类的组合与继承
- oop 的三大特性就是封装、继承、多态性。其中「继承」的目的其实是实现「软件重用」。
我们希望在做程序的时候可以尽量的利用以前的代码来减少的们的工作量,这就是所谓「重用」。但是实现软件重用的方式却不只有「继承」一种,本文将整理包括「继承」在内的两种软件重用方式。
对象的组合
组合对象的意义
- 对象的组合是指我们用已有的对象组合得到新的类,这是一种常见的软件复用方式。
譬如我们已经有两个类:engine 和 tyre(引擎和轮胎),那么我们把它们组合一下,就可以形成一个新的类 car(汽车)。简单来说,就是一个类的成员包含了其他类。
譬如我们现在有两个类 Person 和 Currency,它们组成了一个新的类 SavingAccont :
class Person
{
public:
Person(const char* name, const char* address){/* ... */}
~Person(){/* ... */}
void Print(){/* ... */}
private:
char name[20], address[50];
};
class Currency
{
public:
Currency(const int type, const int cents){/* ... */}
~Currency(){/* ... */}
void Print(){/* ... */}
private:
int type, cents;
};
class SavingAccont
{
public:
SavingAccont(const char* name, const char* address, int cents);
~SavingAccont(){}
void print();
private:
Person mSaver;
Currency mBalance;
};
SavingAccont 类中直接包含了 Person 和 Currency 类的两个对象,也就是重新利用了已经写好的两个类 Currency 和 Person(当然,实际上 Person 和 Currency 类的声明和实现应该被分别封装在别的头文件和 .cpp 文件中,这里全部展示出来只是为了便于理解)。
初始化类内其他类的对象
SavingAccont 类里包含了两个别的类的对象,在构造 SavingAccont 对象之前,需要先调用那两个属于别的类的成员的构造函数。
下面的代码给出了 SavingAccont 类的构造函数:(注意一点,我们是用后构造的 SavingAccont 类去调用先构造的 Person, Currency 类,这一点之后也会再提到)
SavingAccont::SavingAccont(const char* name, const char* address, int cents) : mSaver(name, address), mBalance(0, cents) {}
尽管这一句代码很长,但我们必须使用列联表初始化 mSaver 和 mBalance 这两个对象,而不能这样写:
SavingAccont::SavingAccont(const char* name, const char* address, int cents)
{
mSaver = Person(name, address);
mBalance = Currency(0, cents);
}
因为这样执行构造的时候,我们没有给 mSaver 和 mBalance 的构造函数传入参数,这就要求它们拥有 default constructor(默认构造函数,详见构造与析构函数一节),但是这两个类并没有默认构造函数,所以上面的操作会导致报错。
如果我们给它们一个重载一个默认构造函数呢?
