基于遗传算法实现旅行商问题
问题提出
TSP(Travelling Salesman Problem)被称为巡回售货员问题,在物流中的描述是对应一个物流配送公司,欲将n个客户的订货沿最短路线全部送到而确定最短路线的问题,在数学上可以抽象描述为:在一个n个顶点构成的加权无向图中,寻找一个边的权值之和最小的哈密顿圈。TSP问题已被证明是近代组合优化领域中的一个典型NP难题,在运筹学、管理科学及工程实际中具有广泛的用途,也成为测试组合优化算法的标准问题。
问题分析
当城市数量很少时,可以通过基于表格的动态规划的方法求解TSP问题。然而,随着TSP的研究和利用的不断扩展,图的复杂程度不断加大,TSP问题的解空间随城市数量指数增大,无法为DP算法开辟足够的内存空间存储状态信息。一般TSP问题目前还没有稳定的多项式算法,对于规模较大的问题(如n>40)需要使用启发式方法求解。
常见的求解TSP的启发式算法包括模拟退火算法(Simulated Annealing)、遗传算法(Genetic Algorithm)、粒子群算法/鸟群觅食算法(Particle Swarm Optimization)、蚁群算法(ant colony optimization)、禁忌搜索算法(Tabu Search)和神经网络算法(Neural Network)等。本实验中采取遗传算法求解。
算法介绍
遗传算法(GeneticAlgorithm)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,通过模拟自然进化过程搜索最优解。遗传算法是从代表问题可能潜在的解集的一个种群开始的,初代种群产生之后,按照适者生存和优胜劣汰的原理,逐代演化产生出越来越好的近似解,每一代根据问题域中个体的适应度大小选择个体,并借助于自然遗传学的遗传算子进行组合交叉和变异,产生出代表新的解集的种群。这个过程将导致种群像自然进化一样的后生代种群比前代更加适应于环境,末代种群中的最优个体经过解码,可以作为问题近似最优解。
遗传算法核心有五大要素和三大算子,具体阐释如下。
五大要素
- 参数编码:问题建模,确定染色体长度与编码方式(二进制),形成解空间
- 初始种群:合理设置初始种群大小
- 适应度函数:确定进化规则与方向
- 遗传操作:设定逐代选优方式以及最大迭代次数等
- 控制参数:设置种群中等位基因交叉互换和基因突变的概率
三大算子
- 选择算子:在父代种群中选择进入下一代的个体。
- 交叉算子:对一组等位基因进行交叉互换,包括Partial-Mapped Crossover、Order Crossover、Position-based Crossover等交换方式,频率由交叉率决定。
