python常用标准库和第三方库使用全面总结
本文主要聚焦常用的Python库,便于查阅和使用。框架式的第三方库(如机器学习,深度学习,网络编程等)将以链接的形式不断补充。
数学运算
numpy
用于随机生成和矩阵运算
随机模块
import numpy as np
np.random.rand()# 用于生成[0.0, 1.0)之间的随机浮点数,当没有参数时,返回一个随机浮点数,当有一个参数时,返回该参数长度大小的一维随机浮点数数组
np.random.randn(n)# 数返回一个样本,具有标准正态分布
np.random.randint(low[, high, size])# 返回随机的整数,位于半开区间 [low, high)
random_integers(low[, high, size])# 返回随机的整数,位于闭区间 [low, high]
np.random.shuffle(x)# 类似洗牌,随机打乱顺序
np.random.permutation(x)# 返回一个随机排列
# 随机选择元素
# a:数组,或是整数N代表range(N)
# size:抽取样本数
# replace:True代表放回抽样,False代表不放回抽样
# p:抽取每个样本的概率,一定与a同型
# 例:
a1=np.random.choice(a=5, size=3, replace=False, p=[0.2, 0.1, 0.3, 0.4, 0.0]) # 输出结果:[0 3 2]
a2=np.random.choice(['n','s','e','w'], 5, p=[0.5, 0.1, 0.1, 0.3])
# 输出结果:['n', 'e', 'n', 'n', 'n']
数据运算
import numpy as np
# 定义
a = np.array([[1, 2], [3, 4]]) # 列表转换ndarray对象
b = np.arange(1, 10) # 连续整数列
c,d = np.ones((2,3)),np.zeros((2,3)) # 全1阵,零矩阵
e = np.linspace(1, 10, 4) # 首项为1末项为10长度为4的等差数列
f = np.logspace(0,3,4) # 首项为10^0末项为10^3长度为4的等比数列
# 形状
c.shape # 获得形状
c.reshape((2, 3)) # 改变形状
d.flatten() # 展平成一维向量
d.squeeze() # 去除值为1的维度
# 运算
# + - * / ** ==: 元素加/减/乘/除/平方/逻辑运算
# @: 矩阵乘法
# [备注]:对于二维以上矩阵可设置操作维度,如axis=0(对列),axis=1(对行)
a.min() # 最小值
a.max() # 最大值
a.argmin() # 第一个最小值的索引
a.argmax() # 第一个最大值的索引
a.mean() # a平均值
a.median() # a中位数
a.var()/a.std() # a方差/标准差
a.cumsum() # a累计和
a.diff() # a逐项差
a.nonzero() # 返回n维矩阵a中非零元的坐标信息
a.sort() # 对数组a每一维排序
a.transpose() # 转置
a.clip(min,max) # 限定a中所有值都在[min,max]范围内
# 遍历&合并&拆分
np.nditer(a) # 遍历n维数组的生成器
np.r_[a,b]/np.c_[a,b]/np.vstack((a,b))/np.hstack((a,b)) # 合并
np.hsplit(a,n)/np.vsplit(a,n) # 将矩阵a垂直/水平均等分成n块
# 图像相关
np.flip(img,mode) # 1水平翻转,2上下翻转
cv2.flip(img,mode) # 1水平翻转,0上下翻转,-1上下翻转
img[::-1,:,:] # 上下翻转
img[:,::-1,:] # 左右翻转
img[None]/img[np.newaxis,:] # 增加图片维度
文件读写
# 文件读写
import numpy as np
from scipy.io import loadmat,savemat
a = np.arange(6).reshape(2,3)
b = np.zeros_like(a)
# 储存单个文件
a.tofile('data_a.pkl') # 将数据存储为二进制文件
a.tofile('data_a.txt',sep=' ') # 指定分隔符以文本文件储存
np.save('data_a.npy',a) # 将数据存储为二进制文件,能够保留高维数组维度信息,首选
# 储存多个文件
np.savez('data_a.npz',a=a,b=b) # 将多个数据存储为二进制文件
savemat('data_a.mat',{'a':a,'b':b}) # 将多个数据存储为mat文件
# 读取单个文件
A1 = np.fromfile('data_a.pkl',dtype=int)
A2 = np.fromfile('data_a.txt',dtype=int,sep=' ')
A3 = np.load('data_a.npy')
