prometheus-01 部署、配置文件详解
测量什么
在计划度量收集时,必然会出现一个问题,即定义要观察哪些度量。为了回答这个问题,我们应该求助于当前的最佳实践和方法。在下面的主题中,我们将概述一些最具影响力和最受关注的方法,这些方法可以降低噪声,提高性能和一般可靠性方面的可视性。
1.谷歌提出应该监控如下的四个指标:
延迟:服务请求所需的时间
流量:正在发出的请求的数量
错误:请求失败的比率
饱和:未处理的工作量,通常在队列中。
2.brendan的方法更关注于机器,它声明对于每个资源(CPU、磁盘、网络接口等等),应该监视以下指标:
利用率:以资源繁忙的百分比来衡量
饱和:资源无法处理的工作量,通常会排队
错误:发生的错误数量
3.汤姆.威尔基的红色方法
RED方法更侧重于服务级别的方法,而不是底层系统本身。显然,这种策略对于监视服务很有用,对于预测挖补客户的体验也很有价值。如果服务的错误率增加,那么就可以合理地假设这些错误将直接或间接地影响客户的体验。这些是需要注意的度量标准:
速率:转换成每秒请求数
错误:每秒失败请求的数量
持久性:这些请求所花费的时间
prometheus本地存储
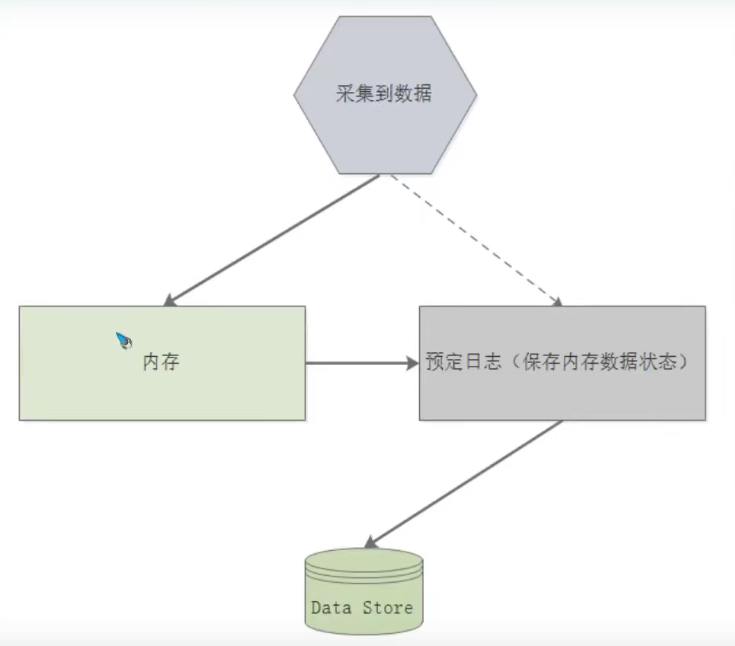
本地存储时在prometheus存储数据的标准方法。在一个非常高的层次上,Prometheus的存储设计是一个索引实现的组合,它使用了所有当前存储的标签及其值得发布列表,以及他自己的时间序列数据格式。
1.数据流:Prometheus在本地存储收集到的数据的方式可以被看作是一个分为三个部分的过程。下面的主题描述了数据在成功持久化之前所经历的各个阶段。
1)最新的一批数据保存在内存中长达两个小时。这包括在两个小时时间窗口期收集的一个或多个数据块。这种方法极大地减少了磁盘IO的两倍;最新的数据存储在内存中,查询速度快的惊人;数据块是在内存中创建的,避免了持续的磁盘写操作。
2)预写日志:
而在内存中,数据不是持久的,如果进程非正常终止,块被写入磁盘。这些块是不可变的,即使数据可以删除,他也不是原子操作的。相反,tombstone文件是用不再需要的数据信息创建的。
2.布局
我们在下面的例子中可以看到,Prometheus中数据的存储方式被组织到一系列的目录(块)中,这些目录(块)包含了数据块,这些数据的levelDB索引就是一个元数据。带有人类可读的关于块的信息的json文件,以及不再需要的数据的tombstone。每个块代表一个数据库。
在顶层,你还可以看到数据没有刷新到自己的数据块的WAL:
...
|---01CZMVW4CB6DCKK8Q33XY%ESQH
| |--- chunks
| | |__000001
| |---index
| |---meta.json
| |---tmbstones
|---01CZNGF9GG10R2P56R9G39NTSJE
| |---chunks
| | |__000001
| |---index
| |---meta.json
| |___tombstones
.....................
