CNN网络总结
从全连接到卷积
- 卷积即用一个像素值代表局部特征,特征对应原图的范围为感受野
- 权值共享,稀疏连接
- \({\displaystyle{out = floor(\frac{in+2p-k}{s})+1}}\)
LeNet
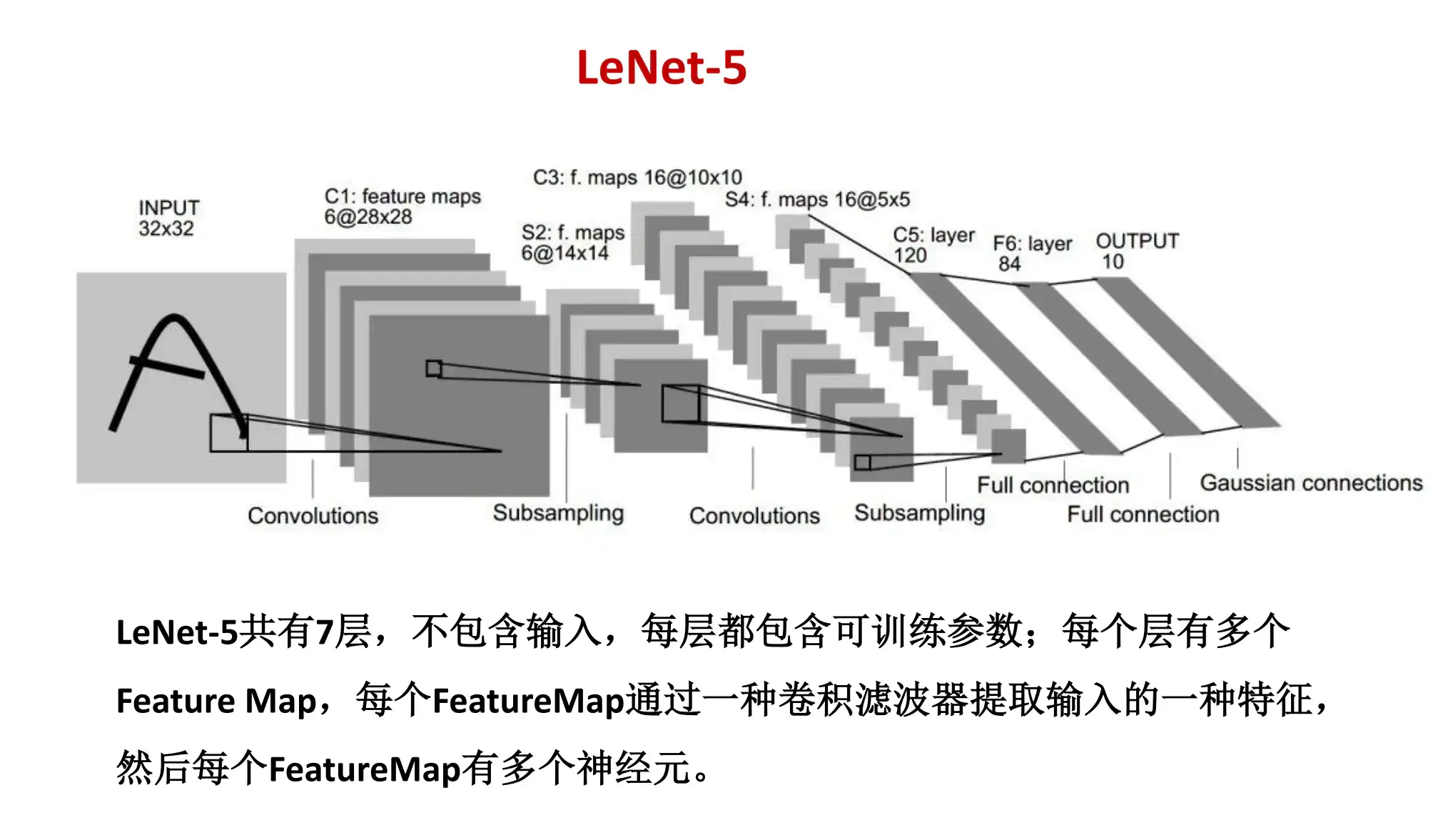
- (卷,池)× 2 + FC × 2 + Gauss(/softmax)十分类输出
- 小图手写数字效果明显,大图效果差
AlexNet(2012年ImageNet比赛冠军)
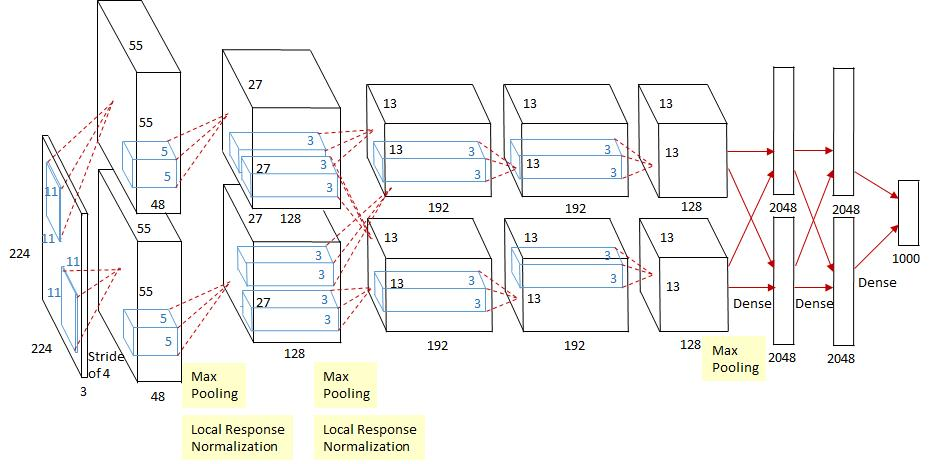
- 5层卷积和3层全连接
- 数据增强:对训练随机加一些变化(如平移、缩放、裁剪、旋转、翻转或者增减亮度),产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。\({\to}\)避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。
- Dropout:抑制过拟合
- ReLU:减少梯度消失现象
VGG
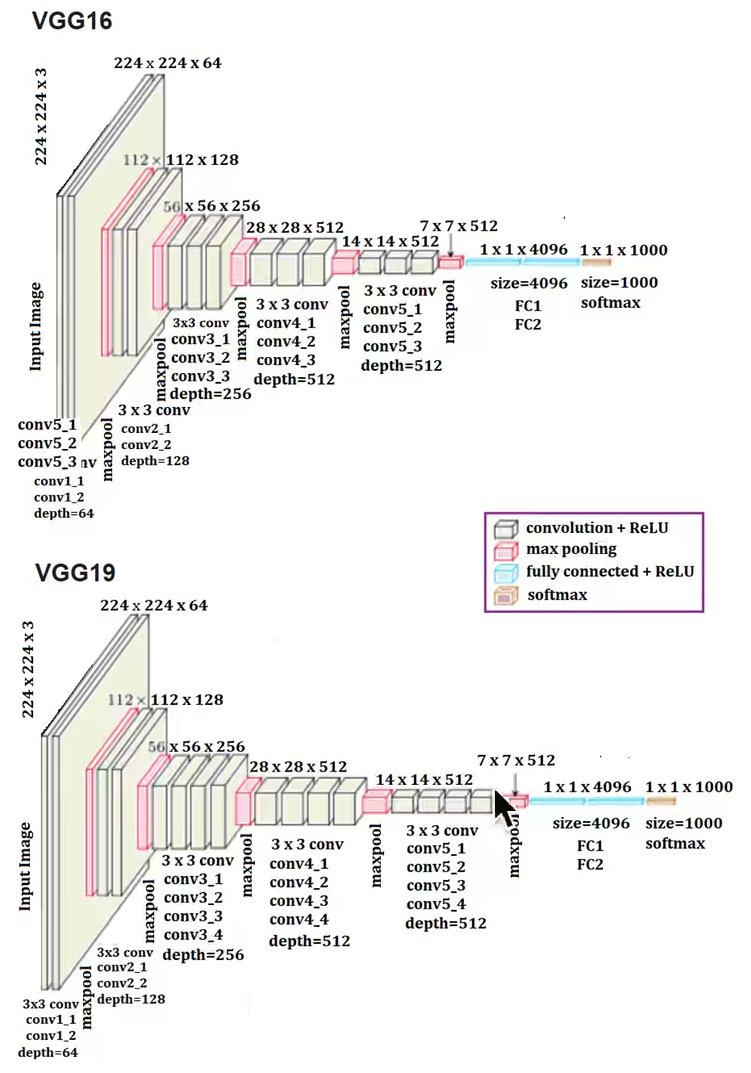
- VGG通过使用一系列大小为3x3的小尺寸卷积核和池化层,为构造深度卷积神经网络提供方向(减少参数个数可以堆叠更多的卷积层,加深网络的深度)
- 每层卷积将使用ReLU作为激活函数,在全连接层后添加dropout来抑制过拟合
GoogLeNet(2014年ImageNet比赛冠军)
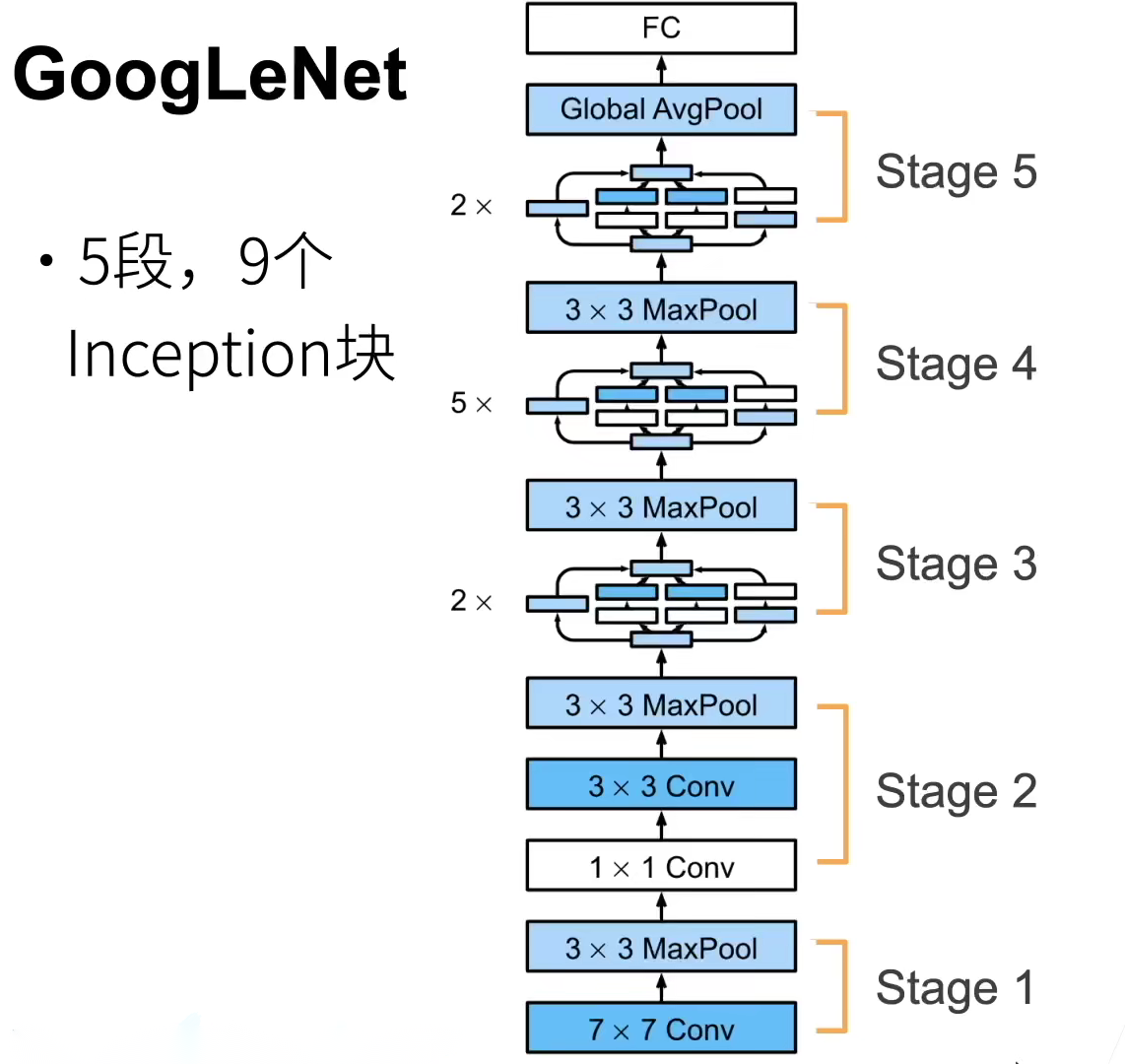
-
