12-K8S之调度器、预选策略和优选函数
目录
调度器、预选策略和优选函数
kube-scheduler
Predicate(预选):
1.在pod模板中定义的资源限额:cpu/memory,node节点是否满足这个资源需求的下限
requests:
cpu:
memory
limits:
cpu:
memory:
2.节点上被占用的端口与新建的pod不冲突
Priority(优先):
根据每个节点资源富余情况倒序,选择富余较多的。
Select(选定):
调度器:
预选策略:
CheckNodeCondition:
GenerapPredicates
HostName: 检查Pod对象是否定义了pod.spec.hostname,
PodFitHostPorts: pod.spec.containers.ports.hostPort
MatchNodeSelector: pod.spec.nodeSelector
PodFitsResources: 检查pod的资源需求是否能被节点满足;
NoDiskConflict: 检查Pod依赖的存储卷是否能满足需求;
PodToleratesNodeTaints: 检查Pod上的spec.tolerations可容忍的五点是否完全包含节点上的污点;
PodToleratesNodeNoExecuteTaints: # 默认没启用
CheckNodeLabelPresence: # 默认没启用
CheckServiceAffinity: # 默认没启用
MaxEBSVolumeCount:
MaxGCEPDVolumeCount:
MaxAzureDiskVolumeCount:
CheckVolumeBinding:
NoVolumeZoneConflict:
CheckNodeMemoryPressure:
CheckNodePIDPressure:
CheckNodeDiskPressure:
MatchInterPodAffinity:
优选函数:
LeastRequested: # 默认启用的优选函数
(cpu((capacity-sum(requested))*10/capacity)+memory((capacity-sum(requested))*10/capacity))/2
BalancedResourceAllocation: CPU和内存资源被占用率相近的胜出; # 默认启用的优选函数
NodePreferAvoidPods:节点注解信息"scheduler.alpha.kubernetes.io/preferAvoidPods" # 默认启用的优选函数
TaintToleration:将Pod对象的spec.tolerations列表项与节点的taints列表项进行匹配度检查,匹配条目越多,得分越低;# 默认启用的优选函数
SelectorSpreading:与当前pod对象同属的标签选择器选择适配的其他pod对象所在的节点越多的得分越低;# 默认启用的优选函数
InterPodAffinity:遍历pod对象的亲和性条目,并将那些能够匹配到给定节点的条目权重相加,值越大的得分越高;# 默认启用的优选函数
