迭代器,生成器,生成器表达式,常用内置方法
迭代器
迭代器的定义:迭代器指的是迭代取值的工具,迭代是一种重复的过程,每一次重复都是基于上一次的结果而来单纯的重复不是迭代。比如:while的死循环打印同一个值就不是迭代。
l=['a','b','c']
i=0
while i < len(l):
print(l[i])
i+=1
这个while循环每一次取值都是基于上一次的结果往下进行,这就是一个迭代的过程。
迭代器的使用原因:迭代器提供了一种通用的且不依赖索引的迭代取值的方式
迭代器的使用方式
特点:可迭代的(iterable)对象都内置有__iter__方法,称之为尅迭代对象。比如:str、list、dict、set、tuple、文件对象。
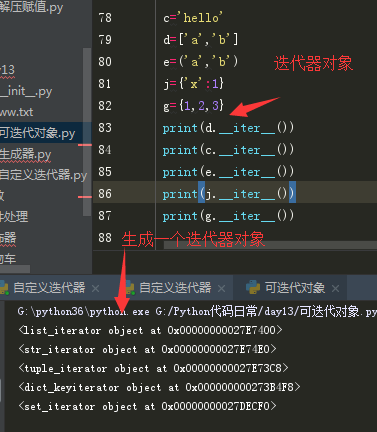
执行可迭代对象下的__iter__或iter(可迭代对象)方法,返回值就是一个迭代器对象(iteration)
1. 既内置有__next__方法的对象,执行迭代器__next__方法可以不依赖索引取值
2. 又内置有__iter__方法的对象,执行迭代器__iter__方法得到的仍然是迭代器本身
迭代器使用__next__取值,取一次只返回一个值,就类似之前说的‘老母猪’
ps:
dic={'x':1,'y':2,'z':3}
iter_dic=dic.__iter__()
print(iter_dic)
print(iter_dic.__next__())
print(iter_dic.__next__())
print(iter_dic.__next__())
print(iter_dic.__next__())或者写成print(next(iter(dic)))
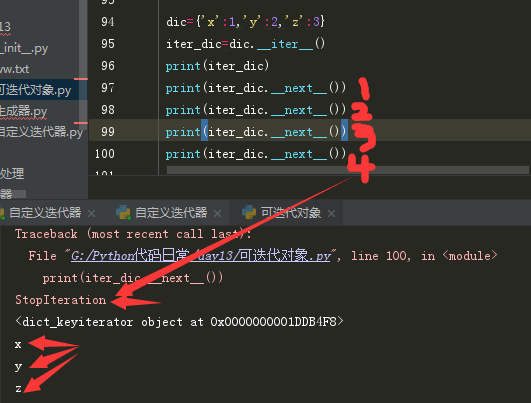
当迭代器一一取出所有元素的时候,再使用next(迭代器)方法,就会出现取值异常,报错(stopiteration),这可以被看做是一种结束取的信号。
ps:迭代器对象一定是可迭代的对象,而可迭代的对象却不一定是迭代器对象;文件对象本身就是一个迭代器对象。
调用可迭代的对象__iter__得到的是迭代对象,然后在对迭代器对象连续使用__iter__得到的仍然是这个迭代器对象本身。比如:print(iter_l is iter_l.__iter__().__iter__().__iter__().__iter__().__iter__().__iter__())
内置方法len()其实就是__len__,比如dic.__len__,得到的就是dic中元素的个数,其内部包含(__iter__和__next__)
对于迭代器取完所有值异常情况的处理
