
Scala学习总结(三)
Scala学习总结
六、集合
1. Scala集合的特点
Java集合:
- 三大类型:列表 List 、集合 Set 、映射 Map ,有多种不同实现。
Scala集合:
- 三大类型:序列 Seq ,集合 Set ,映射 Map ,所有集合都扩展自 Iterable 。
- 对于几乎所有集合类,都同时提供可变和不可变版本。
- 不可变集合: scala.collection.immutable
- 可变集合: scala.collection.mutable
- 两个包中可能有同名的类型,需要注意区分是用的可变还是不可变版本,避免冲突和混淆。
- 对于不可变集合,指该集合长度数量不可修改,每次修改(比如增删元素)都会返回一个新的对象,而不会修改源对象。
- 可变集合可以对源对象任意修改,一般也提供不可变集合相同的返回新对象的方法,但也可以用其他方法修改源对象。
建议:操作集合时,不可变用操作符,可变用方法。操作符也不一定就会返回新对象,但大多是这样的,还是要具体看。
1.1. 不可变集合关系一览
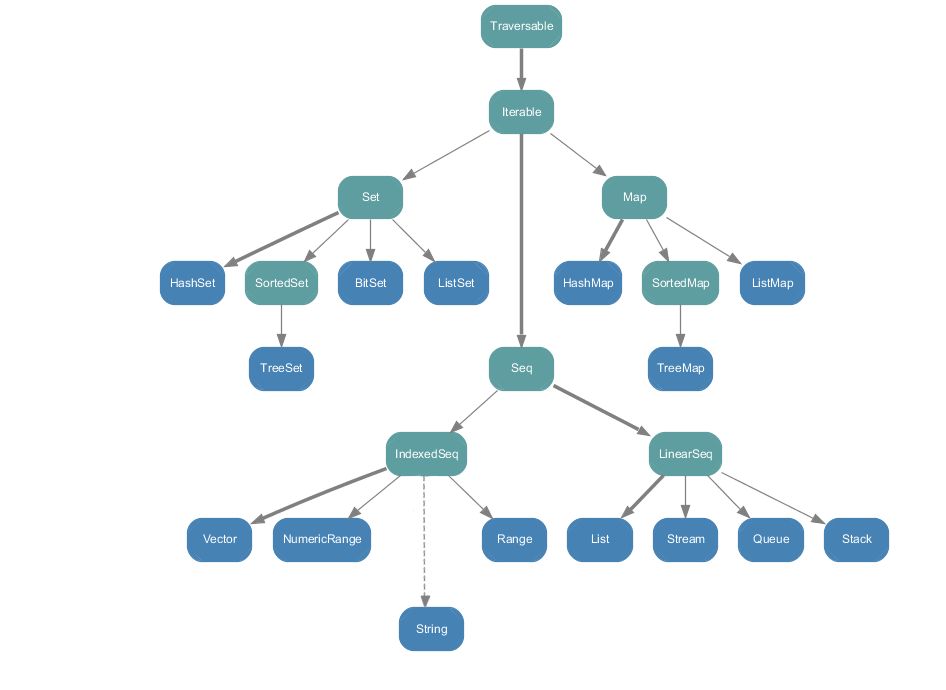
- 不可变集合没有太多好说的,集合和映射的哈希表和二叉树实现是肯定都有的,序列中分为随机访问序列(数组实现)和线性序列(链表实现),基本数据结构都有了。
- `Range` 是范围,常用来遍历,有语法糖支持 `1 to 10 by 2` `10 until 1 by -1` 其实就是隐式转换加上方法调用。
- scala中的 String 就是 java.lang.String ,和集合无直接关系,所以是虚箭头,是通过 `Perdef` 中的低优先级隐式转换来做到的。经过隐式转换为一个包装类型后就可以当做集合了。
- Array 和 String 类似,在图中漏掉了。
- 此类包装为了兼容java在scala中非常常见,scala中很多类型就是对java类型的包装或者仅仅是别名。
- scala中可能会推荐更多地使用不可变集合。能用不可变就用不可变。
1.2. 可变集合一览
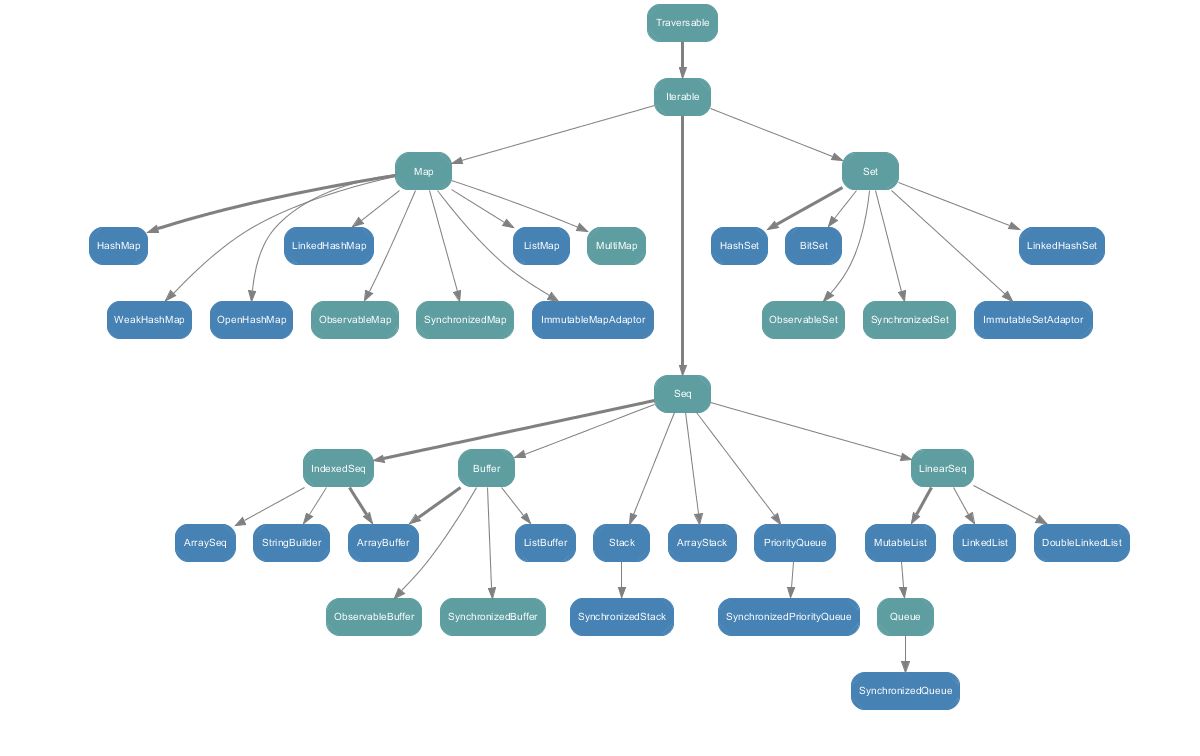
- 序列中多了 Buffer ,整体结构差不多。
- 不可变指的是对象大小不可变,但是可以修改元素的值,需要注意这一点。而如果用了 val 不变量存储,那么指向对象的地址也不可变。
- 不可变集合在原集合上个插入删除数据是做不到的,只能返回新的集合。
- 集合类型大多都是支持泛型,使用泛型的语法是` [Type] `,不同于java的 `<Type>` 。
2. 数组
2.1. 定长数组
- 访问元素使用 `()` 运算符,通过 `apply/update` 方法实现,源码中的实现只是抛出错误作为存根方法(stab method),具体逻辑由编译器填充。
- 代码:
|
// 1. new
val arr = new Array[Int](5)
// 2. factory method in companion obejct
val arr1 = Array[Int](5)
val arr2 = Array(0, 1, 3, 4)
// 3. traverse, range for
for (i <‐ 0 until arr.length) arr(i) = i
for (i <‐ arr.indices) print(s"${arr(i)} ")
println()
// 4. tarverse, foreach
for (elem <‐ arr) print(s"$elem ") // elem is a val
println()
// 5. tarverse, use iterator
val iter = arr.iterator
while (iter.hasNext)
print(s"${iter.next()} ")
println()
// 6. traverse, use foreach method, pass a function
arr.foreach((elem: Int) => print(s"$elem "))
println()
println(arr2.mkString(", ")) // to string directly
// 7. add element, return a new array, : should toward to object
val newArr = arr :+ 10 // arr.:+(10) add to end
println(newArr.mkString(", "))
val newArr2 = 20 +: 10 +: arr :+ 30 // arr.+:(10).+:(20).:+(30)
println(newArr2.mkString(", "))
|
- 可以看到自定义运算符可以非常灵活,规定如果运算符首尾有` : `那么` : `一定要指向对象。
- 下标越界会抛出异常,使用前应该检查。
- 通过 Predef 中的隐式转换为一个混入了集合相关特征的包装类型从而得以使用scala的集合相关特征,
- Array 类型中并没有相关混入。
2.2. 变长数组
- 类型 `ArrayBuffer` ,类似于Java的ArrayList。
|
// 1. create
val arr: ArrayBuffer[Int] = new ArrayBuffer[Int]()
val arr1: ArrayBuffer[Int] = ArrayBuffer(10, 20, 30)
println(arr.mkString(", "))