NodeAffinity:节点亲和性 # 默认启用的优选函数
MostRequested: # 未启用
NodeLabel: # 未启用
ImageLocality:根据满足当前Pod对象需求的已有镜像体积大小之和来评估pod运行所需镜像在节点的体积越大的,得分越高。 # 未启用
1.nodeSelector nodeName调度:
kubectl explain pod.spec
nodeName <string>
nodeSelector <map[string]string>
vim pod-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-demo
namespace: default
labels: # <map[string]string> 映射类型,类似于json
app: myapp
tier: frontend
spec:
containers:
- name: myapp
image: nginx:1.20 # 使用镜像启动默认命令
nodeSelector: # 启用nodeSelector预选函数
disktype: ssd # 表示将此pod调度到标签为disktype=ssd的node节点上
# 先给worker01和worker02打标签disktype: general-disk
kubectl label node worker01 disktype:general-disk
kubectl label node worker02 disktype:general-disk
kubectl apply -f pod-demo.yaml # 发现pod的状态一直为pending状态,这说明的scheduler调度器的预选时这一关都没过,没找到合适的调度节点满足disktype=ssd。。。因为我们的node节点都标记为disktype:general-disk了。
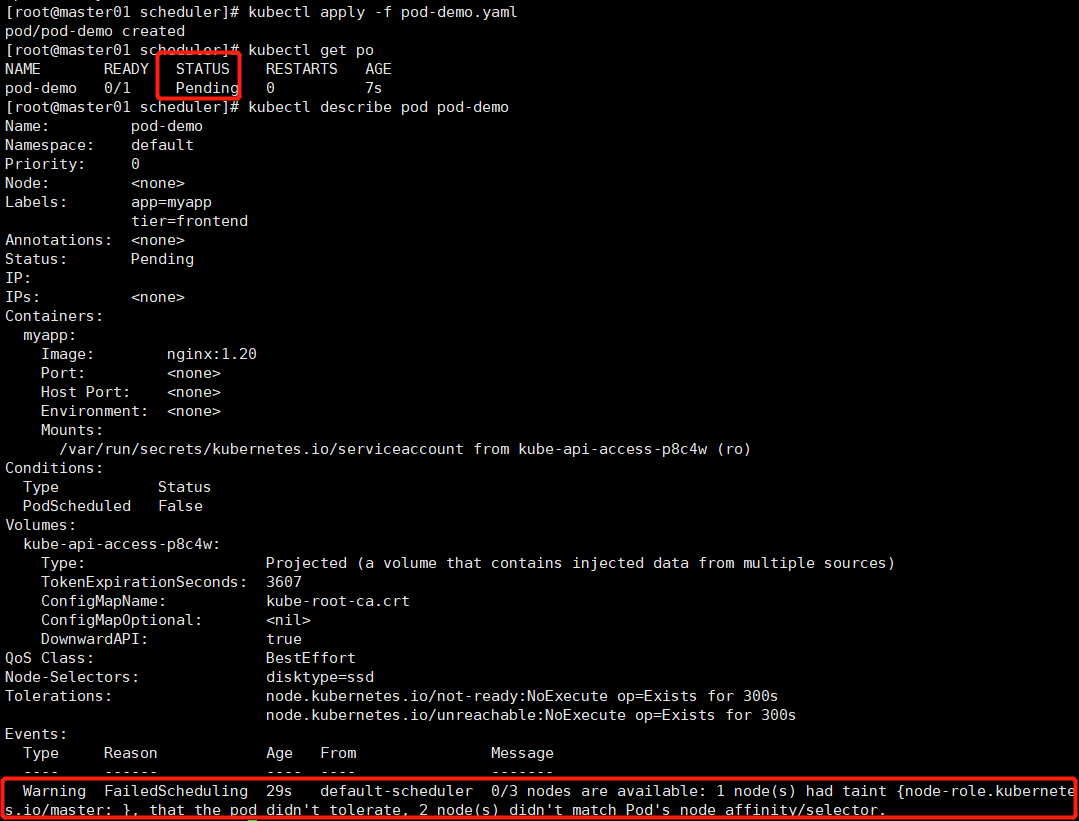
现在将worker01的标签disktype=general-disk修改为disktype=ssd,然后上述apply的pod-demo的pod就能调到worker01了。
kubectl label node worker02 disktype:ssd
2.节点亲和性调度(pod亲和于node节点)
kubectl explain pod.spec
affinity <Object>
kubectl explain pod.spec.affinity
nodeAffinity <Object>
preferredDuringSchedulingIgnoredDuringExecution <[]Object> # 软亲和性,如果能找到满足条件的最好
preference <Object> -required-
matchExpressions <[]Object> # 集合选择器
matchFields <[]Object> # 等值选择器
weight <integer> -required-