class Person
{
public:
Person(){}//重载默认构造函数
Person(const char* name, const char* address){/* ... */}
~Person();
private:
char name[20], address[50];
};
class Currency
{
public:
Currency(){}//重载默认构造函数
Currency(const int type, const int cents){/* ... */}
~Currency();
private:
int type, cents;
};
这样的话,代码虽然可以运行,但是效率会降低一些。因为我们做的实际上是先调用了一遍默认构造函数构造了一遍,又调用带参构造函数重新构造了一遍,这无疑是浪费时间的。
而列联表可以在执行 SavingAccont 类的构造函数之前,先调用 mSaver 和 mBalance 的构造函数并向它们传入参数。
因此,在执行 Saving Accont 的构造函数时,mSaver 和 mBanlance 就已经构造好了,避免了对象的重复构造。
总而言之,我们要求尽量使用列联表进行初始化。
组合后不可破坏原类的访问限制
我们用组合的方法创建了新的类 SavingAccont,但是我们仍然要坚持 oop 的原则。
-
不能从 SavingAccont 类中的任何一个成员函数中访问 mSaver 或 mBalance 的任何一个私有的(private)或受保护(protected)的成员变量或函数。
-
允许访问这两个对象公开的(public)的成员变量/函数。
所以下面这段代码是不合法的,因为我们无权访问其他类的私有成员变量。
void SavingAccont::Print()
{
printf("Name: %s\nAddress: %s\n", mSaver.name, mSaver.address);
printf("type: %d cents: %d\n", mBalance.type, mBalance.cents);
}
但是在 Person 和 Currency 类中提供了打印的方法,而这些方法我们可以使用,所以 SavingAccont 的 Print 函数应该这样写:
void SavingAccont::Print()
{
mSaver.Print();
mBalance.Print();
}
对象的继承
继承类的意义
-
对象的继承是我们在已有类的基础上直接添加一些成员变成新的类,这也是一种常见的软件重用的方法。
-
注意到我们在「对象的组合」一节下第一个小标题是「组合对象的意义」,而这里是「继承类的意义」。这是因为组合的时候,我们必须在新的类中定义原来类的一个实体(也就是对象)。但是在继承中不需要定义实体,是直接在类的基础上进行重用的。
假设我们有一个 Person 类,然后有一个 Student 类,那么我们可以把他们的关系表示成这样:
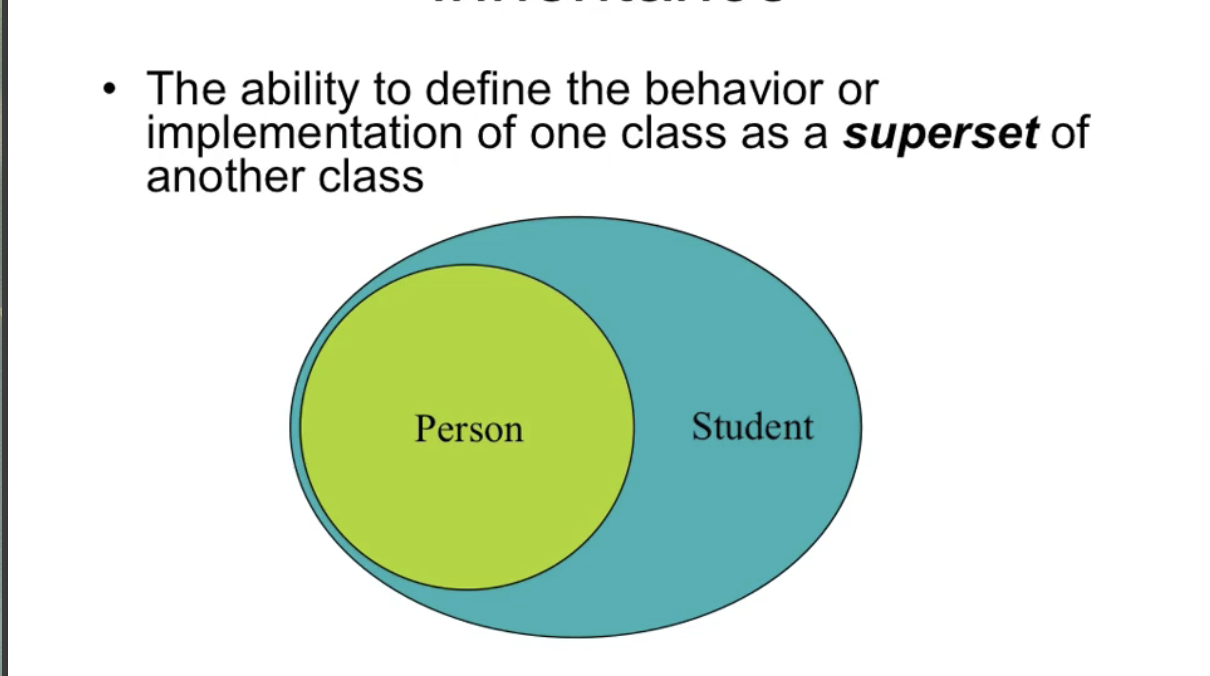
按照逻辑关系来说:学生一定是人,人不一定是学生。
再换句话说,学生不仅具有人的全部特性,学生还具有学生的一些独有的特性。
这时,我们可以说 Student 类「继承」了 Person 类,它不仅拥有 Person 类的一切成员变量和函数,在这基础上它还拥有扩充的、只属于它自己的另一些成员变量和函数。
父类与子类
- 当两个类具有继承关系的时候,我们把被继承的类称为父类,把继承而得到的类称为子类。
下面我们用一些代码来展开说父类与子类的关系和一些特性。
实验 1:子类拥有父类的所有成员
class A
{
public:
A(){ cout << "A::A()" << endl; }
