


作业一
1)要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
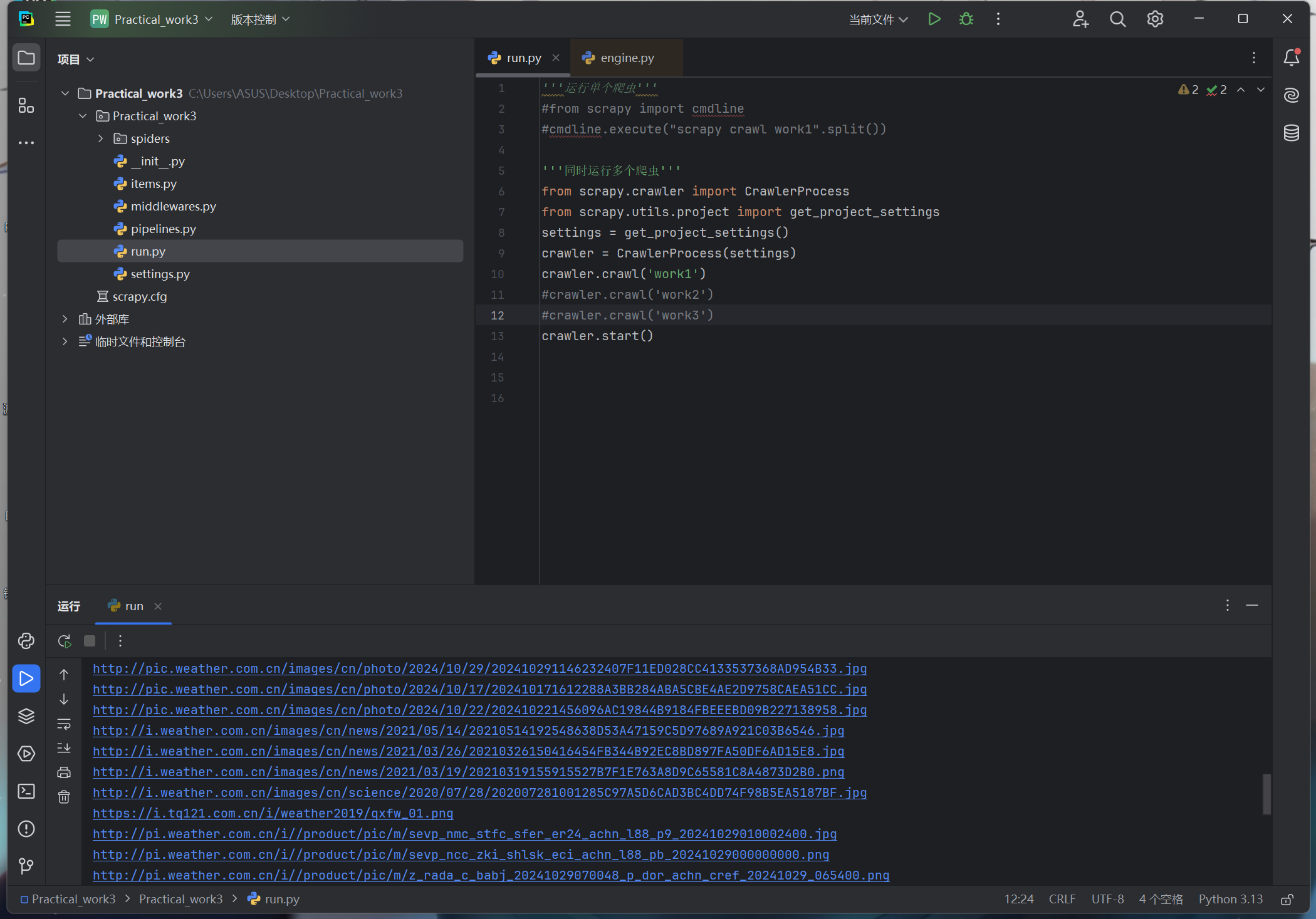
spider:
import scrapy
from Practical_work3.items import work1_Item
class Work1Spider(scrapy.Spider):
name = 'work1'
# allowed_domains = ['www.weather.com.cn']
start_urls = ['http://www.weather.com.cn/']
def parse(self, response):
data = response.body.decode()
selector=scrapy.Selector(text=data)
img_datas = selector.xpath('//a/img/@src')
for img_data in img_datas:
item = work1_Item()
item['img_url'] = img_data.extract()
yield item
pipline
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import threading
from itemadapter import ItemAdapter
import urllib.request
import os
import pathlib
import pymysql
from Practical_work3.items import work1_Item
from Practical_work3.items import work2_Item
from Practical_work3.items import work3_Item
class work1_Pipeline:
count = 0
desktopDir = str(pathlib.Path.home()).replace('\\','\\\\') + '\\Desktop'
threads = []
def open_spider(self,spider):
picture_path=self.desktopDir+'\\images'
if os.path.exists(picture_path): # 判断文件夹是否存在
for root, dirs, files in os.walk(picture_path, topdown=False):
for name in files:
os.remove(os.path.join(root, name)) # 删除文件
for name in dirs:
os.rmdir(os.path.join(root, name)) # 删除文件夹
os.rmdir(picture_path) # 删除文件夹
os.mkdir(picture_path) # 创建文件夹
# 单线程
# def process_item(self, item, spider):
# url = item['img_url']
# print(url)
# img_data = urllib.request.urlopen(url=url).read()
# img_path = self.desktopDir + '\\images\\' + str(self.count)+'.jpg'
# with open(img_path, 'wb') as fp:
# fp.write(img_data)
# self.count = self.count + 1
# return item
# 多线程
def process_item(self, item, spider):