println(arr1) // call toString ArrayBuffer(10, 20, 30)
// 2. visit
arr1(2) = 10
// 3. add element to tail
var newArr = arr :+ 15 :+ 20 // do not change arr
println(newArr)
newArr = arr += 15 // modify arr itself, add to tail return itself, do notrecommand assign to
other var
println(arr)
println(newArr == arr) // true
// 4. add to head
77 +=: arr
println(arr)
// 5. insert to middle
arr.insert(1, 10)
println(arr)
// 6. remove element
arr.remove(0, 1) // startIndex, count
println(arr)
arr ‐= 15 // remove specific element
println(arr)
// 7. convert to Array
val newImmuArr: Array[Int] = arr.toArray
println(newImmuArr.mkString(", "))
// 8. Array to ArryBuffer
val buffer: scala.collection.mutable.Buffer[Int] = newImmuArr.toBuffer
println(buffer)
|
- val arr2 = ArrayBufffferInt 也是使用的 apply 方法构建对象
- def append(elems: A*) { appendAll(elems) } 接收的是可变参数。
- 每append一次,arr在底层会重新分配空间,进行扩容,arr2的内存地址会发生变化,也就成为新的ArrayBuffffer。
- 可变数组和不可变数组可以调用方法互相转换。(toBuffffer/toArray)
2.3. 多维数组
- 就是数组的数组。
- 使用 `Array.ofDim[Type](firstDim, secondDim, ...)` 方法。
|
// create 2d array
val arr: Array[Array[Int]] = Array.ofDim[Int](2, 3)
arr(0)(1) = 10
arr(1)(0) = 100
// traverse
arr.foreach(v => println(v.mkString(",")))
|
2.4. Scala 数组与 Java 的 List 的互转
2.4.1 Scala 数组转 Java 的 List
|
import scala.collection.mutable.ArrayBuffer
object ArrayBuffer2JavaList {
def main(args: Array[String]): Unit = {
// Scala 集合和 Java 集合互相转换
val arr = ArrayBuffer("1", "2", "3")
import scala.collection.JavaConversions.bufferAsJavaList
//即这里的 bufferAsJavaList 是一个隐式函数
/*
implicit def bufferAsJavaList[A](b : scala.collection.mutable.Buffer[A]) : java.util.List[
*/
val javaArr = new ProcessBuilder(arr)
val arrList = javaArr.command()
println(arrList) //输出 [1, 2, 3]
}
}
|
2.4.2 Java 的 List 转 scala 的 Buffer
|
//说明:asScalaBuffer 是一个隐式转换 /* implicit def asScalaBuffer[A](l : java.util.List[A]) : scala.collection.mutable.Buffer[A] */ import scala.collection.JavaConversions.asScalaBuffer import scala.collection.mutable // java.util.List ==> Buffer val scalaArr: mutable.Buffer[String] = arrList scalaArr.append("jack") println(scalaArr) |
3. 元组 Tuple
元组也是可以理解为一个容器 ,可以存放各种相同或不同类型的数据。
特点:
- `(elem1,elem2, ...)`类型可以不同。
- 最多只能22个元素 ,从Tuple1定义到了Tuple22
- 使用 `_1 _2 _3 ...` 访问。
- 也可以使用 `productElement(index)` 访问 ,下标从0开始。
- `->` 创建二元组。
- 遍历:`for(elem <- tuple.productIterator)`
- 可以嵌套 ,元组的元素也可以是元组。
4. 列表 List