~A(){ cout << "A::~A()" << endl; }
void Print(){ cout << "A::Print(), i = " << i << endl; }
void Set(int ii){ i = ii; }
private:
int i;
};
class B : public A//这一句是 B 类继承 A 类
{
};
int main()
{
B b;
b.Set(10);
b.Print();
return 0;
}
运行结果如下:
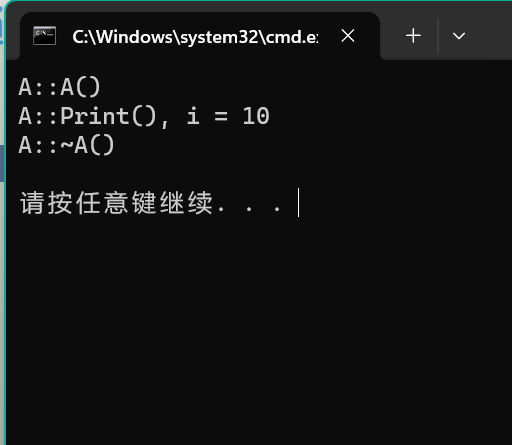
这说明:
- 子类拥有父类的所有成员
实验 2:子类可以调用父类 public 中的成员
在上一节代码的基础上,再加一些东西:
class B : public A
{
public:
void f()//new function
{
Set(20);
Print();
}
};
int main()
{
B b;
b.Set(10);
b.Print();
b.f();//using new function
return 0;
}
运行结果如下:
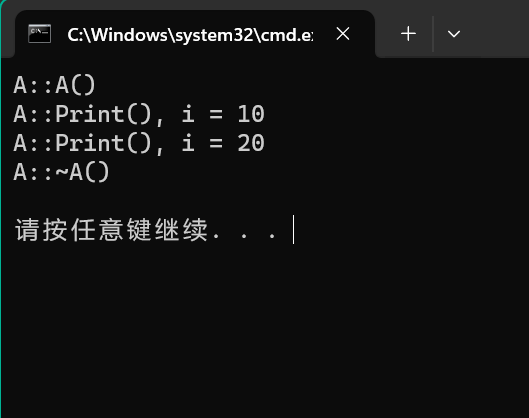
这说明:
- 子类的成员函数可以调用父类的 public 中的成员
实验 3:子类不可以调用父类 private 中的成员
首先根据实验 1,我们可以确定子类 B 已经继承了成员 i(至少它拥有这个成员)。
现在我们再改一下 f 函数,尝试从子类中直接访问成员 i:
void B::f()
{
i = 30;
Print();
}
结果编译器报错了,提示『成员 A::i 不可访问』。
这说明:
- 父类私有的对象在子类中存在,但子类不可以直接访问。子类只能通过父类提供的接口来间接的访问这些成员。
实验 4:访问属性 protected
我们再改一下 Set 函数的访问属性,由 public 变为 protected:
(因为之前改的有点乱了,这里重新放一下代码)
class A
{
public:
A(){ cout << "A::A()" << endl; }
~A(){ cout << "A::~A()" << endl; }
void Print(){ cout << "A::Print(), i = " << i << endl; }
protected://把 Set 函数设置为 protected
void Set(int ii){ i = ii; }
private:
int i;
};
class B : public A
{
public:
void f()//把 f 函数改回实验 2 的版本
{
Set(20);//这里合法
Print();
}
};
int main()
{
B b;
b.Set(10);//这里报错
b.Print();
b.f();
return 0;
}
结果编译器又报错了,提示『函数 A::Set() 不可访问』。
但是这个报错只针对主函数中的 b.set(10); 一句,B::f() 中是可以正常调用 Set 的。
这说明:
-
父类 protected 访问类型下的成员子类可以调用,而外部不可以调用。
事实上,protected 成员只能在定义这个成员的类和该类的子类中访问,这一点在访问限制的 blog 中已做过说明。
实验 5:子类构造/析构
在前面的实验中,我们已经验证了当我们创建一个子类的时候,它的父类的构造函数会自动被调用。事实上析构的时候也是如此。
接下来我们将要讨论子类和父类构造/析构函数的执行顺序,以便进一步确定细节。
还是以前面的代码为基础做实验,为 B 类添加一个 default constructor:
class A