if isinstance(item,work1_Item):
url = item['img_url']
print(url)
T=threading.Thread(target=self.download_img,args=(url,))
T.setDaemon(False)
T.start()
self.threads.append(T)
return item
def download_img(self,url):
img_data = urllib.request.urlopen(url=url).read()
img_path = self.desktopDir + '\\images\\' + str(self.count)+'.jpg'
with open(img_path, 'wb') as fp:
fp.write(img_data)
self.count = self.count + 1
def close_spider(self,spider):
for t in self.threads:
t.join()
2)心得
单线程效率不如多线程 但是简单
初步了解scrapy 框架
作业二
1)熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
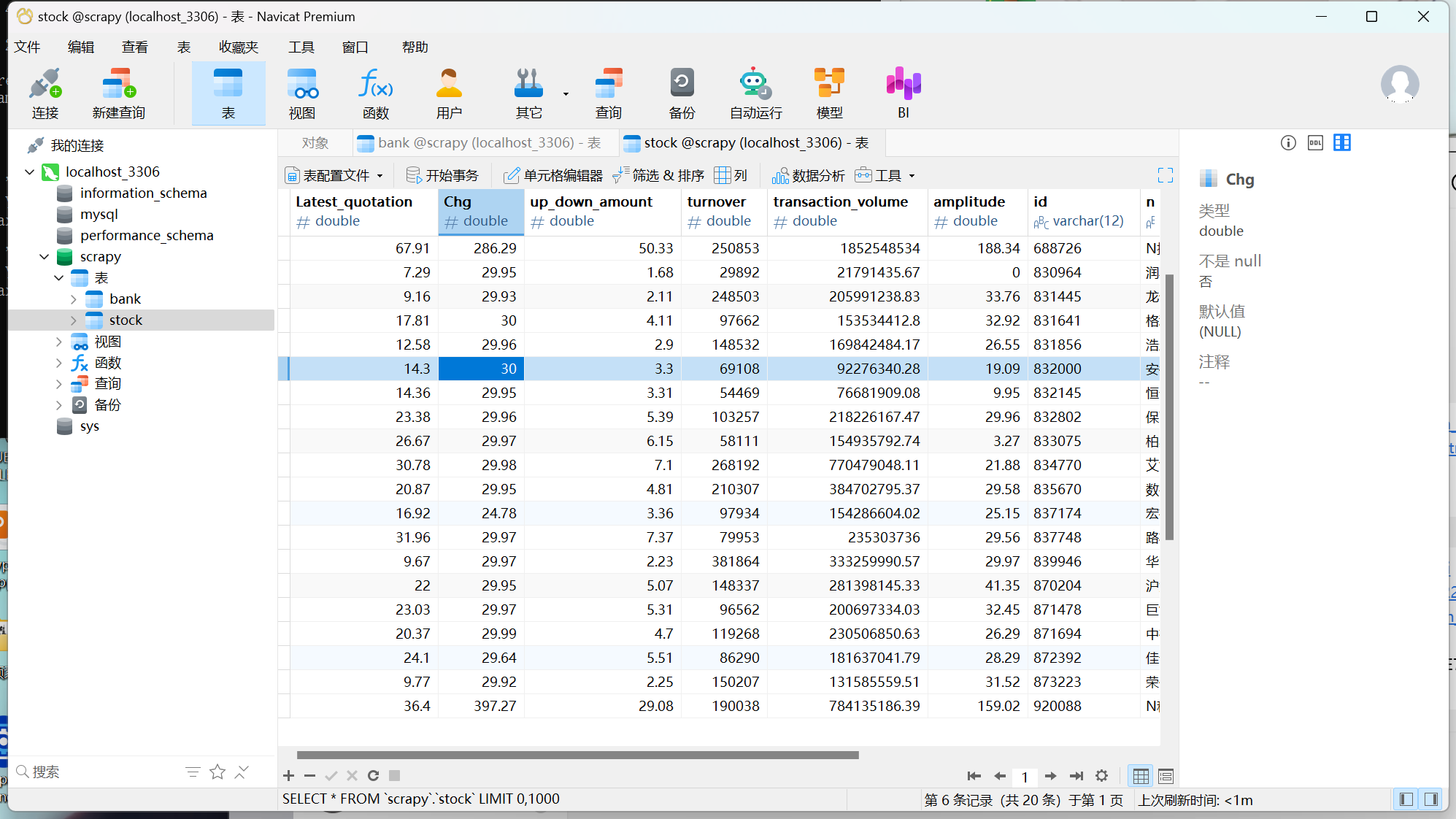
spider:
from typing import Iterable
import scrapy
from scrapy.http import Request
import re
import json
from Practical_work3.items import work2_Item
class Work2Spider(scrapy.Spider):
name = 'work2'
# allowed_domains = ['25.push2.eastmoney.com']
start_urls = ['http://25.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124021313927342030325_1696658971596&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18&_=1696658971636']
def parse(self, response):
data = response.body.decode()
item = work2_Item()
data = re.compile('"diff":\[(.*?)\]',re.S).findall(data)
columns={'f2':'最新价','f3':'涨跌幅(%)','f4':'涨跌额','f5':'成交量','f6':'成交额','f7':'振幅(%)','f12':'代码','f14':'名称','f15':'最高',
'f16':'最低','f17':'今开','f18':'昨收'}
for one_data in re.compile('\{(.*?)\}',re.S).findall(data[0]):
data_dic = json.loads('{' + one_data + '}')
for k,v in data_dic.items():
item[k] = v
yield item
