
数据采集第三次作业
作业①
-
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后3位)
-
输出信息:
-
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件夹中,并给出截图。
解题步骤
单线程
- STEP1 发出请求(通用模板)
def getHTML(url):
try:
header = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
resp = requests.get(url, headers=header)
resp.raise_for_status() # 200
resp.encoding = resp.apparent_encoding
return resp.text
except Exception as err:
print(err)
- STEP2 因要更换页面,所以要获取不同页面的url,将其存入列表,用于爬取
def getURLs(html):
Html =BeautifulSoup(html,'lxml')
html_urls = Html.select('li > a')
url_list = []
for url in html_urls:
url = url['href']
url_list.append(url)
#print(url_list)
return url_list
- STEP3 利用正则爬取并下载图片
def getImages(url_list):
Image_all = 1
for urls in url_list:
req = getHTML(urls)
req = req.replace("\n","")
imagelist = re.findall(r'<img.*?src="(.*?)"', req, re.S | re.M)
while "" in imagelist:
imagelist.remove("")
for img_url in imagelist:
#print(img_url)
if (img_url[0] == 'h'):
#print(img_url[0])
if (Image_all <= 129):
print("第"+str(Image_all)+"张爬取成功")
file = "D:/wea_img/" + "第"+ str(Image_all) + "张" + ".jpg"
urllib.request.urlretrieve(img_url, filename=file)
Image_all += 1
else:
break
else:
continue
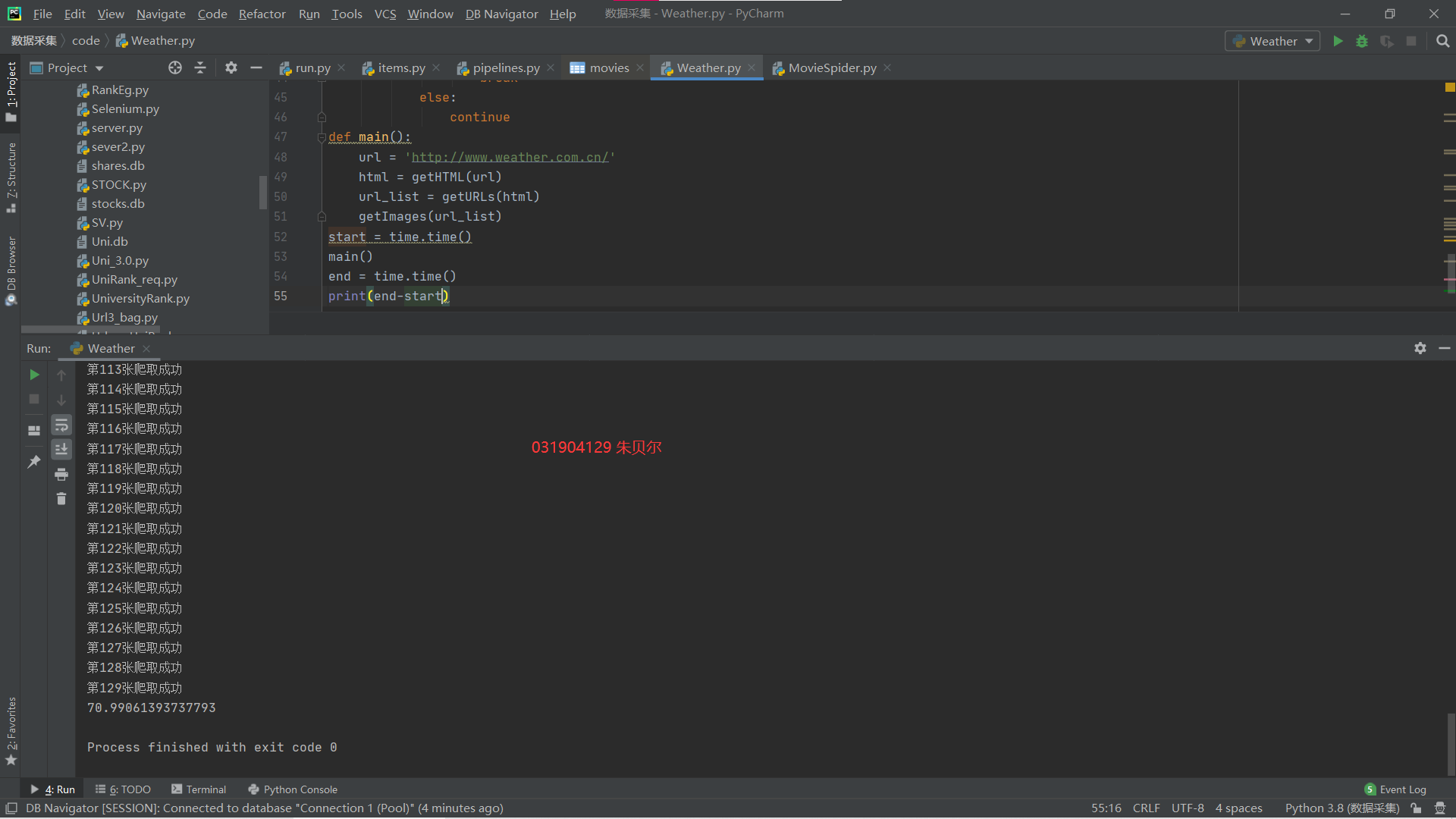
STEP4 加一个时间函数计算时间,和接下来的多线程进行比较
start = time.time()
main()
end = time.time()
print(end-start)