.....................
prometheus数据模型
prometheus将数据存储位时间序列,其中包括称为标签的键值对、时间戳和最后的值。下面的主题将对这些组件进行扩展,并提供每个组件的基础知识。
1.表示法
普罗米修斯的时间序列如下:
<metric_name>[{<label_1="value_1">,<label_N="value_N">}] <datapoint<numerical_value>
如下案例:
api_http_requests_total{method="POST",handler="messages"}
如您所见,他表示为一个度量名称,可选地后跟一组或多组花括号内的标签名称/值,然后是度量的值。此外,样本还具有毫秒精度的时间戳。
2.Metric names
尽管这是一个实现细节,度量名称只不过是一个名为"name"的特殊标签的值。因此,如果您在内部有一个名为"beverages_total"的度量,他被表示为"_name=beverages_total"。请记住,被“”包围的标签是普罗米修斯内的,任何以“__”为前缀的标签只在度量收集周期的某些阶段可用。
标签(键/值)和度量名称的组合定义了时间序列的标识。
普罗米修斯中的每一个度量名称都必须符合以下正则表达式:
"[a-zA-Z_:][a-zA-Z0-9_:]*"
只允许英文字母(a-z)、下划线(_)、冒号(:)和阿拉伯数字(0-9)的大小写字母,不允许使用数字的第一个字符除外。
3.Metric Labels
- 标签,或与某个度量相关的键/值对,向度量添加维度。这时普罗米修斯如此擅长对事件序列进行切片和切割的一个重要部分。
- 虽然标签值可以是完整的UTF-8,但标签名称必须与正则表达式匹配才能被认为是有效的;[例如,“- za-z0-9_]*"。
他们在度量名称方面的主要区别是标签名称不允许冒号(😃。
4.Samples
样本是采集的数据点,代表时间序列数据的数值。定义一个实例所需要的组件是一个float64值和一个精确到毫秒的时间戳。需要记住的是,不按顺序收集的样本会被普罗米修斯丢弃。同样的情况也发生在具有相同度量单位和不同样本值得样本上。
指标类型
1.counter:计数,该指标数值只增不减,适合统计网卡收发包的数量和字节数、以及系统正常运行的时间等等。除非重启,不然一直递增。
2.Gauge:测量是一种度量,它在收集时对给定的测量进行快照,可以增加或减少(例如湿度、磁盘空间和内存使用量)
3.Histogram:在大多数情况下人们都倾向于使用某些量化指标的平均值,例如CPU的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统API调用的平均响应时间为例:如果大多数API请求都维持在100ms的响应时间范围内,而个别请求的响应时间需要5s,那么就会导致某些web页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
Histogram常常用于观察,一个Histogram包含下列值得合并:
(1)Buckets:桶是观察的计数器。它应该有个最大值的边界和最小值的边界。他的格式为<basename>_bucket{le="<bound_value>"}
(2)观察结果的和,这是所有观察的和。针对它的格式是<basename>_sum
(3)观察结果统计,这是在本次观察的和。它的格式为<basename>_count
一个普罗米修斯HTTP请求持续时间以秒为单位,分为桶,这是显示在Grafana热图,以更好地说明桶的概念:
4.Summaries:与Histogram类型类似,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间来计算。
指标摘要
通常来说,单个指标对我们价值很小,往往需要联合并可视化多个指标,这其中需要一些数学变换,例如,我们可能会统计函数应用用于指标或只标组,一些可能应用常见函数包括:
计数:计算特定时间间隔内的观察点数。
求和:将特定时间间隔内所有观察的值累计相加。
平均值:提供特定时间间隔内所有值的平均值。
中间数:数值的集合中点,正好50%的数值位于它前面,而另外50%则位于它后面。
百分位数:度量占总数特定百分比的观察点的值。
标准差:显示指标分布中与平均值的标准差,这可以测量出数据集的差异程度。标准差为0表示数据都等于平均值,较高的标准差意味着数据分布的范围很广。
变化率:显示时间序列中数据之间的变化程度。
指标聚合
