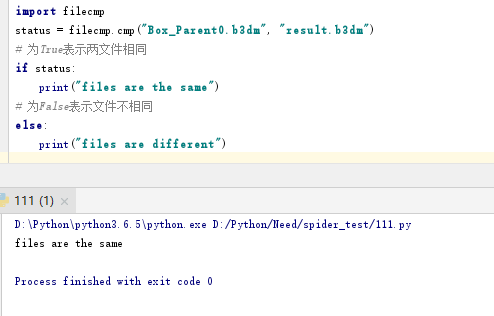
可以看到对比结果,前后文件是相同的,并且过程中文件被解码成了我可以编辑的格式,可以达到目的。并且用画图软件打开gif也是正常的。