requiredDuringSchedulingIgnoredDuringExecution <Object> # 硬亲和性
nodeSelectorTerms <[]Object> -required-
matchExpressions <[]Object>
matchFields <[]Object>
podAntiAffinity <Object>
preferredDuringSchedulingIgnoredDuringExecution <[]Object>
requiredDuringSchedulingIgnoredDuringExecution <Object>
scp pod-demo.yaml pod-nodeaffinity-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-node-affinity-demo
namespace: default
labels: # <map[string]string> 映射类型,类似于json
app: myapp
tier: frontend
spec:
containers:
- name: myapp
image: nginx:1.20 # 使用镜像启动默认命令
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # 硬亲和性只有node标签是foo和bar的节点才满足被调度的需求。
nodeSelectorTerms:
- matchExpressions:
- key: zone
operator: In
values:
- foo
- bar
kubectl apply -f pod-nodeaffinity-demo.yaml
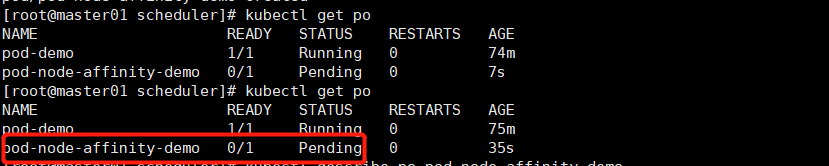
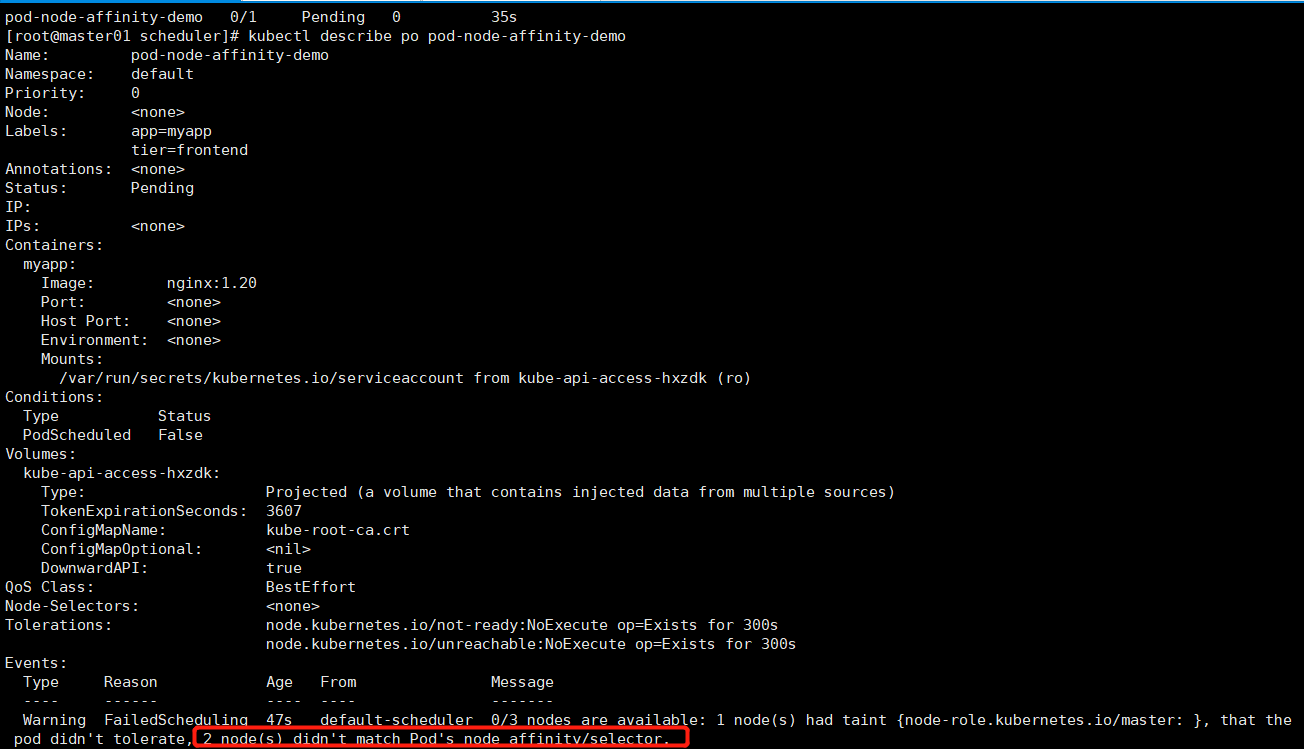
# 改成软亲和性
preferedDuringSchedulingIgnoredDuringExecution # 这时node的标签即使不满足带有foo或者bar,也能勉为其难地找一个node节点部署。
[root@master01 scheduler]# vim pod-nodeaffinity-demo2.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-node-affinity-demo2
namespace: default
labels: # <map[string]string> 映射类型,类似于json
app: myapp
tier: frontend
spec:
containers:
- name: myapp
image: nginx:1.20 # 使用镜像启动默认命令
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution: # 硬亲和性只有node标签是foo和bar的节点才满足被调度的需求。
- preference:
matchExpressions:
- key: zone