# 读取多个文件
AB1 = np.load('data_a.npz')
A,B = AB1['a'],AB1['b']
AB2 = loadmat('data_a.mat')
A_,B_ = AB2['a'],AB2['b']
scipy
import numpy as np
from scipy.integrate import quad, dblquad
'''积分'''
# 定积分
print('-' * 30 + '定积分计算' + '-' * 30)
y = lambda x, a, b: np.sqrt(a * x ** 2 + b * np.sin(x))
I, err = quad(y, 0, 1, args=(2, 1))
print('积分值为:', I)
print('积分误差为:', err)
# 计算曲面积分
print('-' * 30 + '曲面积分计算' + '-' * 30)
I, err = dblquad(lambda x, y: x * y, # 被积函数
-1, 2, # 下界和上界
lambda y: y ** 2, lambda y: y + 2)
print('积分值为:', I)
print('积分误差为:', err)
'''求解非线性方程组'''
from scipy.optimize import fsolve
print('-' * 30 + '非线性方程组计算' + '-' * 30)
def func(t):
x, y, z = t
return [x + 2 * y + 3 * z - 6,
5 * x ** 2 + 6 * y ** 2 + 7 * z ** 2 - 18,
9 * x ** 3 + 10 * y ** 3 + 11 * z ** 3 - 30]
s = fsolve(func, np.random.rand(3))
print('方程的解为:', s)
'''求函数极值点和最值点'''
print('-' * 30 + '极值最值计算1' + '-' * 30)
from scipy.optimize import fmin, fminbound, minimize, leastsq
import pylab as plt
yx = lambda x: x ** 2 + 10 * np.sin(x) + 1
x = np.linspace(-6, 6, 100)
x1 = fmin(yx, 5) # 求5附近的极小点
print("极小点:", x1);
x2 = fminbound(yx, -6, 6) # 区域的最小点
print("最小值为:", yx(x2))
plt.plot(x, yx(x));
plt.show()
print('-' * 30 + '极值最值计算2' + '-' * 30)
def f(X):
x, y = X
return (x - 1) ** 4 + 5 * (y - 1) ** 2 - 2 * x * y
X = minimize(f, [0, 0]).x
val = minimize(f, [0, 0]).fun
print("极小点和极小值分别为:", X, ',', val)
x = y = np.linspace(-1, 4, 100)
x, y = np.meshgrid(x, y)
c = plt.contour(x, y, f((x, y)), 40)
plt.clabel(c);
plt.colorbar()
plt.plot(X[0], X[0], 'Pr');
plt.show()
'''最小二乘法'''
# f(x,y)=axy+bsin(cx),取a=2,b=3,c=4构造数据,利用模拟数据反过来拟合函数
from scipy.optimize import curve_fit
print('-' * 30 + '最小二乘法' + '-' * 30)
x = y = np.linspace(-6, 6, 30)
fxy = lambda t, a, b, c: a * t[0] * t[1] + b * np.sin(c * t[0])
z = fxy([x, y], 2, 3, 4)
p = curve_fit(fxy, [x, y], z, bounds=([1, 2, 3], [3, 4, 5]))[0]
print(p)
# 非线性拟合,必须得约束拟合参数的上界与下界才能得到好的拟合结果
'''求微分方程的数值解'''
# 求解下列微分方程组:
# x'=-x^3-y,x(0)=10
# y'=x-y^3,y(0)=0.5 0<=t<=30
from scipy.integrate import odeint
import pylab as plt
print('-' * 30 + '求解微分方程的数值解' + '-' * 30)
2
plt.rc('text', usetex=True)
plt.rc('font', family="SimHei")
def func(w, t):
x, y = w;
return [-x ** 3 - y, x - y ** 3]
t = np.linspace(0, 30, 100)
s = odeint(func, [1, 0.5], t)
