Linux03 重定向,管道,文件查找(grep)
重定向(>、>>、&>、&>>、2>、2>>、<、 <<)
计算机组成:
运算器、控制器:CPU
存储器:RAM
输入设备/输出设备
程序:指令和数据
控制器:指令
存储器:
地址总线:内存寻址
数据总线:传输数据
控制总线:控制指令
寄存器:CPU暂时存储器
I/O:硬盘
程序
INPUT设备:
OUTPUT设备:
系统设定:
默认输出设备:标准输出,STDOUT,1
默认输入设备,标准输入,STDIN,0
标准储物输出:STDERR,2
标准输入:键盘
标准输出和错误输出:显示器
I/O重定向:改变了数据的输入和输出的来源,这种操作就叫做重定向。对于Linux而言,输出重定向用‘>’,输入重定向用‘<’。
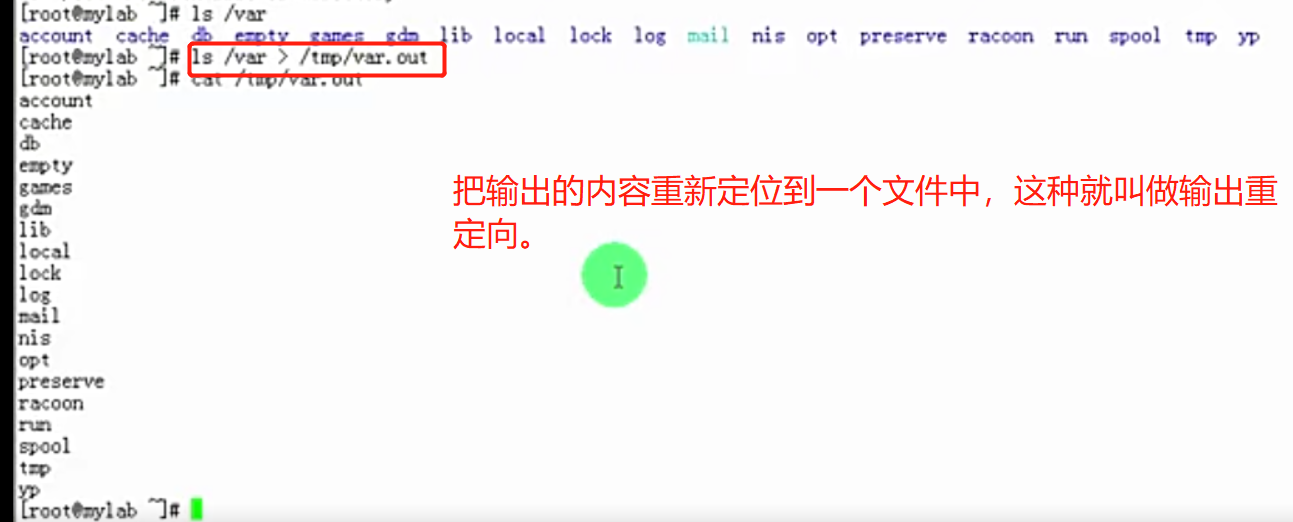
# 输出重定向:
>:使用一个>输出重定向,它会覆盖目标文件中原来的内容;这种叫做覆盖输出;
>>:追加输出