- 变异算子:对个体的基因随机进行突变,频率由变异率决定。
算法描述
遗传算法的基本过程如下:
[初始化]:设置最大进化代数T、交叉概率、变异概率以及随机生成M个个体作为初始种群P
[个体评价]:计算种群P中各个个体的适应度
[选择运算]:将选择算子作用于群体。以个体适应度为基础,选择最优个体直接遗传到下一代或通过配对交叉产生新的个体再遗传到下一代
[交叉运算]:在交叉概率的控制下,对群体中的个体两两进行交叉
[变异运算]:在变异概率的控制下,对群体中的个体两两进行变异,即对某一个体的基因进行随机调整
[迭代]:经过选择、交叉、变异运算之后得到下一代群体P1。
[终止条件]:重复以上1-6,直到遗传代数为T,以进化过程中所得到的具有最大适应度个体作为最优解输出,终止计算。
结合TSP问题的遗传算法实现步骤
[step 1]:初始化阶段
初始化对象:种群规模、城市数量、运行代数、交叉概率、变异概率
初始化数据:读入数据源,将坐标转换为距离矩阵(标准化欧式距离)
初始化种群:随机生成n个路径序列,n表示种群规模。
-------------------------------------------------------------
[step 2]:计算种群适应度
计算每个哈密顿圈的边权之和的倒数。
-------------------------------------------------------------
[step 3]:交叉与变异
选择算子:赌轮选择策略挑选下一代个体。
交叉运算:第k个算子和k+1个算子有一定的概率交叉变换,k=0、2、4、...、2n
变异运算:每个算子有一定概率基因多次对换,概率取决于变异概率
计算新的种群适应度以及个体累积概率,并更新最优解。
新种群newGroup替代旧种群oldGroup中,进行下一轮迭代
-------------------------------------------------------------
[step 4]:结果输出
输出迭代过程中产生的最短路径长度、最短路径出现代数、以及最短路径
代码实现
以下对遗传算法求解TSP核心代码进行分块讲解。
初始化
定义个体类(Life)与遗传算法类(GA),并对GA类中最大进化代数、交叉和变异概率进行初始化设置。
class Life(object):
"""个体类"""
def __init__(self, aGene=None):
self.gene = aGene
self.score = -1
class GA(object):
"""遗传算法类"""