plt.subplot(121)
plt.plot(t, s[:, 0], '*-', label="$x(t)$") # 画出了x(t)的解曲线
plt.plot(t, s[:, 1], '--p', label="$y(t)$") # 画出了y(t)的解曲线
plt.legend()
plt.subplot(122)
plt.plot(s[:, 0], s[:, 1]) # 画出解的轨迹线
plt.show()
sympy
表格处理
csv
用于csv基本读写,python内置库,示例如下:
import csv
table = [{'age': '30', 'name': 'John', 'last_name': 'Doe'}, {'age': '30', 'name': 'Jane', 'last_name': 'Doe'}]
with open('my.csv', 'w+') as csv_file:
headers = [k for k in table[0]]
writer = csv.DictWriter(csv_file, fieldnames=headers)
writer.writeheader()
for item in table:
writer.writerow(item)
with open('my.csv', 'r+') as csv_file:
reader = csv.DictReader(csv_file)
for row in reader:
print(row)
相比而言pandas读写文件更多样,对于excel表格读写:df=pd.read_excel()读取*.xlsx数据,df.to_excel()保存数据。读取参数见下表:

各种Excel读写库比较:
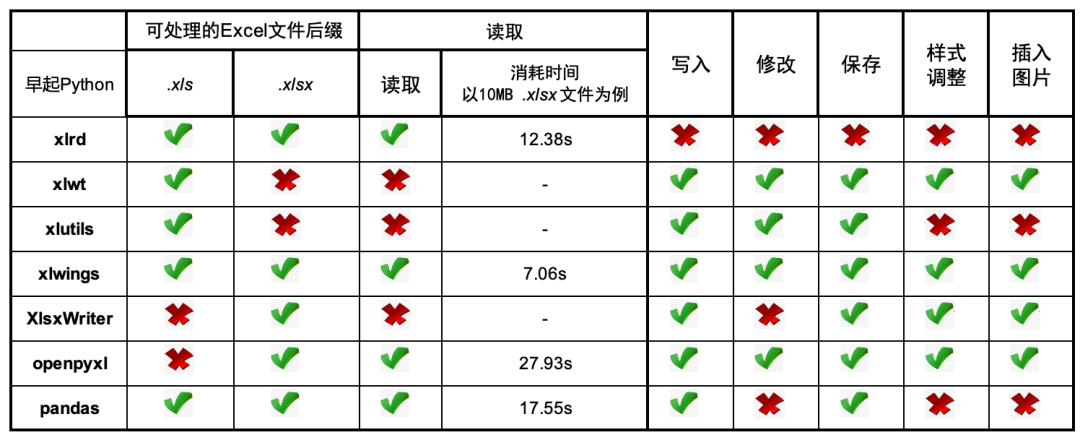
pandas
加速表格数据的处理,常用$$split→apply→combine$$流程进行数据分组。详细用法参考joyfulpandas
科研绘图
实用网站总结:
地图绘制folium(obj.save('*.html')储存成.html用网页打开)
matplotlib
使用默认样式
import matplotlib.pyplot as plt
import numpy as np
if __name__ == '__main__':
# 随机生成数据
data = [
[0.90, 0.91, 0.92, 0.93, 0.94, 0.95, 0.96],
[0.89, 0.92, 0.93, 0.94, 0.94, 0.95, 0.95],
[0.87, 0.90, 0.91, 0.92, 0.93, 0.94, 0.94],
[0.88, 0.89, 0.91, 0.94, 0.96, 0.98, 0.985],
]
plt.style.available # 查看所有可用样式列表
plt.style.use('seaborn-colorblind') # 使用样式
plt.plot(np.transpose(data)) # 列向量绘图
plt.grid(True)
plt.xlabel("epoch")
plt.ylabel("accuracy")
plt.title("Title")
plt.legend(["model 1","model 2","model 3","model 4"], loc="best")
plt.show()
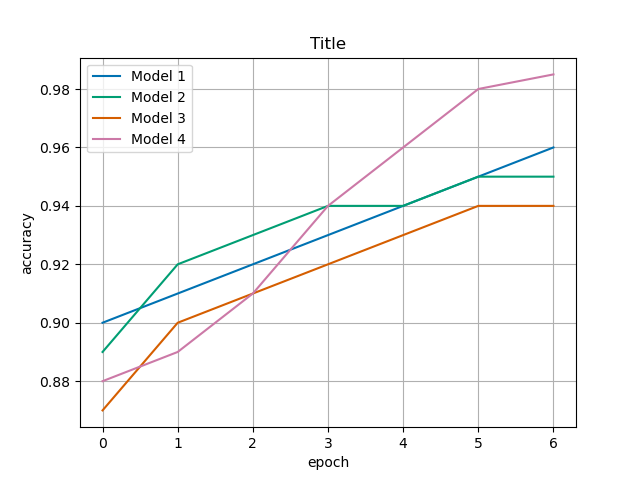
亦可手动设置样式
import matplotlib.pyplot as plt
import pandas as pd
if __name__ == '__main__':
# 全局设置
params = {
"font.size": 14, # 全局字号
'font.family': 'STIXGeneral', # 全局字体,微软雅黑(Microsoft YaHei)可显示中文
"figure.subplot.wspace": 0.2, # 图-子图-宽度百分比
"figure.subplot.hspace": 0.4, # 图-子图-高度百分比
"axes.spines.right": True, # 坐标系-右侧线
"axes.spines.top": True, # 坐标系-上侧线
"axes.titlesize": 14, # 坐标系-标题-字号
"axes.labelsize": 14, # 坐标系-标签-字号
"legend.fontsize": 14, # 图例-字号
"xtick.labelsize": 12, # 刻度-标签-字号
"ytick.labelsize": 12, # 刻度-标签-字号
"xtick.direction": 'in', # 刻度-方向
"ytick.direction": 'in' # 刻度-方向
}
plt.rcParams.update(params)
# 随机生成数据
data = [
[0.90, 0.91, 0.92, 0.93, 0.94, 0.95, 0.96],
[0.89, 0.92, 0.93, 0.94, 0.94, 0.95, 0.95],
