面向对象之继承
1、下面这段代码的输出结果将是什么?请解释。
class Parent(object):
x = 1
class Child1(Parent):
pass
class Child2(Parent):
pass
print(Parent.x, Child1.x, Child2.x)
'''
1 1 1
'''
# 父类Parent名称空间有属性x,顾访问的是自己的x;子类Child1和Child2名称空间都没有属性x,故去父类Parent中找属性x,所以结果为....
Child1.x = 2
print(Parent.x, Child1.x, Child2.x)
'''
1 2 1
'''
#Child1中的名称空间中添加了属性x,故Child1首先去自己的名称空间中找属性x,所以.....Parent和Child2仍然找的是Parent名称空间中的x。
Child1.x = 2
Parent.x = 3
print(Parent.x, Child1.x, Child2.x)
'''
3 2 3
'''
# Child1自己名称空间有属性x,首先查找的是自己的名称空间的x,而父类Parent修改了自己名称空间的x,继承了该类的子类及其对象都能感知到,所以....
2、多重继承的执行顺序,请解答以下输出结果是什么?并解释。
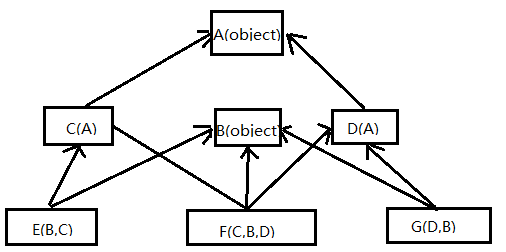
class A(object): # 显式地继承了object类,不论是Python2还是Python3都是新式类
def __init__(self):
print('A')
super(A, self).__init__()
class B(object):
def __init__(self):
print('B')
super(B, self).__init__()
class C(A):
def __init__(self):
print('C')
super(C, self).__init__()
class D(A):
def __init__(self):
print('D')
super(D, self).__init__()
class E(B, C):
def __init__(self):
print('E')
super(E, self).__init__()
class F(C, B, D):
def __init__(self):
print('F')
super(F, self).__init__()
class G(D, B):
def __init__(self):
print('G')
super(G, self).__init__()
if __name__ == '__main__':
g = G()
f = F()
'''
这是经典类的菱形继承问题,广度优先(即一条分支一条分支的查找,最后访问顶级类), 类加括号调用会自动触发类中__init__函数。
类G加括号调用属性查找顺序为:G->D->B->A->object
类F加括号调用属性查找顺序为:F->C->B->->D->A->object
'''
3、什么是新式类,什么是经典类,二者有什么区别?什么是深度优先,什么是广度优先?
一个类只要继承了object类,就是新式类,在Python3中不管是否显式继承object类,都是新式类;
Python2中只有显式继承了object类才是新式类。
经典类:经典类只在Python2中才存在,而且是这个类没有显式的继承object类才能称之为是经典类。
深度优先:多继承的情况下,经典类在要查找属性不存在时,会按照深度优先查找,从左往右一个分支一个分支的查找,在第一个分支就查找顶级类;
广度优先:多继承的情况下,新式类在要查找属性不存在时,会按照广度优先查找,从左往右一个分支一个分支的查找,在最后一个分支才去查找顶级类;
4、用面向对象的形式编写一个老师类, 老师有特征:编号、姓名、性别、年龄、等级、工资,老师类中有功能。
1.生成老师唯一编号的功能,可以用hashlib对当前时间加上老师的所有信息进行校验得到一个hash值来作为老师的编号
def create_id(self):
pass
2.获取老师所有信息
def tell_info(self):
pass
3.将老师对象序列化保存到文件里,文件名即老师的编号,提示功能如下
def save(self):
with open('老师的编号','wb') as f:
pickle.dump(self,f)
4.从文件夹中取出存储老师对象的文件,然后反序列化出老师对象,提示功能如下
def get_obj_by_id(self,id):
return pickle.load(open(id,'rb'))
5、按照定义老师的方式,再定义一个学生类
6、抽象老师类与学生类得到父类,用继承的方式减少代码冗余
import time
import hashlib
import pickle
class People:
def __init__(self,name,sex,age):
self.name = name
self.sex = sex
self.age = age
class Teacher(People):
school='清华大学'
def __init__(self,id,name,sex,age,level,salary):
super().__init__(name,sex,age)
self.id=id
self.level=level
self.salary=salary
def create_id(self):
all_info=time.strftime('%Y-%m-%d %X') + self.name + self.sex + str(self.age)\
+ str(self.level) + str(self.salary)
id=str(self.id)
md5=hashlib.md5()
md5.update(all_info.encode('utf-8'))
md5.update(id.encode('utf-8'))
return md5.hexdigest()
def tell_info(self):
msg=f'老师所有信息为:\nid:{self.id}\n年龄:{self.name}\n性别:{self.sex}\n年龄:{self.age}\n等级:{self.level}\n工资:{self.salary}'
return msg
def save(self):
with open(str(self.id), 'wb') as f:
pickle.dump(self, f)
def get_obj_by_id(self):
return pickle.load(open(str(self.id), 'rb'))
class Student(People):
def __init__(self,name,sex,age,grade,course):
super().__init__(name,sex,age)
self.grade=grade
self.course=course
def choose_course(self):
print(f'同学{self.name}正在选{self.course}课程!')
tea=Teacher(12,'苍老师','male',18,9,1200)
stu=Student('zhang','male',18,'2班','python')
# tea.create_id()
# print(tea.tell_info())
# tea.save()
# print(tea.get_obj_by_id())
stu.choose_course()
# print(type(time.strftime('%Y-%m-%d %X')))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号