运行结果
多线程
引入threading
print("第"+str(Image_all)+"张爬取成功")
file = "D:/weath/" + "第"+ str(Image_all) + "张" + ".jpg"
urllib.request.urlretrieve(img_url, filename=file)
r = threading.Thread(target=download, args=(img_url, file))
r.setDaemon(False)
r.start()
Image_all += 1
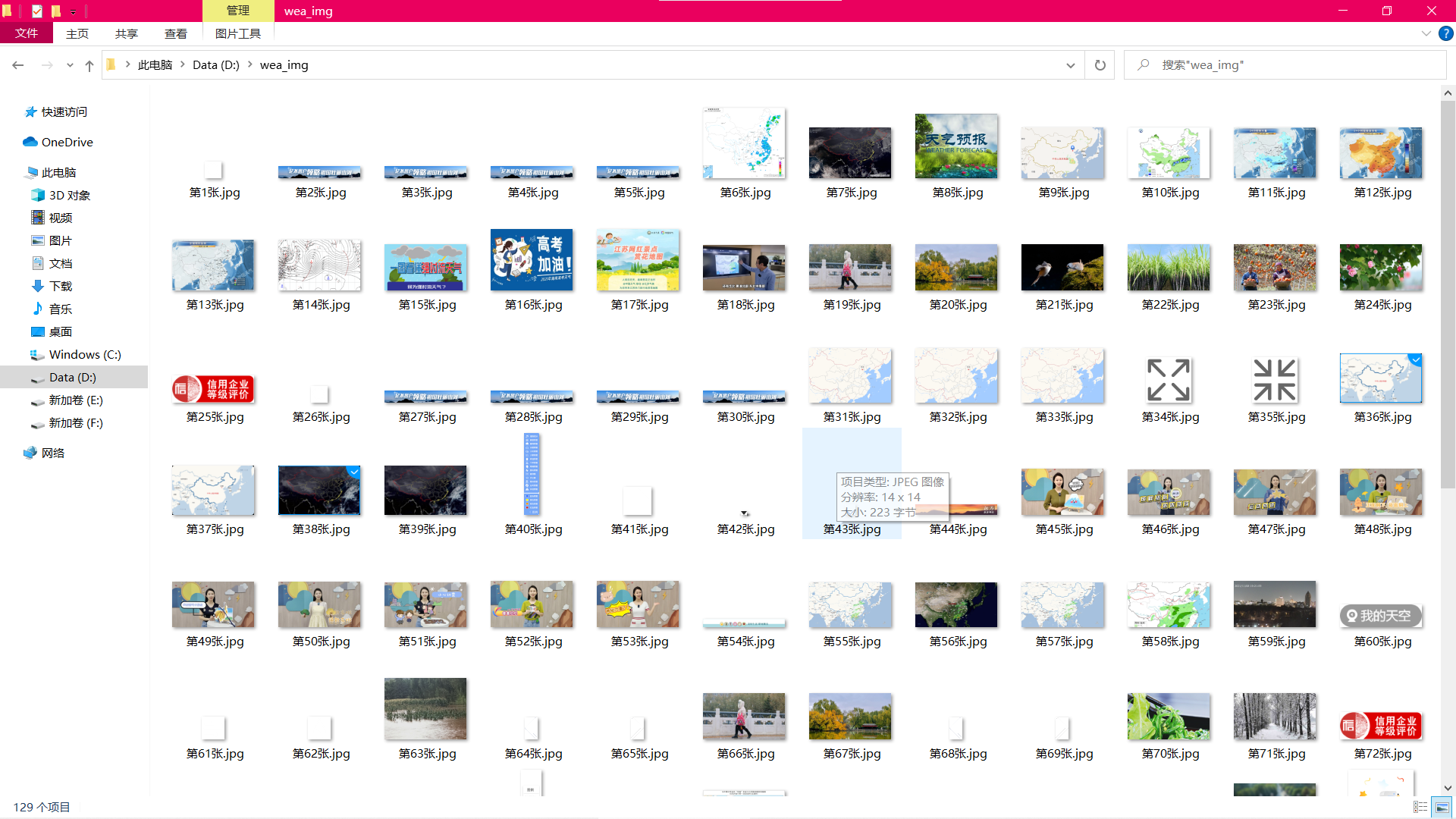
结果截图:

下载于文件夹图片截图:
代码地址:https://gitee.com/zhubeier/zhebeier/blob/master/第三次大作业/第一题多线程
- 实验心得
1.将单线程和多线程进行对比,发现多线程下载图片明显快于单线程。
2.更换页面让我更熟悉了找不具有规律的url的方法
作业二
要求:使用scrapy框架复现作业①。
输出信息:
同作业①
解题步骤
STEP1 创建好scrapy爬虫后,编写items文件
import scrapy
class WeatherItem(scrapy.Item):
urls_list = scrapy.Field()
STEP2 修改setting文件中参数
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