Scala 中的 List 和 Java List 不一样 ,在 Java 中 List 是一个接口 ,真正存放数据是 ArrayList ,而 Scala 的 List 可以 直接存放数据 ,就是一个 object ,默认情况下 Scala 的 List 是不可变的 , List 属于序列 Seq。
4.1. 不可变列表
- `List `,抽象类,不能直接 `new` ,使用伴生对象 `apply` 传入元素创建。
- `List` 本身也有 `apply` 能随机访问(做了优化),但是不能 `update` 更改。
- `foreach` 方法遍历。
- 支持 `+: :+ `首尾添加元素。
- `Nil `空列表, `::` 添加元素到表头。
- 常用 `Nil.::(elem) `创建列表,换一种写法就是 `10 :: 20 :: 30 :: Nil `得到结果 `List(10, 20, 30)`
- 合并两个列表: `list1 ::: list2` 或者 `list1 ++ list2 `。
4.2. 可变列表
- 可变列表 `ListBuffer` ,和 `ArrayBuffer` 很像。
- `final`的,可以直接 `new` ,也可以伴生对象 `apply `传入元素创建。
- 方法: `append prepend insert remove`
- 添加元素到头或尾:` +=: +=`
- 合并: `++` 得到新的列表, `++=` 合并到源上。
- 删除元素也可以用 `-= `运算符。
5. 队列 Queue
- 队列是一个有序列表,在底层可以用数组或是链表来实现。
- 其输入和输出要遵循先入先出的原则。即:先存入队列的数据,要先取出。后存入的要后取出
- 在 Scala 中,由设计者直接给我们提供队列类型使用。
- 在 scala 中, 有 `scala.collection.mutable.Queue `和 `scala.collection.immutable.Queue` , 一般来说,我们在开发中通常使用可变集合中的队列
- 入队 `enqueue(Elem*)` 出队` Elem = dequeue() `
6. 集 Set
6.1. 不可变集
- 数据无序,不可重复。
- 可变和不可变都叫 `Set `,需要做区分。默认 `Set` 定义为` immutable.Set` 别名。
- 创建时重复数据会被去除,可用来去重。
- 添加元素: `set + elem`
- 合并: `set1 ++ set2`
- 移除元素: `set - elem`
- 不改变源集合。
6.2. 可变集
- 操作基于源集合做更改。
- 为了与不可变集合区分,` import scala.collection.mutable `并用 `mutable.Set `。
- 不可变集合有的都有。
- 添加元素到源上: `set += elem` `add`
- 删除元素: `set -= elem remove`
- 合并: `set1 ++= set2 `
7. 映射 Map
Scala 中的 Map 和 Java 类似 ,也是一个散列表 ,它存储的内容也是键值对(key-value)映射 ,Scala 中不可变的 Map 是有序的 ,可变的 Map 是无序的。
7.1. 不可变映射
- Map 默认就是 `immutable.Map` 别名。
- 两个泛型类型。
- 基本元素是一个二元组。
|
// create Map
val map: Map[String, Int] = Map("a" ‐> 13, "b" ‐> 20)
println(map)
// traverse
map.foreach((kv: (String, Int)) => println(kv))
map.foreach(kv => println(s"${kv._1} : ${kv._2}"))
// get keys and values
for (key <‐ map.keys) {
println(s"${key} : ${map.get(key)}")
}
// get value of given key
println(map.get("a").get)
println(map.getOrElse("c", ‐1)) // avoid excption
println(map("a")) // if no such key will throw exception
// merge
val map2 = map ++ Map("e" ‐> 1024)
println(map2)
|
7.2. 可变映射
- `mutable.Map`
- 不可变的都支持
|
// create mutable Map
val map: mutable.Map[String, Int] = mutable.Map("a" ‐> 10, "b" ‐> 20)
// add element
map.put("c", 30)
map += (("d", 40)) // two () represent tuple to avoid ambiguity
println(map)
// remove element
map.remove("a")
map ‐= "b" // just need key
println(map)
// modify element
map.put("c", 100) // call update, add/modify
println(map)
// merge Map
map ++= Map("a" ‐> 10, "b" ‐> 20, "c" ‐> 30) // add and will override
println(map)
|
七、集合的应用操作
1. 集合通用属性和方法
