

机器学习笔记(更新中)
1.1监督学习:数据集中包含大量的数据,但每一个数据都有确定的标签。比如:1.肿瘤数据:良性还是恶性 2.卖房子已知很多房子的数据并且知道最后买了多少钱。
基于这些数据对新的数据进行预测,比如归回问题:即通过回归来推出一个连续的输出;分类问题:其目标是推出一组离散的结果。肿瘤可以看成分类问题,预测房子的价格可以看成回归问题。
1.2无监督学习:大量的数据,但是没有一个明确的标签,只是有一堆数据而已。通过算法让机器自己根据这些数据的特点进行分类并根据分类对数据进行划分。
比如:大量新闻报道中,把对同事件的报道归为一类。鸡尾酒会问题:多个麦克风同时录制多种声音,最终分类消除杂音。
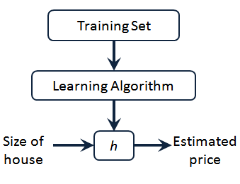
2.1线性回归模型:x-输入变量(例如房子的面积);y-输出变量(例如房子的成交价格);m-训练集中数据的数量;(x,y)一个训练集中的实例;(x(i),y(i))第i个训练实例;h代表学习算法的解决方案或函数也称为假设。
2.2代价函数J:也被称为平方误差函数,是解决回归问题最常用的手段。
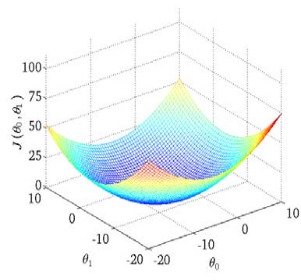
图例
可以看出在三维空间中存在一个使𝐽(𝜃0, 𝜃1)最小的点。
2.3 梯度下降:用来求代价函数𝐽(𝜃0, 𝜃1)的最小值,也叫批量梯度下降(batch gradient descent)
计算公式:
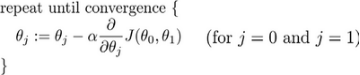
其中α是学习率(learning rate)相当于步长;要注意在梯下降中要保证𝜃0,𝜃1同步更新。
3.1 多变量线性回归及其多变量梯度下降
在多变量线性回归中,如果有n个特征,例如房子楼层数,卧室数,楼房年龄等,x=(x0,x1,....xn)是n+1维向量,其中x0=1,x1到xn是n个特征。
多变量线性回归中的代价函数: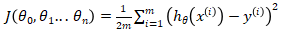
其中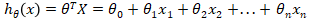
多变量线性回归的批量梯度下降算法为:
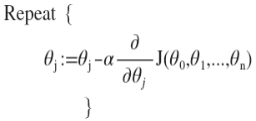
即:
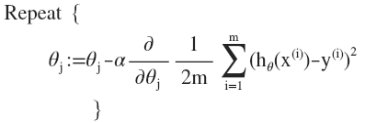
求导后:
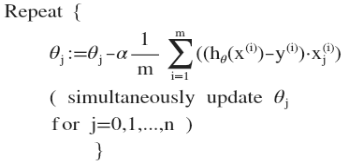
其中x0(i)=1
最开始初始化参数值,计算所有的预测结果后,再给所有的参数一个新的值,如此循环直到收敛。
3.2 特征缩放:
面对多维特征问题的时候,保证这些特征都具有相近的尺度,这将帮助梯度下降算法更快地收敛。
一般化公式:![]() ,μn是xn的平均值,sn是标准差,可以用范围的最大值减最小值代替。
,μn是xn的平均值,sn是标准差,可以用范围的最大值减最小值代替。
一般(-3,3)以内(-1/3,1/3)以外是可接受范围。
3.3 学习率α的影响和选取
经验之谈:绘制迭代次数和代价函数的图表来观察算法在何时趋于收敛要好于设置阈值ε自动测试是否收敛,因为很难选取到合适的阈值ε。
梯度下降算法的每次迭代受到学习率的影响,如果学习率过小,则达到收敛所需的迭代次数会非常高;如果学习率过大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛。
通常可以考虑尝试些学习率:
α=0.01,0.03,0.1,0.3,1,3,10...
3.4 多项式回归
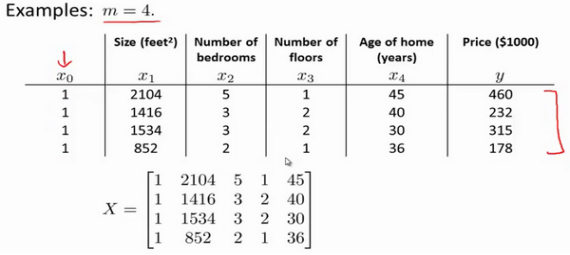
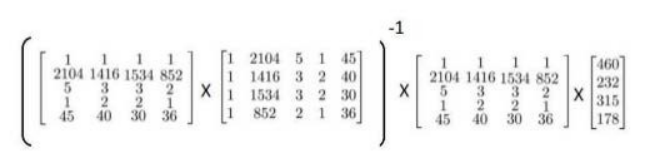
经验:只要特征变量的数目不大,标准方程是一个很好的计算参数𝜃的替代方法。
一般对于特征数量的要求是其小于10000,但其只适用于线性模型,不适合逻辑回归等其他模型;而梯度下降法适用于各类模型,当特征数量n较大时也能较好的适用。