def __init__(self, aCrossRate, aMutationRage, aLifeCount, aGeneLenght, aMatchFun):
self.croessRate = aCrossRate # 交叉概率
self.mutationRate = aMutationRage # 突变概率
self.lifeCount = aLifeCount # 种群中个体数量
self.geneLenght = aGeneLenght # 基因长度
self.matchFun = aMatchFun # 适配函数
self.lives = [] # 种群
self.best = None # 保存这一代中最好的个体
self.generation = 1 # 第几代
self.crossCount = 0 # 交叉计数
self.mutationCount = 0 # 变异计数
self.bounds = 0.0 # 适配值之和
self.mean = 1.0 # 适配值平均值
self.initPopulation()
根据所设置的种群规模,对GA类中初始种群进行随机化构建。
def initPopulation(self):
"""初始化种群"""
self.lives = []
for i in range(self.lifeCount):
gene = [x for x in range(self.geneLenght)]
random.shuffle(gene) # 用来对一个元素序列进行重新随机排序
life = Life(gene)
self.lives.append(life)
在初始化GA类的基础上初始化TSP类,TSP类主要初始化城市坐标信息。
class TSP(object):
def __init__(self, aLifeCount=100,):
self.initCitys()
self.lifeCount = aLifeCount
self.ga = GA(aCrossRate=0.7,
aMutationRage=0.02,
aLifeCount=self.lifeCount,
aGeneLenght=len(self.citys),
aMatchFun=self.matchFun())
计算适应度
def judge(self):
# 评估每一个个体的适应度
self.bounds = 0.0
self.best = self.lives[0]
for life in self.lives:
life.score = self.matchFun(life)
self.bounds += life.score # 距离和倒数
