Redis缓存的使用和优化
一 缓存的收益与成本
1.1 受益
1 加速读写
2 降低后端负载:后端服务器通过前端缓存降低负载,业务端使用redis降低后端mysql负载
1.2 成本
1 数据不一致:缓存层和数据层有时间窗口不一致,和更新策略有关
2 代码维护成本:多了一层缓存逻辑
3 运维成本:比如使用了Redis Cluster
1.3 使用场景
1 降低后端负载:对高消耗的sql,join结果集/分组统计的结果做缓存
2 加速请求响应:利用redis优化io响应时间
3 大量写合并为批量写:如计数器先redis累加再批量写入db
二 缓存更新策略
1 LRU/LFU/FIFO算法剔除:例如maxmemory-policy(到了最大内存,对应的应对策略)
LRU -Least Recently Used,没有被使用时间最长的
LFU -Least Frequenty User,一定时间段内使用次数最少的
FIFO -First In First Out
LIRS (Low Inter-reference Recency Set)是一个页替换算法,相比于LRU(Least Recently Used)和很多其他的替换算法,LIRS具有较高的性能。这是通过使用两次访问同一页之间的距离(本距离指中间被访问了多少非重复块)作为一种尺度去动态地将访问页排序,从而去做一个替换的选择
配置文件中设置:
# LRU配置 maxmemory-policy:volatile-lru (1)noeviction: 如果内存使用达到了maxmemory,client还要继续写入数据,那么就直接报错给客户端 (2)allkeys-lru: 就是我们常说的LRU算法,移除掉最近最少使用的那些keys对应的数据,ps最长用的策略 (3)volatile-lru: 也是采取LRU算法,但是仅仅针对那些设置了指定存活时间(TTL)的key才会清理掉 (4)allkeys-random: 随机选择一些key来删除掉 (5)volatile-random: 随机选择一些设置了TTL的key来删除掉 (6)volatile-ttl: 移除掉部分keys,选择那些TTL时间比较短的keys# LFU配置 Redis4.0之后为maxmemory_policy淘汰策略添加了两个LFU模式: volatile-lfu:对有过期时间的key采用LFU淘汰算法 allkeys-lfu:对全部key采用LFU淘汰算法 # 还有2个配置可以调整LFU算法: lfu-log-factor 10 lfu-decay-time 1 # lfu-log-factor可以调整计数器counter的增长速度,lfu-log-factor越大,counter增长的越慢。 # lfu-decay-time是一个以分钟为单位的数值,可以调整counter的减少速度
2 超时剔除:例如expire,设置过期时间
3 主动更新:开发控制生命周期
| 策略 | 一致性 | 维护成本 |
|---|---|---|
| LRU/LIRS算法剔除 | 最差 | 低 |
| 超时剔除 | 较差 | 低 |
| 主动更新 | 强 | 高 |
1 低一致性:最大内存和淘汰策略
2 高一致性:超时剔除和主动更新结合,最大内存和淘汰策略兜底
三 缓存粒度控制
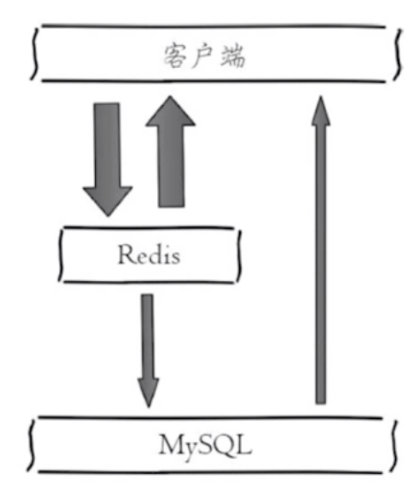
1 从mysql获取用户信息:select * from user where id=100
2 设置用户信息缓存:set user:100
select * from user where id=1003 缓存粒度:
缓存全部属性
缓存部分重要属性
1 通用性:全量属性更好
2 占用空间:部分属性更好
3 代码维护:表面上全量属性更好
四 缓存穿透,缓存击穿,缓存雪崩
通过布隆过滤器避免缓存穿透
### 缓存穿透
#描述:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
#解决方案:
1 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
2 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
3 通过布隆过滤器实现
### 缓存击穿
#描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
#解决方案:
设置热点数据永远不过期。
### 缓存雪崩
#描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至宕机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
# 解决方案:
1 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
2 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
3 设置热点数据永远不过期。
缓存雪崩、击穿、穿透具体讲解:https://www.zhihu.com/question/351019352

 浙公网安备 33010602011771号
浙公网安备 33010602011771号