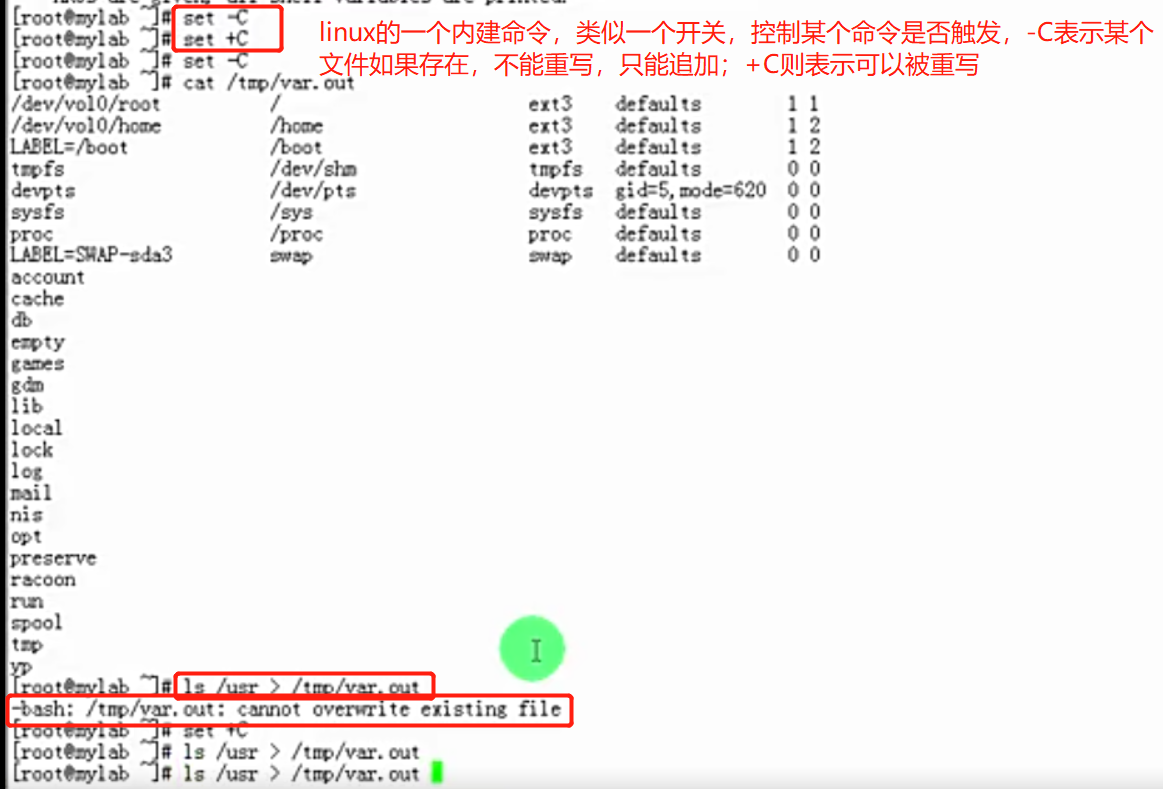
set -C:禁止对已经存在文件使用覆盖重定向;
强制覆盖输出,则使用 ‘ >| ’ 。
set +C:关闭上述功能
2>:重定向错误输出,正确输出仍然显示在屏幕上。
2>>:追加方式重定向错误输出,正确输出仍然显示在屏幕上。
同时定义标准输出和错误输出:
ls /varr > /tmp/var.out 2> /tmp/var.out # 无论是正确输出还是错误输出,都不会显示在屏幕上,全部重定向到/tmp/var.out文件中去。
&> : 重定向标准输出或错误输出至同一个文件(使用这一个符号就可以代替同时使用 >和2> 符号输出的结果。)
&>>: 追加的方式重定向标准输出或错误输出至同一个文件
ls /varr &>> /tmp/var.out # 等价于 ls /varr > /tmp/var.out 2> /tmp/varr.out
# 输入重定向
<:输入重定向
<<:Here Document(表示在此处生成文档)
输出重定向:


输入重定向:



如何将标准输出即显示到屏幕又在文件中保存一份?
tee: # read from standard input and write to standard output and files
echo "Hello,World." | tr 'a-z' 'A-Z' | tee /tmp/hello.out # 输出到屏幕的“hello ,world.”是tee完成的,这里可不是echo.

管道
管道:前一个命令的输出,作为后一个命令的输入。
命令1 | 命令2 | 命令3 | ...
echo "hello,world." | tr 'a-z' 'A-Z'
echo "redhat" | passwd --stdin hive # 修改当前用户登录密码
echo cut -d: -fl /etc/passwd | sort | tr 'a-z' 'A-Z'
wc -l /etc/passwd | cut -d' ' -f1
小练习:
1. 统计/usr/bin/目录下的文件个数;
# ls /usr/bin/ | wc -l
2. 取出当前系统上所有用户的shell,要求:每种shell只显示一次,并且按顺序进行显示;
# cut -d: -f7 /etc/passwd | sort | sort -u
3. 思考:如何显示/var/log目录下每个文件的内容类型?
# file /var/log/*
4. 取出/etc/inittab文件的第6行;
# head -6 /etc/inittab | tail -1
5.取出/etc/passwd文件中倒数第9个用户名和shell,显示到屏幕上并将其保存至/tmp/users文件中;
# tail -9 /etc/passwd | head -1 | cut -d: -f1,7 | tee /tmp/users
6. 显示/etc目录下所有以pa开头的文件,并统计其个数;
# ls -d /etc/pa* | wc -l
7. 不使用文本编辑器,将alias cls=clear一行内容添加至当前用户的.bashrc文件中;
echo "alias cls=clear" >> ~/.bashrc
grep(Global Reseearch )
grep:根据模式,搜索文本,并将符合模式的文本行显示到屏幕上来。只支持基本正则表达式定义的模式来过滤文本的命令。
Pattern:由文本字符和正则表达式的元字符组合 而成匹配条件。
grep [options] PATTERN [FILE...]
基本正则表达式
-i: # 表示在查找的时候忽略大小写
--color: # 将要查找的内容,以高亮的方式显示出来
-v: # 显示没有被模式匹配的行
-o: # 只显示被模式匹配的串,行中的其他字符不显示
-c: # 统计某一字符串的个数
ps aux | grep -c nginx # 统计出现nginx字符串的个数
# 扩展的表达式
-E:使用扩展正则表达式
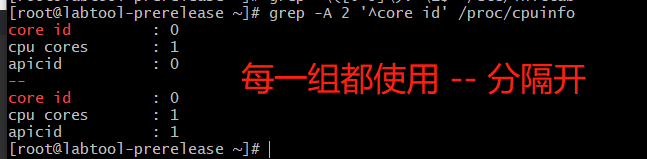
-A(after) 数字:表示grep匹配到当前这一行,不仅显示当前这一行,还会显示当前行下面的几行(根据-A后面的数字决定显示几行)
eg:
grep -A 2 '^core id' /proc/cpuinfo
-B(before):表示grep匹配到当前这一行,不仅显示当前这一行,还会显示当前行上面的几行(根据-A后面的数字决定显示几行)
-C(context):表示grep匹配到当前这一行,不仅显示当前这一行,还会显示当前行上面和下面的几行(根据-A后面的数字决定显示几行)
正则表达式:REGular EXPression,REGEXP
元字符:
.:匹配任意单个字符
[]:匹配指定范围内的任意单个字符
[^]:匹配指定范围外的任意单个字符
字符集合:[:digit:],[:lower:],[:upper:],[:punct:],[:space:],[:alpha:],[:alnum:]
eg:
grep '[[:digit:]]$' /etc/inittab
grep '[[:space:]][[:digit:]]$' /etc/inittab
匹配次数(贪婪模式,尽量往多的个数匹配):
*:匹配其前面的字符任意次
a,b,ab,aab,acb,adb,amnb
a*b:能匹配-->ab,aab
a.*b:这里的*匹配的是. 而.又代表任意字符,所以a.*b表示是匹配以a开头,b结尾,中间是任意个数的任意字符; -->ab,aab,acb,adb,amnb # grep 'a.*b' test.txt
.*:任意长度的任意字符
\?:匹配其前面的字符1次或0次
a?b --> b,ab,aab,acb,adb,amnb # grep 'a\?b' test.txt
\{m,n\}:前面加反斜杠的作用是转义,不加的话,会被bash识别为花括号展开;表示匹配其前面的字符至少m此,至多n次。
\{1,\}:表示至少1次;
\{1,3\}:至少1次,最多3次
eg:
grep 'a\{1,3\}b' test.txt 表示匹配a至少1次,对多3次
grep 'a.\{1,3\}b' test.txt # 表示在a和b中间匹配任意字符至少1次,最多3次。
位置锚定:
^:锚定行首,此字符后面的任意内容必须出现在行首
eg:
grep '^r' /etc/inittab
$:锚定行尾,此字符前面的任意内容必须出现在行尾
eg:
grep 'w$' /etc/inittab
grep '^r..h$' /etc/inittab
^$: 匹配空白行
eg:
grep '^$' /etc/inittab | wc -l
\<或\b: 其后面的任意字符必须作为单词首部出现
\>或\b: 其前面的任意字符必须作为单词的尾部出现
\<root\>:表示root这个单词既不作为词首出现,也不作为词尾出现,必须作为整个单词出现。
分组:
\(\)
\(ab\)*:表示ab可以匹配无数次
eg:
grep "\(ab\)*" test.txt
后向引用:
\1:第一个左括号以及与之对应的右括号所包括的所有内容
\2:第二个左括号以及与之对应的右括号所包括的所有内容
\3:第三个左括号以及与之对应的右括号所包括的所有内容
eg:
grep '\(l..e\).*\1' test3.txt
grep '\([0-9]\).*\1$' /etc/inittab

\b:
后向引用:

扩展正则表达式:
扩展正则表达式
字符匹配(同基本正则表达式):
.
[]
[^]
次数匹配:
*:
?(不需要反斜杠了):
*:匹配其前面的字符至少一次
{m,n}:
位置锚定:
^
$
\<
\>
分组:
():分组
\1,\2,\3,...
或者
|:or
C|cat: Cat或cat,C或cat
grep -E=egrep (扩展表达式)
. : 如果匹配点本身,不让它匹配其前面任意单个字符,则可以在.前面加一个反斜杠,即"\.",这样就是匹配"."本身。
fgrep:不支持正则表达式

小练习:
1. 显示所有以数字结尾且文件名中不包含空白的文件:
ls *[^[:space:]]*[0-9]
2. 找出/boot/grub/grub.conf文件中1-255之间的数字:
\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>
ifconfig | egrep --color '\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>'
ifconfig | egrep --color '(\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.){3}\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>'
3. 匹配三类网址:
IPV4:
5类:A,B,C,D,E
A: 1-127
B: 128-191
C: 192-223
ifconfig | egrep --color '/<([1-9]|[1-9][0-9]|1[0-9]{2}|2[01][0-9]|22[0-3])\>(\.\<([1-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-4])\>){2}\.\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-4])\>'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号