- 线性序列才有长度 length 、所有集合类型都有大小 size 。
- 遍历 `for (elem <- collection) `、迭代器 `for (elem <- collection.iterator)` 。
- 生成字符串 `toString mkString` ,像 Array 这种是隐式转换为scala集合的,` toString `是继承自`java.lang.Object` 的,需要自行处理。
- 是否包含元素 `contains `。
2. 衍生集合的方法
- 获取集合的头元素 head (元素)和剩下的尾 tail (集合)。
- 集合最后一个元素 last (元素)和除去最后一个元素的初始数据 init (集合)。
- 反转 reverse 。
- 取前后n个元素 take(n) takeRight(n)
- 去掉前后n个元素 drop(n) dropRight(n)
- 交集 intersect
- 并集 union ,线性序列的话已废弃用 concat 连接。
- 差集 diff ,得到属于自己、不属于传入参数的部分。
- 拉链 zip ,得到两个集合对应位置元素组合起来构成二元组的集合,大小不匹配会丢掉其中一个集合不匹配
- 的多余部分。
- 滑窗 sliding(n, step = 1) ,框住特定个数元素,方便移动和操作。得到迭代器,可以用来遍历,每个迭代
- 的元素都是一个n个元素集合。步长大于1的话最后一个窗口元素数量可能个数会少一些。
3. 集合的简单计算操作
- 求和 sum 求乘积 product 最小值 min 最大值 max
- maxBy(func) 支持传入一个函数获取元素并返回比较依据的值,比如元组默认就只会判断第一个元素,要根
- 据第二个元素判断就返回第二个元素就行 xxx.maxBy(_._2) 。
- 排序 sorted ,默认从小到大排序。从大到小排序 sorted(Ordering[Int].reverse) 。
- 按元素排序 sortBy(func) ,指定要用来做排序的字段。也可以再传一个隐式参数逆序 sortBy(func)
- (Ordering[Int].reverse)
- 自定义比较器 sortWith(cmp) ,比如按元素升序排列 sortWith((a, b) => a < b) 或者 sortWith(_ < _) ,
- 按元组元素第二个元素升序 sortWith(_._2 > _._2) 。
- 例子:
|
object Calculations {
def main(args: Array[String]): Unit = {
// calculations of collections
val list = List(1, 4, 5, 10)
// sum
var sum = 0
for (elem <‐ list) sum += elem
println(sum)
println(list.sum)
println(list.product)
println(list.min)
println(list.max)
val list2 = List(('a', 1), ('b', 2), ('d', ‐3))
println(list2.maxBy((tuple: (Char, Int)) => tuple._2))
println(list2.minBy(_._2))
// sort, default is ascending
val sortedList = list.sorted
println(sortedList)
// descending
println(list.sorted(Ordering[Int].reverse))
// sortBy
println(list2.sortBy(_._2))
// sortWith
println(list.sortWith((a, b) => a < b))
println(list2.sortWith(_._2 > _._2))
}
}
|
4. 集合高级计算函数
- 大数据的处理核心就是映射(map)和规约(reduce)。
- 映射操作(广义上的map):
- 过滤:自定义过滤条件, filter(Elem => Boolean)
- 转化/映射(狭义上的map):自定义映射函数, map(Elem => NewElem)
- 扁平化(flflatten):将集合中集合元素拆开,去掉里层集合,放到外层中来。 flatten
- 扁平化+映射:先映射,再扁平化, flatMap(Elem => NewElem)
- 分组(group):指定分组规则, groupBy(Elem => Key) 得到一个Map,key根据传入的函数运用于集
- 合元素得到,value是对应元素的序列。
- 规约操作(广义的reduce):
- 简化/规约(狭义的reduce):对所有数据做一个处理,规约得到一个结果(比如连加连乘操作)。reduce((CurRes, NextElem) => NextRes) ,传入函数有两个参数,第一个参数是第一个元素(第一次运算)和上一轮结果(后面的计算),第二个是当前元素,得到本轮结果,最后一轮的结果就是最终结果。 reduce 调用 reduceLeft 从左往右,也可以 reduceRight 从右往左(实际上是递归调用,和一般意义上的从右往左有区别,看下面例子)。
- 折叠(fold): fold(InitialVal)((CurRes, Elem) => NextRes) 相对于 reduce 来说其实就是 fold 自己给初值,从第一个开始计算, reduce 用第一个做初值,从第二个元素开始算。 fold 调用foldLeft ,从右往左则用 foldRight (翻转之后再 foldLeft )。具体逻辑还得还源码。从右往左都有点绕和难以理解,如果要使用需要特别注意。
- 案例:
|
object HighLevelCalculations {
def main(args: Array[String]): Unit = {
val list = List(1, 10, 100, 3, 5, 111)
// 1. map functions
// filter
val evenList = list.filter(_ % 2 == 0)
println(evenList)
// map
println(list.map(_ * 2))
println(list.map(x => x * x))
// flatten
val nestedList: List[List[Int]] = List(List(1, 2, 3), List(3, 4, 5), List(10, 100))
val flatList = nestedList(0) ::: nestedList(1) ::: nestedList(2)
println(flatList)
val flatList2 = nestedList.flatten
println(flatList2) // equals to flatList
// map and flatten
// example: change a string list into a word list
val strings: List[String] = List("hello world", "hello scala", "yes no")
val splitList: List[Array[String]] = strings.map(_.split(" ")) // divide string to words
val flattenList = splitList.flatten
println(flattenList)
// merge two steps above into one
// first map then flatten
val flatMapList = strings.flatMap(_.split(" "))
println(flatMapList)
// divide elements into groups
val groupMap = list.groupBy(_ % 2) // keys: 0 & 1
val groupMap2 = list.groupBy(data => if (data % 2 == 0) "even" else "odd") // keys :"even" & "odd"
println(groupMap)
println(groupMap2)
val worldList = List("China", "America", "Alice", "Curry", "Bob", "Japan")
println(worldList.groupBy(_.charAt(0)))
// 2. reduce functions
// narrowly reduce
println(List(1, 2, 3, 4).reduce(_ + _)) // 1+2+3+4 = 10
println(List(1, 2, 3, 4).reduceLeft(_ ‐ _)) // 1‐2‐3‐4 = ‐8
println(List(1, 2, 3, 4).reduceRight(_ ‐ _)) // 1‐(2‐(3‐4)) = ‐2, a little confusing
// fold
println(List(1, 2, 3, 4).fold(0)(_ + _)) // 0+1+2+3+4 = 10
println(List(1, 2, 3, 4).fold(10)(_ + _)) // 10+1+2+3+4 = 20
println(List(1, 2, 3, 4).foldRight(10)(_ ‐ _)) // 1‐(2‐(3‐(4‐10))) = 8, a little
confusing
}
}
|
5. 集合应用案例
- Map的默认合并操作是用后面的同key元素覆盖前面的,如果要定制为累加他们的值可以用 `fold` 。
|
// merging two Map will override the value of the same key
// custom the merging process instead of just override
val map1 = Map("a" ‐> 1, "b" ‐> 3, "c" ‐> 4)
val map2 = mutable.Map("a" ‐> 6, "b" ‐> 2, "c" ‐> 5, "d" ‐> 10)
val map3 = map1.foldLeft(map2)(
(mergedMap, kv) => {
mergedMap(kv._1) = mergedMap.getOrElse(kv._1, 0) + kv._2
mergedMap
}
)
println(map3) // HashMap(a ‐> 7, b ‐> 5, c ‐> 9, d ‐> 10)
|
- 经典案例:单词计数:分词,计数,取排名前三结果。
|
// count words in string list, and get 3 highest frequency words
def wordCount(): Unit = {