除了上述的指标摘要外,可能经常希望能看到来自多个源的指标的聚合视图,例如所有应用程序服务器的磁盘空间使用情况。指标聚合最典型的样式就是在一张图上显示多个指标,这有助于你识别环境的发展趋势。例如,负载均衡器中的间歇性故障可能导致多个服务器的web流量下降,这通常比通过查看每个单独的指标更容易发现。
prometheus安装和部署
1.Prometheus二进制安装
去清华源下载二进制包,本实验使用的是: prometheus-2.31.1.linux-amd64.tar.gz
Prometheus二进制包文件的组织架构:
1.前期准备工作
1)各个主机的DNS解析正确,时间同步。
2)克隆项目
2.安装prometheus
1)创建新的系统用户
useradd --system prometheus
2)解压tar包,并把每个文件放到正确目录
tar xvf prometheus-2.31.1.linux-amd64.tar.gz
mkdir -pv /usr/share/prometheus/consoles
install -m 0644 -D -t /usr/share/prometheus/consoles prometheus-2.31.1.linux-amd64/consoles/*
mkdir -p /usr/share/prometheus/consoles_libraries
install -m 0644 -D -t /usr/share/prometheus/consoles_libraries prometheus-2.31.1.linux-amd64/console_libraries/*
install -m 0755 prometheus-2.31.1.linux-amd64/promtool /usr/bin/
install -m 0755 prometheus-2.31.1.linux-amd64/prometheus /usr/bin/
install -d -o prometheus -g prometheus /var/lib/prometheus
vim prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
rule_files:
- "first_rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets:
- 'prometheus:9090'
- job_name: 'node'
static_configs:
- targets:
- 'prometheus:9100'
- 'grafana:9100'
- 'alertmanager:9100'
- job_name: 'grafana'
static_configs:
- targets:
- 'grafana:3000'
- job_name: 'alertmanager'
static_configs:
- targets:
- 'alertmanager:9093'
vim prometheus.service
# vim:ser ft=systemd
[Unit]
Description=The Prometheus monitoring system and time series database.
Documentation=https://prometheus.io
After=network.target
[Service]
User=prometheus
LimitNOFILE=8192
ExecStart=/usr/bin/prometheus \
--config.file=/etc/prometheus/prometheus.yml \
--storage.tsdb.path=/var/lib/prometheus/data \
--web.console.templates=/usr/share/prometheus/consoles \
--web.console.libraries=/usr/share/prometheus/console_libraries
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
vim first_rules.yml
groups:
- name: example.rules
rules:
- alert: ExampleAlert
expr: vector(42)
labels:
severity: "critical"
annotations:
description: Example alert is firing.