if self.best.score < life.score:
self.best = life # 选出最佳适应度个体
self.mean = self.bounds / self.lifeCount # 计算平均个体适应度
def matchFun(self):
# 倒数
return lambda life: 1.0 / self.distance(life.gene)
def distance(self, order):
# 计算一个个体编码代表的哈密顿圈路径和
distance = 0.0
for i in range(-1, len(self.citys) - 1):
index1, index2 = order[i], order[i + 1]
city1, city2 = self.citys[index1], self.citys[index2]
distance += math.sqrt((city1[0] - city2[0]) ** 2 + (city1[1] - city2[1]) ** 2)
return distance
产生子代个体
轮盘赌选择子代个体,按照设定的概率交叉突变后形成新种群
def newChild(self):
# 产生子代个体
parent1 = self.getOne() # 用适应度作为概率,轮盘赌选择
rate = random.random()
# 按概率交叉
if rate < self.croessRate: # 概率执行交叉互换
# 交叉
parent2 = self.getOne()
gene = self.cross(parent1, parent2)
else:
gene = parent1.gene # 返回根据适应度轮盘赌选择出来的个体
# 按概率突变
rate = random.random()
if rate < self.mutationRate:
gene = self.mutation(Life(gene))
return L
def getOne(self):
# 轮盘赌选择子代个体
r = random.uniform(0, self.bounds) # 均匀分布中随机采样
for life in self.lives:
r -= life.score
if r <= 0:
return life
raise Exception("选择错误", self.bounds)
def cross(self, parent1, parent2, T=120, crossmode=2):
# 交叉
n = 0
while 1:
newGene = []
if crossmode == 1:
index = random.randint(0, self.geneLenght - 1)
crossGene = parent2.gene[index:]
for i in parent1.gene[:index]:
while i in crossGene:
i = parent1.gene[index:][crossGene.index(i)]
newGene.append(i)
newGene.extend(crossGene)
if crossmode == 2:
index1 = random.randint(0, self.geneLenght - 1) # 用于生成一个指定范围内的整数
index2 = random.randint(index1, self.geneLenght - 1)
tempGene = parent2.gene[index1:index2] # 取p2交叉部分的基因片段
# 新基因片段 = [p1原基因左片段 p2交叉部分 p1原基因右片段]
p1len = 0
for g in parent1.gene:
if p1len == index1:
newGene.extend(tempGene) # p2交叉部分的基因片段直接成为新基因片段
p1len += 1
if g not in tempGene:
newGene.append(g)
p1len += 1
# 直到选出比p1和p2适应度都高的新基因
if (self.matchFun(Life(newGene)) > max(self.matchFun(parent1), self.matchFun(parent2))):
self.crossCount += 1
return newGene
if (n > T):
self.crossCount += 1
return newGene
n += 1
def mutation(self, egg, mutationmoce=2):
# 突变
newGene = egg.gene[:] # 产生一个新的基因序列,以免变异的时候影响父种群
if mutationmoce == 1: # 均匀变异
for i in range(len(newGene)):
if np.random.uniform() < self.mutationRate:
j = random.randint(0, self.geneLenght - 1)
newGene[i], newGene[j] = newGene[j], newGene[i]
if mutationmoce == 2: # 二元变异