对于同一张图片,不同尺寸的卷积核由于感受野不同表现效果不一样,在不同尺度的图片里,需要不同大小的卷积核才能使性能最好。
-
模块化(首次提出,方便增添和修改)Inception结构中并列提供多种卷积核的操作,网络在训练的过程中通过调节参数自己选择。
-
使用1*1的卷积核解决参数过多的问题;同时会跟着有非线性激励,能够提升网络的表达能力。
-
采用了Global Average Pooling代替FC(想法来自Network in Network,将准确率提高0.6%)。由于Average Pooling没有参数,可以减少参数数量。
GAP:计算每张特征图所有像素点的均值,n个特征图组成n*1特征向量,就可以softmax分类计算
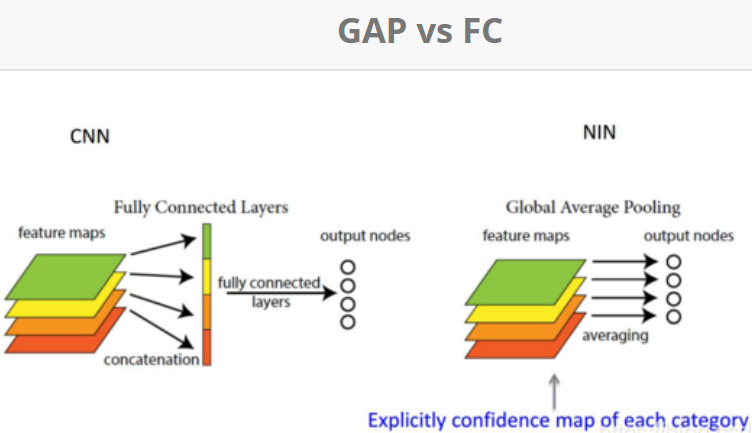
-
移除了全连接,依然使用了Dropout。
-
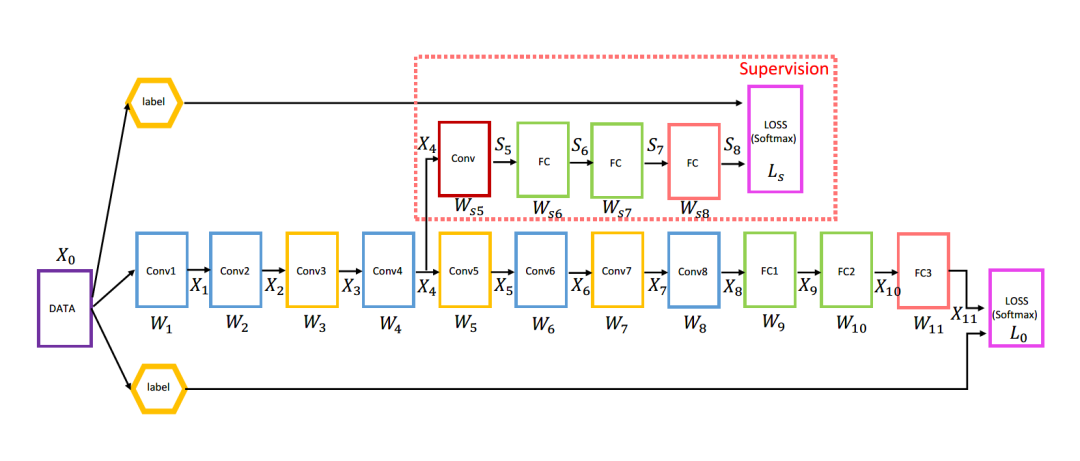
辅助分类器(仅训练时使用):网络额外增加了2个辅助的softmax用于向前传导梯度,为了避免梯度消失,也是一种类似正则化的手段。
2014年DSN(Deeply-Supervised Nets)提出deep supervision trick,在深度神经网络的某些中间隐藏层加了一个辅助的分类器作为一种网络分支来对主干网络进行监督的技巧,用来解决深度神经网络训练梯度消失和梯度爆炸等问题。
网络结构示例:
代码示例:
import torch.nn as nn # 定义卷积块 # 包含3x3卷积+BN+relu def conv3x3_bn_relu(in_planes, out_planes, stride=1): "3x3 convolution + BN + relu" return nn.Sequential( nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False), BatchNorm2d(out_planes), nn.ReLU(inplace=True), ) class C1DeepSup(nn.Module): def __init__(self, num_class=150, fc_dim=2048, use_softmax=False): super(C1DeepSup, self).__init__() self.use_softmax = use_softmax self.cbr = conv3x3_bn_relu(fc_dim, fc_dim // 4, 1) self.cbr_deepsup = conv3x3_bn_relu(fc_dim // 2, fc_dim // 4, 1) # 最后一层卷积 self.conv_last = nn.Conv2d(fc_dim // 4, num_class, 1, 1, 0) self.conv_last_deepsup = nn.Conv2d(fc_dim // 4, num_class, 1, 1, 0) # 前向计算流程 def forward(self, conv_out, segSize=None): conv5 = conv_out[-1] x = self.cbr(conv5) x = self.conv_last(x) if self.use_softmax: # is True during inference x = nn.functional.interpolate( x, size=segSize, mode='bilinear', align_corners=False) x = nn.functional.softmax(x, dim=1) return x # 深监督模块 conv4 = conv_out[-2] _ = self.cbr_deepsup(conv4) _ = self.conv_last_deepsup(_) # 主干卷积网络softmax输出 x = nn.functional.log_softmax(x, dim=1) # 深监督分支网络softmax输出 _ = nn.functional.log_softmax(_, dim=1) return (x, _)使用深监督技巧是U-Net等经典语义分割网络中的一个通用做法
Inception
Inception-v1(GoogLeNet)
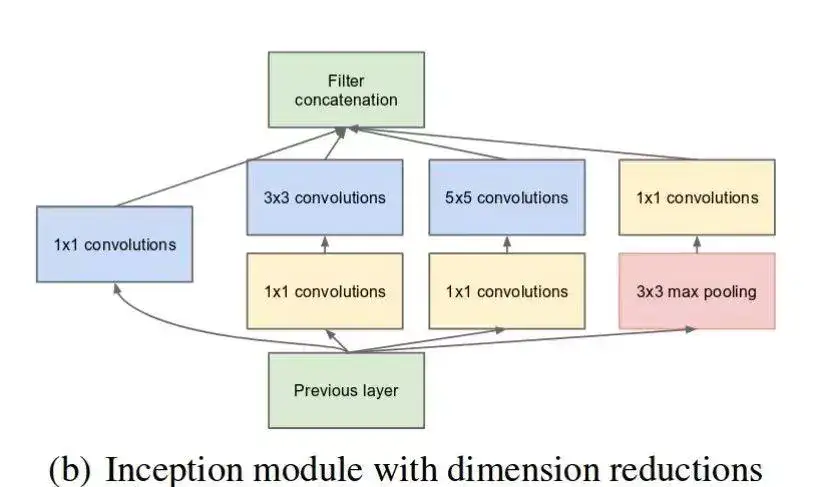
- 包含1x1卷积,3x3卷积和5x5卷积和3x3的max pooling层,这些卷积层和pooling层得到的特征concat在一起作为最终的输出,即下一个模块的输入。
- 大卷积核计算复杂度较大\({\to}\)先采用1x1卷积将特征的channel数降低,再进行前面所说的卷积(“瓶颈层”设计)。
Inception-v2(BN-Inception)
引入BN,使得每一层神经网络的输入保持相同标准分布。
理解batch normalization:https://www.cnblogs.com/guoyaohua/p/8724433.html
