collections queue、os&shutil、datetime,序列化(json和pickle)模块
Collections 模块
Collections模块的数据类型:Counter、deque、defaultdict、namedtuple、orderedDict等。
1.nametuple
nametuple:官方读法叫做“具名元组”,生成可以使用名字来访问元素内容的tuple。
比如生成地理坐标:
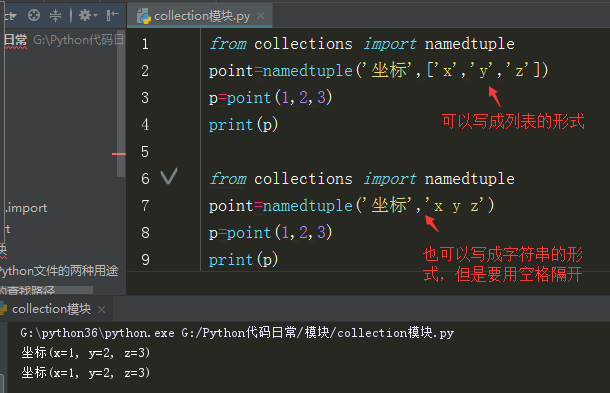
Namedtuple(‘名称’,‘参数’),参数既可以是一个可迭代对象,也可以是字符串,字符串之间要用空格隔开,我们所传的值要与参数的个数数量一致。
生成扑克牌:
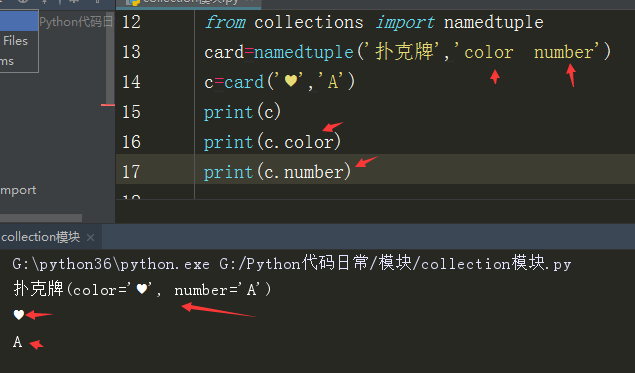
2.deque(双端队列)
队列是先进先出,也叫FIFO(first in first out),双端队列就是两端都能进出,特点:使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候插入和删除效率很低。Deque是为了高效实现插入和删除操作的双向列表,适用于队列和栈。
对列的先进先出
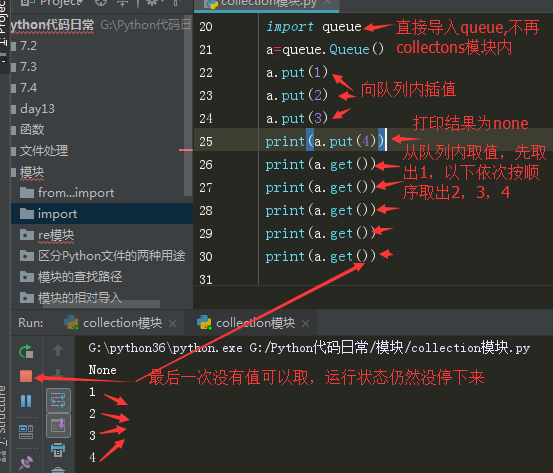
图中可以看出,如果队列中的值取完了,程序会在原地等待,直到从队列中拿到值才会停止,我们往队列放值的顺序是1,2,3,4,,,取出的时候仍然是1,2,3,4的顺序,所以是先进先出。
3.双端队列(deque):
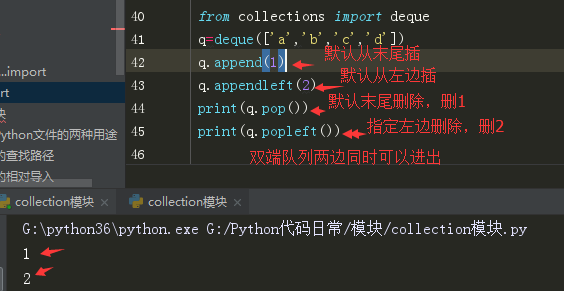
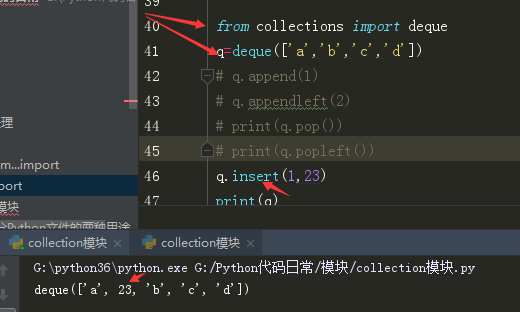
队列是不应该支持任意位置插值的,只能在首尾插值;但双端队列有些特殊,可以根据索引在任意位置用insert插值,下图是实例。
4.Odereddict(有序字典):