{
public:
A(){ cout << "A::A()" << endl; }
~A(){ cout << "A::~A()" << endl; }
void Print(){ cout << "A::Print(), i = " << i << endl; }
void Set(int ii){ i = ii; }
private:
int i;
};
class B : public A
{
public:
B(){ cout << "B::B()" << endl; }
~B(){ cout << "B::~B()" << endl; }
void f()
{
Set(20);
Print();
}
};
int main()
{
B b;
b.Set(10);
b.Print();
b.f();
return 0;
}
运行结果如下:
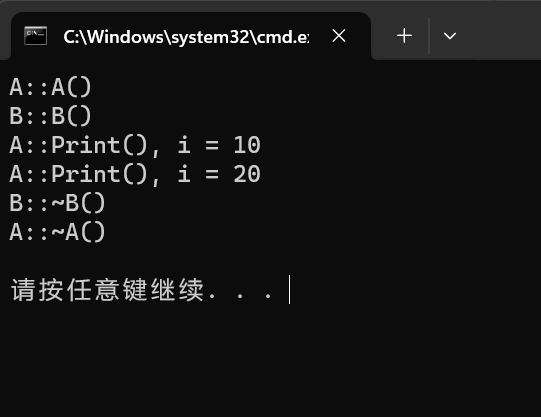
可以看到,构造时先构造了父类,然后构造了子类;析构时先析构了子类,再析构了父类。
如果 A 没有 default constructor,那么就像本文「对象的组合」一节中提到的问题一样,我们必须给 A 类的构造函数参数,否则就会报错。
而我们也有类似的解决方法,即使用后构造的类(子类)的构造函数的列联表构造先构造的类(父类)。
A::A(int ii){ i = ii; cout << "A::A()" << endl; }
B::B(int ii) : A(ii) { cout << "B::B()" << endl; };
函数名隐藏原则
- 当父类中存在某个函数,子类中存在和父类的函数同名同参数表的函数,子类的函数会把父类的函数隐藏掉。
- 特别的,如果被隐藏的父类函数是一个重载函数,那么所有的重载函数都会被隐藏。
class A
{
public:
A(){ cout << "A::A()" << endl; }
~A(){ cout << "A::~A()" << endl; }
void Print(){ cout << "A::Print()" << endl; }
void Print(int ii){ i = ii; cout << "A::Print(int ii)" << endl; }
private:
int i;
};
class B : public A
{
public:
B(){ cout << "B::B()" << endl; }
~B(){ cout << "B::~B()" << endl; }
void Print(){ cout << "B::Print()" << endl; }
};
int main()
{
B b;
b.Print();
return 0;
}
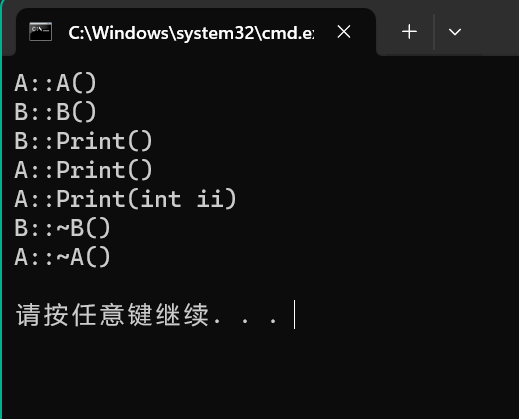
这段代码运行结果如下:
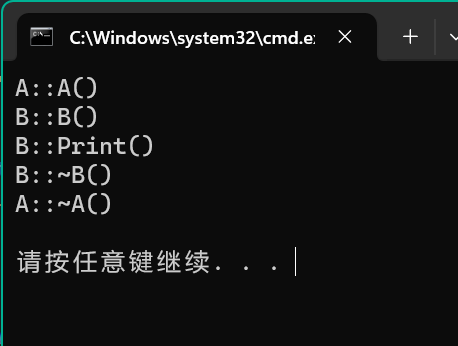
可以看到 b.Print(); 一句调用的是定义在子类 B 中的 Print 函数,而不是父类 A 中的 Print 函数。
假设我们把这一句改成 b.Print(100); 看上去是不是就应该调用父类中的 Print(int ii) 函数了呢?

结果编译器报错了,提示函数调用参数太多,并且问:是不是想要调用 A 类中的 Print(int ii) 函数。
从上面这个例子我们可以证明函数名的隐藏原则了。
-
如果我们想要调用父类中被隐藏的函数怎么办呢?
-
只要给编译器指明「我要调用 A 类中的 Print 函数」就可以了,我们把上面主函数中的代码改成这样:
b.Print();
b.A::Print();
b.A::Print(100);
代码运行结果如下: