垃圾收集算法笔记
之前我们说过了Java运行时的数据区域划分,其中程序计数器、虚拟机栈、本地方法栈3个区域随线程生灭,这几个区域内就不需要过多考虑回收的问题,因为方法结束或者线程结束时,内存自然就很随着回收了。而Java堆和方法区则不一样,我们只有在程序处于运行期间才能知道会创建哪些对象,这部分内存的分配和回收都是动态的,垃圾收集器所关注的是这部分内存。
判断对象是否「已死」的方法
在垃圾收集器对堆进行回收前,要做的就是确定对象是否还「活着」,其中有如下两种方法。
-
引用计数法(没有被主流Java虚拟机使用)
给对象中添加一个引用计数器,每当有一个地方引用它时,计数器的值就加1;当引用失效时,计数器的值就减1;任何时刻计数器为0的对象就是不可能再被使用的(可以进行垃圾回收)。
优点:实现简单,判定效率高
缺点:很难解决对象之间相互循环引用的问题
-
可达性分析算法(主流Java虚拟机中所使用)
通过一系列的称为「GC Roots」的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链,当一个对象到 GC Roots没有任何引用链相连时,则证明此对象是不可用的(可以进行垃圾回收)。
在Java语言中,可作为GC Roots的对象包括下面几种:
-
虚拟机栈(栈帧中的本地变量表)中引用的对象
-
方法区中类静态属性引用的对象
-
方法区中常量引用的对象
-
本地方法区中JNI(Java Native Interface)引用的对象
垃圾收集算法
-
标记-清除算法
算法分为「标记」和「清除」两个部分:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象,它的标记过程就是前面所说的对象标记判定。

此法主要有如下两个缺点:
-
效率问题(标记和清除两个过程的效率都不高)
-
空间问题,标记清除后会产生大量不连续的内存碎片,可能导致无法分配较大对象。
-
复制算法
为了解决标记清除的效率问题,「复制算法」出现了,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内容用完了,将活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。

缺点就是这种算法将内存缩小为了原来的一半。
-
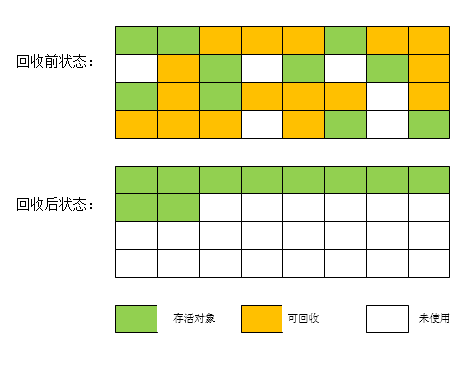
标记-整理算法
复制收集算法在对象存活率较高时就要进行较多的复制操作,效率将会变低。而「标记-整理算法」,标记过程仍然与「标记-清除」算法一样,但是后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
-
分代收集算法
当前商业虚拟机的垃圾收集都采用「分代收集」算法,根据对象存活周期的不同将内存划分为几块,一般是把Java堆分为新生代和老年代。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用「标记-清理」或者「标记-整理」算法来进行回收。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号