[0.87, 0.90, 0.91, 0.92, 0.93, 0.94, 0.94],
[0.88, 0.89, 0.91, 0.94, 0.96, 0.98, 0.985],
]
df = pd.DataFrame(data)
fig, ax = plt.subplots() # 添加图和坐标系
# 设置图表信息
props = {'title': 'Title', # 坐标系-标题
'xlabel': 'epoch', # 坐标系-坐标轴-标签
'ylabel': 'accuracy'} # 坐标系-坐标轴-标签
ax.set(**props)
# 单独设置每条线样式
style_dict = {
0: dict(label='Model 1', linewidth=3, linestyle=':', marker='o', markersize=6, color='#E15F0F'), # DE4312深一点的红
1: dict(label='Model 2', linewidth=3, linestyle='-', marker='*', markersize=6, color='#E6730A'),
2: dict(label='Model 3', linewidth=3, linestyle='--', marker='s', markersize=6, color='#abdda4'),
3: dict(label='Model 4', linewidth=3, linestyle='-.', marker='v', markersize=6, color='#2b83ba')
}
# 画出每条线
for i in range(df.shape[0]):
ax.plot(df.columns, df.iloc[i], **style_dict[i]) # 坐标系-线
plt.grid('minor')
plt.legend(loc='best')
plt.show()
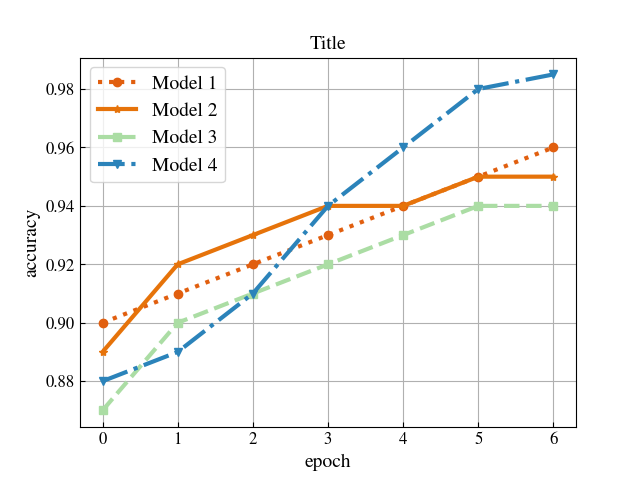
seaborn
常用热力图(二维矩阵的可视化方法),举例如下:
import matplotlib.pyplot as plt
import seaborn as sns
# 设置
plt.rcParams['font.sans-serif'] = ['STIXGeneral']
plt.rcParams['axes.unicode_minus'] = False
sns.set_context({"figure.figsize": (8, 8)}) # 设置热力图大小
sns.set(font_scale=1) # 设置热力图中字体大小
'''
vmax:设置颜色带的最大值
vmin:设置颜色带的最小值
cmap:设置颜色带的色系,参考 https://blog.csdn.net/weixin_39777626/article/details/95892284
center:设置多种颜色构成色带的分界线位置
annot:是否显示数值注释
fmt:format的缩写,设置数值的格式化形式
linewidths:控制每两小方格之间的线宽
linecolor:控制分割线的颜色
cbar_kws:颜色带方向等的设置,cbar_kws={"orientation":"horizontal"}横向显示色带
mask:传入布尔型矩阵,若为矩阵内为True,则热力图相应的位置的数据将会被屏蔽掉,常用在绘制相关系数矩阵图
'''
data = sns.load_dataset("flights").pivot("month", "year", "passengers") # 导入数据
sns.heatmap(data=data, annot=True, fmt="d", linewidths=0.3, cmap="RdBu_r") # 绘图
# plt.xticks(rotation=0,fontsize=12) 设置x轴刻度字体大小和旋转角度
plt.show()
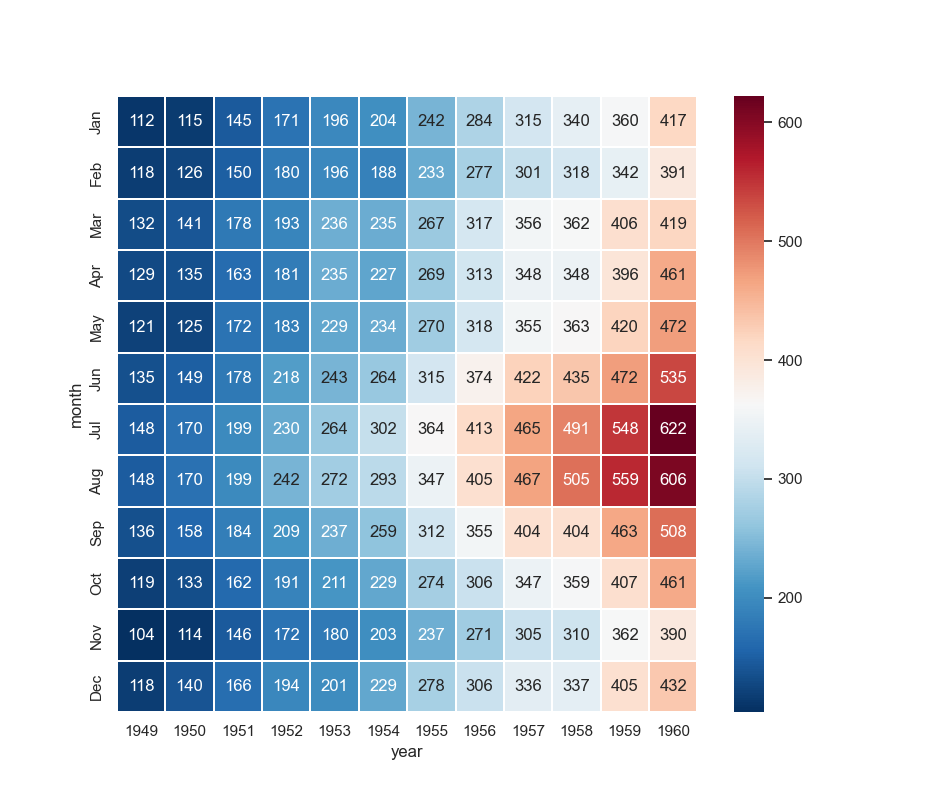
pyecharts
python+echarts,用html样式绘图
文件操作
os
路径处理
import os
import sys
sys.argv[0](代码)||__file__(控制台) # 获得当前文件绝对路径
os.getcwd() # 获得当前文件所在文件夹绝对路径
os.chdir(path) # 更改当前目录至path
filepath,filename=os.path.split(path) # 分割路径,文件名
name,external=os.path.splitext(path) # 分割文件名字,扩展名
os.path.exists(path) # 判断路径是否存在
os.path.isfile(path) # 检验给出的路径是否是一个文件
os.path.isdir(path) # 检验给出的路径是否是一个目录
# 层序遍历文件结构:os.walk()
for root, dirs, files in os.walk('.'):
print('root_dir:', root) # 对当前目录路径操作
print('sub_dirs:', dirs) # 对当前路径下所有子目录操作