operator: In
values:
- foo
- bar
weight: 60
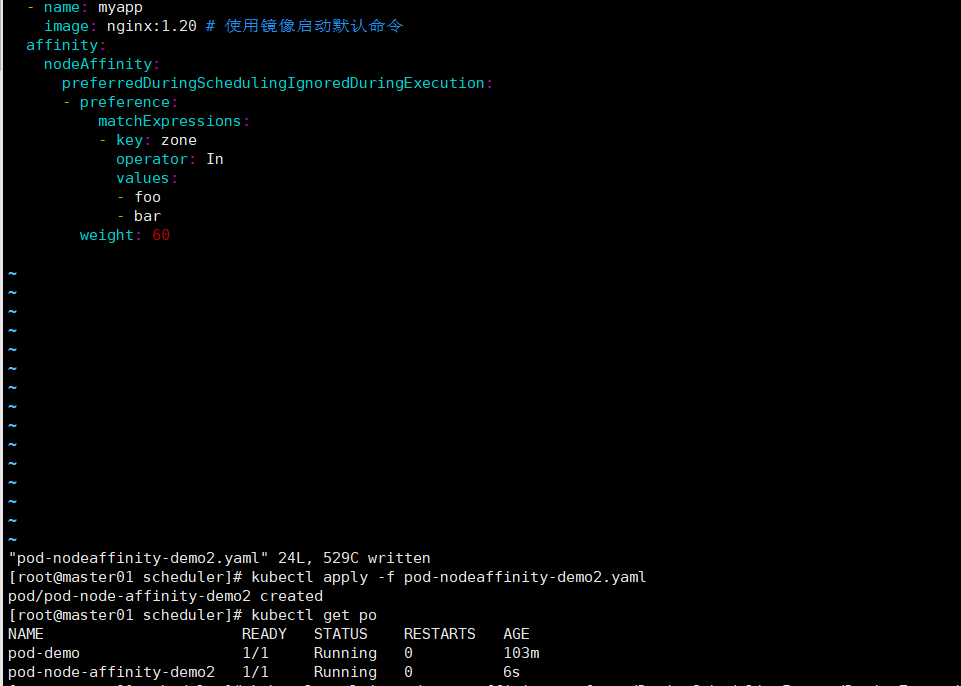
3.pod亲和度调度(pod亲和于pod)
kubectl explain pod.spec
affinity <Object>
kubectl explain pod.spec.affinity
podAffinity <Object>
preferredDuringSchedulingIgnoredDuringExecution <[]Object>
preferredDuringSchedulingIgnoredDuringExecution <[]Object>
podAffinityTerm <Object> -required-
labelSelector <Object> # 标签选定一组亲和的pod的资源
matchExpressions <[]Object>
matchLabels <map[string]string>
namespaceSelector <Object>
namespaces <[]string> # 指定和亲和的pod的所在名称空间,不指定默认是亲和的pod的名称空间。
topologyKey <string> -required- # 位置拓扑的键,将多个节点标记为同一个标签,作为同一个位置使用(可以将pod调度到同一标签下的不同节点上去)
weight <integer> -required-
requiredDuringSchedulingIgnoredDuringExecution <[]Object>
labelSelector <Object>
matchExpressions <[]Object>
matchLabels <map[string]string>
namespaces <[]string>
topologyKey <string> -required-
kubectl apply -f podaffinity-demo.yaml
cat podaffinity-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-first
namespace: default
labels: # <map[string]string> 映射类型,类似于json
app: myapp
tier: frontend
spec:
containers:
- name: myapp
image: nginx:1.20 # 使用镜像启动默认命令
---
apiVersion: v1
kind: Pod
metadata:
name: pod-second
namespace: default
labels: # <map[string]string> 映射类型,类似于json
app: db
tier: db
spec:
containers:
- name: busybox
image: busybox:latest # 使用镜像启动默认命令