pipeline:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import threading
from itemadapter import ItemAdapter
import urllib.request
import os
import pathlib
import pymysql
from Practical_work3.items import work1_Item
from Practical_work3.items import work2_Item
from Practical_work3.items import work3_Item
class work2_Pipeline:
def open_spider(self,spider):
try:
self.db = pymysql.connect(host='127.0.0.1', user='root', passwd='5F&fDpc_yih;', port=3306,charset='utf8',database='scrapy')
self.cursor = self.db.cursor()
self.cursor.execute('DROP TABLE IF EXISTS stock')
sql = """CREATE TABLE stock(Latest_quotation Double,Chg Double,up_down_amount Double,turnover Double,transaction_volume Double,
amplitude Double,id varchar(12) PRIMARY KEY,name varchar(32),highest Double, lowest Double,today Double,yesterday Double)"""
self.cursor.execute(sql)
except Exception as e:
print(e)
def process_item(self, item, spider):
if isinstance(item,work2_Item):
sql = """INSERT INTO stock VALUES (%f,%f,%f,%f,%f,%f,"%s","%s",%f,%f,%f,%f)""" % (item['f2'],item['f3'],item['f4'],item['f5'],item['f6'],
item['f7'],item['f12'],item['f14'],item['f15'],item['f16'],item['f17'],item['f18'])
self.cursor.execute(sql)
self.db.commit()
return item
def close_spider(self,spider):
self.cursor.close()
self.db.close()
2)心得
对scrapy框架越发熟悉 mysql开始上手
作业三
1)熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
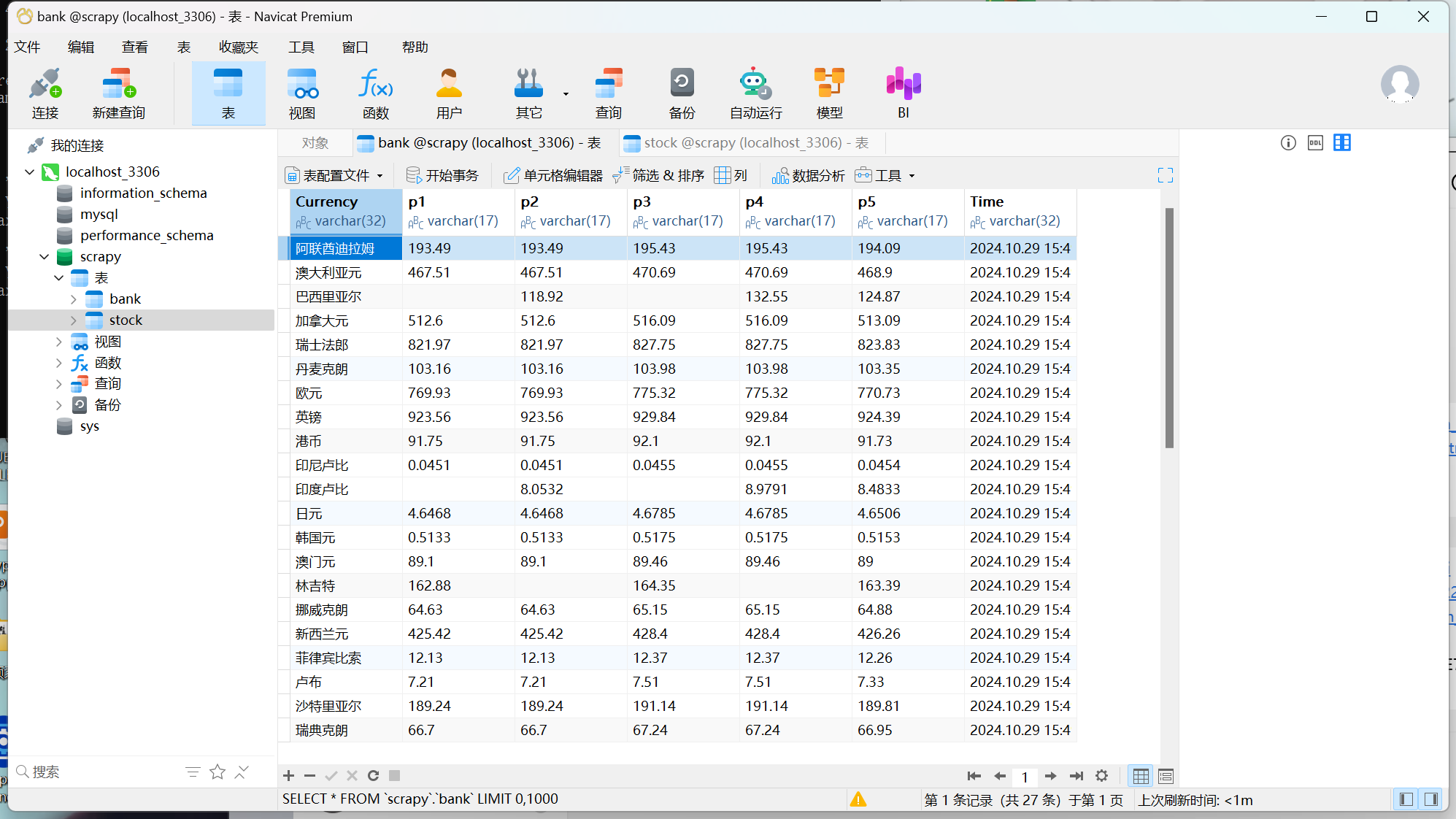
spider:
import scrapy
from Practical_work3.items import work3_Item
class Work3Spider(scrapy.Spider):
name = 'work3'
# allowed_domains = ['www.boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
data = response.body.decode()