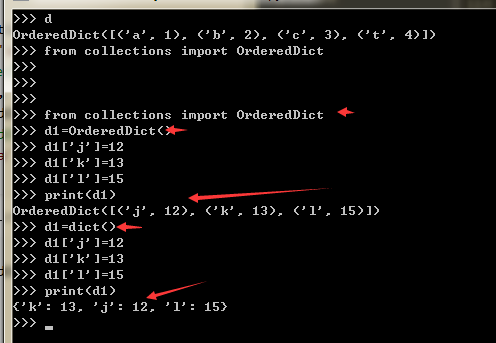
使用dict是无序的,在对dict迭代时,我们无法确定key的顺序。如果要保持key的顺序,可以用OrderedDict。以下实例在Python2或python3.6之前的版本证明一下为何dict无序,而orderedict是有序字典。
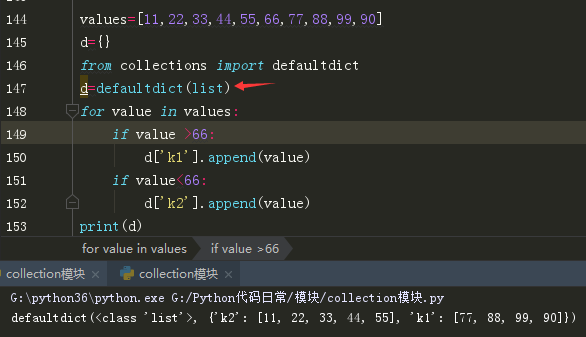
5.Defaultdict(默认字典,首字母要大写):

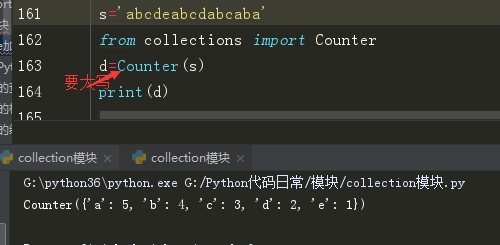
6.Counter(计数器,首字母要大写)
counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。counter类和其他语言的bags或multisets很相似。
time模块
调用方法:import time
和时间有关的我们就要用到时间模块,在使用时,应该先导入这个模块。
常用方法:
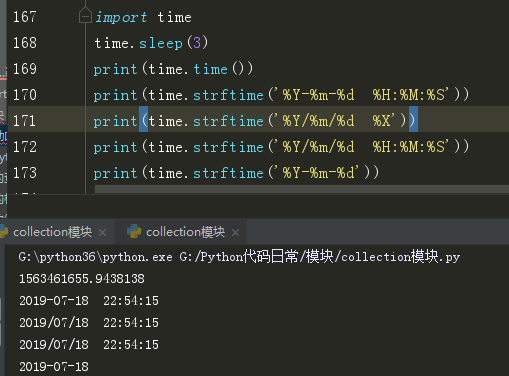
1)time.time()获取当前时间戳 2)timesleep(secs) 让计算机休眠指定的时长,单位是秒
表示时间的三种方式:
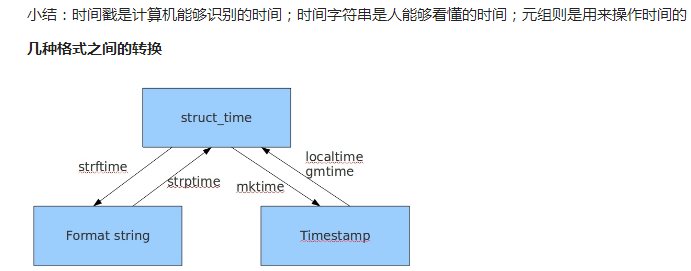
(1)时间戳(Timestamp)
时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量,我们运行“type(time.time)”,返回的是float类型。
(2)格式化时间
字符串(Format String)’1999-08-14’
Python 中时间日期格式化字符:
%y 两位数的年份表示(00-99) %Y四位数的年份表示 (0000-9999) %m 月份(01-12)
%d 月内的某一天 %H 24小时制小时数(0-23) %I 12小时制小 时数(01-12)