该函数图像:
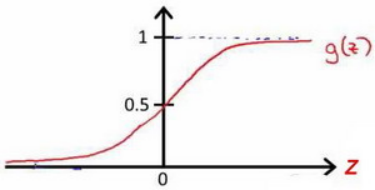

虽然形式和线性回归的梯度下降算法一样,但是ℎ𝜃(𝑥) 已经发生了变化。
 又或者:
又或者:
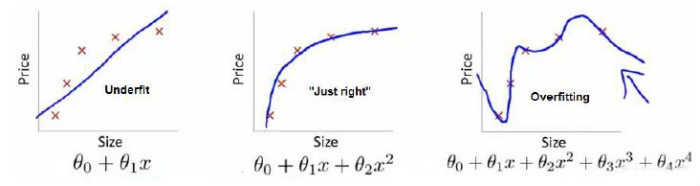
这两幅图的第一个都是欠拟合,第三个都是过拟合。
通过多项式理解, 多项式中x的次数越高,拟合的越好,但相应的预测的能力就可能变差。
处理方法:
1.丢掉一些不能帮助我们正确预测的特征。可以手工选择保留哪些特征,也可以运用一些模型选择的算法来帮助选择。
2.正则化方法:保留所有特征,但是减少每个特征的参数大小。
5.2 线性回归中的正则化
正则化线性回归的代价函数:
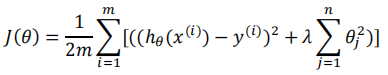
线性回归中最小化代价函数有两种方法,梯度下降法和正规方程法。
其中梯度下降法:
![]()
![]() ,(𝑗 =1,2, .. . ,𝑛 )
,(𝑗 =1,2, .. . ,𝑛 )
正规方程法:
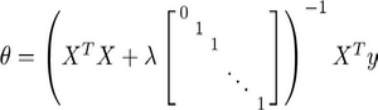
图中矩阵为(𝑛 + 1) ∗ (𝑛 + 1)阶矩阵。
5.3 逻辑回归模型中的正则化
正则化后的代价函数:
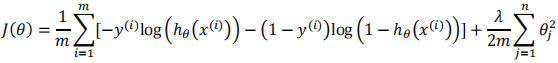
梯度下降算法:
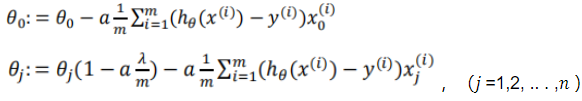
6.1 非线性假设
对于一些分类问题,例如预测房子能否卖出,识别图像是否为小汽车等,这些问题都有一个特点:特征数很多。当特征很多时,如果运用非线性模型,模型的特征数会指数倍增长,即使用只含平方项或立方项的logistic回归算法,计算成本也太高了。
因此面对很多的特征时,我们需要更好的算法:神经网络算法。
6.2 神经网络的模型表示
三层神经网络:
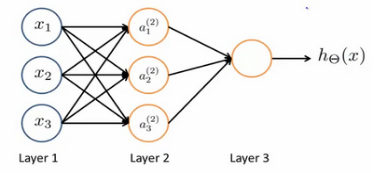
其中:
x1,x2,x3是输入单元(input units),我们将原始数据输入给它们;a1,a2,a3是中间单元,它们负责将数据进行处理,然后呈递到下一层;最后是输出单元,它负责计算。
神经网络模型是许多逻辑单元按照不同层级组织起来的网络,每一层的输出变量都是下
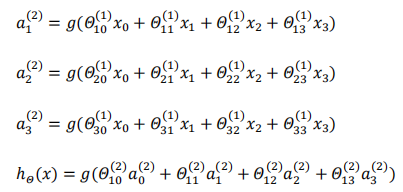
这种从左到右的算法称为前向传播算法( FORWARD PROPAGATION )。
6.3 模型的向量化
向量化的方法会让计算更加简便,令上图g()中的表达式为z(2),其中:
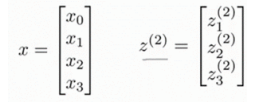
则:
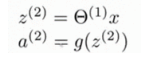
同理,令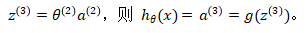
如图所示:
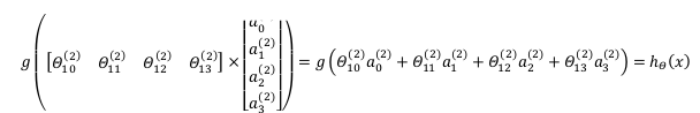
6.4 神经网络的一些简单应用
从本质上讲,神经网络能够通过学习得出其自身的一系列特征。在普通的逻辑回归中,我们被限制为使用一些二项式来拟合数据中的原始特征,拟合过程会受到特征数的限制。在神经网络中,原始特征只是输入层,在上面三层的神经网络例子中,第三层也就是输出层做出的预测利用的是第二层的特征,而非输入层中的原始特征,可以认为第二层中的特征是神经网络通过学习后自己得出的一系列用于预测输出变量的新特征。
单层神经元可表示逻辑与逻辑或逻辑非运算。
逻辑与:
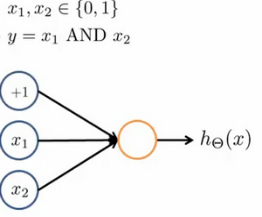
其中𝜃0=-30,𝜃1=20,𝜃2=20;输出函数h𝜃(x)=g(-30+20x1+20x2)
逻辑或:

逻辑非:
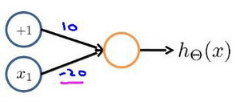
三者相比只是𝜃的取值不同。
三者组合可以实现XNOR运算符功能的神经网络。
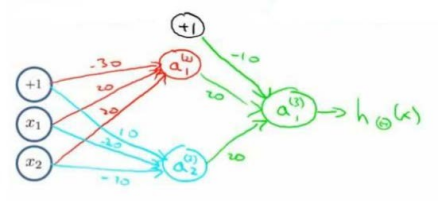
按这种方法可以逐渐构造出越来越复杂的函数,也能得到更加厉害的特征值,这就是神经网络相比线性回归,逻辑回归的厉害之处。
7.1 神经网络的代价函数
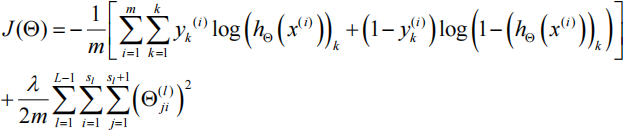
k=2称为二类分类,k>2称为K类分类;其中m代表训练样本个数,L代表神经网络的层数,Sl代表第L层神经元的个数(不包括偏置单元)
神经网络中,k=2时输出0或1,k>2时ℎ𝜃(𝑥)输出的是一个向量。
7.2 反向传播算法
反向传播算法的目的是为了计算代价函数的偏导数![]()
举例说明:

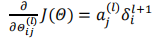
如果考虑正则化,则计算偏导数的算法为

算法的含义为首先用正向传播方法计算出每一层的激活单元,利用训练集的结果与神经网络预测的
偏导数计算公式如下图: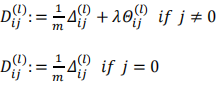
7.3 梯度检验
在反向传播的实现中可能会存在一些bug,即使存在bug也能进行梯度下降最小化代价函数,但是最终可能和没有bug的反向传播所得出的结果相差一个数量级,所以梯度检验是很有必要的。
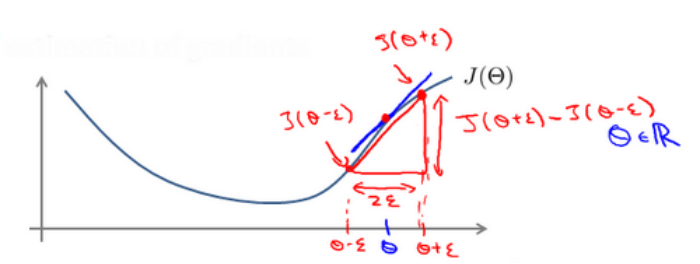
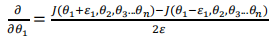
检验时,要将𝛥𝑖𝑗(𝑙)矩阵展开成为向量,同时我们也将 𝜃 矩阵展开为向量,我们针对每一个 𝜃 都计算一个近似的梯度值,将这些值存储于一个近似梯度矩阵中,最终将得出的这个矩阵同𝛥𝑖𝑗(𝑙) 进行比较。
7.4 随机初始化



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」