print('files:', files) # 对当前路径下所有文件操作
目录操作
os.makedirs(path) # 递归创建path所包括的文件夹
os.mkdir(path) # 仅创建叶文件夹,上级目录必须存在
os.rmdir(path) # 删除文件夹
os.remove(file) # 删除文件
os.path.getsize(x) # 获得文件/文件夹的byte大小
os.path.getatime(x) # 获取文件或目录的最近访问时间
os.path.getctime(x) # 获取文件或目录的最近创建时间
os.path.getmtime(x) # 获取文件或目录的最近修改时间
os.listdir(path) # 获得path目录下的所有文件+文件夹
os.rename("oldname","newname") # 重命名,目录/文件均可
shutil
用于文件的复制、移动、删除,作为os库的补充
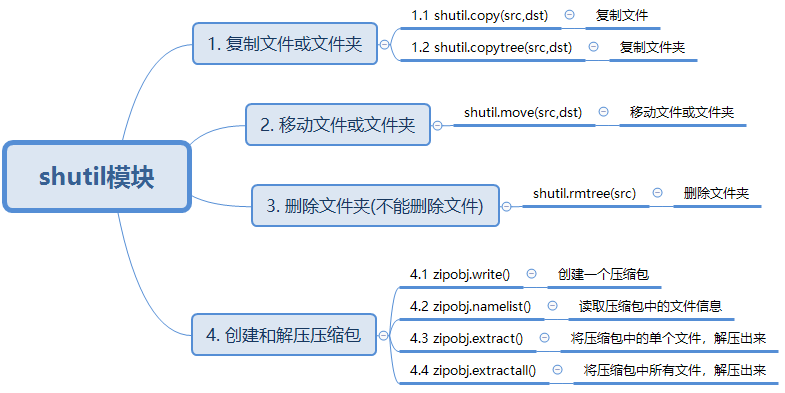
# 1.复制
shutil.copy(src,dst) # 用来复制文件,还可以复制文件且重命名
shutil.copytree(src,dst) # 用来递归复制src文件夹中内容到一个未生成的路径
# 2.移动
shutil.move(src,dst) # 移动文件/文件夹
# 3.删除
shutil.rmtree(path) # 递归删除文件夹中所有内容
glob
用于文件搜索。支持通配符*,?,[],输入文件路径,返回指定路径下所有匹配的完整文件名。
from glob import glob
glob.glob(r'c:\*.txt') # 获得C盘下的所有txt文件
f = glob.iglob(r'../*.py') # 获得父目录中的所有.py文件,返回迭代器
zipfile
用于文件的压缩与解压
# 压缩
import zipfile
import os
file_list = os.listdir(os.getcwd()) # 将该文件夹所有文件打包
with zipfile.ZipFile(r"myzip.zip", "w") as zipobj:#没有open
for file in file_list:
zipobj.write(file)
# 读取与解压
dst = "." # 将压缩包中的所有文件解压到dst目录下
with zipfile.ZipFile("myzip.zip", "r") as zipobj:
print(zipobj.namelist())
zipobj.extract("test.ipynb",dst) # 解压特定文件
zipobj.extractall(dst) # 全部解压
read&write
图形界面
turtle
tkinter
pygame
待完善
pyqt
待完善
图片处理
read/show/save images
-
cv2
import cv2 # 读取图片:默认三维np数组[height,width,channel],设置模式可读取灰度图 # OpenCV目前支持读取bmp、jpg、png、tiff等常用格式 I = cv2.imread('test.png') # 显示图片 window_name = 'display image' cv2.namedWindow(window_name,0) cv2.imshow(window_name,I) cv2.waitKey() # 存储图片 cv2.imwrite('test.jpg',I) -
PIL.Image
from PIL import Image import numpy as np # 读取图片 I = Image.open('test.png') # 显示图片 I.show() # 储存图片 I.save('test.gif') # PIL对象转换为np数组 I_array = np.array(I) -
matplotlib.pyplot
import matplotlib.pyplot as plt # 读取图片 img=plt.imread('test.png') # 显示图片 plt.imshow(img) plt.show() # 保存图片 plt.imsave('test.jpg',img) -
skimage.io
from skimage import io # 读取图片 I = io.imread('test.png') # 显示图片 io.imshow(I) io.show() # 保存图片 io.imsave('test.gif', I)
opencv
数字图像处理常用函数汇总如下:
音频视频
音频
使用pygame异步播放音频
import pygame
import time
def playmusic(audio):
pygame.mixer.init()
print("播放音乐")
track = pygame.mixer.music.load(audio)
pygame.mixer.music.play(start=0, loops=2)
time.sleep(1e5)
pygame.mixer.music.stop() # 停止播放,