ITEM_PIPELINES = {
'weather.pipelines.WeatherPipeline': 300,
}
STEP3
编写爬虫文件spider parse模块,爬取页面
def parse(self, response):
try:
links = response.xpath('//a//@href').extract()
yield scrapy.Request(self.start_urls, callback=self.parse_for_page)
for link in links:
if link != 'javascript:void(0)':# 去除这样的链接
yield scrapy.Request(link,callback=self.parse_for_page)
except Exception as err:
print(err)
STEP4 编写pipeline文件,用于存储下载爬取的文件
num = 1
class WeatherPipeline:
def process_item(self, item, spider):
global num
if not os.path.exists('./images_scrapy/'):
os.mkdir('./images_from_scrapy/')
for url in item["urls_list"]:
if num <= 129:
print(url)
image_name = './images_scrapy/'+'第'+str(num)+'张图片.jpg'
print("成功使用scrapy下载第" + str(num) + "张图片")
urllib.request.urlretrieve(url,image_name)
num += 1
STEP5 编写一个run.py文件用于启动爬虫
from scrapy import cmdline
cmdline.execute("scrapy crawl Weather -s LOG_ENABLED=False".split())
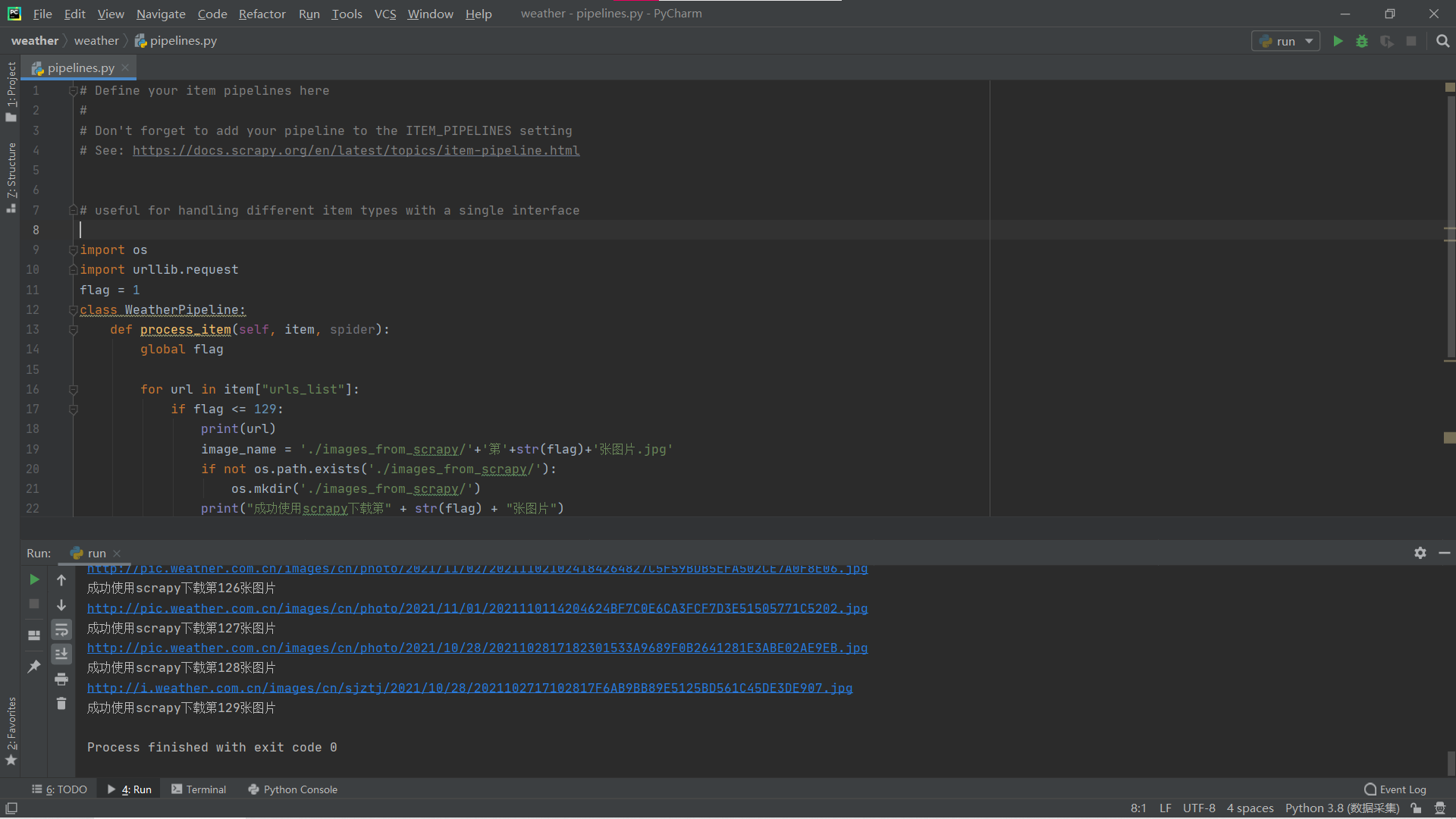
- 运行结果:

- 实验心得
熟悉了编写scrapy基本步骤,即items->settings->爬虫文件->pipeline文件
熟悉处理掉一些特殊的url链接
代码地址:https://gitee.com/zhubeier/zhebeier/blob/master/第三次大作业/第二题
作业三
要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在
imgs路径下。
候选网站: https://movie.douban.com/top250
输出信息:
| 序号 | 电影名称 | 导演 | 演员 | 简介 | 电影评分 | 电影封面 |
|---|---|---|---|---|---|---|