val stringList: List[String] = List(
"hello",
"hello world",
"hello scala",
"hello spark from scala",
"hello flink from scala"
)
// 1. split
val wordList: List[String] = stringList.flatMap(_.split(" "))
println(wordList)
// 2. group same words
val groupMap: Map[String, List[String]] = wordList.groupBy(word => word)
println(groupMap)
// 3. get length of the every word, to (word, length)
val countMap: Map[String, Int] = groupMap.map(kv => (kv._1, kv._2.length))
// 4. convert map to list, sort and take first 3
val countList: List[(String, Int)] = countMap.toList
.sortWith(_._2 > _._2)
.take(3)
println(countList) // result
}
|
- 单词计数案例扩展,每个字符串都可能出现多次并且已经统计好出现次数,解决方式,先按次数合并之后再按照上述例子处理。
|
// strings has their frequency
def wordCountAdvanced(): Unit = {
val tupleList: List[(String, Int)] = List(
("hello", 1),
("hello world", 2),
("hello scala", 3),
("hello spark from scala", 1),
("hello flink from scala", 2)
)
val newStringList: List[String] = tupleList.map(
kv => (kv._1.trim + " ") * kv._2
)
// just like wordCount
val wordCountList: List[(String, Int)] = newStringList
.flatMap(_.split(" "))
.groupBy(word => word)
.map(kv => (kv._1, kv._2.length))
.toList
.sortWith(_._2 > _._2)
.take(3)
println(wordCountList) // result
}
|
- 当然这并不高效,更好的方式是利用上已经统计的频率信息。
|
def wordCountAdvanced2(): Unit = {
val tupleList: List[(String, Int)] = List(
("hello", 1),
("hello world", 2),
("hello scala", 3),
("hello spark from scala", 1),
("hello flink from scala", 2)
)
// first split based on the input frequency
val preCountList: List[(String, Int)] = tupleList.flatMap(
tuple => {
val strings: Array[String] = tuple._1.split(" ")
strings.map(word => (word, tuple._2)) // Array[(String, Int)]
}
)
// group as words
val groupedMap: Map[String, List[(String, Int)]] = preCountList.groupBy(_._1)
println(groupedMap)
// count frequency of all words
val countMap: Map[String, Int] = groupedMap.map(
kv => (kv._1, kv._2.map(_._2).sum)
)
println(countMap)
// to list, sort and take first 3 words
val countList = countMap.toList.sortWith(_._2 > _._2).take(3)
println(countList)
}
|
6. 并行集合(Parllel Collection)
- 使用并行集合执行时会调用多个线程加速执行。
- 使用集合类前加一个 `.par` 方法。
- 具体细节待补。
- 依赖 `scala.collection.parallel.immutable/mutable` ,2.13版本后不再在标准库中提供,需要单独下载,
- 暂未找到编好的jar的下载地址,从源码构造需要sbt,TODO。
八、模式匹配
1. match-case
- 用于替代传统C/C++/Java的 switch-case 结构,但补充了更多功能,拥有更强的能力。
- 语法:(Java中现在也支持 => 的写法了)
|
value match {
case caseVal1 => returnVal1
case caseVal2 => returnVal2
...