index1 = random.randint(0, self.geneLenght - 1)
index2 = random.randint(0, self.geneLenght - 1)
newGene[index1], newGene[index2] = newGene[index2], newGene[index1] # 随机交换两个染色体
if self.matchFun(Life(newGene)) > self.matchFun(egg):
self.mutationCount += 1
return newGene
else:
rate = random.random()
if rate < math.exp(-10 / math.sqrt(self.generation)):
self.mutationCount += 1
return newGene
return egg.gene
迭代更新种群
迭代更新种群,精英操作不断选出最优秀的个体加入下轮迭代,保证子代不比亲代差,若干次迭代后即可使得种群中个体的适应度保持稳定。
def next(self):
# 评估当前一代每一个个体的适应度
self.judge()
# 产生下一代
newLives = []
newLives.append(self.best) # 把适应度最好的个体加入下一代
while len(newLives) < self.lifeCount:
newLives.append(self.newChild())
self.lives = newLives
self.generation += 1
结果呈现
交叉互换:5513次
基因突变:43次
迭代次数:80次(解释见8.1)
最短距离:154.639643
途径顺序:济南->合肥->南京->上海->杭州->台北->福州->南昌->武汉->长沙->广州->香港->澳门->海口->南宁->贵阳->重庆->成都->昆明->拉萨->乌鲁木齐->西宁->兰州->银川->西安->郑州->太原->呼和浩特->石家庄->北京->天津->哈尔滨->长春->沈阳->济南
备注:回路起点不唯一,回路中任一城市节点均可成为起点。
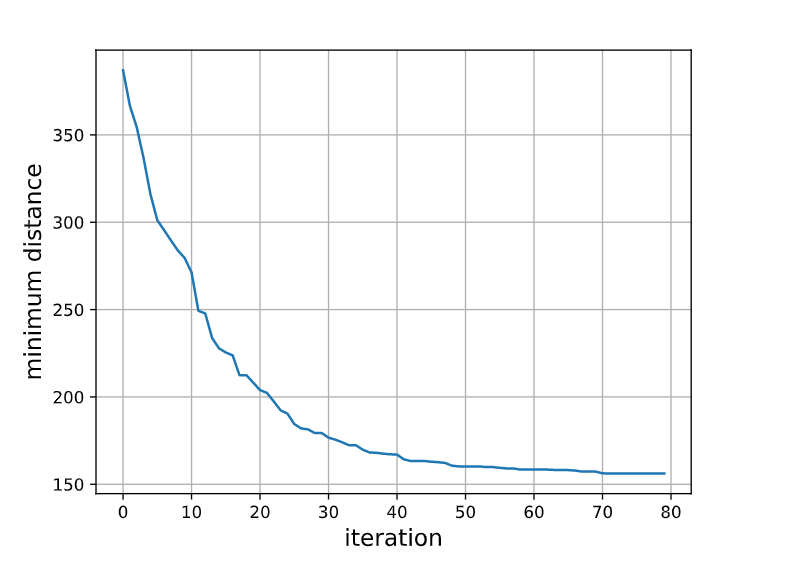
最短距离随迭代次数的变化趋势如下图所示。由图象可以看出随着迭代次数的增加,哈密顿圈的路径和不断递减而且减速逐渐放缓最终趋向收敛。
全国34个城市途径顺序可视化如下动图所示:
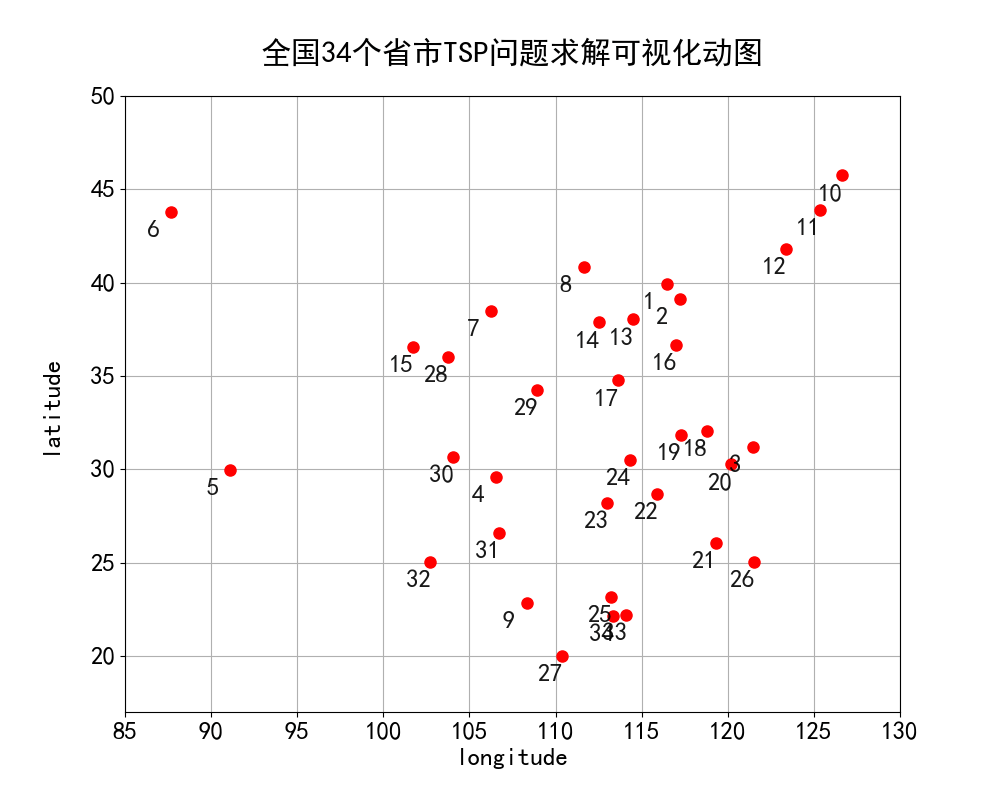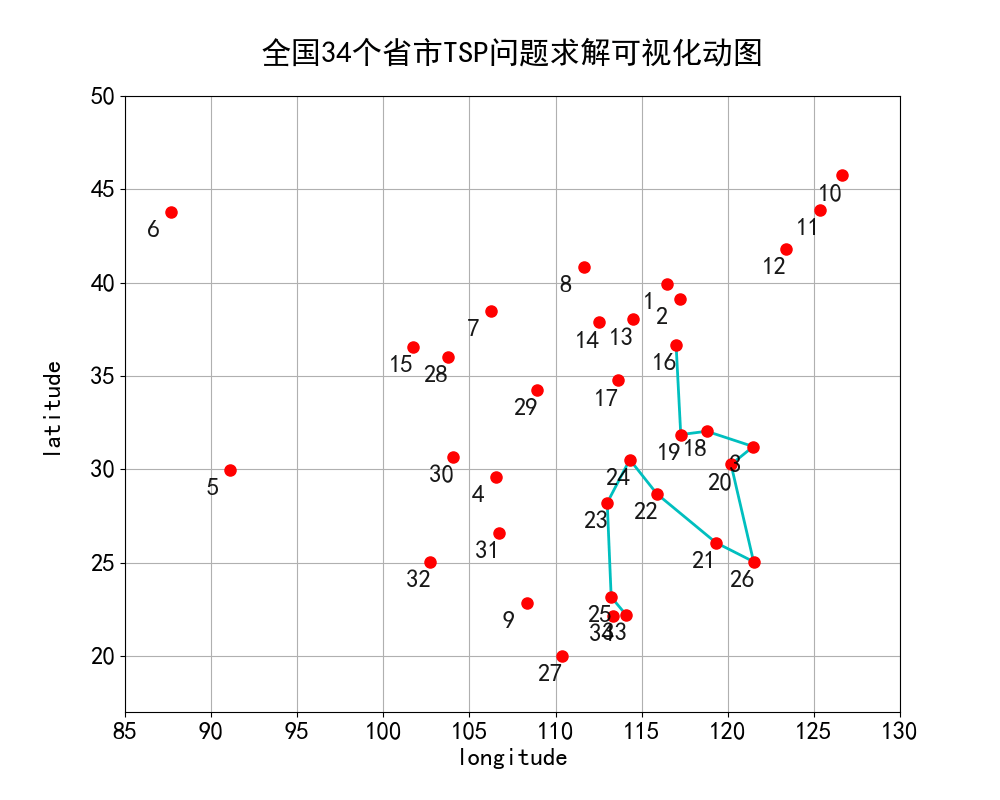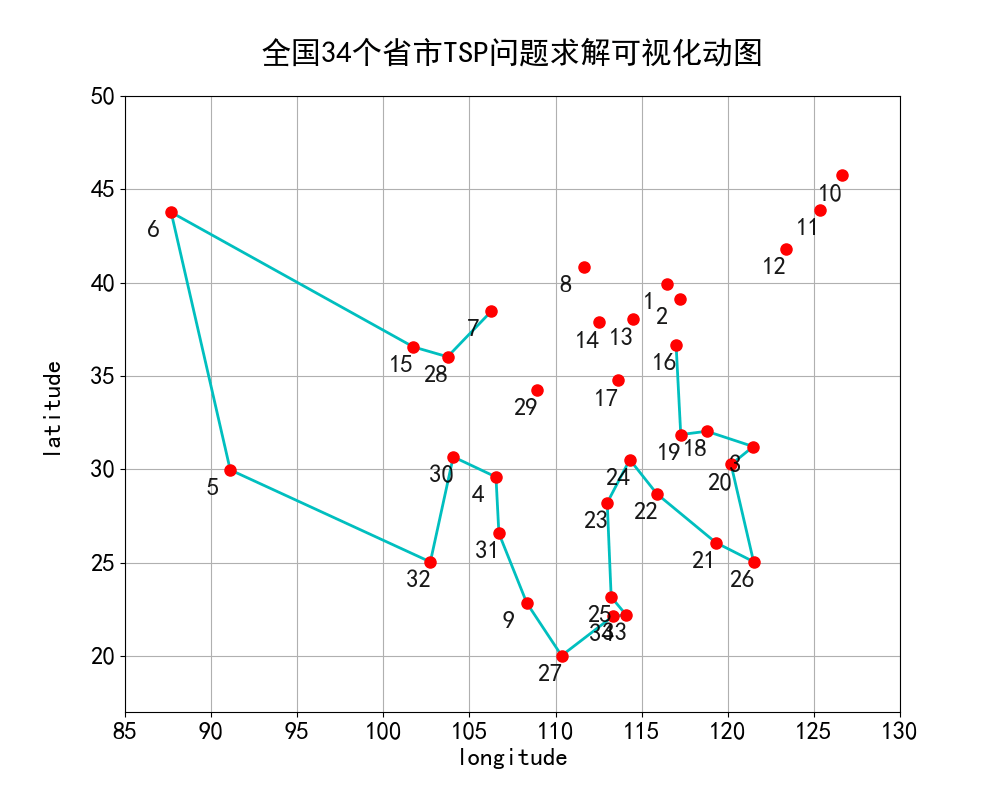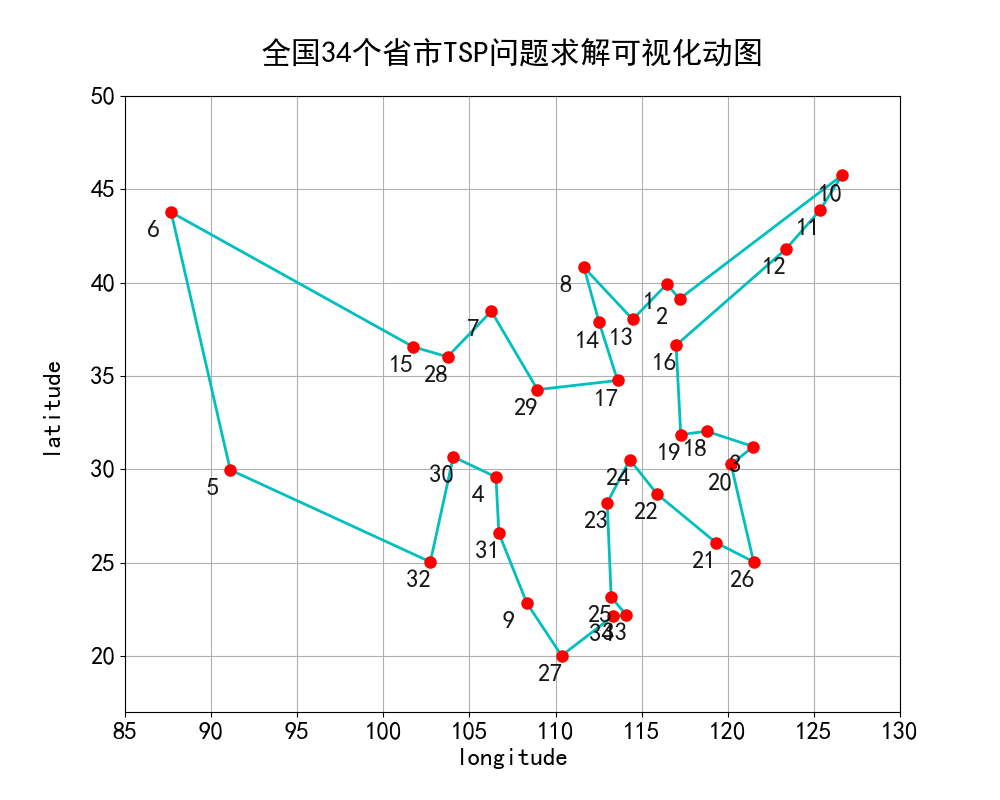
备注:由于绘图空间有限,故使用数字代替地名呈现在地图上
灵敏度分析
迭代次数的影响
迭代次数过少,寻找到的最短距离尚未收敛可能无法达到最优;迭代次数超过一定范围,算法已经寻找到最优解完成收敛,达到饱和。
本实验中改善了传统的遗传操作的方式,设置阈值T=120,对于遗传(或变异)操作当且仅当出现适应度更好的个体才停止,否则重复操作T次才结束。这样可以大概率保证子代的适应度优于亲代。在此遗传操作条件下通过调试得出合适的迭代次数范围在100代左右。
种群数量的影响
保持变异概率和交叉概率一定,分别设置种群数量为50,100,200,所觅路径距离随迭代次数的收敛曲线如下左图所示;保持变异概率和交叉概率一定,在每个种群数量下运行程序10次,每次运行迭代100代,绘制最短距离分布箱线图如下右图所示:
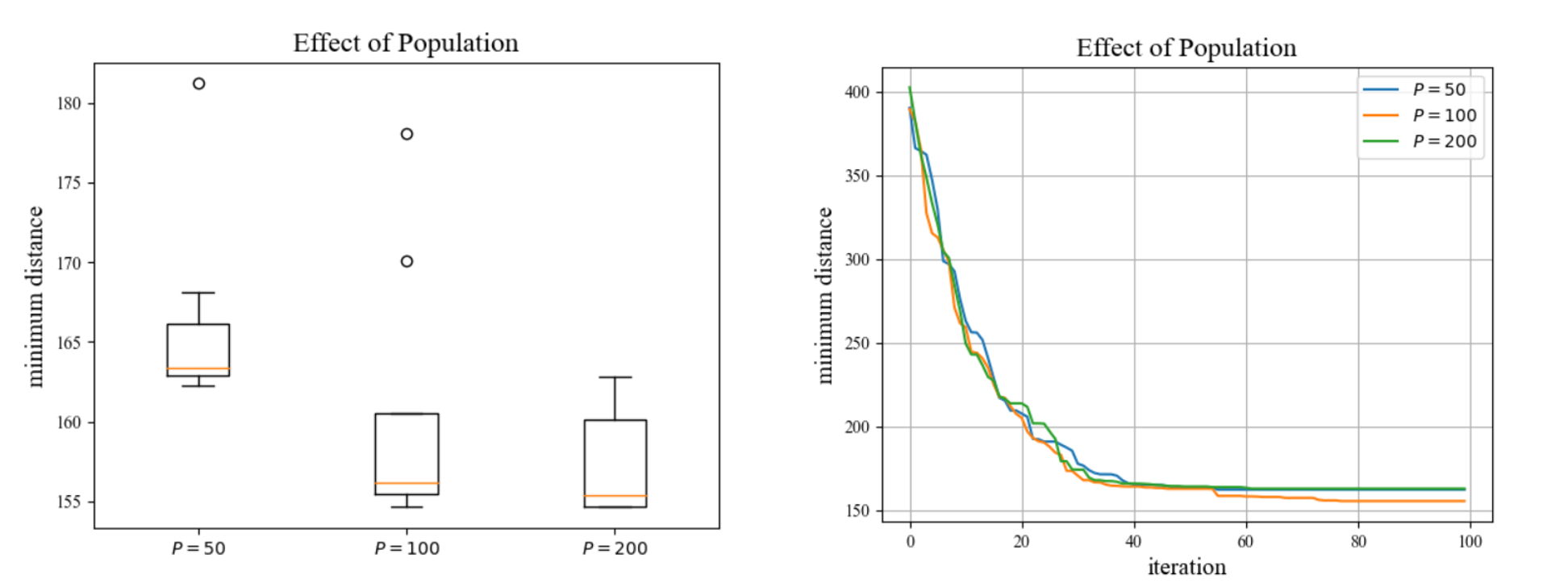
由图可知,在一定范围内,较小的群体规模可能会因为近亲交配产生病态基因,使得种群进化不能达到理想的效果;而较大的群体规模会使得稳定性略微下降,且对结果的提升效果并不显著。因此,实验得出合适的种群数量应设置在100左右。
变异概率的影响
保持种群数量和交叉概率一定,分别设置变异概率为0.02, 0.05, 0.1,所觅路径距离随迭代次数的收敛曲线如下左图所示;保持种群数量和交叉概率一定,在每个变异概率下运行程序10次,每次运行迭代100代,绘制最短距离分布箱线图如下右图所示:
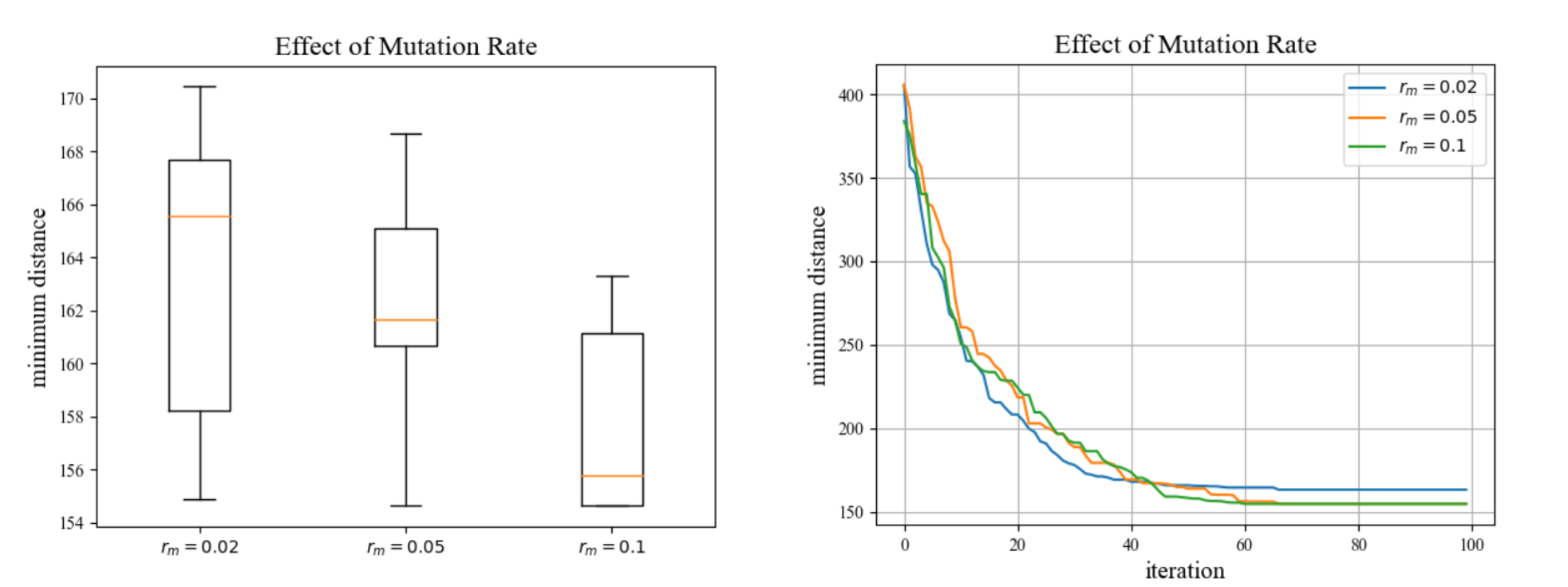
由图可知,在一定范围内,变异概率偏小时,种群的多样性下降太快,容易导致收敛不稳定,导致平均最短距离偏大,效果更不理想。因此,在有限次代码执行次数条件下,略微增大变异概率,有助于增大种群多样性,提高寻找到最优路线的可能性。
交叉概率的影响
保持种群数量和变异概率一定,分别设置交叉概率为0.6, 0.7, 0.8,所觅路径距离随迭代次数的收敛曲线如下左图所示;保持种群数量和变异概率一定,在每个交叉概率下运行程序10次,每次运行迭代100代,绘制最短距离分布箱线图如下右图所示:
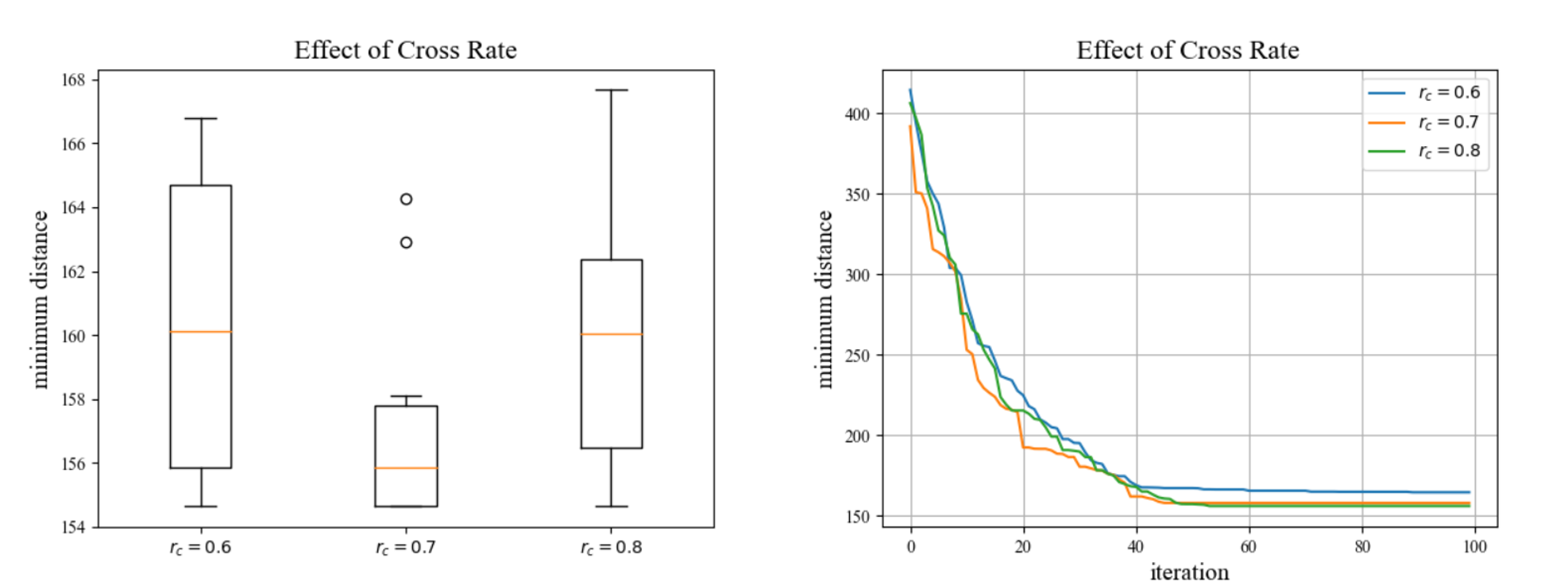
由图可知,在一定范围内,交叉概率偏小,种群不能有效更新,导致收敛结果不具说服性;交叉概率太大,容易破坏已有的最适应解,随机性增大,容易错失最优个体。实验得出选择交叉概率在0.7左右对找到最优路径最有利。
交叉方式的影响
