
mysql底层原理
mysql索引是帮助mysql高效获取的排好序的数据结构
数据结构
二叉树(左小右大)
缺点:如果是递增或者递减的数据,就会成一个链状,失去了索引的功能
红黑树
二叉树的升级版,如果是递增或递减的数据就会做一下优化
缺点:治标不治本,树高还是很高 i/o 还是多
Hash表
在mysql中每一个索引都对应着hash表中的一个hash值,然后mysql就会把hash值和索引的内存地址存储起来(k,v),每次用索引查询的时候,mysql就会把索引通过hash运算,然后得到hash值, 然后就能高效的查到索引的地址(缺点:1.哈希冲突,2.这种结构不适用范围性查找,所以用的不多 只有数据量特别大,而且基本不会用范围性查询)mysql索引支持这种数据结构,只是用的不多
B-Tree
增加了横向宽度,索引和data是在一块的所以存索引存的少(相对应B+Tree)
B+Tree *
现在mysql索引99%都是用的这种索引 优点 :加大了横向宽度(一个节点大小是16KB,也是左小右大于等于,一个节点对应着一个分支,只有在叶子节点上才存数据地址(MyISAM)(InnoDB存的是主键)。非叶子节点存储的都是冗余的节点。)所以即便是上千万的数据,纵向(树的高度)也不会超过4。所以大大的提高了查找效率。目前mysql索引大多数都是用的这种
MyISAM
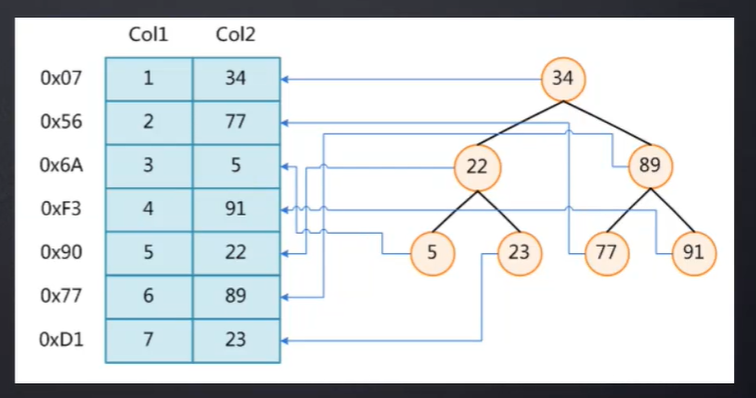
非聚集索引:索引和数据是分开的 索引的data部分只是索引的地址值(轻量)
InnoDB(支持事务)
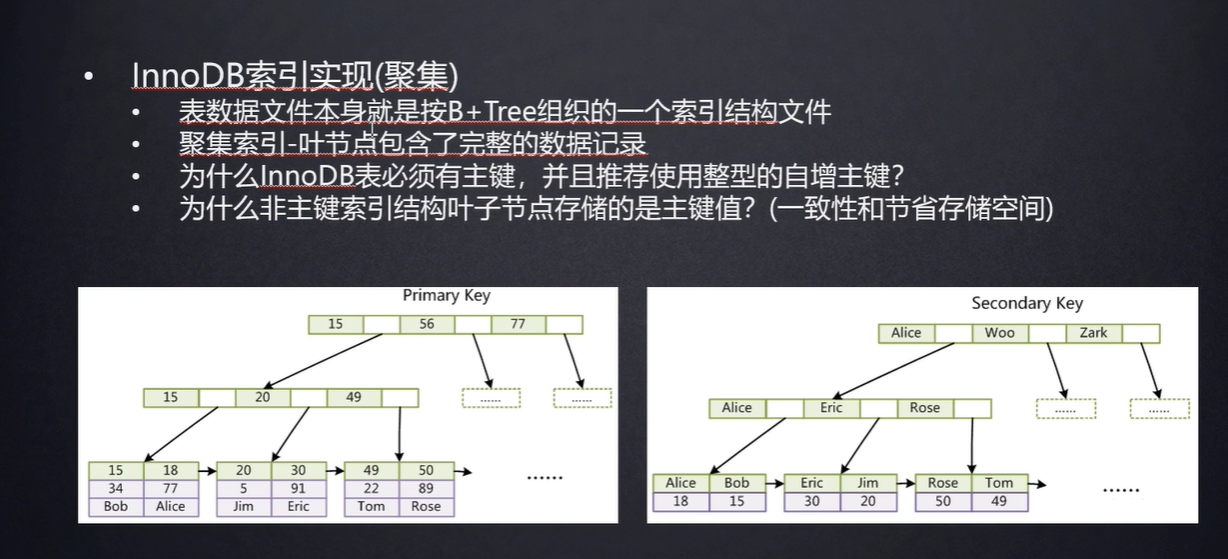

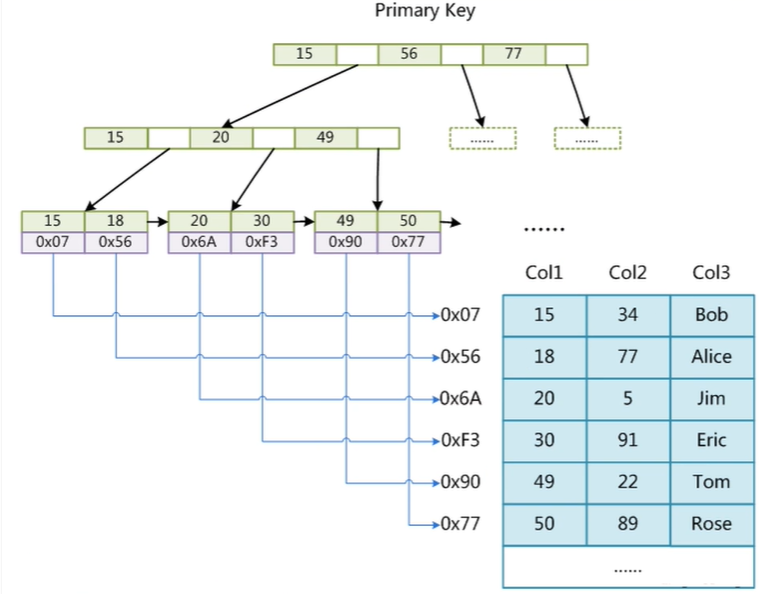
2.聚集索引:就是索引的data数据部分是表的全部信息(索引和数据在一块),这样就不用在进行 i/o操作了(重量)
3.InnoDB表必须有主键,如果你不加,他会先找一列合适的作为主键,如果找不到,就会自己建一列主键。因为B+Tree是需要索引来维护的。
整形主键比其他的主键(eg:UUID)比较起来会更快(因为用索引查找的时候,会比大小),自增是为了在叶子节点上好存储(拆中间的肯定比在末尾加慢了)
InnoDB和MYISAM类型表物理磁盘存储的区别