如果在图像处理中对输入图像进行白化(Whiten)操作(对输入数据分布变换到0均值,单位方差的正态分布),神经网络就会较快收敛。BN层对深层神经网络每个隐层神经元的激活值做简化版本的白化操作。
深层神经网络在做非线性变换前的激活输入值,随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因。BN就是通过规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域(非线性函数的线性区内,其对应的导数远离导数饱和区),以此避免梯度消失问题,加速训练收敛过程。

BN原理解读:首先计算特征的mean和var,然后进行归一化,但是为了保证一定的可变度,增加了gamma和beta两个训练参数进行缩放和偏移。在训练过程,还要记录两个累积量:moving_mean和moving_var,它是每个训练step中batch的mean和var的指数加权移动平均数。在inference过程,不需要计算mean和var,而是使用训练过程中的累积量。这种训练和测试之间的差异性是BN层最被诟病的,所以后面有一系列的改进方法,如Group Norm等。
Inception-v3
引入核心理念“因子化”(Factorization),将一些较大的卷积核分解成几个较小的卷积核,参数数量减少但感受野等价。
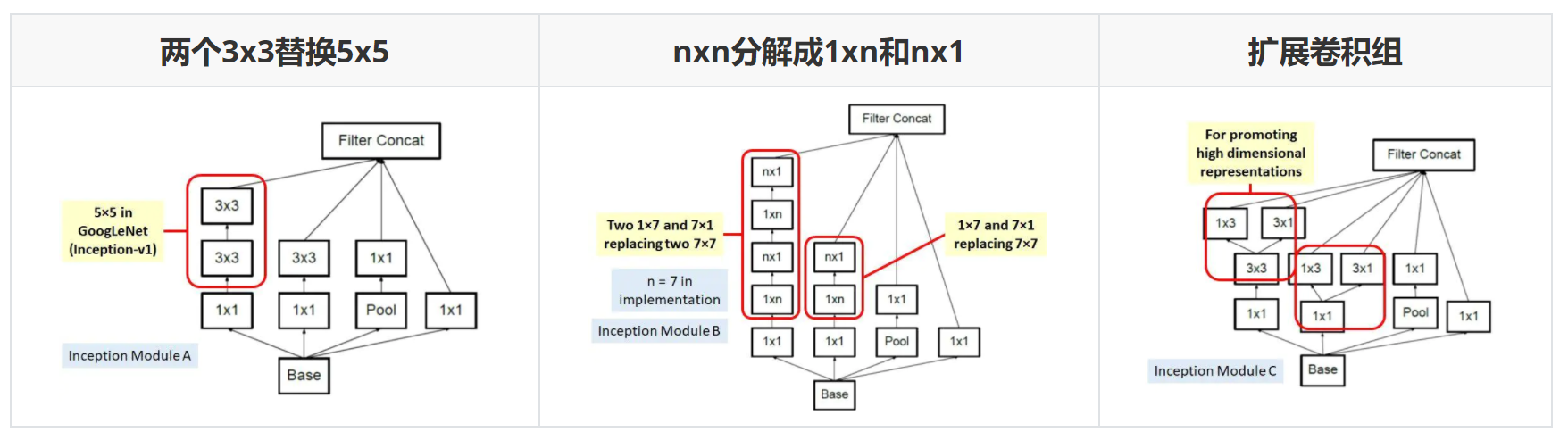
Inception-v3的另外的一个改进是不再直接使用max pooling层进行下采样,因为这样导致信息损失较大。一个可行方案是先进行卷积增加特征channel数量,然后进行pooling,但是计算量较大。所以作者设计了另外一种方案,即两个并行的分支,一个是pooling层,另外一个卷积层,最后将两者结果concat在一起。这样在使用较小的计算量情形下还可以避免瓶颈层,这种策略其实在ShuffleNet网络中也采用了。
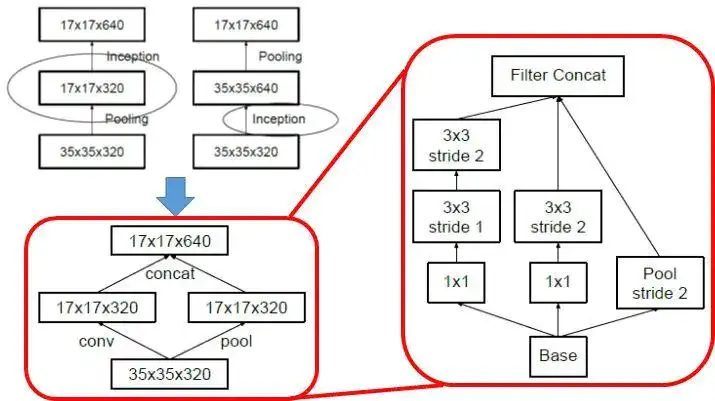
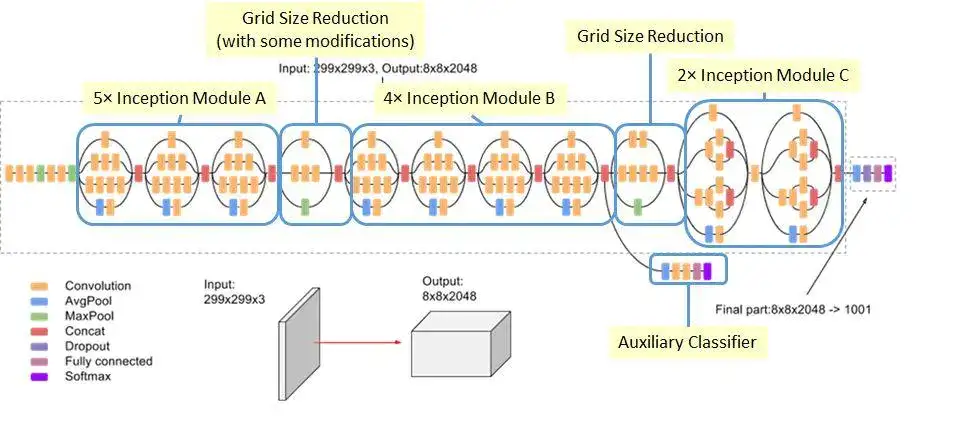
Inception-v3网络结构如下,较早的层采用模块A,中间层采用模块B,而后面层采用模块C。Inception-v3的默认输入大小是229x229。
-
使用了深度监督,即中间层引入loss。
-
采用了Label Smoothing技术正则化模型,提升泛化能力。
Label Smoothing主要理念是防止最大的logit远大于其它logits,因为可能会导致过拟合。具体实现通过改变one-hot编码的label即可。其中K是类别数,而ε=0.1是一个超参数。
\[new\_labels = (1 — ε) * one\_hot\_labels + ε / K \]
Inception-v4
对原来的版本进行了梳理
Inception-ResNet
加入残差结构没有很明显地提升模型效果,但是残差结构有助于加速收敛。
ResNet
-
直连通道,恒等映射,Highway Network,Identity,shortcut,skip connections
推广核心:create short paths from early layers to later layers
-
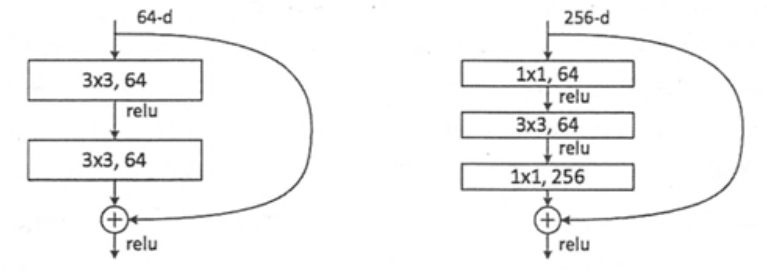
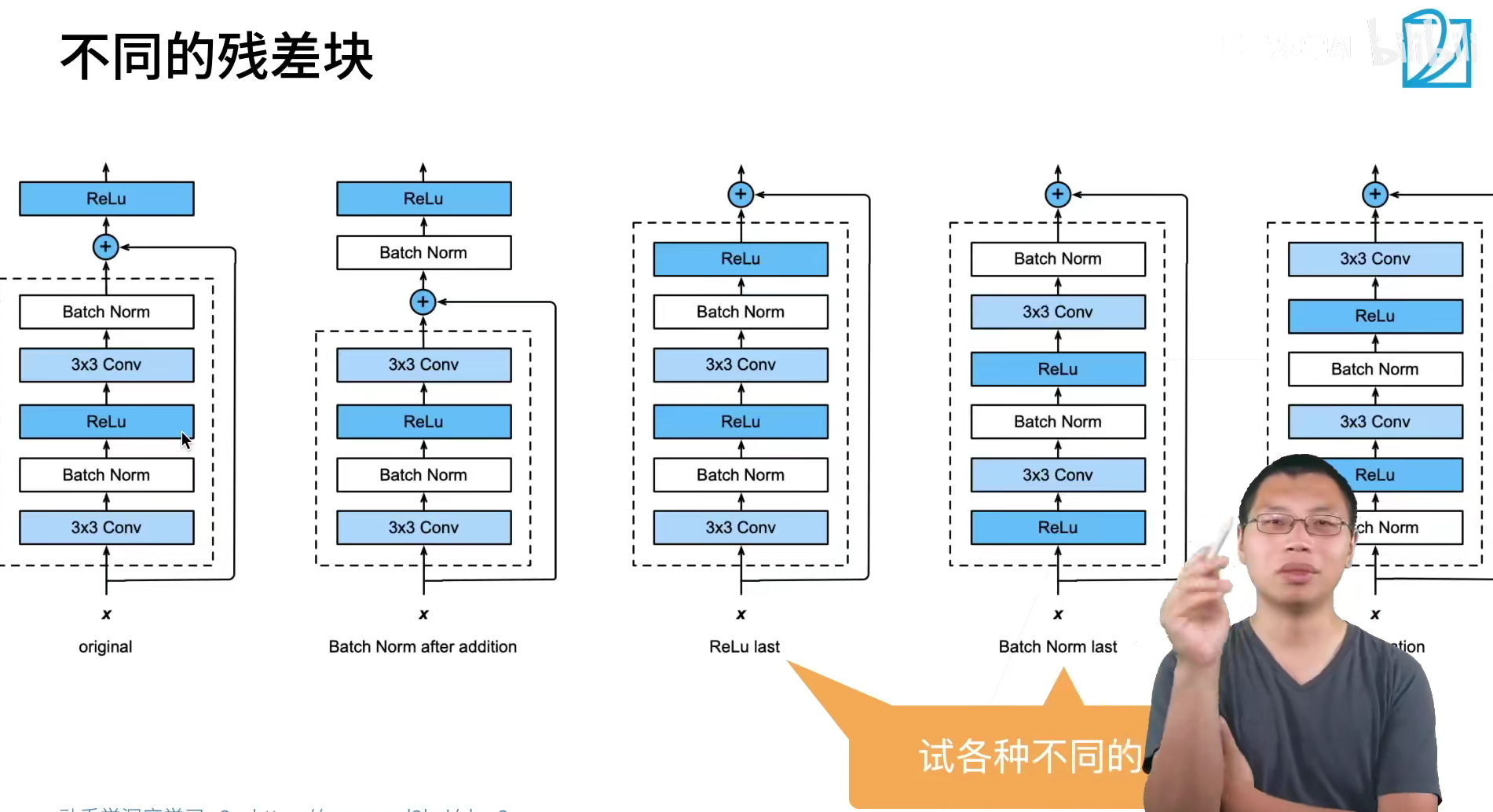