%M 分钟数(00=59)%S 秒(00-59) %p 本地A.M.或P.M.的 等价符
(3)结构化时间(struct_time)
struct_time元组共有9个元素:(年月日时分秒,一年中的第几周,一年中的第几天等)
(4)三种时间之间的转换
(5)时间字符串的拼接
Datetime:
调用方法:import datetime

random(随机模块)
Import random
print(random.randint(1,6)) # 随机取一个你提供的整数范围内的数字 包含首尾
print(random.random()) #随机取0~1之间的小数
print(random.choice([1,2,3,4,5,6])) #摇号,随机从列表中取一个元素
res=[1,2,3,4,5,6]
random.shuffle(res) #洗牌
Print(res)
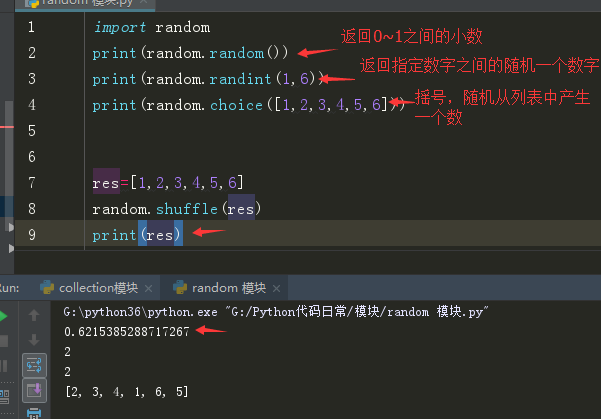
生成随机验证码案例:
要求:验证码由大写字母、小写字母、数字组成,生成5位随机验证码。
运用的知识点:chr:将ASCII码表里面对应的十进制数字转换成对应的大小写字母。
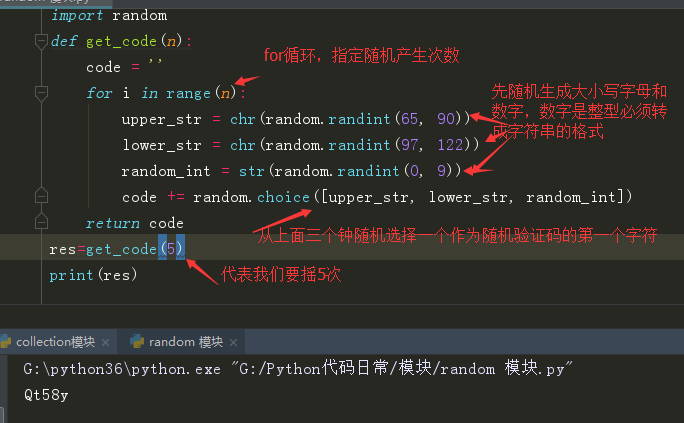
OS模块 (跟操作系统打交道的模块)
Import os
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录属性
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.getenv()与os.putenv() 读取和设置环境变量
os.exit() 终止当前进程
os.mknod('test.txt') 创建空文件
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
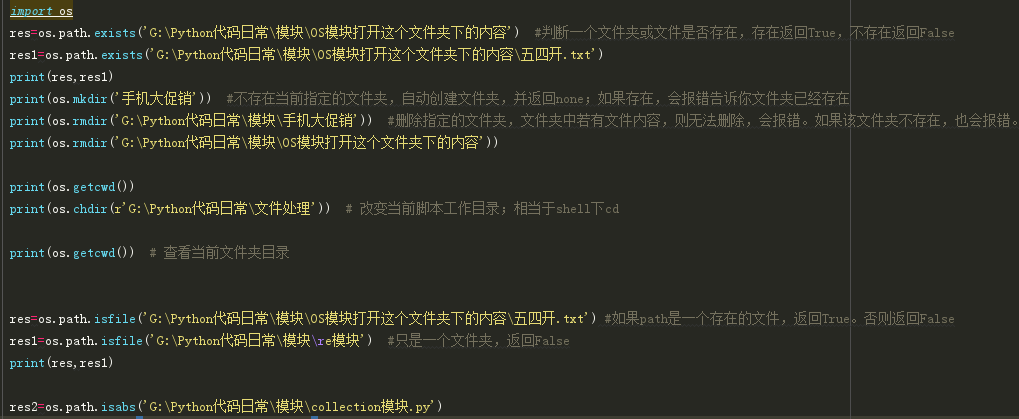