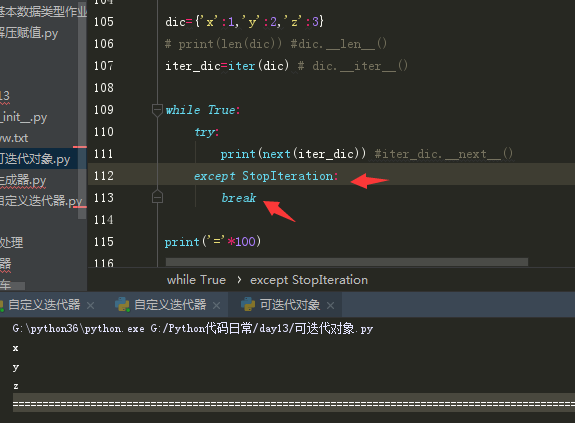
for循环(也称之为迭代器循环)的工作原理:
1,先调用in后面那个对象的__iter__的方法,将其变成一个迭代器对象‘
2,调用next(迭代器),将其得到的返回值赋值给变量名K,
3,循环往复直到next(迭代器)抛出异常,for会自动捕捉异常,然后结束循环。
dic={'x':1,'y':2,'z':3}
for k in dic:
print(k)
迭代器总结:
优点:
1,提供一种通用的且不依赖索引的迭代取值的方式
2,同一时刻在内存中只存在一个值,更节省内存。
缺点:
1,取值不如按照索引的方式灵活,(不能区指定的某一个值而且取值是从左往右,)
2,无法预测迭代器的长度,取完之后会报stopiteration错
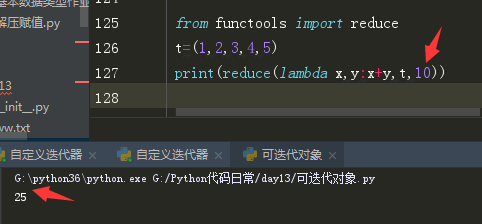
内置方法reduce的使用:
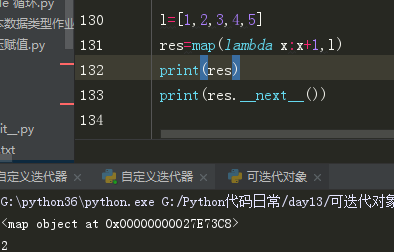
map的使用:
map在Python中做了优化,其返回值是一个迭代器,可以节省内存空间。
二,生成器:用户自定义的迭代器,本质就是迭代器。优点:节省内存(如果数据量较大,最好不要用列表生成式),代码量更少,执行更高效。
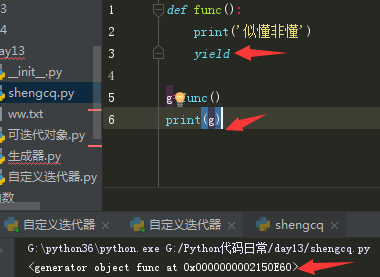
从图中看出,只要函数体中包含yield关键字,调用函数不会执行函数体代码,会得到一个返回值,该返回值就是生成器对象。
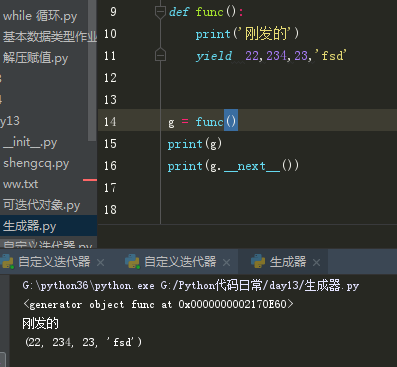
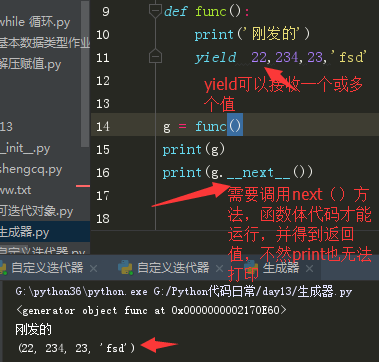
上面两张图看出,yield可以返回一个或多个值,多个值按照元组的形式返回,如果没有返回值,在调用next()返回值是none。图中的g=func()是生成器初始化:将函数变成迭代器。
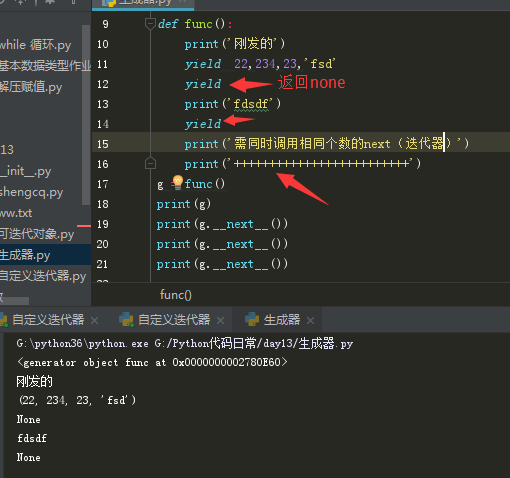
图中g.__text__会出发函数体执行代码,直到遇到一个yield停下来,并将yield后面的值当作本次next的结果返回。
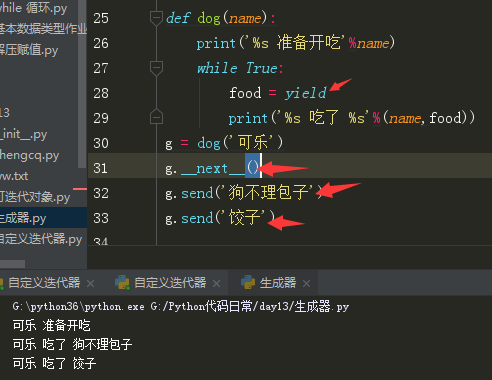
yield支持外界为其传参,必须先将代码运行至yield 才能够为其传值, 给yield左边的变量传参 触发了__next__方法。
yield:
1,帮我们提供了一种自定义生成器方式;2,能将函数的运行状态暂停住。
yield与return之间的异同点:
相同点:都可以返回值,并且都可以返回多个值
不同点:
yield可以返回多次值,而return只能返回一次,函数立即结束。
yield还可以接受外部传入的值。