两种残差模块
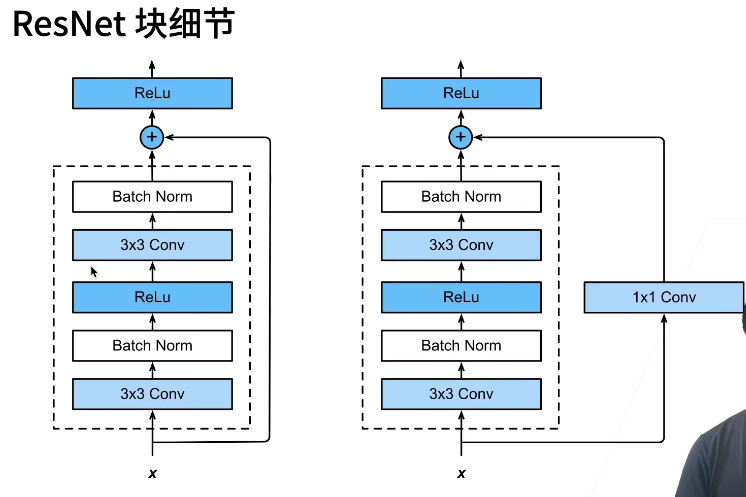
-
ResNet在一定程度上解决信息丢失、损耗,缓解梯度消失或者梯度爆炸,利于网络深度训练。直接将输入信息传到输出,保护信息的完整性,网络只需学习输入、输出的差别部分,简化学习目标和难度。
DenseNet
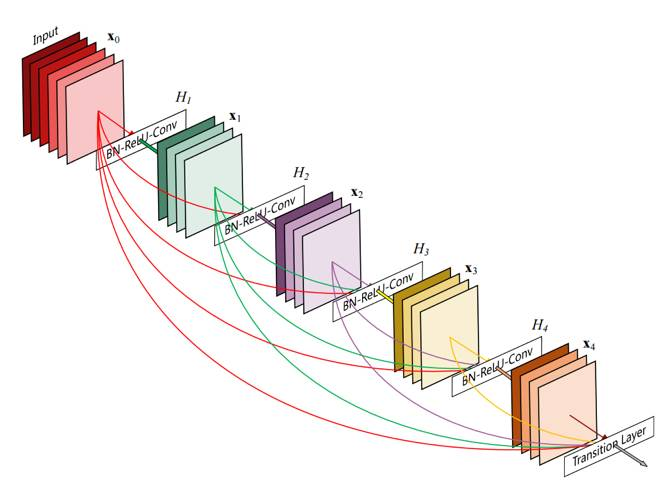
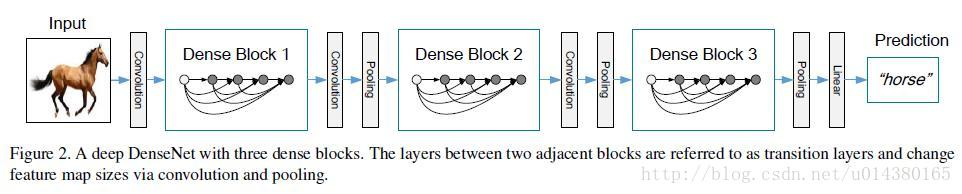
- 随着网络加深,输入信息和梯度信息在很多层之间传递导致愈加明显的梯度消失问题\({\to}\)保证网络层与层之间最大程度的信息传输的前提下,使每层的输入来自前面所有层的输出(共L(L+1)/2个连接),dense connection相当于每一层都直接连接input和loss,特征和梯度的传递更加有效,减轻vanishing-gradient,网络更容易训练。
- 网络更窄,参数更少,dense block中每个卷积层的输出feature map的数量都小于100,使得dense connection具备正则化效果,对于过拟合有一定程度的抑制
-

- DenseNet-BC:两个Dense Block中间有transition layer,用1*1的卷积核来降维,参数reduction(\({0<r<1}\)),将原输出缩小\(r\)倍传给下一个Dense Block;每个Dense Block中有子结构bottleneck layer,3*3卷积前面都包含了一个1*1的卷积操作,减少输入的feature map数量,既能降维减少计算量,又能融合各个通道的特征。
- dropout操作来随机减少分支,避免过拟合
MobileNet
网络小型化方面常用的手段:
- 卷积核分解,使用1×N和N×1的卷积核代替N×N的卷积核
- 使用bottleneck结构,以SqueezeNet为代表
- 以低精度浮点数保存,例如Deep Compression
- 冗余卷积核剪枝及哈弗曼编码
MobileNet进一步深入的研究了depthwise separable convolutions使用方法后设计出MobileNet,depthwiseseparable convolutions的本质是冗余信息更少的稀疏化表达。在此基础上给出了高效模型设计的两个选择:宽度因子(width multiplier)和分辨率因子(resolutionmultiplier)。通过权衡大小、延迟时间以及精度,来构建规模更小、速度更快的MobileNet。
-
轻量高效的网络架构\({\to}\)在很小精度损失情况下,参数量可减少8~9倍,运算量减小30倍,在自动驾驶汽车,机器人和无人机等对实时性、存储空间、能耗有严格要求的终端智能应用中发挥显著作用。
-
基本结构单元是深度级可分离卷积(depthwise separable convolution):
- 深度卷积(depthwise convolution)
- 逐点卷积(pointwise convolution)
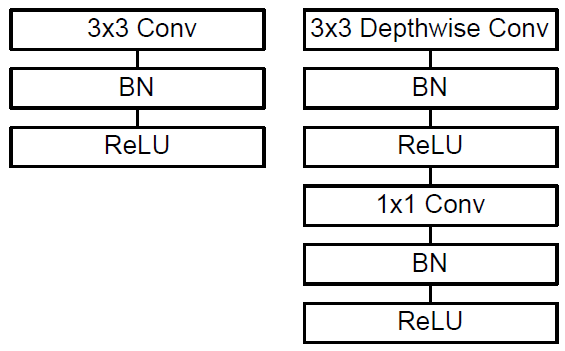
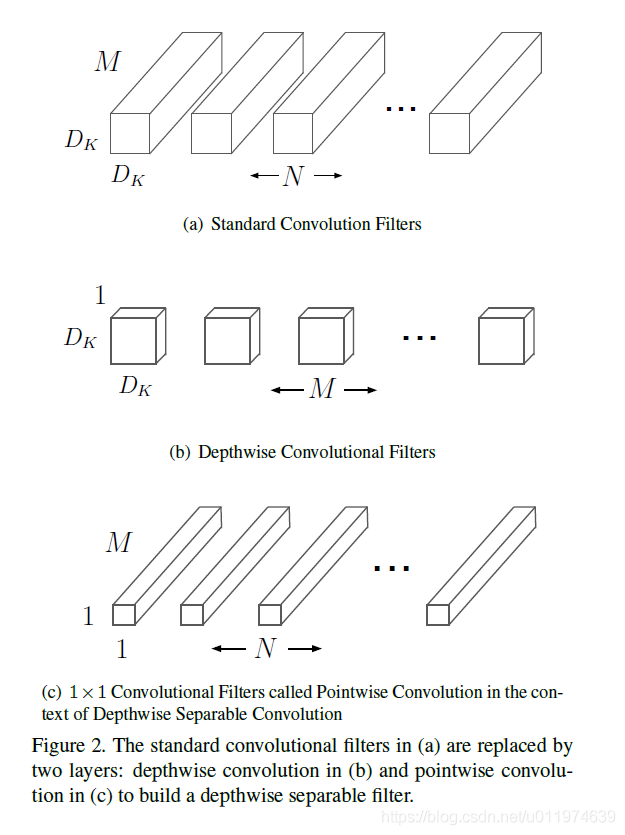
证:定量说明MobileNet参数数量降低


 浙公网安备 33010602011771号
浙公网安备 33010602011771号