link: http://example.com
install -m 0644 -D prometheus.yml /etc/prometheus/prometheus.yml
install -m 0644 -D first_rules.yml /etc/prometheus/first_rules.yml
install -m 0644 -D prometheus.service /etc/systemd/system/
systemctl daemon-reload
systemctl start prometheus # 或者用prometheus命令:prometheus --config.file=/etc/prometheus.yml
systemctl status prometheus
systemctl enable prometheus
ss -lnt # prometheus监听在9090端口
2.Prometheus容器安装
1.docker的安装推荐方式
prometheus镜像存储Docker Hub
如果知识简单的运行: docker run -p 9090:9090 prom/prometheus 那么只是使用简单的配置文件,并把它导出为9090端口来运行的。
prometheus镜像使用一个卷存储实际的度量。针对生产环境来讲,强烈建议使用基于数据卷的容器。
2.如果向使用自己的配置,可以有以下两种方式:
2.1 卷绑定挂载
(1)使用卷启动时就挂载(我用的是这种方法)
docekr run -p 9090:9090 -v ~/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
(2)针对配置或者使用其它的卷
docker run -p 9090:9090 -v /path/to/config:/etc/prometheus prom/prometheus
2.2 自定义镜像
为了比卖你管理主机上的文件并绑定挂载它,可以将配置嵌入到映像中。如果配置本身是静态的,并且在所有环境中都是相同的,那么这种方法就可以很好地工作。
(1)创建Dockerfile文件内容如下所示:
FROM:prom/prometheus
ADD prometheus.yml /etc/prometheus
(2)执行构建
docker build -t my-prometheus .
docker run -p 9090:9090 my-prometheus
通过docker-compose 管理容器
1.安装docker-compose
直接去阿里镜像站下载,那里提供了有关docker的工具包(docker toolbox:docker machine/docker compose/Docker Client/Docker Kitematic
VirtualBox)二进制包,包括docker compose,地址:https://developer.aliyun.com/mirror/docker-toolbox?spm=a2c6h.13651102.0.0.25e31b11yICXdm
# 安装方法:
1.此包就是二进制,并没有压缩,直接下载相应版本docker-compose二进制就行了。
2.执行以下命令:
mv docker-compose-Linux-x86_64 /usr/local/docker-compose # 重命名
ln -s /usr/local/docker-compose /usr/bin/docker-compose
chmod a+x /usr/local/docker-compose
chmod a+x /usr/bin/docker-compose
3. docker-compose -v # 检查docker-compose版本
2.编写docker-compose.yml
version: '3'
networks:
monitor: # 创建一个名称为monitor的网络,使用的驱动为--driver=bridge; docker network ls。但在启动容器时会将网络名称修改为第一个容器名称+_monitor
driver: bridge
services:
prometheus:
image: prom/prometheus
container_name: prometheus
hostname: prometheus
user: root
restart: always
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- ./rules:/etc/prometheus/rules
- /prometheus-data:/promtheus # bind volume方式,将prometheus容器内数据库文件挂载到宿主机,不然默认挂载路径可以通过docker inspect prometheus查看,/var/lib/docker/volumes/..../_data/
ports:
- "9090:9090"
networks:
- monitor
docker-compose up -d # 启动docker-compose.yml文件定义所有docker容器
docker-compose down # 停止所有容器
docker-compose start service # 启动某个容器,前提是此容器已经被创建了
docker-compose restart service # 重启
docker-compose kill service #杀死某个容器
docker-compose -h # 查看docker-compose命令使用选项
prometheus配置
1.配置prometheus去监控它自身
prometheus通过收集这些目标上的HTTP断点数据来收集被监控目标的数据。因为普罗米修斯也会以同样的方式暴露自己的数据,所以它也可以收集可监控自己的健康状况。
# 配置prometheus.yml文件
global:
scrape_interval: 15s
external_labels:
monitor: 'codelab-monitor'
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
prometheus配置命令详解
prometheus配置主要有两种方式:
1.直接采用命令行加选项及参数的形式运行;
2.把选项和参数放入到一个配置文件中运行;
prometheus可以在运行时重新加载配置。如果新配置不是有效的配置,则不会应用更改。通过向Prometheus进程发送SIGHUP或向/-/reload 端点发送HTTP POST请求来触发配置重新加载。这还将重新加载。这还将重新加载任何已配置的规则文件。
1.Prometheus启动配置

1.1 config
通常首先通过 --config.file选项要设置的是普罗米修斯配置文件路径。默认Prometheus启动命令会在在当前目录查找Prometheus.yml文件。
1.2 storage