case _ => defaultVal
}
|
- 每一个case条件成立才返回,否则继续往下走。
- case 匹配中可以添加模式守卫,用条件判断来代替精确匹配。
|
def abs(num: Int): Int= {
num match {
case i if i >= 0 => i
case i if i < 0 => ‐i
}
}
|
- 模式匹配支持类型:所有类型字面量,包括字符串、字符、数字、布尔值、甚至数组列表等。
- 你甚至可以传入 `Any `类型变量,匹配不同类型常量。
- 需要注意默认情况处理, `case _ `也需要返回值,如果没有 但是又没有匹配到,就抛出运行时错误。默认情况 `case _ `不强制要求通配符(只是在不需要变量的值建议这么做),也可以用 `case abc` 一个变量来接住,可以什么都不做,可以使用它的值。
2. 类型匹配
- 通过指定匹配变量的类型(用特定类型变量接住),可以匹配类型而不匹配值,也可以混用。
- 需要注意类型匹配时由于泛型擦除,可能并不能严格匹配泛型的类型参数,编译器也会报警告。但 `Array` 是基本数据类型,对应于java的原生数组类型,能够匹配泛型类型参数。
|
// match type
def describeType(x: Any) = x match {
case i: Int => "Int " + i
case s: String => "String " + s
case list: List[String] => "List " + list
case array: Array[Int] => "Array[Int] " + array
case a => "Something else " + a
}
println(describeType(20)) // match
println(describeType("hello")) // match
println(describeType(List("hi", "hello"))) // match
println(describeType(List(20, 30))) // match
println(describeType(Array(10, 20))) // match
println(describeType(Array("hello", "yes"))) // not match
println(describeType((10, 20))) // not match
|
3. 匹配数组
- 对于数组可以定义多种匹配形式,可以定义模糊的元素类型匹配、元素数量匹配或者精确的某个数组元素值匹配,非常强大。
|
for (arr <‐ List(
Array(0),
Array(1, 0),
Array(1, 1, 0),
Array(10, 2, 7, 5),
Array("hello", 20, 50)
)) {
val result = arr match {
case Array(0) => "0"
case Array(1, 0) => "Array(1, 0)"
case Array(x: Int, y: Int) => s"Array($x, $y)" // Array of two elements
case Array(0, _*) => s"an array begin with 0"
case Array(x, 1, z) => s"an array with three elements, no.2 is 1"
case Array(x:String, _*) => s"array that first element is a string"
case _ => "somthing else"
}
println(result)
|
4. 匹配列表
- List匹配和Array差不多,也很灵活。还可用用集合类灵活的运算符来匹配。比如使用` :: `运算符匹配` first :: second :: rest `,将一个列表拆成三份,第一个第二个元素和剩余元素构成的列表。
- 注意模式匹配不仅可以通过返回值当做表达式来用,也可以仅执行语句类似于传统 switch-case 语句不关心返回值,也可以既执行语句同时也返回。
5. 匹配元组
- 可以匹配n元组、匹配元素类型、匹配元素值。如果只关心某个元素,其他就可以用通配符或变量。
- 元组大小固定,所以不能用 `_*` 。
6. 变量声明匹配
- 变量声明也可以是一个模式匹配的过程。
- 元组常用于批量赋值。
- val (x, y) = (10, "hello")
- val List(first, second, _*) = List(1, 3, 4, 5)
- val List(first :: second :: rest) = List(1, 2, 3, 4)
7. for表达式中的模式匹配
- 元组中取元素时,必须用 _1 _2 ... ,可以用元组赋值将元素赋给变量,更清晰一些。
- for ((first, second) <- tupleList)
- for ((first, _) <- tupleList)
- 指定特定元素的值,可以实现类似于循环守卫的功能,相当于加一层筛选。比如 `for ((10, second) <- tupleList)`
- 其他匹配也同样可以用,可以关注数量、值、类型等,相当于做了筛选。
- 元组列表匹配、赋值匹配、 for 循环中匹配非常灵活,灵活运用可以提高代码可读性。
8. 匹配对象
- 对象内容匹配。
- 直接 match-case 中匹配对应引用变量的话语法是有问题的。编译报错信息提示:不是样例类也没有一个合法的 unapply/unapplySeq 成员实现。
- 要匹配对象,需要实现伴生对象 unapply 方法,用来对对象属性进行拆解以做匹配。
9. 样例类
- 第二种实现对象匹配的方式是样例类。
- case class className 定义样例类,会直接将打包 apply 和拆包 unapply 的方法直接定义好。
- 样例类定义中主构造参数列表中的 val 甚至都可以省略,如果是 var 的话则不能省略,最好加上的感觉,奇奇怪怪的各种边角简化。
- 对象匹配和样例类例子:
|
object MatchObject {
def main(args: Array[String]): Unit = {
val person = new Person("Alice", 18)