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions: # 对象列表
- {key: app,operator: In, values: ["myapp"]} # 根据pod的标签做亲和性调度,这里选择调度到标签名为myapp的pod所在的节点上。
topologyKey: kubernetes.io/hostname # kubectl get po --show-labels
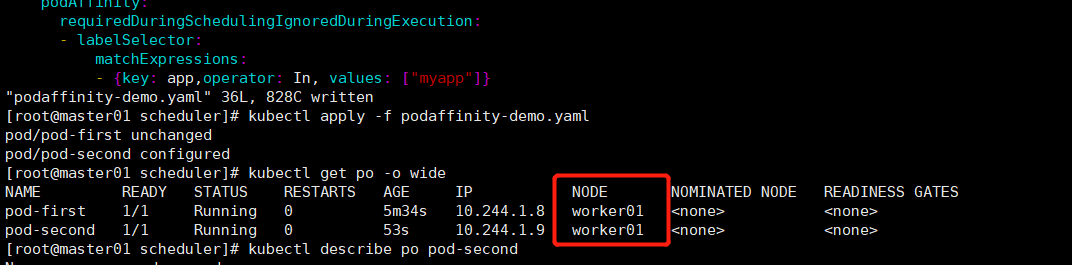
4.pod反亲和性度调度pod亲和于pod)
kubectl explain pod.spec.affinity.podAntiAffinity # 根据标签选择pod。让使用podAntiAffinity属性定位到某标签的pod和自己不再同一个节点之上。
podAntiAffinity <Object>
kubectl apply -f pod-antiaffinity-demo.yaml
cat podaffinity-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-first
namespace: default
labels: # <map[string]string> 映射类型,类似于json
app: myapp
tier: frontend
spec:
containers:
- name: myapp
image: nginx:1.20 # 使用镜像启动默认命令
---
apiVersion: v1
kind: Pod
metadata:
name: pod-second
namespace: default
labels: # <map[string]string> 映射类型,类似于json
app: db
tier: db
spec:
containers:
- name: busybox
image: busybox:latest # 使用镜像启动默认命令
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions: # 对象列表
- {key: app,operator: In, values: ["myapp"]} # 根据已知pod的标签做亲和性调度,这里选择调度到不与标签名为myapp的pod所在节点的同一个节点上。
topologyKey: kubernetes.io/hostname # kubectl get po --show-labels
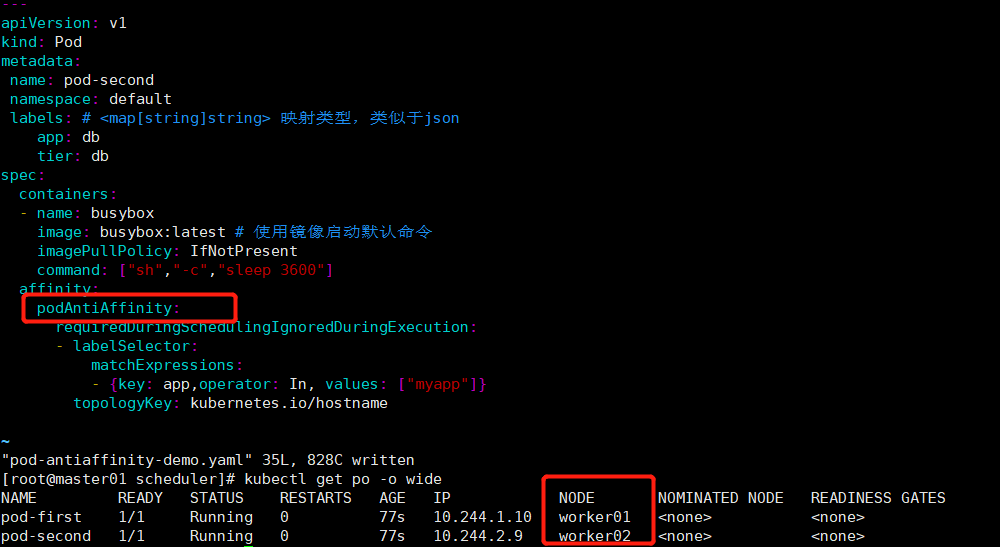
演示节点worker01和worker02在同一个位置(将两个节点定义同一个标签),busybox pod使用反亲和(podAntiAffinity)调度,pod busybox 的topology属性定义的是我们标记worker01和worker02在同一个位置的标签,如果使用requiredDuringSchedulingIgnoredDuringExecution,意味着busybox pod 无节点可以调度,处于pending状态;如果使用preferreddDuringSchedulingIgnoredDuringExecution,虽然两个节点都不满足被调度的要求,但是由于是preferred,busy pod可以勉强被调度到两个节点当中的任意一个上。