--storage.tsdb.path指定数据存储的路径。默认的存储当前目录中的/data目录。
1.3 web
--web.external-url 选项指定Prometheus服务器的URL地址。
--web.enable-admin-api选项启用的话,那么就可以通过HTTP端点执行一些高级管理操作。比如创建数据快照,删除时间序列数据。
1.4 query
如何调优查询引擎的内部工作方式。有些非常容易理解,比如给定的查询在终止之前可以运行多长时间(--query.tumeout),或者可以并发查询多少(--query.max-concurrency)
2.prometheus配置文件概览
我们可以把配置文件拆分成如下部分:
global
scrape_configs
alerting
rule_files
remote_read
remote_write
3.全局配置案例
全局配置指定所有其它配置上下文中有效的参数。它们还可以作为其他配置部分的默认值。
global:
scrape_interval: 1m # 抓取度量时间的间隔值,通常10秒-1分钟之间
scrape_timeout: 10s #设置采取度量的等待时间
evaluation_interval: 1m
external_labels: # 给数据打上标签
dc: dc1
prom: prom1
# ==================================================================================
1.scrape_interval: <duration> | default =1m:抓取度量的间隔值,默认值为1分钟
2.[scrape_timeout: <duration> | default = 10s ]:设置抓取度量值的超时时间。
3.[ evaluation_interval: <duration> | default = 1m]:评估警告的间隔,往往和scrape_interval一样的。
4.external_labels:
[ <labelname>: <labelname> ... ] :当和外部系统(联绑,远端存储,AlertManager)通信时,添加到时间序列数据或警告的标签。
5. [ query_log_file:<strins>]:PromQL查询记录
4.scrape的配置案例
该配置主要指定在收集度量的目标,间的地说,就是采集哪些服务上的值。
配置案例如下所示:
# The job name assigned to scraped metrics by default.
job_name: <job_name>
# How frequently to scrape targets from this job.
[ scrape_interval: <duration> | default = <global_config.scrape_interval> ]
# Per-scrape timeout when scraping this job.
[ scrape_time: <duration> | default = <global_config.scrape_timeout> ]
# The HTTP resource path on whuch to fetch metrics from targets.
[ metrics_path: <path> | default = /metrics ]
# Configures the protocol scheme used for requests.
[ scheme: <scheme> | default = http ]
# Optional HTTP URL parameters.
params:
[ <string>: [<string>,...] ]
# Sets the 'Authorization' header on every scrape request with the configured username and password. password and password_file are mutually exclusive.
basic_auth:
[ username: <string> ]
[ password: <secret> ]
[password_file: <string>]
5.标签的分类
标签基本可以分为拓扑标签和模式标签:
1.拓扑标签:通过物理或逻辑组成来切割服务组件。比如Job的名称,在那个数据中心等等。
2.模式标签是url,错误代码或user。
6.prometheus的relabel_configs的理解
重新标记是个强大的工具,可以在目标的标签集被抓取之前俺动态地重写它。每隔刮擦配置可以配置多个重新标记步骤。他们按在配置文件中出现的顺序应用于每隔目标的标签集。
最初,除了为每隔目标配置的标签外,还将目标的job标签设置为各个刮取配置的job_name值。比如__address__标签设置为目标的
以__开头的标签将在目标重新贴标签完成后从标签集中移除。
如果重新标记步骤只需要临时存储标签值,使用__tmp的标签前缀,这个前缀保证普罗米修斯自己永远不会使用。
# The source labels select values from existing labels. Their content is concatenated using the configured separator and matched against the configured regular expression for the replace,keep,and drop action.
[ source_labels: '[' <labelname> [,...] ']' ]
# Sepatator placed between concatenated source label values.
[ separator: <string> | default = ; ]
# Label to which the resulting value is written in a replace action. It is mandatory for replace actions. Regex capture groups are available.
[ target_label: <labelname> ]
# Regualr expression against which the extrected value is matched.
[ regex: <regex> | default = (.*) ]
# Modulus to take of the hash of the source label values.
[ modulus: ,uint64> ]
# Replacement value againt which a regex replace is performed if the regular expression matches. Regex capture groups are available.