| 1 | 肖申克的救赎 | 弗兰克·德拉邦特 | 蒂姆·罗宾斯 | 希望让人自由 | 9.7 | ./imgs/xsk.jpg |
| 2.... | ||||||
| 解题步骤: | ||||||
| STEP1 编写items文件,共计六个属性 |
class MovieItem(scrapy.Item):
name = scrapy.Field() # 电影名
director = scrapy.Field() # 导演
actor = scrapy.Field() # 主演
statement = scrapy.Field() # 简介
rank = scrapy.Field() # 评分
image_urls = scrapy.Field() # 封面
STEP2 修改settings文件,同作业二
STEP3 编写爬虫文件,利用xpath提取所需信息
item["director"] = directors # 导演
item["actor"] = actors # 演员
item["statement"] = response.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[2]/span/text()').extract()
item["rank"] = response.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()').extract()
item["image_urls"] = response.xpath('//*[@id="content"]/div/d
STEP4 编写PipeLines文件,将爬取下来的数据存入数据库
def openDB(self):
self.con = sqlite3.connect("M.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("create table movies(rank varchar(10),name varchar(10),director varchar(10),actor varchar(10),state varchar(20),score varchar(10),surface varchar(50))")
except:
self.cursor.execute("delete from movies")
def closeDB(self):
self.con.commit()
self.con.close()
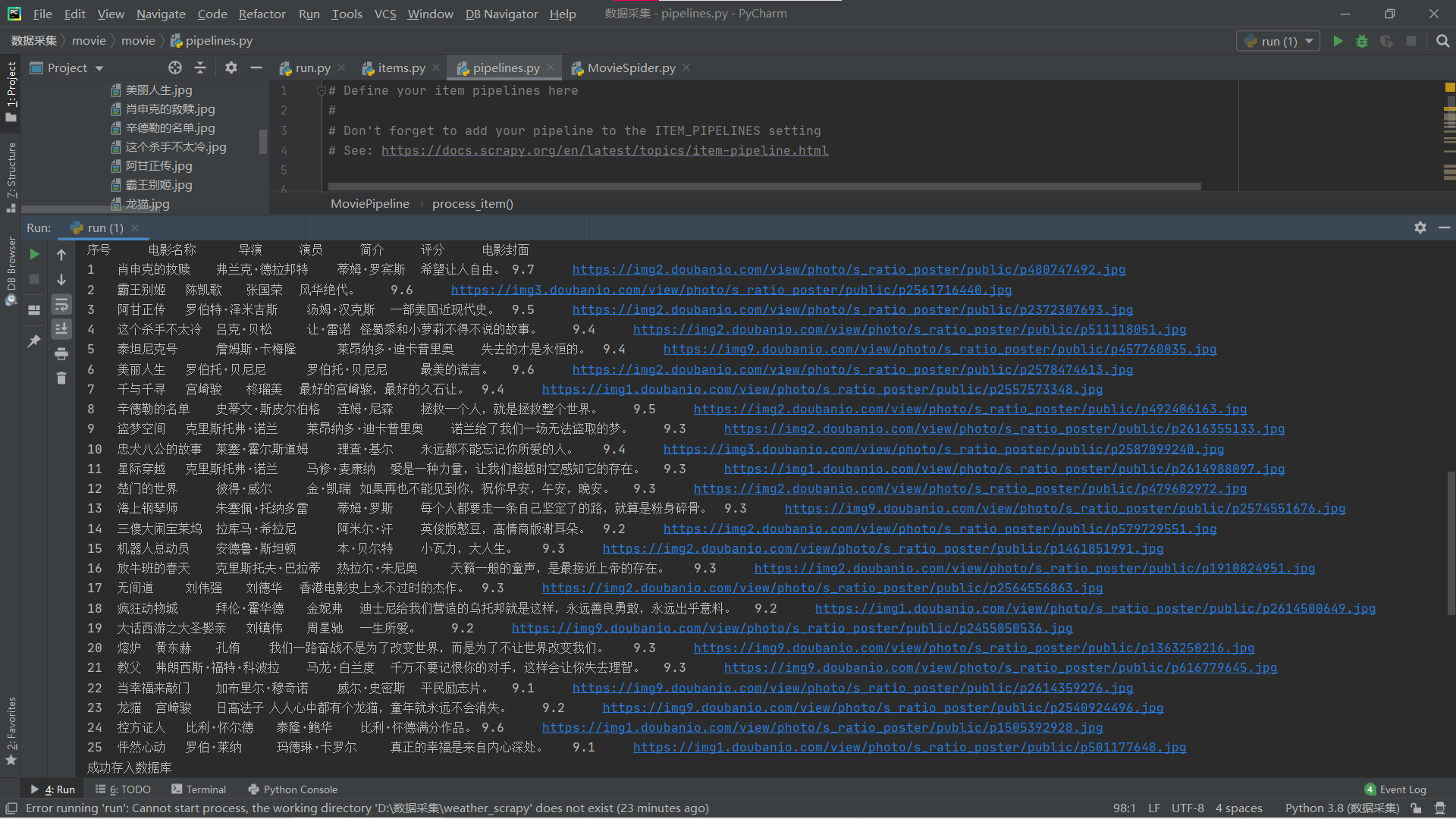
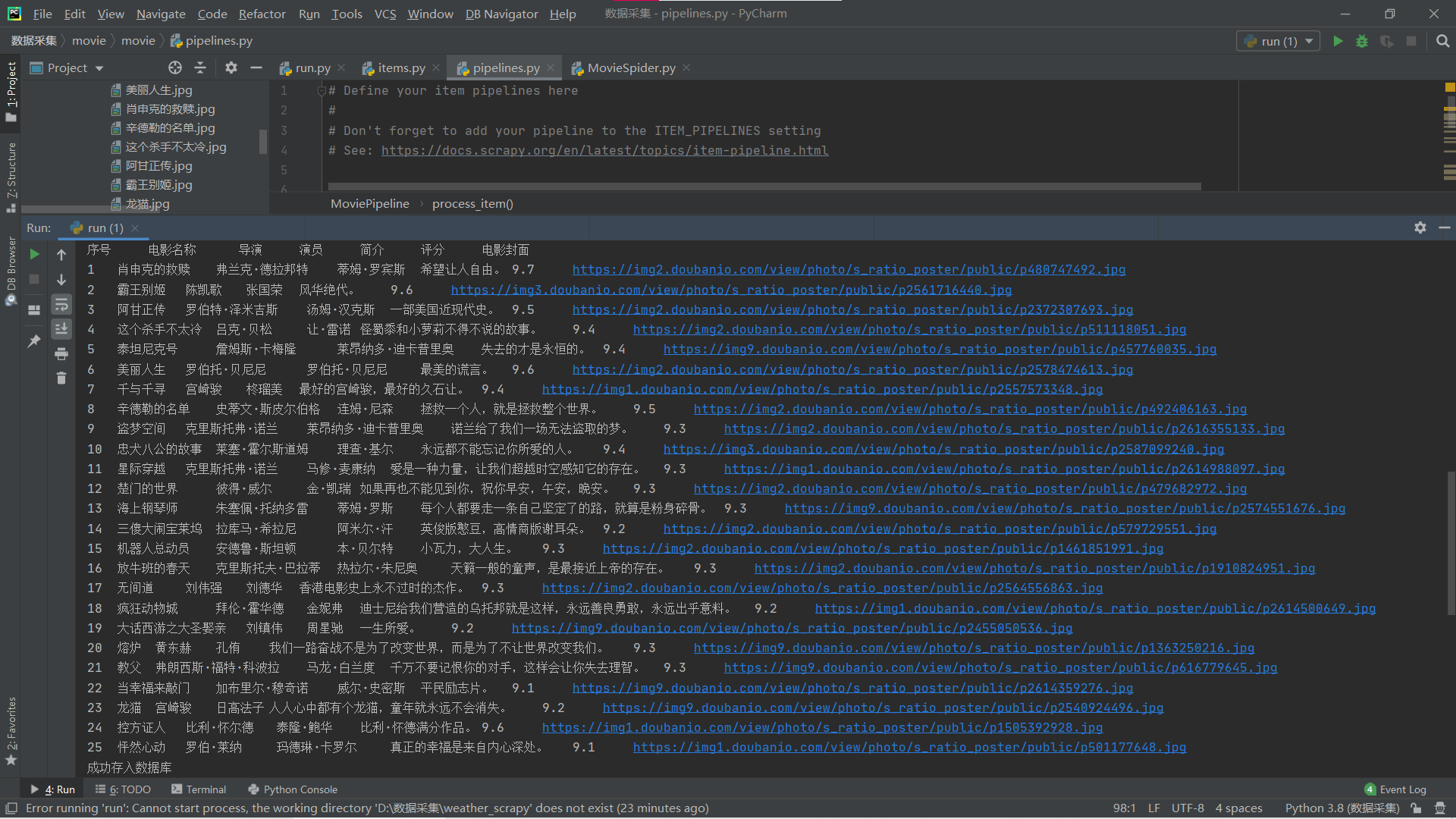
运行结果:
终端:
数据库:
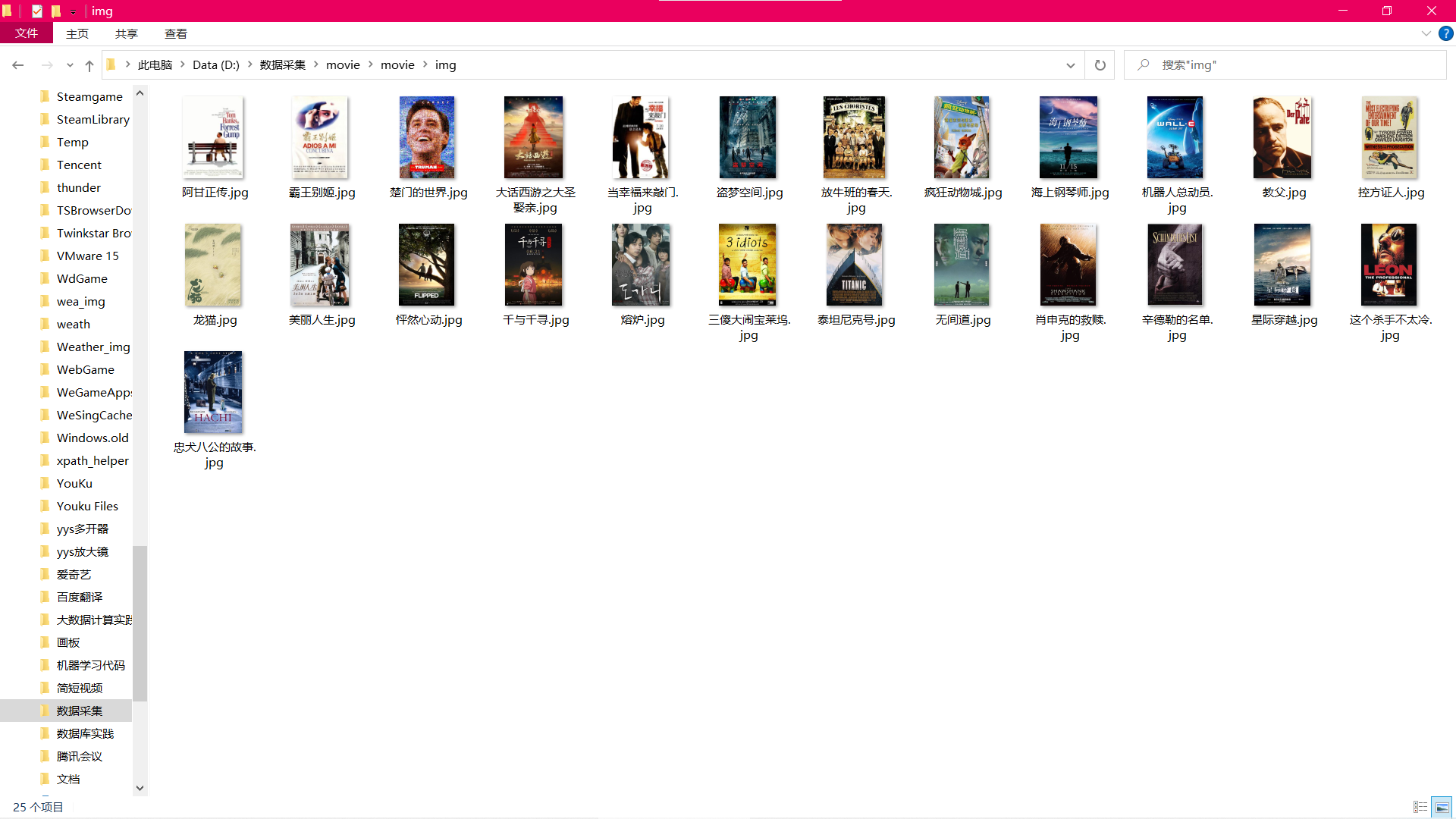
封面文件下载查看:
- 作业心得
更加熟悉了xpath提取信息以及感受到了scrapy的方便性
代码地址:https://gitee.com/zhubeier/zhebeier/blob/master/第三次大作业/第三题