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
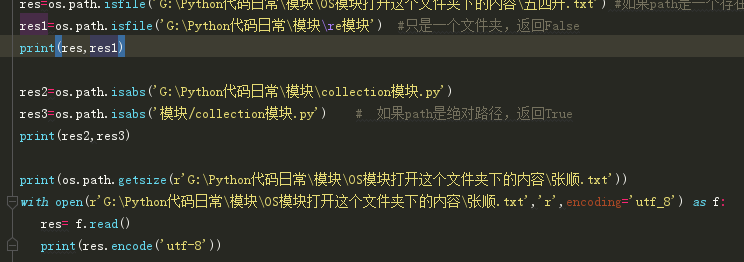
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
以下是常用的OS下的模块:listdir
listdir 可以获取指定文件夹下的全部文件的内容
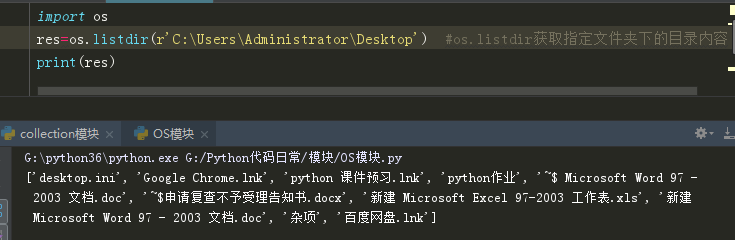
路径拼接

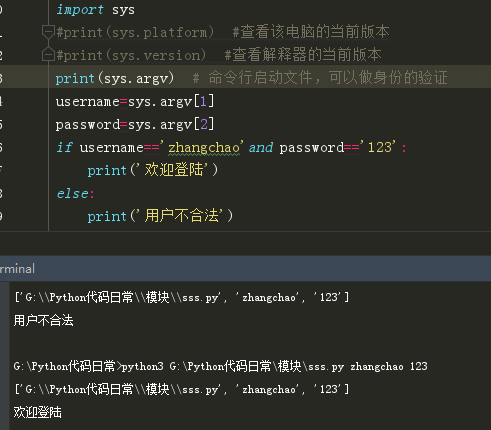
os 和 sys 模块组合添加环境变量
os模块下各个方法使用实例
shutil
# 复制文件
shutil.copyfile('oldfile','newfile')oldfile和newfile都只能是文件
shutil.copy('oldfile','newfile')oldfile只能是文件夹,newfile可以是文件,也可以是目标目录
# 复制文件夹
shutil.copytree('olddir','newdir')olddir和newdir都只能是目录,且newdir必须不存在
# 移动文件(目录)
shutil.move('oldpos', 'newpos')
# 删除文件
os.remove('file')
# 删除目录
os.rmdir('dir') # 只能删除空目录
shutil.rmtree('dir') 空目录、有内容的目录都可以删
# 转换目录
os.chdir('path') 换路径
序列化模块
序列化:其他数据类型转换成字符串的过程; 反序列化:字符串转成其他数据类型
序列化目的:1、以某种存储形式使自定义对象持久化;2、将对象从一个地方传递到另一个地方。3、使程序更具维护性。
所有的语言都支持json格式支持的数据类型很少,字符串,列表,字典, 整型 ,元组(转成列表),布尔值;
pickle模块(****)
只支持python ,python所有的数据类型都支持.