val result: String = person match {
case Person("Alice", 18) => "Person: Alice, 18"
case _ => "something else"
}
println(result)
val s = Student("Alice", 18)
val result2: String = s match {
case Student("Alice", 18) => "Student: Alice, 18"
case _ => "something else"
}
println(result2)
}
}
class Person(val name: String, val age: Int)
object Person {
def apply(name: String, age: Int) = new Person(name, age)
def unapply(person: Person): Option[(String, Int)] = {
if (person == null) { // avoid null reference
None
} else {
Some((person.name, person.age))
}
}
}
case class Student(name: String, age: Int) // name and age are vals
|
10. 偏函数(partial function)
- 偏函数是函数的一种,通过偏函数我们可以方便地对参数做更精确的检查,例如偏函数输入类型是 `List[Int] `,需要第一个元素是0的集合,也可以通过模式匹配实现的。
- 定义:
|
val partialFuncName: PartialFunction[List[Int], Option[Int]] = {
case x :: y :: _ => Some(y)
}
|
- 通过一个变量定义方式定义, PartialFunction 的泛型类型中,前者是参数类型,后者是返回值类型。函数体中用一个 case 语句来进行模式匹配。上面例子返回输入的 List 集合中的第二个元素。
- 一般一个偏函数只能处理输入的一部分场景,实际中往往需要定义多个偏函数用以组合使用。
- 例子:
|
object PartialFunctionTest {
def main(args: Array[String]): Unit = {
val list: List[(String, Int)] = List(("a", 12), ("b", 10), ("c", 100), ("a", 5))
// keep first constant and double second value of the tuple
// 1. use map
val newList = list.map(tuple => (tuple._1, tuple._2 * 2))
println(newList)
// 2. pattern matching
val newList1 = list.map(
tuple => {
tuple match {
case (x, y) => (x, y * 2)
}
}
)
println(newList1)
// simplify to partial function
val newList2 = list.map {
case (x, y) => (x, y * 2) // this is a partial function
}
println(newList2)
// application of partial function
// get absolute value, deal with: negative, 0, positive
val positiveAbs: PartialFunction[Int, Int] = {
case x if x > 0 => x
}
val negativeAbs: PartialFunction[Int, Int] = {
case x if x < 0 => ‐x
}
val zeroAbs: PartialFunction[Int, Int] = {
case 0 => 0
}
// combine a function with three partial functions
def abs(x: Int): Int = (positiveAbs orElse negativeAbs orElse zeroAbs) (x)
println(abs(‐13))
println(abs(30))
println(abs(0))
}
}
|
九、泛型
1. 泛型
- `[TypeList] `,定义和使用都是。
- 常用于集合类型中用于支持不同元素类型。
- 和java一样通过类型擦除/擦拭法来实现。
- 定义时可以用` +- `表示协变和逆变,不加则是不变。
- class MyList[+T] {} // 协变
- class MyList[‐T] {} // 逆变
- class MyList[T] {} // 不变
2. 协变和逆变
- 比如 Son 和 Father 是父子关系, Son 是子类。
- 协变(Covariance): MyList[Son] 是 MyList[Father] 的子类,协同变化。
- 逆变(Contravariance): MyList[Son] 是 MyList[Father] 的父类,逆向变化。
- 不变(Invariant): MyList[Father] MyList[Son] 没有父子关系。
- 还需要深入了解。
3. 泛型上下限
- 泛型上限: class MyList[T <: Type] ,可以传入 Type 自身或者子类。
- 泛型下限: class MyList[T >: Type] ,可以传入 Type 自身或者父类。
- 对传入的泛型进行限定。
4. 上下文限定
- `def f[A : B](a: A) = println(a)` 等同于 `def f[A](a: A)(implicit arg: B[A])`
- 是将泛型和隐式转换结合的产物,使用上下文限定(前者)后,方法内无法使用隐式参数名调用隐式参数,
- 需要通过 `implicitly[Ordering[A]] `获取隐式变量。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律