selector=scrapy.Selector(text=data)
data_lists = selector.xpath('//table[@align="left"]/tr')
for data_list in data_lists:
datas = data_list.xpath('.//td')
if datas != []:
item = work3_Item()
keys = ['name','price1','price2','price3','price4','price5','date']
str_lists = datas.extract()
for i in range(len(str_lists)-1):
item[keys[i]] = str_lists[i].strip('<td class="pjrq"></td>').strip()
yield item
pipeline:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import threading
from itemadapter import ItemAdapter
import urllib.request
import os
import pathlib
import pymysql
from Practical_work3.items import work1_Item
from Practical_work3.items import work2_Item
from Practical_work3.items import work3_Item
class work3_Pipeline:
def open_spider(self,spider):
try:
self.db = pymysql.connect(host='127.0.0.1', user='root', passwd='5F&fDpc_yih;', port=3306,charset='utf8',database='scrapy')
self.cursor = self.db.cursor()
self.cursor.execute('DROP TABLE IF EXISTS bank')
sql = """CREATE TABLE bank(Currency varchar(32),p1 varchar(17),p2 varchar(17),p3 varchar(17),p4 varchar(17),p5 varchar(17),Time varchar(32))"""
self.cursor.execute(sql)
except Exception as e:
print(e)
def process_item(self, item, spider):
if isinstance(item,work3_Item):
sql = 'INSERT INTO bank VALUES ("%s","%s","%s","%s","%s","%s","%s")' % (item['name'],item['price1'],item['price2'],
item['price3'],item['price4'],item['price5'],item['date'])
self.cursor.execute(sql)
self.db.commit()
return item
def close_spider(self,spider):
self.cursor.close()
self.db.close()
2)心得:对scrapy越发熟悉 掌握mysql