kubectl apply -f pod-antiaffinity-demo.yaml
cat podaffinity-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-first
namespace: default
labels: # <map[string]string> 映射类型,类似于json
app: myapp
tier: frontend
spec:
containers:
- name: myapp
image: nginx:1.20 # 使用镜像启动默认命令
---
apiVersion: v1
kind: Pod
metadata:
name: pod-second
namespace: default
labels: # <map[string]string> 映射类型,类似于json
app: db
tier: db
spec:
containers:
- name: busybox
image: busybox:latest # 使用镜像启动默认命令
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions: # 对象列表
- {key: app,operator: In, values: ["myapp"]} # 根据pod的标签做亲和性调度,这里选择调度到标签名为myapp的pod所在的节点上。
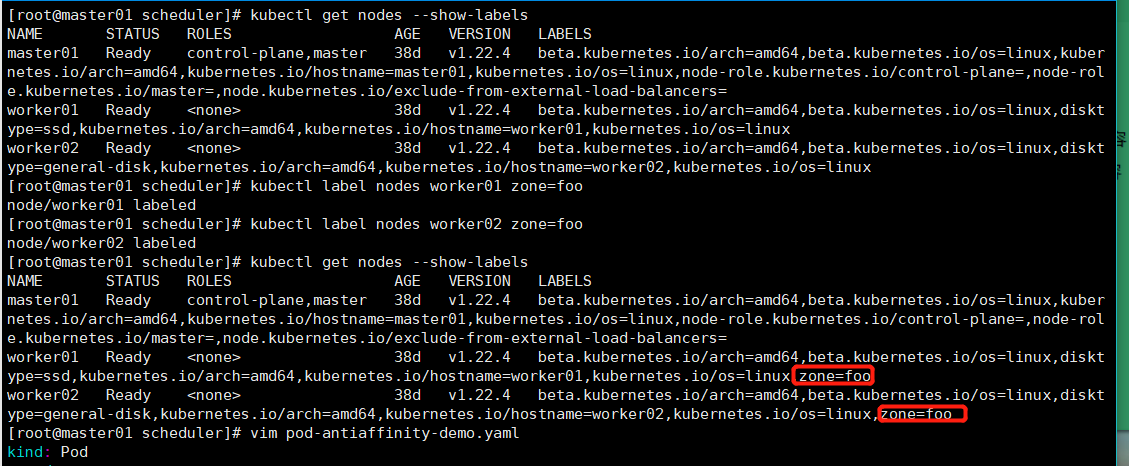
topologyKey: zone # kubectl get po --show-labels
kubectl label nodes worker01 zone=foo
kubectl label nodes worker02 zone=foo
kubectl get nodes --show-labels
kubectl apply -f pod-antiaffinity-demo.yaml
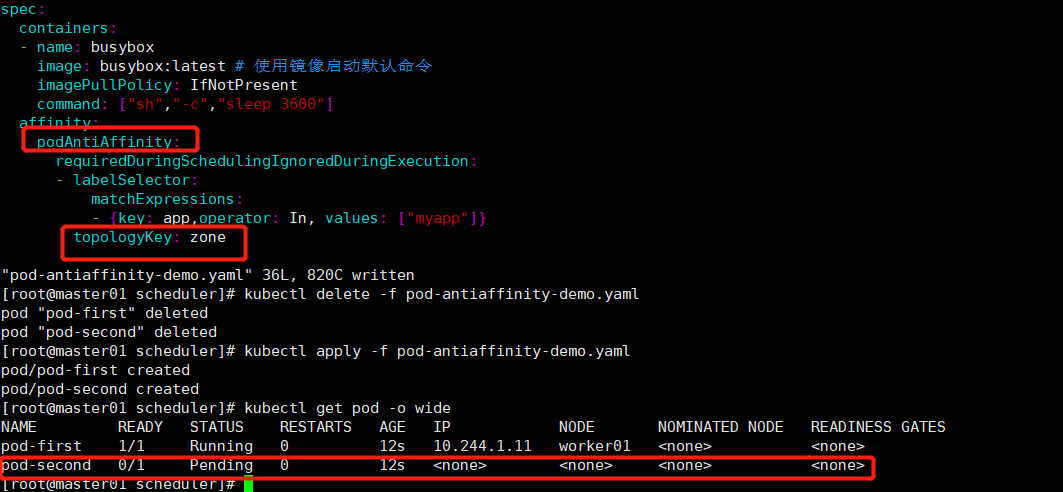
5.taint和toleration
污点就是定义在节点之上的键值属性,键值属性有3类:
1.标签(label):用在任何资源对象之上
2.注解(Annotations):用在任何资源对象之上
3.污点(taint):用在节点之上
tolerations:一个键值列表,定义在pod上,用来表示能够容忍节点之上哪些污点。。
节点亲和性,是pod的一种属性,pod的亲和性也是pod的一种属性,但污点是节点的一种属性。
kubectl get nodes worker01/worker02/master01 -o yaml
kubectl explain nodes.spec
configSource <Object>
externalID <string>
podCIDR <string>
podCIDRs <[]string>
providerID <string>
taints <[]Object>
effect <string> -required-
key <string> -required-
timeAdded <string>
value <string>
unschedulable <boolean>
taint的effect定义对Pod排斥效果:
NoSchedule:仅影响调度过程,对现存的Pod对象不产生影响(调度完成后,node节点上后加的污点对现存的pod没有任何影响。);
NoExecute:不仅影响调度,还影响现存节点上的Pod对象;不容忍的Pod对象将被驱逐;
PreferNoSchedule:pod如果不能容忍节点上的污点,就不能调度到此节点上。但如果实在没找到合适的节点,也可以调度到不能容忍的节点上。
查看网络插件flannel的容忍度:
kubectl get po kube-flannel-ds-4gq2l -n kube-system -o yaml
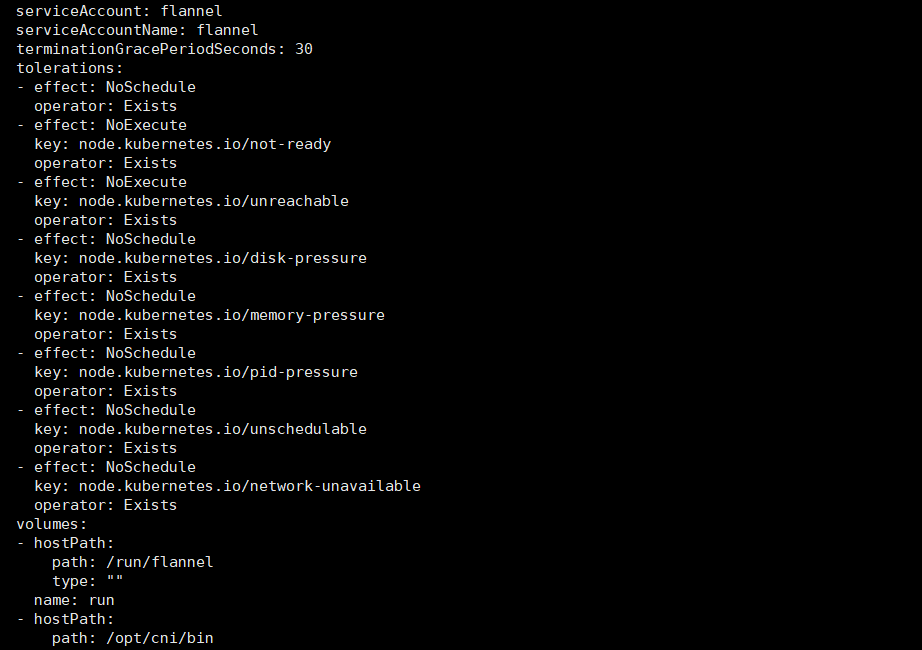
给某个节点标记为污点
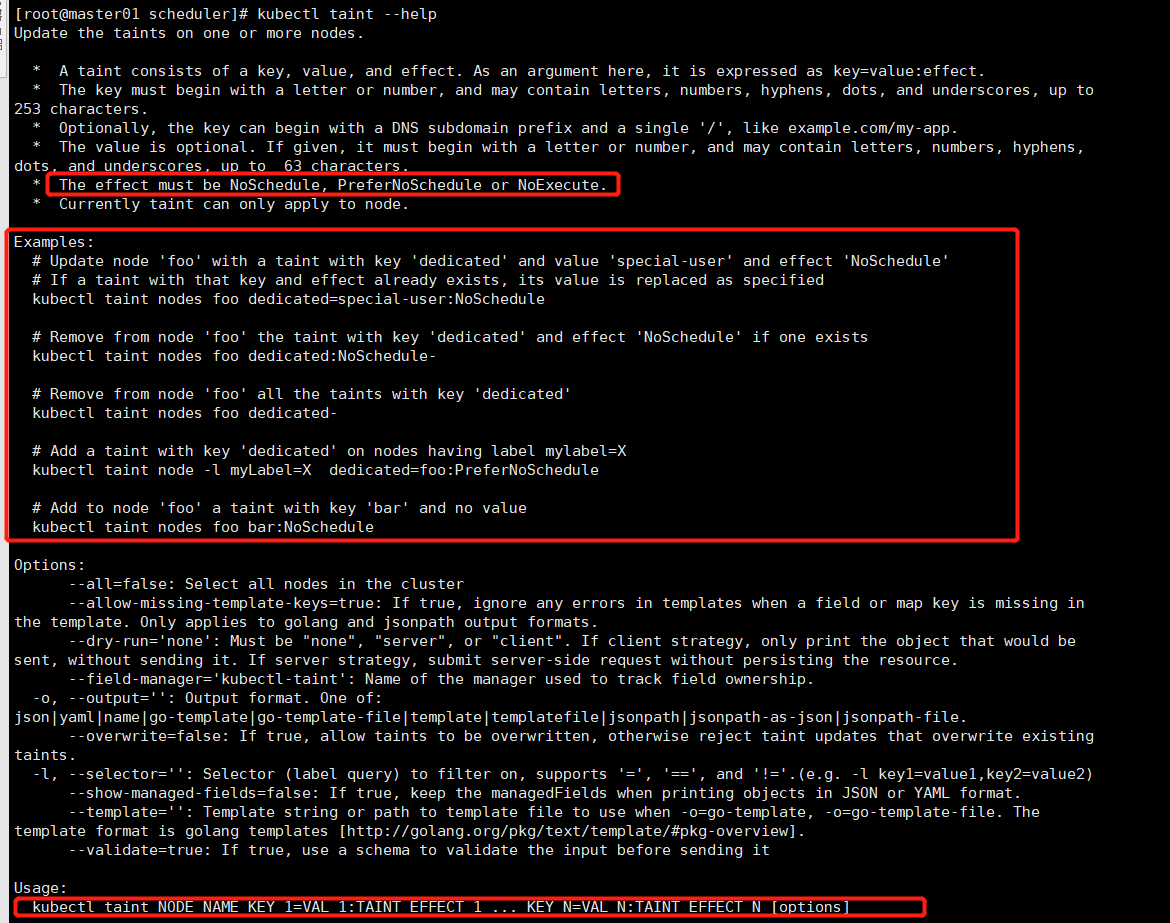
# 图1
kubectl taint NODE NAME KEY_1=VAL_1:TAINT_EFFECT_1 ... KEY_N=VAL_N:TAINT_EFFECT_N [options]
图1:
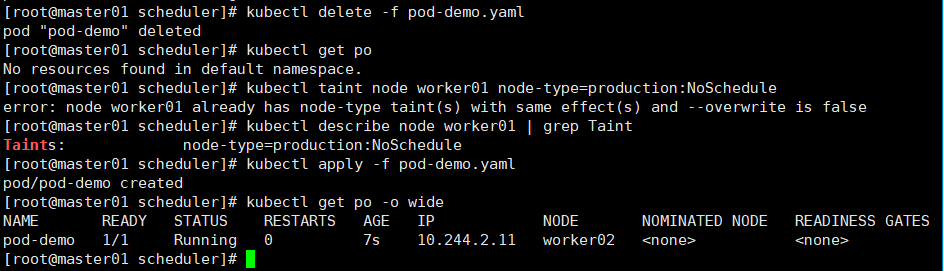
给worker01打上NoSchedule的污点,然后新创建的pod将不能被调度到worker01节点上
kubectl taint node worker01 node-type=production:NoSchedule # 如果新创建的pod没有定义此容忍度,就不能调度到worker01节点上了。
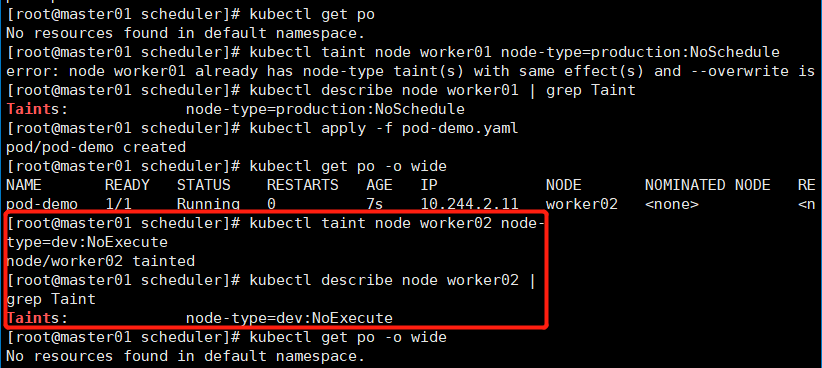
现在给worker02打上NoExecute的污点,然后新创建的pod将不能被调度到worker02节点上,原有在worker02节点上的pod如果没有此容忍度,也将被驱离。
kubectl taint node worker02 node-type=dev:NoExecute # 将worker02节点定义NoExecute污点,如果新创建的pod没有定义此容忍度,就不能调度到worker02节点上了;如果已经运行在worker02节点上的pod也没有此容忍度,那么将会被驱离,调度到下一个合适的节点之上;如果没有合适的节点处于pending状态。。
现在将worker01标上污点NoSchedule,worker02标上污点NoExecute,然后定义pod的tolerarions
kubectl explain pod.spec.tolerations
tolerations <[]Object>
effect <string>
key <string>
operator <string>
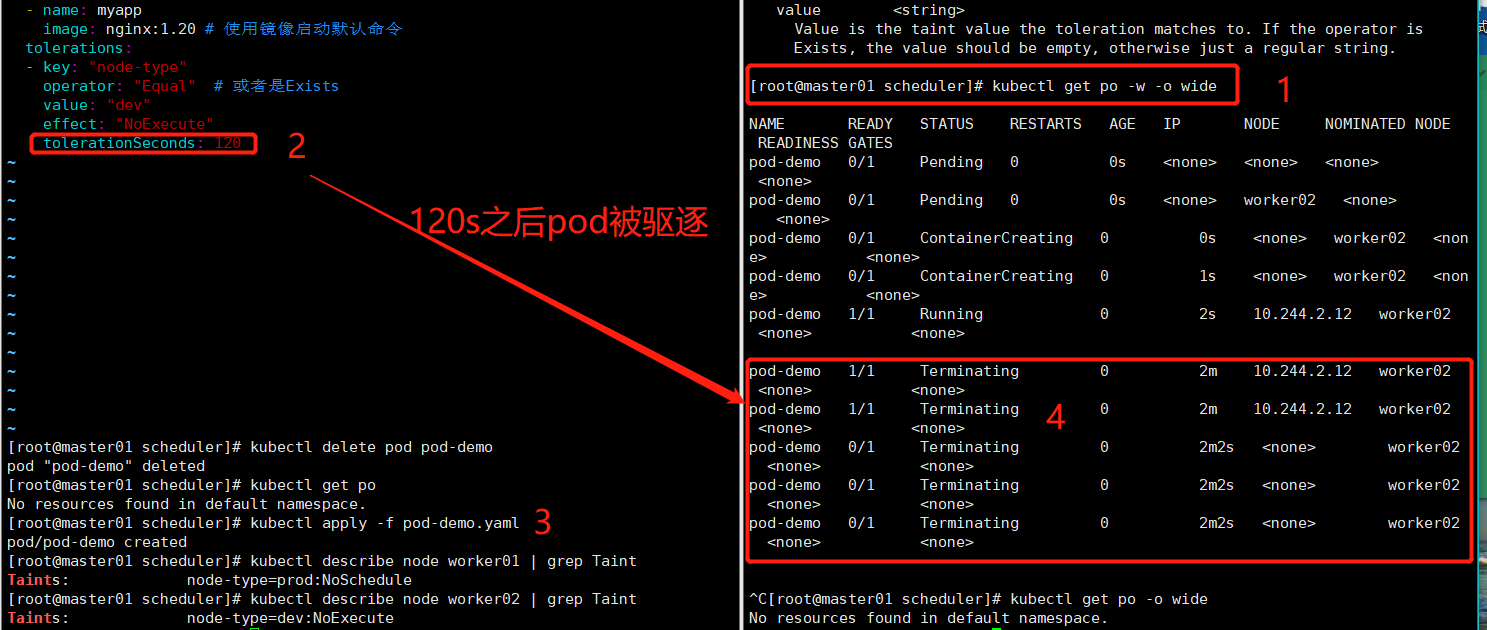
tolerationSeconds <integer> # 定义宽限多长时间之后驱逐,只适合污点为NoExecute的情况
value <string>
operator: Equal/Exists,默认是Equal.
Equal:严格地按照key=value精准匹配
Exists: 只要Node节点上有我们这里定义的key就可以。value可以设置为"",表示可以容忍任何种类的污点(比如)
kubectl taint node worker01 node-type=production:NoSchedule
kubectl taint node worker02 node-type=dev:NoExecute
[root@master01 scheduler]# vim pod-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-demo
namespace: default
labels: # <map[string]string> 映射类型,类似于json
app: myapp
tier: frontend
spec:
containers:
- name: myapp
image: nginx:1.20 # 使用镜像启动默认命令
tolerations:
- key: "node-type"
operator: "Equal" # 或者是Exists
value: "dev"
effect: "NoExecute"
tolerationSeconds: 120
kubectl apply -f pod-demo.yaml
operator: Equal/Exists,默认是Equal.
Equal:严格地按照key=value精准匹配
Exists: 表示Node节点上只要存在这个key这个键,不论value是什么,都能容忍effect.
tolerations:
- key: "node-type"
operator: "Exists" # 或者是Exists
value: ""
effect: "NoExecute"
tolerationSeconds: 120
tolerations:
- key: "node-type"
operator: "Exists" # 或者是Exists
value: ""
effect: "" # 表示节点污点不论是NoSchedule,或者是NoExecute,或者PreferNoSchedule都能容忍
Exists表示只要存在key为node-type,value为任何值,effect为任何类型的污点的节点,pod都能容忍。
kubectl apply -f pod-demo.yaml
删除节点上的污点和标签
kubectl taint node worker02 node-type- # 删除节点上的污点
kubectl label nodes worker01 zone- # 删除节点上标签

 浙公网安备 33010602011771号
浙公网安备 33010602011771号