dumps:序列化 将其他数据类型转成json格式的字符串
loads:反序列化 将json格式的字符串转换成其他数据类型
json模块序列化字典和列表 用dumps 和 loads
json 模块
json可以序列化的数据类型
"""
Extensible JSON <http://json.org> encoder for Python data structures.Supports the following objects and types by default:
可扩展json<http://json.org>用于python数据结构的编码器。默认支持以下对象和类型:
| Python | JSON |
|---|---|
| dict | object |
| list,tuple | array |
| str | string |
| int,float | number |
| True | true |
| False | false |
| None | null |
To extend this to recognize other objects, subclass and implement a
``.default()`` method with another method that returns a serializable
object for ``o`` if possible, otherwise it should call the superclass
implementation (to raise ``TypeError``).
为了扩展它以识别其他对象,子类化并实现``.default()``方法与另一个返回可序列化的方法
对象,如果可能的话,它应该调用超类实现(引发“typeerror”)。
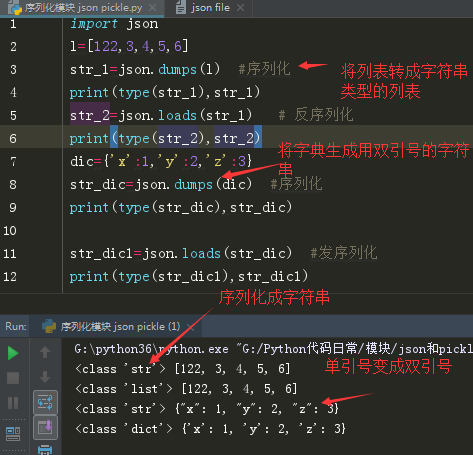
json序列化和反序列化 写、读文件用dump和load

# 元组序列化之后,再经反序列化就变成了列表。
import json
t=(1,2,3,4,5)
res=json.dumps(t)
print(res,type(res))
print(json.loads(res),type(json.loads(res)))
'''
[1, 2, 3, 4, 5] <class 'str'>
[1, 2, 3, 4, 5] <class 'list'>
'''
Pickle模块
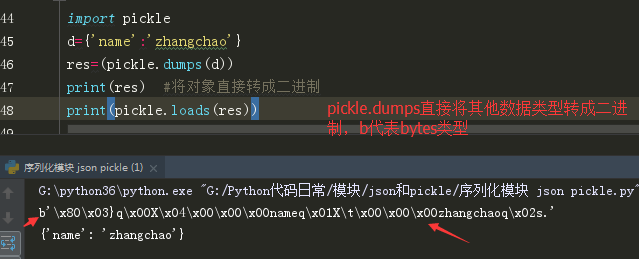
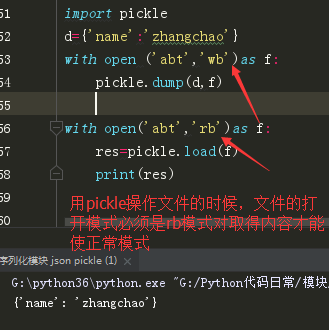
Pickle转码文件,直接将文件写成二进制,读的时候默认也是二进制形式,即‘rb’模式读取。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号