[ replacement: <string> | default = $1 ]
# Action to perform based on regex matching.
[ action: <relabel_action> | default = replace ]
<relable_action>决定着重新标记的动作。
replace:将regex与source_labels进行匹配,如果匹配,那么设置target_label为replacement,如果正则表达式不匹配,那么就不执行动作。
keep:针对正则表达式不匹配source_labels的目标,就丢弃。
drop:针对正则表达式匹配的source_labels的目标,就丢弃。
labeldrop:将regex与所有标签匹配。任何匹配的标签都将从标签集中删除。
labelkeep:将regex与所有标签名匹配。任何不匹配的标签将从标签集中删除。
如果没有定义action,那么默认的就是replace。
我们有两个阶段可以重新标记。第一阶段是对来自服务发现的目标进行重新标记,这是对于来自服务发现的元数据标签中的信息应用于指标上的标签来说非常有用。第二阶段是抓取指标之后但是在存储系统之前。这样就可以确定哪些指标需要保存,哪些需要丢弃以及这些指标的样式。
抓取之前使用relabel_configs,抓取之后使用metrics_relabel_configs.
使用案例
1.丢弃不需要的度量值
2.丢弃不需要的时间序列(带有特定变量的度量值)
3.丢弃敏感或者某些不想含有某些标签的度量值。
4.修改最终的标签格式
在实现这些场景时,Prometheus将在数据被社区和永久存储之前对这些数据应用一些逻辑。
1.丢弃不需要的度量
- job_name: cadvisor
...
metric_relabel_configs:
- source_labels: [__name__]
regex: '(container_tasks_state|container_memory_failure_total)'
action: drop
他将使带有名称container_tasks_state和container_memory_failure_total的metric完全删除,并且不会存储在数据库中,而__name__针对metric名称的保留的。
2.丢弃不需要的时间序列
- job_name: cadvisor
...
metric_relabel_configs:
- source_labels: [id]
regex: '/system.slice/var-lib-docker-containers.*-shm.mount'
action: drop
- source_labels: [container_label_JenkinsId]
regex: '.+'
action: drop
丢弃所有含有标签对id='/system.slice/var-lib-docker-containers.*-shm.mount'或者标签container_label_JenkinsId的时间序列。如果它属于一个单一的度量,这就没有必要了。他将适用于所有具有预定义标签集的指标。这可能又有助于避免不必要的垃圾对指标数据的污染。对于container_label_JenkinsId,当您让Jenkins在Docker容器中运行从服务器,并且不希望他们打乱底层主机容器指标(例如Jenkins服务器容器本身、系统容器等)时,这一点特别有用。
3.丢弃敏感或者不想要的某些标签的度量
- job_name: cadvisor
...
metric_relabel_configs:
- regex: 'container_label_com_amazonaws_ecs_task_arn'
action: labeldrop
这个代码端将中删除名称为container_label_com_amazonaws_ecs_task_arn的标签。当处于安全原因不希望普罗米修斯记录敏感数据时,这是非常有用的。在我的例子中,我宁愿不存储AWS资源标识符,因为我甚至不需要它们。注意,在删除标签时,您需要确保标签删除后的最终指标仍然是唯一标记的,并且不会导致具有不同值得重复时间序列。
4.修改最终得标签格式
- job_name: cadvisor
...
metric_relabel_configs:
- source_labels: [image]
regex: '.*/(.*)'
replacement: '$1'
target_label: id
- source_labels: [service]
regex: 'ecs-.*:ecs-([a-z]+-*[a-z]*).*:[0-9]+'
replacement: '$1'
target_label: service
有两个规则执行。第一个拿有含有image标签名得度量,且匹配./(.),把它放到新标签id得最后面。比如:
container_memery_rss{image="quiq/logspout:20170306"}就会变成 container_memery_rss{id="logspout:20170306"}。
第二条规则解析容器名称,默认情况下,ECS-agent在AWS ECS实例上创建容器名称,并提取其可识别得服务名称,并将其放入服务标签中。通过这种方式,您可以使用人类可读的容器服务名称进行操作。