保证控制概率参数一定,分别设置交叉方式为单点交叉和两点交叉进行实验,比较迭代曲线,结果如下所示:
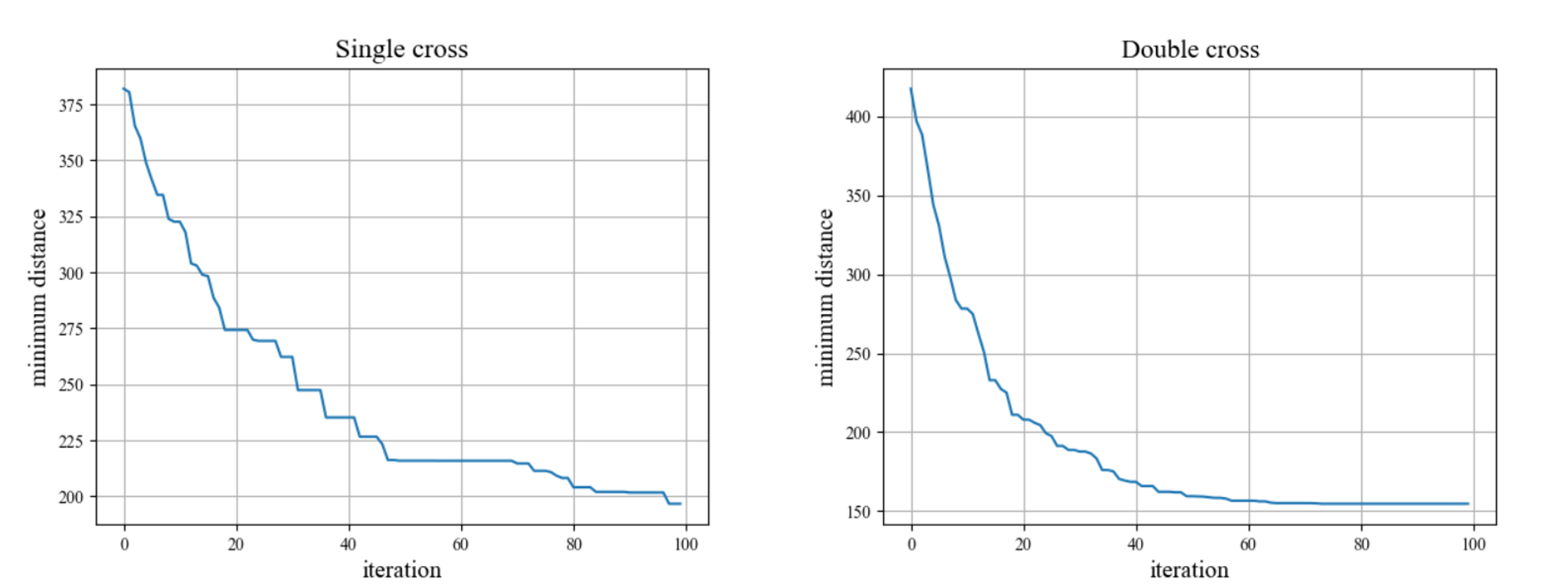
由图可明显发现,两点交叉在未找到最优解前比单点交叉提供了更多的子代基因多样性,在相同的100代迭代次数下,使用单点交叉曲线并没有完全收敛,找到的当前最优距离和为197左右;而使用两点交叉曲线在70代左右已经收敛且达到最优值154.639643。可以得出,使用相比单点交叉使用多点交叉有助于所需要的减少迭代次数,更有助于在巨大的解空间中更有效地寻求更优解。
变异方式的影响
保证控制概率参数一定,分别设置变异方式为二元变异和均匀变异进行实验,比较迭代曲线,结果如下所示:
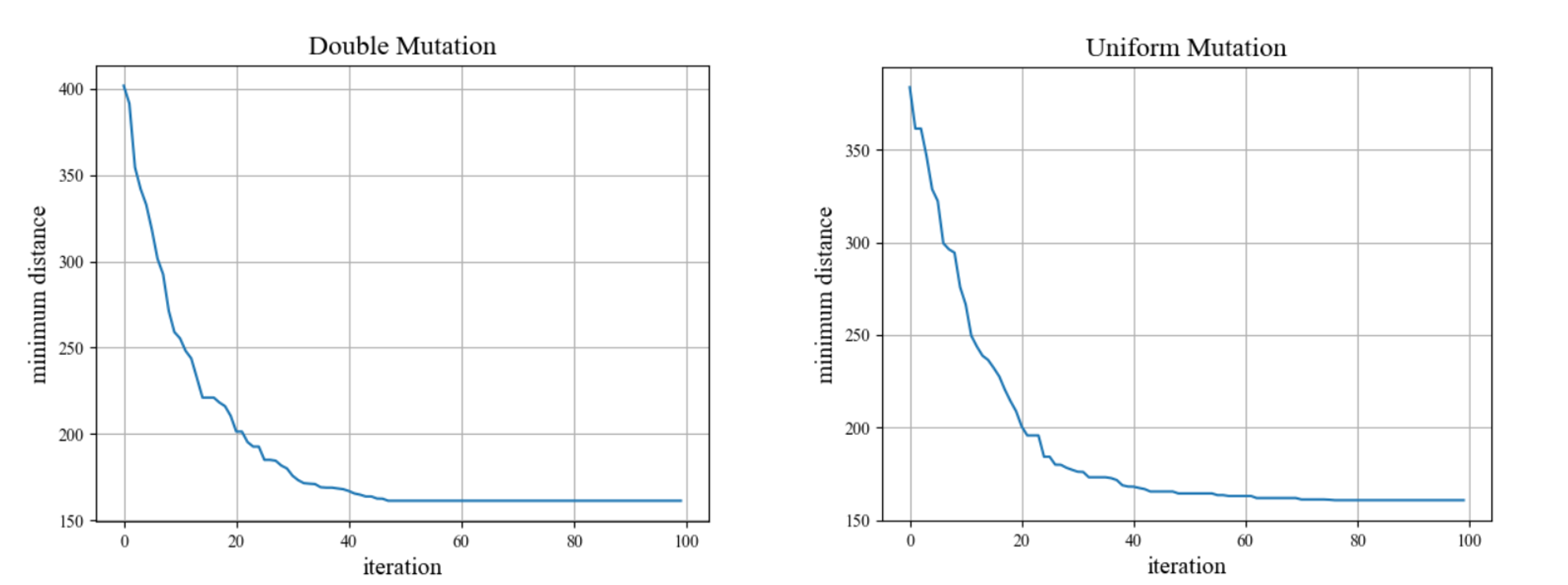
对比发现两种变异方式对结果的影响并不显著,由于设置的变异概率较小,在保证交叉概率0.7不变的条件下,子代种群的更新主要依靠交叉,在曲线接近收敛时由变异产生的变化有限,因此可以认为两种变异方式对寻找最优路径的影响相近。
评价扩展
优点
- 贯彻面向对象的编程思想,算法的核心代码以及可视化代码通过类封装并形成一个完整模块,使得代码可读性强,也便于调试与维护。
- 通过动图呈现TSP问题求解结果,直观可感;灵敏度分析采用曲线图和箱线图呈现,真实可信。
扩展
本文主要借助启发式算法中的一种——遗传算法求解TSP问题。事实上,各种智能算法(如3中介绍)及其改进算法都可以运用在NP问题的启发式求解中,以下几种常用智能算法的可执行代码详见:https://github.com/zhoubohan0/TSP/tree/master (Github)/https://gitee.com/zhou-bohan/tsp (Gitee)
- 模拟退火算法(Simulated Annealing)算法
- 遗传算法(Genetic Algorithm)
- 粒子群算法/鸟群觅食算法(Particle Swarm Optimization)
- 蚁群算法(ant colony optimization)
- 禁忌搜索(Tabu Search)算法
总结
本文通过手动实现遗传算法,加深了对启发式算法以及NP问题的认识,并将结果进行可视化呈现,还进一步进行灵敏度分析探究种群数量、交叉概率、变异概率等参数的改变对结果的影响。此外,还可以使用传统动态规划方法解决小规模TSP问题以及使用模拟退火算法、粒子群算法、蚁群算法和禁忌搜索探索大规模TSP问题的最优解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号