pygame.mixer.music.pause() # 暂停播放。
pygame.mixer.music.unpause() # 取消暂停。
pygame.mixer.music.fadeout(time=500) # 淡出,在time毫秒的时间内音量由初始值渐变为0,最后停止播放。
pygame.mixer.music.set_volume(volume=0.5) # 设置播放的音量,音量value的范围为0.0到1.0。
pygame.mixer.music.get_busy() # 判断是否在播放音乐,返回1为正在播放。
pygame.mixer.music.set_endevent(
pygame.USEREVENT + 1) # 在音乐播放完成时,用事件的方式通知用户程序,设置当音乐播放完成时发送pygame.USEREVENT+1事件给用户程序。
# pygame.mixer.music.queue(filename) 指定下一个要播放的音乐文件,当前的音乐播放完成后自动开始播放指定的下一个。一次只能指定一个等待播放的音乐文件。
if __name__ == '__main__':
audiosrc = 'test.wav'
playmusic(audio=audiosrc)
语音-文本互相转换模块详见我的仓库:
moviepy
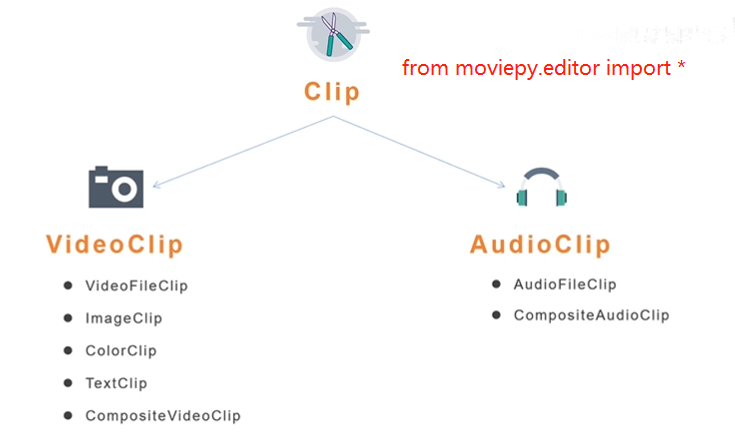
文本处理
pdfminer
pdf文件的读取方法:
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
from io import StringIO
def read_pdf(filename, pages=None):
if not pages:
pagenums = set()
else:
pagenums = set(pages)
output = StringIO()
manager = PDFResourceManager()
converter = TextConverter(manager, output, laparams=LAParams())
interpreter = PDFPageInterpreter(manager, converter)
infile = open(filename, 'rb')
for page in PDFPage.get_pages(infile, pagenums):
interpreter.process_page(page)
infile.close()
converter.close()
text = output.getvalue()
output.close()
return text
if __name__ == '__main__':
filename = 'test.pdf'
content = read_pdf(filename)
print(content)
机器学习&深度学习
scikit-learn
torch
request
异步编程
threading
-
创建、命名
以函数激活线程,构造的时候可以给线程取名便于多线程管理
-
Thread 的生命周期
- 创建对象时线程内部被初始化,调用 start() 方法后线程会开始运行。
- thread 代码正常运行结束或者是遇到异常,线程会终止。
- 可以通过 Thread 的 is_alive() 方法查询线程是否还在运行。
[备注]:is_alive() 返回 True 的情况是 Thread 对象被正常初始化,start() 方法被调用,然后线程的代码还在正常运行。
import threading import time def test(): for i in range(5): print(threading.current_thread().name+' test ',i) time.sleep(0.5) thread = threading.Thread(target=test,name='TestThread') thread.start() for i in range(5): print(threading.current_thread().name+' main ', i) print(thread.name+' is alive ', thread.isAlive()) time.sleep(1) -
阻塞线程
主线程创建了thread后,thread.start(),然后thread.join() 主线程一直被阻塞,直到thread结束才开始主线程。thread.join(timeout=1.0)表示主线程等待1s。
-
Daemon
# Daemon为bool值 # False(默认):子线程不随主线程一起结束,主线程结束子线程还能继续 # True:子线程随主线程一起结束,主线程结束子线程立即停止 # 设置 Daemon = True两种方法: # 法一 thread =threading.Thread(target=test,name='TestThread',daemon=True) # 法二 thread =threading.Thread(target=test,name='TestThread') thread.setDaemon(True) # 一定在start前设置 thread.start()
命令行
