
unity3D 知识点随手记
最近闲来无事,记记unity3D相关的一些知识点吧,也当作笔记存储。转载请标明出处:http://www.cnblogs.com/zblade/
1、unity是如何调用Start/Awake等相关函数的?
在unity中,一个常见的问题是awake, start, update等相关函数的执行顺序,这个就不在这儿赘述了,一个比较深入的问题,是如何调用这些函数的。如果是虚函数的重载,那么我们为什么没有override关键字?我查阅了一下,知乎上有一个相关问题,大概是2个方向的意见。一个是源代码显示,unity的mono支持对函数名进行字符串获取,在获取到这些函数名后,再进行反射调用。其实说的更浅白一点,就是继承自mono的类,unity都会对其中的函数进行引用统计,在每帧调用的时候,对于非空的函数,都会执行一次遍历反射回调。很多人觉得反射对于性能影响比较大,其实可以用缓存的方式,在第一次反射执行后,缓存下来,下一次执行的之后可以直接从缓存中获取,直接执行,所以很多人测试发现反射的性能接近于函数调用,就是这个原理。
2、图集的原理及使用图集的原因?
图集的本质,其实就是一张大图,将各个图集中的小图合并到一张大图,然后还有一份保存各个小图的尺寸、位置、偏移等信息的数据文件,所以一般一个图集会对应2个文件,当然如果把数据文件也打包进去,就会只有一个数据文件。
使用图集的原因,有这么几点:首先,使用图集可以方便的管理图片资源;其次,在每次绘制一张图的时候,都会在GPU阶段送入一张图片进去,这样的一次操作就会触发一次DrawCall,如果有几十上百个图,那么每次在转换的时候,都会触发多次DrawCall,使用图集,可以只触发一次DrawCall,把所有相关的图片都塞入进去,从而大大降低DrawCall;最后使用图集也方便图片资源的加载和卸载。
3、lua相关的一些问题
1)lua中table实现的原理
lua对于table的设计,是基于数组和hash共同兼容的,对于数组,其主要存储连续的同类型数据,hash则通过key-value的方式存储。对于hash和数组,默认大小都是0,然后是1,2,4等等基于2的幂次递增,由于每次递增的时候,都会进行一次rehash,所以性能都消耗在rehash上,所以在创建table的时候,尽量避免这样rehash的操作,比如:
local t1 = {} t["x"] =1, t["y" ] =2 , t["z"] = 3, 这样三次操作,就会触发三次rehash,想想原理即可明白
local t2 = {"x" = 1, "y" = 2, "z" = 3}, 这样只会触发一次rehash,对比节省3次性能。
2)请回答lua中对于key值的查找过程
lua对于key值的查找,首先会去数组和hash中查找对应的key值,如果存在,则返回;如果不存在,则查找该table是否有元表metatable,如果没有,则返回nil;如果有,则查看metatable中是否有__index方法,如果没有,则返回nil;如果有,则执行__index[key]查找,返回对应的值。
3)lua如何执行GC,以及对应的原理和API设置
lua GC的原理,推荐大家阅读一下云风的blog中对于GC的详细过程的阐述,结合源代码,有较为详细的讲解过程:Lua GC的源码剖析
这儿做一个读后笔记记录吧:
(1) Lua GC对象
lua中一共有9种数据类型,分别为nil, boolean, lightuserdata, number, string, table, function, userdata 和 thread。其中, string, table, function, thread会被GC处理,此外还有proto和upvalue需要被GC处理。
(2) Lua 数据定义方式 union + type
//Union of all Lua values
typedef union
{
GCObject* gc;
void* p;
lua_Number n;
int b;
}Value;
#define TValuefields Value value;
int tt
typedef struct lua_TValue
{
TValuefields;
}TValue
所有的GCObject都有一个相同的数据头,CommonHeader,其定义为:
#define CommonHeader GCObject* next; lu_byte tt; lu_byte marked;
这样所有的GCObject都会被同一个单向链表串接起来,每个对象基于tt识别,marked用来标记清除的工作
(3) Lua 对不同类型的清除操作分类
Lua在每次GC清除的的时候,分为多种类型:
对于GCObject,通过若干根节点开始,逐个直接或者间接的将其上的所有节点左上标记,完成标记后,遍历链表,对未被标记的节点执行删除操作;
对于string类型,由于所有的string都放在一张大的hash表中,这样是为了确保整个lua中同一个string不会被创建两份,所以其是被单独管理的,不会被串在GCObject的链表中
对于upvalue类型数据,也是一个特殊处理过程,这是由于GC可能分布扫描,由于upvalue是对已有的对象的间接引用,在创建的时候不属于创建新数据,在mark的过程中需要添加luaC_barrier
对于userdata, 由于userdata都有gc方法,所以会在最后单独处理逐一遍历所有的userdata来执行其中的gc方法,会有一些特殊的处理
(4) Lua执行GC的几个流程
Lua执行GC的几个流程,可以分为5步: GCSpause\ GCSpropagate\GCSsweepstring\GCSsweep\GCSfinalize,从lua5.1 开始就执行分布GC,每次执行可能会有多个状态切换
GCSpause 为GC阶段的启动流程,标记系统的根节点即可
GCSpropagate 这是标记流程,对尚未标记的对象(灰色链表)迭代标记(反复调用propagatemark),否则在atomic函数中执行一次标记
GCSsweepstring 这就是前面提起的对string类型的数据,进行特殊的处理,在这个状态中,每步都会清除string的hash表中的一列
GCSsweep 和上一个状态类是,不过这步操作的对象是GCObject
GCSfinalize 在这儿主要对userdata执行,如果需要调用其gc,则执行gc操作,由于userdata的对象和关联数据不会在之前的清除阶段被清除,所以其实际清除会在下一次的GC清除中执行或者在lua_close中被清除:lua_close的工作就是简单的处理所有userdata的gc元方法,以及释放其所用到的内存。
(5) Lua GC的标记流程
Lua对于所有的GCObject都设置一个颜色,最开始是白色,新建的节点也是白色,然后在标记阶段,可见的节点被设置为黑色,如果某些节点关联其他节点,在没有处理完其关联节点前,都被标记为灰色,对于颜色的标记,其存储在CommonHeader的8位的marked域中,对于白色有两个白色的标记位,采用一种乒乓开关,避免在标记完成后,清理没有完成前,对象间关系发生变化的时候,某些不需要被清理的节点,就可以从一种类型的白色转换到另一种类型的白色中,比如当前删除0型白色,那么转换到1型白色,这样1型白色就会被保护起来不会被删除,反之亦然。具体对于8个位的定义和使用,可以看云风的原文,有一定讲解。
(6) Lua GC的操作
常用的几个API: luaC_fullgc\ luaC_step\luaC_checkGC
luaC_fullgc: 执行一次完整的gc动作,对于可能执行一般的流程,在走完一次流程后,会阻塞状态再次执行一遍gc,对于已经执行的前半程gc,其实不需要做清除操作,只需要做状态回复
luaC_step: 其核心在与调用singlestep函数,通过设置gcstepmul值,可以设置步长,从而影响gcthreshold,其实步进量的设置,是一个经验值
luaC_checkGC: 自动GC的接口,在大部分导致内存增长的api中会调用该方法,自动GC,可能会在某一个周期性中将众多临时对象也mark了,造成系统的峰值内存占用比实际需求大,可以在这种周期性调用中采用gcstep的方法,同时设置较大的data量,使得有限周期做一个完整的gc。
(7) Lua GC的mark操作
对于Lua的mark操作,主要操作的API: markroot\ reallymarkobject\remarkupvals\atomic\iscleared
(8) Lua GC的write barrier操作
主要的API: luaC_barrier\luaC_barriert\luaC_objbarrier\luaC_objbarriert
(9) Lua GC的剩余操作 sweep/finalize
sweep的操作分为 GCSsweepstring 和GCSseep, 贴2个源码:
case GCSsweepstring: {
lu_mem old = g->totalbytes;
sweepwholelist(L, &g->strt.hash[g->sweepstrgc++]);
if (g->sweepstrgc >= g->strt.size) /* nothing more to sweep? */
g->gcstate = GCSsweep; /* end sweep-string phase */
lua_assert(old >= g->totalbytes);
g->estimate -= old - g->totalbytes;
return GCSWEEPCOST;
}
case GCSsweep: {
lu_mem old = g->totalbytes;
g->sweepgc = sweeplist(L, g->sweepgc, GCSWEEPMAX);
if (*g->sweepgc == NULL) { /* nothing more to sweep? */
checkSizes(L);
g->gcstate = GCSfinalize; /* end sweep phase */
}
lua_assert(old >= g->totalbytes);
g->estimate -= old - g->totalbytes;
return GCSWEEPMAX*GCSWEEPCOST;
}
对于seeplist,其源代码为:
static GCObject **sweeplist (lua_State *L, GCObject **p, lu_mem count) {
GCObject *curr;
global_State *g = G(L);
int deadmask = otherwhite(g);
while ((curr = *p) != NULL && count-- > 0) {
if (curr->gch.tt == LUA_TTHREAD) /* sweep open upvalues of each thread */
sweepwholelist(L, &gco2th(curr)->openupval);
if ((curr->gch.marked ^ WHITEBITS) & deadmask) { /* not dead? */
lua_assert(!isdead(g, curr) || testbit(curr->gch.marked, FIXEDBIT));
makewhite(g, curr); /* make it white (for next cycle) */
p = &curr->gch.next;
}
else { /* must erase `curr' */
lua_assert(isdead(g, curr) || deadmask == bitmask(SFIXEDBIT));
*p = curr->gch.next;
if (curr == g->rootgc) /* is the first element of the list? */
g->rootgc = curr->gch.next; /* adjust first */
freeobj(L, curr);
}
}
return p;
}
基本看源代码就可以理解,对于dead的freeobj,没有dead的则执行makewhite,最后一个流程就是GCS finalize,通过GCTM函数执行,每次调用一个需要回收的userdata的gc元方法:
static void GCTM (lua_State *L) {
global_State *g = G(L);
GCObject *o = g->tmudata->gch.next; /* get first element */
Udata *udata = rawgco2u(o);
const TValue *tm;
/* remove udata from `tmudata' */
if (o == g->tmudata) /* last element? */
g->tmudata = NULL;
else
g->tmudata->gch.next = udata->uv.next;
udata->uv.next = g->mainthread->next; /* return it to `root' list */
g->mainthread->next = o;
makewhite(g, o);
tm = fasttm(L, udata->uv.metatable, TM_GC);
if (tm != NULL) {
lu_byte oldah = L->allowhook;
lu_mem oldt = g->GCthreshold;
L->allowhook = 0; /* stop debug hooks during GC tag method */
g->GCthreshold = 2*g->totalbytes; /* avoid GC steps */
setobj2s(L, L->top, tm);
setuvalue(L, L->top+1, udata);
L->top += 2;
luaD_call(L, L->top - 2, 0);
L->allowhook = oldah; /* restore hooks */
g->GCthreshold = oldt; /* restore threshold */
}
}
在回收的时候,设置较大的GCthreshold来避免GC的重入
4、C#的GC原理和机制
对于上面的Lua的GC的原理,在阅读了源码后,可以进一步的衍生到C#的GC机制和原理,找到一篇超级赞的博文:c#技术漫谈之垃圾回收机制(GC),拜读大牛对于GC的详细漫谈,对GC也有一个初步的学习和了解,这儿记下来,用作后续的阅读。对于C#的托管和非托管资源,可以一图解释:
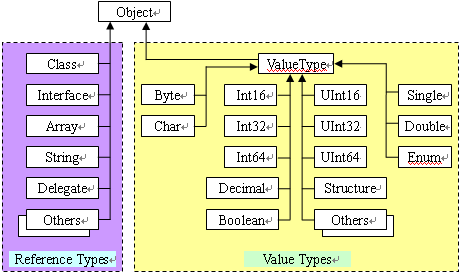
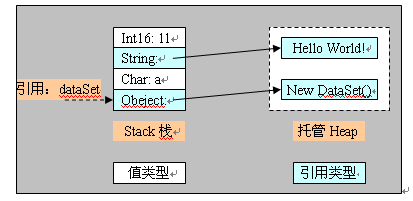
1) 使用内存托管的原因
(1) 提高软件的开发速度(无需陷入内存管理中);(2) 降低模块耦合,使得接口更清晰;(3) 提高内存管理的效率;
2) GC 的定义
garbage collection , 以应用程序的root为基础,遍历应用程序在堆上动态分配的所有对象,识别其是否被引用来确定其是否死亡还是被引用,对于不再引用的对象或者整个root,都标记为垃圾,然后执行回收。主要的算法有 Reference Counting\Mark Sweep\ Copy Collection, 目前主流的.NET CLR, JAVA VM都是采用Mark Sweep的算法
3) Mark Sweep-Compact 算法
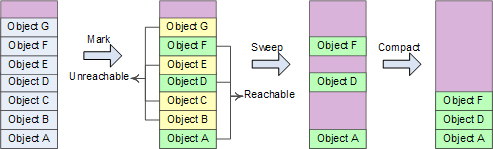
阶段1:Mark sweep标记清除阶段,先假设heap中所有对象都可以回收,然后找出不能回收的对象,给这些对象打上标记,然后heap中没有被打标记的对象都是可以被回收的;
阶段2:compact阶段,对象回收之后heap内存空间变得不连续,在heap中移动这些对象,使得其从heap的基地址开始连续排列,类似于磁盘空间的碎片整理,然后将heap的指针指向压缩后的起始位置,便于下次内存分配;
操作流程: 线程挂起-> 确定roots->创建reachable objects graph-> 对象回收->heap 压缩->指针修复
roots: 就是CLR在heap之外可以找到的各个入口点,一般在全局变量、静态变量、局部对象、函数调用参数、当前CPU寄存器中的对象指针、finalization queue中,可以分为已经初始化了的静态变量、线程仍在使用的对象;
指针修复:由于heap的压缩,对象的地址发生变化,需要修复所有引用指针,包括stack\CPU register中的指针\heap中其他对象的指针,copy原文中的图片:
4)Generational 分代算法
分代算法,将对象按照生命周期分成新的、老的,根据统计分布规律所反应的结果,对新老区域采用不同的回收策略和算法,加快回收速度,其基本假设为:
(1) 新创建的对象生命周期都较短,较老的对象生命周期会更长;
(2) 对部分内存回收会比全内存回收更快;
(3) 新创建的对象之间关联较强,内存分配是连续的,其基本操作如原文中图:
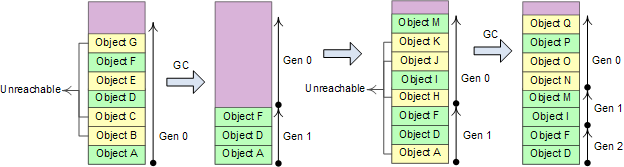
heap分为三个代,对应三种GC方式:#Gen 0 collection #Gen 1 collection #Gen 2 collection, 对应的频率可以设置为1:10:100
5) Finalization Queue \Freachable Queue
这两个队列会用来存储对象的指针,当程序中new一个对象创建在heap上,在GC的时候会对对象进行分析,如果其中含有Finalize方法,则会在Finalization Queue中添加执行该对象的指针,在GC的时候,会将这个对象从垃圾中分离出来,然后将其从Finalization Queue中移到Freachable Queue中,这个过程就是对象的复生。当被添加到Freachable Queue中后,就会触发对象执行Finalize方法,然后将指针从队列中移除,这时候整个对象可以安静的go die了。
System.GC类提供两个控制Finalize的方法,ReRegisterForFinalize和SuppressFinalize,前者请求系统完成对象的Finalize方法,后者请求系统不要完成对象的Finalize方法。
对于非托管的资源,主要采用Dispose方法来进行主动释放其中的托管和非托管资源,最后摘抄一下作者的总结:
GC注意事项:
1) 只管理内存,非托管资源,如文件句柄,GDI资源,数据库连接等还需要用户去管理。
2) 循环引用,网状结构等的实现会变得简单。GC的标志-压缩算法能有效的检测这些关系,并将不再被引用的网状结构整体删除。
3) GC通过从程序的根对象开始遍历来检测一个对象是否可被其他对象访问,而不是用类似于COM中的引用计数方法。
4) GC在一个独立的线程中运行来删除不再被引用的内存。
5) GC每次运行时会压缩托管堆。
6) 你必须对非托管资源的释放负责。可以通过在类型中定义Finalizer来保证资源得到释放。
7) 对象的Finalizer被执行的时间是在对象不再被引用后的某个不确定的时间。注意并非和C++中一样在对象超出声明周期时立即执行析构函数
8) Finalizer的使用有性能上的代价。需要Finalization的对象不会立即被清除,而需要先执行Finalizer.Finalizer,不是在GC执行的线程被调用。GC把每一个需要执行Finalizer的对象放到一个队列中去,然后启动另一个线程来执行所有这些Finalizer,而GC线程继续去删除其他待回收的对象。在下一个GC周期,这些执行完Finalizer的对象的内存才会被回收。
9) .NET GC使用"代"(generations)的概念来优化性能。代帮助GC更迅速的识别那些最可能成为垃圾的对象。在上次执行完垃圾回收后新创建的对象为第0代对象。经历了一次GC周期的对象为第1代对象。经历了两次或更多的GC周期的对象为第2代对象。代的作用是为了区分局部变量和需要在应用程序生存周期中一直存活的对象。大部分第0代对象是局部变量。成员变量和全局变量很快变成第1代对象并最终成为第2代对象。
10) GC对不同代的对象执行不同的检查策略以优化性能。每个GC周期都会检查第0代对象。大约1/10的GC周期检查第0代和第1代对象。大约1/100的GC周期检查所有的对象。重新思考Finalization的代价:需要Finalization的对象可能比不需要Finalization在内存中停留额外9个GC周期。如果此时它还没有被Finalize,就变成第2代对象,从而在内存中停留更长时间。
5、unity中协程的理解
协程的本质是一个分部执行函数,在unity的mainThread中执行,unity在每帧的更新中,都会执行各个协程调用,分别在FixedUpdate和LateUpdate之后的一些协程调用上,其本质就是一个迭代器,当遇到条件不满足的时候会被挂起,条件满足的时候,会被唤醒来继续执行。举个在其他地方看到的例子吧,这样便于讲解过程:
void Start() { StartCoroutine(Test1()); } IEnumerator Test1() { LogWrapper.Error("a1"); yield return Test2(); LogWrapper.Error("a2"); } IEnumerator Test2() { LogWrapper.Error("b1"); yield return null; LogWrapper.Error("b2"); }
会输出什么的顺序:a1, b1, b2, a2
执行的顺序是先输出a1,然后执行Test2,输出b1,这时候遇到yield return null ,被挂起,在下一帧,被唤醒,继续执行,输出b2, 接着执行输出a2
如果对这个过程理解了,那么协程基本就没问题了
6、unity中meta文件的作用
有两个作用,第一是包含了当前资源(代码或者prefab, 图片等)在当前工程中唯一的guid, unity获取资源是依据guid来获取的,所以每个资源都会附带生成一份meta文件;
第二个,包含了当前资源的导入信息,比如图片资源,会包含一下bump等相关的信息
7、unity UGUI的自适应方案设计
这是很多游戏中都会需要处理的一个问题,现在晚上的解决方案有这样的示例:UGUI的自适应方案,这里面简单的讲解了一下Canvas和Canvas Scaler的设置,其中对于Canvas设置为Scree Space-Camera的render mode,对于canvas scaler,设置UI Scale Mode为Scale With Screen Size, 然后填写对应的resolution的width 和height, Screen Match Mode 示例中设置为Match Width or Height, 对于这种匹配方式,其Match值为0的时候是依据Width来匹配,Match值为1的时候,是依据Height来匹配。不过一般的工程中,都是采用Expand的匹配方式,具体的流程我写一份伪代码来阐述:
1)首先判断当前系统的平台,主要分为ios/android/PC三种主流平台;
2)针对不同的平台,读取不同的SystemInfo的参数来设置当前应该设置的renderLevel,具体的参数读取和判断,每个项目可能设置的不一样;
3)根据获取的renderLevel,再来设置当前Screen的width和height, renderLevel主要分为高,中,低三个档次
4)对于高中低三个档次,分别不同的处理,
高,直接将当前屏幕的width和height设置为最终的width/height;
中,则根据当前读取的屏幕的height来做不同的设置
低,则将当前屏幕的width/height减半;
对于中低两个档次的设置,最后还需要执行一次adjust,避免width低于最低width,然后对比初始width/height和计算后的width/height的比值大小,做对应的width或者height的调整;
最后,都调用Screen.SetResolution(width, height, Screen.fullScreen)这个接口来实现自适应的匹配
8、c#的虚函数的调用
在查找这个问题的时候,找到一篇非常赞的博文:c#之虚函数
摘用作者的几句话,详尽的解释了虚函数的特点和执行过程:
虚函数的特点:
虚函数前不允许有static\abstract\override等修饰字,不能私有(private不能有)
虚函数的执行:
一般函数在编译时期就静态的编译到执行文件中,其相对地址在程序运行期间是不会发生变化的;
虚函数在编译期间不被静态编译,其相对地址不确定,而是根据运行时期对象实例来动态判断要调用的函数。
1)当调用一个对象的函数时,首先检测该对象的申明类,看该方法是否为虚函数;
2)如果不为虚函数,则直接执行该函数,如果为虚函数,则检测该对象的实例类;
3)检测实例类中是否有实现该虚函数或者重新实现该虚函数(override),如果有,则执行该虚函数,否则继续查找该实例的父类,知道找到第一个重载或者实现了该虚函数的地方,执行该虚函数。
未完待续,持续更新ing

 浙公网安备 33010602011771号
浙公网安备 33010602011771号