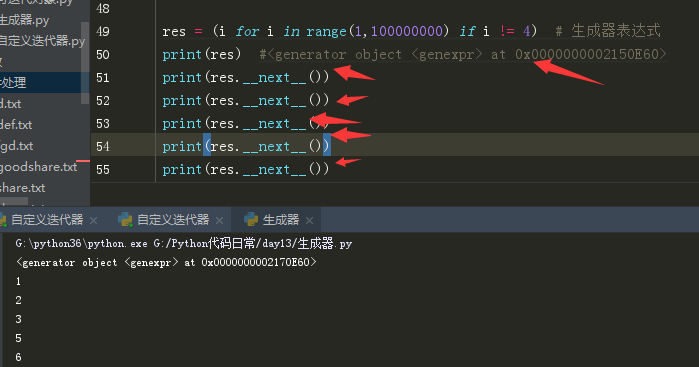
生成器表达式:生成器不会主动执行任何一行代码,必须通过__next__触发代码的运行。
三,常用内置方法
abs(求绝对值) ps:print(abs(-11.11)) 返回值式11.11
all、any
all:判断一个tuple或者list是否全不为空,全不为空,返回True,否则内部包含例如0,‘ ’,或者False、[]、()、{}等,则返回False;
any:只要内部元素不全部为空,就返回True,全为空返回False。
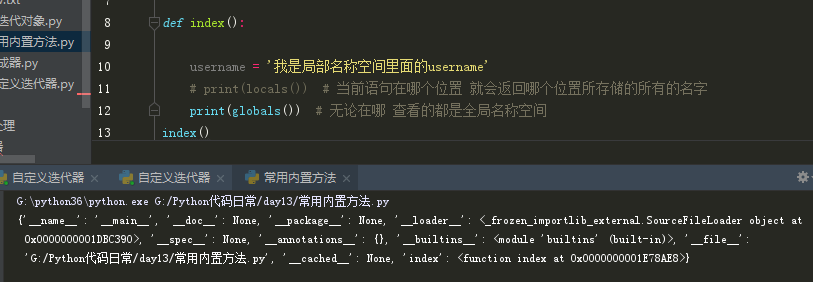
globals和locals
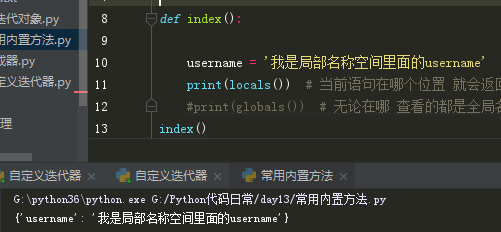
globals:无论在哪 查看的都是全局名称空间
locals:当前语句在哪个位置 就会返回哪个位置所存储的所有的名字
bin()、oct()、hex() 分别将一个十进制数转换为对应的二进制数(bin),八进制数(oct),十六进制数(hex).
print(int('0b1010',2)) #二进制数转换为十进制
print(int('o ',8))八进制转换为十进制
print(int(‘x ’,16))十六进制数转换为十进制数
bool返回布尔值的True或者False
bytes 将任意数据类型转换为二进制
s = 'hello'
print(s.encode('utf-8')) #b'hello'
print(bytes(s,encoding='utf-8')) #b'hello'
callable 是否可调用
chr和ord
chr将数字转换为ASCII码表对应的字符 #print(chr(97))
ord将字符按照ASCII码表转成对应的数字 #print(ord('a'))
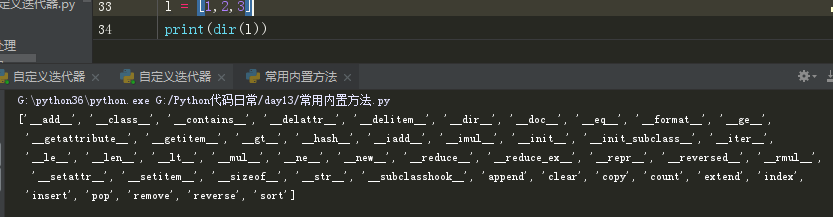
dir 获取当前对象名称空间里面的名字
divmod (x,y)分页器 x代表总数,y代表x/y的余数。
enumerrate 枚举
eval、exec 可以对注释中的Python代码执行并返回结果,但eval不支持逻辑代码,只支持一些简单的python代码
format 占位符 三种站位方式:1,位置站位 2,索引站位, 3,指名道姓
help 可以帮助我们获取解释器对于Python中的某些东西的提示。
isinstance:判断对象是否属于某个数据类型
pow(x,y):表示x的y次方 #print(pow(2,3)) 结果就是8
round:类似于四舍五入,但这里必须大于0.5才进1。 print(round(3.5)) 返回结果为3。print(round(3.6)) 返回结果为4