argparse
用于命令行参数解析
import argparse
# 1.初始化argparse对象,description表示命令行显示帮助信息时描述程序信息
parser = argparse.ArgumentParser(description="Demo of argparse")
# 2.add_argument('--name')函数来增加参数
parser.add_argument('-arch', required=True, choices=['alexnet', 'vgg'],help='we only support alexnet and vgg in CNN.')
'''
# default:设置缺省值
# required:表示参数是否一定需要设置
# type:声明参数类型
# choices:参数选择列表,只能从中选择
# help:指定参数的说明信息
# dest:设置参数在代码中的变量名,argparse默认的变量名是--或-后面的字符串,也可以通过dest=xxx来设置参数的变量名,然后在代码中用args.xxx来获取参数的值
# nargs:设置参数在使用可以提供的个数
N 整数,参数的绝对个数
'?' 0或1个参数
'*' 0或所有参数
'+' 所有,并且至少一个参数
'''
# 3. 获取解析的参数
args = parser.parse_args()
arch = args.arch
# 4.用解析出来的参数去执行函数
……
click
附
Python基础
重要基础语法
# 列表表达式
generator = (i**2 for i in range(10) if i%2)
gridlist = [(x,y) for x in range(10) for y in range(10)]
# 三目表达式、匿名函数
f = lambda argument: return_value1 if True else return_value2
# 字典排序/取出最大值对应的键值对
orderedlist = sorted(d.items(),key=lambda x:x[1]) # 按值排序,返回列表
maxitem = max(d.items(),key=lambda x:x[1])# 按值排序返回最大值对应元组
# map映射:可自定义复杂函数,返回生成器
map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 实现单数组逐元素平方
map(lambda x, y: x + y, [1, 3, 5], [2, 4, 6]) # 两数组函数映射到一数组
# 类中的默认属性和方法
__dir__() # 返回类内方法列表
__doc__() # 类文档
__hash__() # 对象哈希值
__new__() # 实例化时自动触发,分配空间地址
__str__() # 输出类对象时调用,返回值必须是字符串对象
__getitem__() # 元素索引
__setitem__() # 元素设置
__delitem__() # 元素删除
__getslice__() # 切片索引
__setslice__() # 切片设置
__delslice__() # 切片删除
# 运算符=/>=/>/<=/</!=/()重载
__eq__()/__ge__()/__gt__()/__le__()/__lt__()/__ne__()/__call__()
# __call__()与hasattr()搭配使用判断一个变量名是成员还是方法
hasattr(self.x,"__call__") # True说明是函数,False说明是成员变量
装饰器
装饰器在不修改原函数的内容和调用的条件下对原函数的功能进行扩展,符合面向对象编程的“对扩展开放,对修改封闭”的原则。装饰器是闭包的一种应用,简单的计时装饰器如下:
import time
def timing(f):
def wrap(*args, **kwargs):
time1 = time.time()
ret = f(*args, **kwargs)
time2 = time.time()
print('%s function took %0.3f ms' % (f.__name__, (time2 - time1) * 1000.0))
return ret
return wrap
@timing
def f():
for i in range(1000000):
pass
f()
类装饰器
-
@property:将函数视为变量调用
python无法设置私有属性,通过@property方法可以隐藏属性名,让用户进行使用的时候无法随意修改,示例如下:
class DataSet(object): def __init__(self): self._images = 1 self._labels = 2 #定义属性的名称 @property def images(self): #方法加入@property后,这个方法相当于一个属性,这个属性可以让用户进行使用,而且用户有没办法随意修改。 return self._images @property def labels(self): return self._labels l = DataSet() #用户进行属性调用的时候,直接调用images即可,而不用知道属性名_images,因此用户无法更改属性,从而保护了类的属性。 print(l.images) # 加了@property后,用调用属性的形式来调用方法,后面无需加()property对象还具有setter、deleter 可用作装饰器:setter是设置属性值。deleter用于删除属性值:
class C: def __init__(self): self._x = None @property def x(self): return self._x @x.setter def x(self, value): self._x = value @x.deleter def x(self): del self._x #实例化类 c = C() # 为属性进行赋值 c.x=100 # 输出属性值 print(c.x) # 删除属性 del c.x -
@abstractmethod:抽象方法
含abstractmethod方法的类不能实例化,继承了含abstractmethod方法的子类必须复写所有abstractmethod装饰的方法,未被装饰的可以不重写。
- @staticmethod:静态方法
类不需要创建实例的情况下可以通过类名直接调用方法。
class Algo:
name = "test"
def __init__(self, name):
self.name = name
@staticmethod
def add(x, y): #此处不需要传出self,函数不需要访问类
return x + y
# 该函数只能由实例调用
def multy(self, x, y):
return x * y
cls = Algo("felix")
print("通过实例引用方法")
print(cls.add(2, 3)) # 参数个数必须与定义中的个数保持一致,否则报错
print(cls.multy(2, 3))
print("类名直接引用静态方法")
print(Algo.add(4, 3)) # 参数个数必须与定义中的个数保持一致,否则报错
- @classmethod:类内方法
修饰的方法不需要实例化,不需要 self 参数,但第一个参数需要是表示自身类的 cls 参数,可以来调用类的属性,类的方法,实例化对象等,是将类本身作为操作的方法。类方法被哪个类调用,就传入哪个类作为第一个参数进行操作。
class A():
number = 10
@classmethod
def get_a(cls): #cls 接收的是当前类,类在使用时会将自身传入到类方法的第一个参数
print('这是类本身:',cls)# 如果子类调用,则传入的是子类
print('这是类属性:',cls.number)
class B(A):
number = 20
pass
# 调用类方法 不需要实例化可以执行调用类方法
A.get_a()
B.get_a()
Git

用命令行提交代码至Github/Gitee仓库:
在Github/Gitee创建新仓库获得url,写好README.md/.gitignore/LICENSE,在项目文件夹下git bash,输入以下命令:
git init
git remote rm origin
git remote add origin $url$
git add .
git commit -m "initial commit"
git push -u origin master
常见问题及解决:
-
OpenSSL SSL_read: Connection was reset, errno 10054 ...
# Solution1: 检查所配置的用户名,邮箱,移除仓库,重新添加 git config -l git config --global user.name "xxx" git config --global user.email "xxx" git remote rm origin git remote add origin $url$ # Solution2: 修改解除SSL认证 git config --global http.sslVerify "false" # Solution3: 增大缓存区 git config http.postBuffer 5242880003 # Solution4: 更新DNS缓存 ipconfig /flushdns -
Failed to connect to github.com port 443: Timed out
# 尝试关掉代理,或者设置中查看代理号重新手动设置代理 git config --global --unset http.proxy git config --global http.proxy http://127.0.0.1:1080 git config --global https.proxy http://127.0.0.1:180
欢迎留言补充

 浙公网安备 33010602011771号
浙公网安备 33010602011771号